
美團的OCR方案介紹

向AI轉(zhuǎn)型的程序員都關(guān)注了這個號??????
機器學習AI算法工程 公眾號:datayx
背景
近年來,移動互聯(lián)、大數(shù)據(jù)等新技術(shù)飛速發(fā)展,倒逼傳統(tǒng)行業(yè)向智能化、移動化的方向轉(zhuǎn)型。隨著運營集約化、數(shù)字化的逐漸鋪開,尤其是以O(shè)CR識別、數(shù)據(jù)挖掘等為代表的人工智能技術(shù)逐漸深入業(yè)務場景,為用戶帶來持續(xù)的經(jīng)濟效益和品牌效應。圖書情報領(lǐng)域作為提升公共服務的一個窗口,面臨著新技術(shù)帶來的沖擊,必須加強管理創(chuàng)新,積極打造智能化的圖書情報服務平臺,滿足讀者的個性化需求。無論是高校圖書館還是公共圖書館,都需加強人工智能基礎(chǔ)能力的建設(shè),并與圖書館內(nèi)部的信息化系統(tǒng)打通,優(yōu)化圖書館傳統(tǒng)的服務模式,提升讀者的借閱體驗。
影像分類和錄入紙質(zhì)材料是圖書館的常態(tài)生產(chǎn)需求,比如:拍照的圖書文本和借閱證件信息的分類與錄入,會消耗大量人力、物力和時間成本,影響業(yè)務流程的效率和用戶體驗。人工錄入的效率和準確性低,且易受館員情緒影響。長期從事繁瑣機械的錄入工作,對于館員是極大的心理負擔。智能OCR利用機器24h連續(xù)工作,不受時間限制,可解決上述圖書館業(yè)務的痛點,提高影像處理效率。
隨著2012年Imagenet競賽采用深度學習技術(shù)的AlexNet奪得冠軍,深度學習算法開始應用于圖像視頻領(lǐng)域。基于深度學習的智能OCR技術(shù)是一次跨越式的升級[9-12],深度學習算法實現(xiàn)整行識別,提升了OCR的識別率和識別速度,人工需要幾分鐘才能錄入的文本,智能OCR技術(shù)可以秒速進行精準識別。智能OCR識別技術(shù)對識別流程進行了優(yōu)化,優(yōu)化后的識別流程包括檢測、識別和后處理3個主要步驟,如圖2所示。
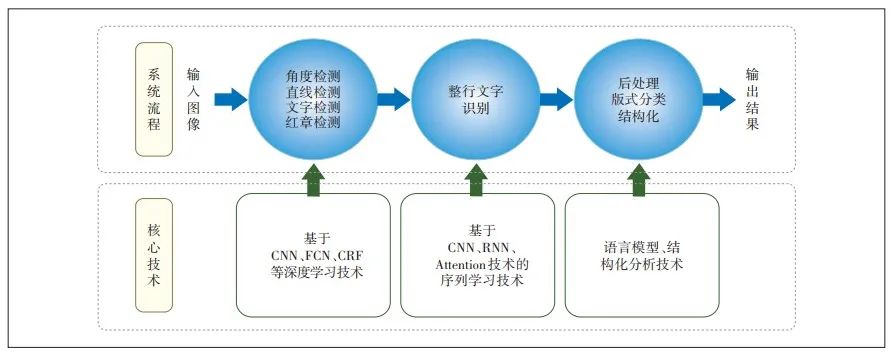
智能OCR識別技術(shù)流程
基于深度學習的OCR定位與識別通過卷積神經(jīng)網(wǎng)絡(luò)CNN、循環(huán)神經(jīng)網(wǎng)絡(luò)RNN、長短期記憶網(wǎng)絡(luò)LSTM技術(shù)實現(xiàn),可在灰度圖像上實現(xiàn)文字區(qū)域的自動定位和整行文字的識別,解決了傳統(tǒng)OCR技術(shù)中單字識別無法借助上下文來判斷形似字的問題。此外,智能OCR識別技術(shù)在低質(zhì)量圖片的容忍能力和識別準確率方面得到了顯著的提升,可在印刷體低分辨率與模糊字符識別、印刷體復雜或者非均勻背景識別、印刷體多語言混合識別、印刷體藝術(shù)字體識別、手寫小寫數(shù)字識別、手寫大寫金額識別、手寫通用文本識別等場景下實現(xiàn)高效的識別和分類。基于深度學習的智能OCR識別技術(shù)支持移動設(shè)備拍攝的圖像識別,可適用于對焦不準、高噪聲、低分辨率、強光影等復雜背景。
除了在卡證識別、票據(jù)識別、表單識別、文檔識別,智能OCR可應用于互聯(lián)網(wǎng)廣告推薦系統(tǒng)、UCG圖片視頻過濾、醫(yī)學影像識別、街景路牌識別等。智能OCR識別屬于多類分類問題,場景復雜、挑戰(zhàn)性大;尤其是中文識別,字符集達到20000類,而英文數(shù)字加字母只有62類。影響OCR識別效果的因素較多,比如背景的復雜度、字體的種類、分辨率的高低、多語言混合度、字體的排列、變形和透視情況等。
圖書館生產(chǎn)需求更多的發(fā)生在移動端,用戶更喜歡用手機拍照后即可識別,智能OCR技術(shù)綜合已有的信息化技術(shù),可在各種移動端實現(xiàn)適配。首先,基于輕量級深度學習技術(shù),實現(xiàn)移動端的取圖功能;其次,融合視頻流識別技術(shù),即從視頻中識別出圖書館卡證的有效信息。深度學習網(wǎng)絡(luò)可高效地學習到邊緣情況,通過邊緣的檢測,得到物體的邊緣輪廓,然后通過邊緣跟蹤合并,保障識別效果。移動端適配網(wǎng)絡(luò)計算量很小,大多數(shù)的移動端設(shè)備均支持,即使透視變換很嚴重的圖像也能很好地校正,保證移動端識別的準確率。
移動端圖像的采集受光照強弱、拍攝抖動、對焦方式等條件影響,有時會導致采集的原始圖像非常模糊,最終使得圖像無法被有效地識別。基于此,需要將模糊的圖像阻擋在識別之前,使得系統(tǒng)資源被合理的利用。基于深度學習的圖像質(zhì)量判斷,提供一種圖像質(zhì)量判斷能力,通過CNN學習得到輸入圖像質(zhì)量的分類,給出判斷的可信度。
角度檢測和文本檢測是文本識別的前提,可在雜亂無序、千奇百怪的復雜場景中準確定位出角度、直線、圖章、文字等區(qū)域。由于圖像可能帶有一定角度,有的甚至有可能是90°以上傾斜或者倒立圖像,需要檢測出圖像的主方向角度;處理的圖像可能存在表格線,圖章等,都需要檢測出來;對于圖像中的文字行區(qū)域,需按照文本行檢測出每一塊的外接四邊形。傳統(tǒng)的方法是功能模塊分開,各自采用不同的網(wǎng)絡(luò)進行定位,所需的網(wǎng)絡(luò)規(guī)模巨大,串行效率較低。為解決此問題,可采用基于多任務(MultiTask)的FCN檢測網(wǎng)絡(luò),將角度檢測、直線檢測、圖章檢測、文字檢測融合在一個檢測網(wǎng)絡(luò)中,從輸出的特征圖中預測出需要檢測結(jié)果。
文字圖像是按照一定的規(guī)則和順序排列的,OCR可看成是一種與語音識別類似的序列識別問題。基于與語音識別問題類似,OCR技術(shù)可視為時序依賴的詞匯或短語識別問題。利用CNN+LSTM+Attention+CTC網(wǎng)絡(luò)實現(xiàn)端到端的整行文字識別,精度和效率均有較大提升,下面介紹2種常見的整行識別算法。
基于CRNN的整行識別技術(shù)(CNN+LSTM+CTC)
基于聯(lián)結(jié)時序分類CTC(Connectionist Temporal Classification)訓練RNN的算法,在語音識別領(lǐng)域中相對于傳統(tǒng)算法具有顯著優(yōu)勢,所以嘗試在OCR識別中借鑒CTC損失函數(shù)。CRNN就是其中代表性算法,CRNN算法輸入100×32歸一化高度的詞條圖像,基于7層CNN提取特征圖,把特征圖按列切分(Map-to-Se?quence),每一列包含512個維度特征,輸入到兩層雙向LSTM神經(jīng)網(wǎng)絡(luò)(每層包含256個單元格)進行分類。在訓練過程中,通過CTC損失函數(shù)的指導,實現(xiàn)字符位置與類標的近似軟對齊。CRNN借鑒語音識別中的LSTM+CTC的建模方法,不同點是輸入的LSTM特征,從語音領(lǐng)域的聲學特征(MFCC),替換為CNN網(wǎng)絡(luò)提取的圖像特征向量。CRNN算法把CNN做圖像特征工程的潛力與LSTM做序列化識別的潛力結(jié)合,既提取了魯棒特征,又通過序列識別避免了傳統(tǒng)算法中難度極高的單字符切分與單字符識別等問題,同時序列化識別也嵌入時序依賴(隱含利用語料)。
智能OCR識別技術(shù)通過改進LSTM+CTC算法,在CNN一側(cè),通過在卷積層采取類似VGG網(wǎng)絡(luò)的結(jié)構(gòu),減少CNN卷積核數(shù)量的同時增加卷積層深度,既保證精度又降低時耗,同時加入BatchNorm機制。在RNN一側(cè),針對LSTM有對語料和圖像背景過擬合的傾向,在雙向LSTM單元層實現(xiàn)Dropout。在訓練階段,針對CTCloss對初始化敏感和收斂速度慢的問題,采用樣本由易到難、分階段訓練的策略。在測試階段,針對字符拉伸導致識別率降低的問題,保持輸入圖像尺寸比例,根據(jù)卷積特征圖的尺寸動態(tài)決定LSTM時序長度。
聯(lián)合CTC和Attention機制的整行識別
近年來,注意力機制廣泛應用于語音識別、圖像描述、自然語言處理等領(lǐng)域。就其在OCR的應用而言,注意力機制能夠?qū)崿F(xiàn)特征向量與原圖字符區(qū)域的近似對齊,聚焦詞條圖像特征向量的ROI,優(yōu)化深度網(wǎng)絡(luò)Encoder-Decoder模型的準確率。相比于CNN+LSTM+CTC模型,注意力模型更顯式的把當前時刻待分類字符與原圖位置對齊,也更顯式的利用前一時刻語料;注意力模型配合自回歸連接,除了精度提升,收斂速度也加快了。
聯(lián)合訓練方案的精度更優(yōu),且收斂速度與CTC相當,注意力機制就是采用基于內(nèi)容和歷史相結(jié)合的方法。基于內(nèi)容的方法利用上一步預測的字符向量和預測該向量的加權(quán)特征向量作為聯(lián)合特征,LSTM的輸入也來源于聯(lián)合特征向量,并生成注意力機制的查詢向量。基于歷史的方法借助上一步的注意力,并利用CNN模型提取上一步注意力的特征,生成注意力機制索引向量的部分內(nèi)容。除此,還在訓練數(shù)據(jù)與技巧等方面做多處改進,如引入圖像隨機填補、依據(jù)每個batch內(nèi)樣本動態(tài)填補圖像長度等。
對于識別的各種票據(jù)、單據(jù)圖像,如果一次只能上傳識別一張,且需要指定圖像必須正立的,會大大影響用戶體驗。多目標分割定位技術(shù),可同時對一張圖像上的不同目標進行分割定位,實現(xiàn)多種票據(jù)的同時識別。算法支持任意角度和任意方向的文檔,分割得到最佳擬合文檔的多邊形,做到最大限度的所見即所得,有利于后面的圖像校正和識別。
多圖像的智能分類運用了分層特征融合方法,從圖像分割開始就支持圖像的大類分割分類,然后基于圖像特征和OCR文本特征進行圖像類別的精分類。圖3是一種可注冊的圖像分類流程。
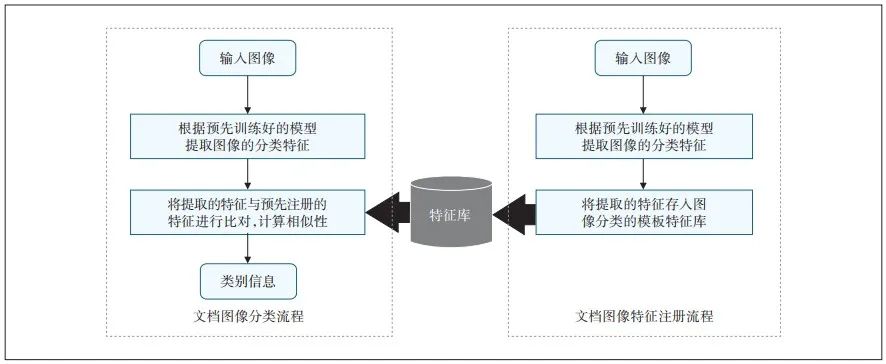
智能OCR多文檔圖像智能分類
在各種場景中,要求不但要定位識別出圖像中文字,還需要將圖像分類到之前定義的版式中,方便圖像歸類和識別結(jié)果入庫。在版式分類模塊中,通過工具配置模板,然后利用模板信息對輸入圖像進行匹配打分,提取最大的匹配分數(shù);當分數(shù)大于預定值時,則匹配成功,否則匹配不成功。整個版式匹配的算法流程圖如圖4所示。版式匹配分3個步驟。
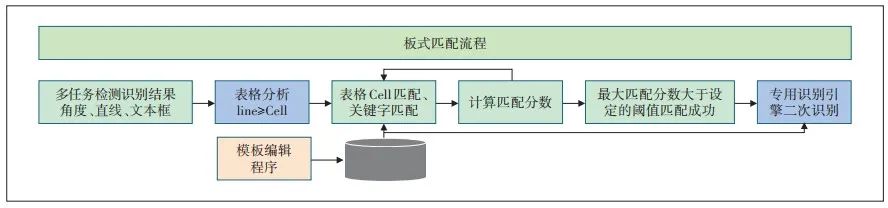
智能OCR版式分類流程圖
第1步就是利用提取的直線,分析出表格各個格子(Cell)和表格的結(jié)構(gòu),將文字行納入該Cell。
第2步,匹配表格結(jié)構(gòu)、行列數(shù)量、表格Cell的相對尺寸、Cell占的行數(shù)和列數(shù),特別是需要匹配表格Cell內(nèi)部關(guān)鍵字。
第3步,計算線匹配分數(shù)和表格線匹配分數(shù),計算關(guān)鍵字文本匹配分數(shù)并加權(quán)相加后得到最終的匹配分數(shù)。最后,計算所有的模板與識別結(jié)果的匹配分數(shù),匹配分數(shù)最大者為表格分類結(jié)果,調(diào)用設(shè)定的多類識別核心,完成對應內(nèi)容的二次識別。
基于深度學習的OCR
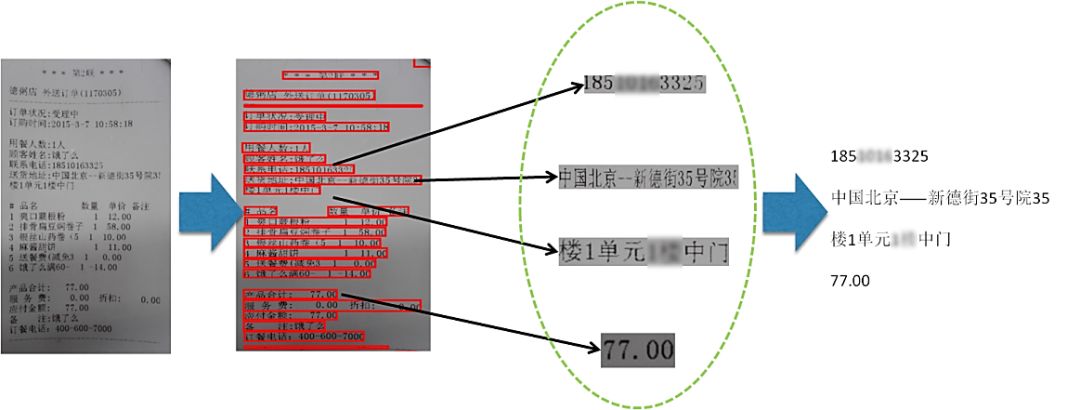
文字是不可或缺的視覺信息來源。相對于圖像/視頻中的其他內(nèi)容,文字往往包含更強的語義信息,因此對圖像中的文字提取和識別具有重大意義。OCR在美團業(yè)務中主要起著兩方面作用。一方面是輔助錄入,比如在移動支付環(huán)節(jié)通過對銀行卡卡號的拍照識別以實現(xiàn)自動綁卡,輔助運營錄入菜單中菜品信息,在配送環(huán)節(jié)通過對商家小票的識別以實現(xiàn)調(diào)度核單,如圖1所示。另一方面是審核校驗,比如在商家資質(zhì)審核環(huán)節(jié)對商家上傳的身份證、營業(yè)執(zhí)照和餐飲許可證等證件照片進行信息提取和核驗以確保該商家的合法性,機器過濾商家上單和用戶評價環(huán)節(jié)產(chǎn)生的包含違禁詞的圖片。
OCR技術(shù)發(fā)展歷程
傳統(tǒng)的OCR基于圖像處理(二值化、連通域分析、投影分析等)和統(tǒng)計機器學習(Adaboost、SVM),過去20年間在印刷體和掃描文檔上取得了不錯的效果。傳統(tǒng)的印刷體OCR解決方案整體流程如圖2所示。
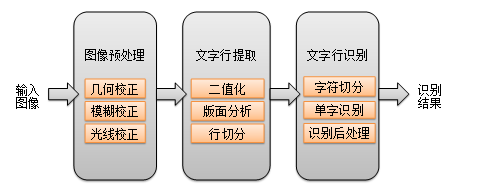
從輸入圖像到給出識別結(jié)果經(jīng)歷了圖像預處理、文字行提取和文字行識別三個階段。其中文字行提取的相關(guān)步驟(版面分析、行切分)會涉及大量的先驗規(guī)則,而文字行識別主要基于傳統(tǒng)的機器學習方法。隨著移動設(shè)備的普及,對拍攝圖像中的文字提取和識別成為主流需求,同時對場景中文字的識別需求越來越突出。因此,相比于印刷體場景,拍照文字的識別將面臨以下三方面挑戰(zhàn):
成像復雜。噪聲、模糊、光線變化、形變。
文字復雜。字體、字號、色彩、磨損、筆畫寬度任意、方向任意。
場景復雜。版面缺失、背景干擾。
對于上述挑戰(zhàn),傳統(tǒng)的OCR解決方案存在著以下不足:
通過版面分析(連通域分析)和行切分(投影分析)來生成文本行,要求版面結(jié)構(gòu)有較強的規(guī)則性且前背景可分性強(例如黑白文檔圖像、車牌),無法處理前背景復雜的隨意文字(例如場景文字、菜單、廣告文字等)。另外,二值化操作本身對圖像成像條件和背景要求比較苛刻。
通過人工設(shè)計邊緣方向特征(例如方向梯度直方圖)來訓練字符識別模型,在字體變化、模糊或背景干擾時,此類單一的特征的泛化能力迅速下降。
過度依賴于字符切分的結(jié)果,在字符扭曲、粘連、噪聲干擾的情況下,切分的錯誤傳播尤其突出。
盡管圖像預處理模塊可有效改善輸入圖像的質(zhì)量,但多個獨立的校正模塊的串聯(lián)必然帶來誤差傳遞。另外由于各模塊優(yōu)化目標獨立,它們無法融合到統(tǒng)一的框架中進行。
為了解決上述問題,現(xiàn)有技術(shù)在以下三方面進行了改進。
1. 文字行提取
傳統(tǒng)OCR(如圖3所示)采取自上而下的切分式,但它只適用于版面規(guī)則背景簡單的情況。該領(lǐng)域還有另外兩類思路。
自底向上的生成式方法。該類方法通過連通域分析或最大穩(wěn)定極值區(qū)域(MSER)等方法提取候選區(qū)域,然后通過文字/非文字的分類器進行區(qū)域篩選,對篩選后的區(qū)域進行合并生成文字行,再進行文字行級別的過濾,如圖3所示。該類方法的不足是,一方面流程冗長導致的超參數(shù)過多,另一方面無法利用全局信息。
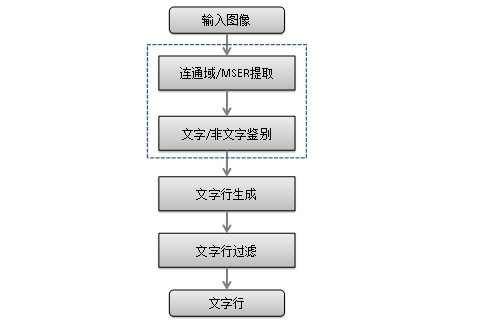
基于滑動窗口的方法。該類方法利用通用目標檢測的思路來提取文字行信息,利用訓練得到的文字行/詞語/字符級別的分類器來進行全圖搜索。原始的基于滑動窗口方法通過訓練文字/背景二分類檢測器,直接對輸入圖像進行多尺度的窗口掃描。檢測器可以是傳統(tǒng)機器學習模型(Adaboost、Random Ferns),也可以是深度卷積神經(jīng)網(wǎng)絡(luò)。
為了提升效率,DeepText、TextBoxes等方法先提取候選區(qū)域再進行區(qū)域回歸和分類,同時該類方法可進行端到端訓練,但對多角度和極端寬高比的文字區(qū)域召回低。
2. 傳統(tǒng)單字識別引擎→基于深度學習的單字識別引擎
由于單字識別引擎的訓練是一個典型的圖像分類問題,而卷積神經(jīng)網(wǎng)絡(luò)在描述圖像的高層語義方面優(yōu)勢明顯,所以主流方法是基于卷積神經(jīng)網(wǎng)絡(luò)的圖像分類模型。實踐中的關(guān)鍵點在于如何設(shè)計網(wǎng)絡(luò)結(jié)構(gòu)和合成訓練數(shù)據(jù)。對于網(wǎng)絡(luò)結(jié)構(gòu),我們可以借鑒手寫識別領(lǐng)域相關(guān)網(wǎng)絡(luò)結(jié)構(gòu),也可采用OCR領(lǐng)域取得出色效果的Maxout網(wǎng)絡(luò)結(jié)構(gòu),如圖4所示。對于數(shù)據(jù)合成,需考慮字體、形變、模糊、噪聲、背景變化等因素。
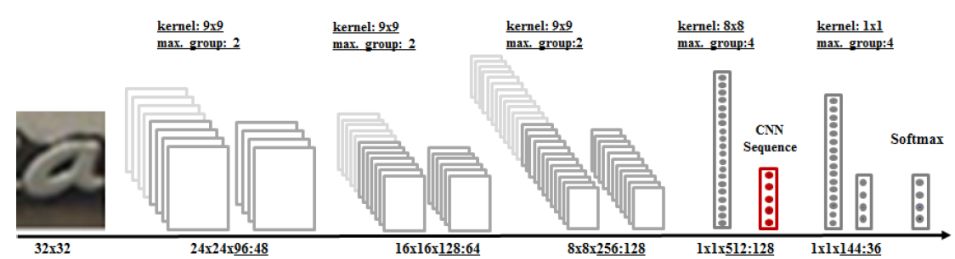
表1給出了卷積神經(jīng)網(wǎng)絡(luò)的特征學習和傳統(tǒng)特征的性能比較,可以看出通過卷積神經(jīng)網(wǎng)絡(luò)學習得到的特征鑒別能力更強。

3. 文字行識別流程
傳統(tǒng)OCR將文字行識別劃分為字符切分和單字符識別兩個獨立的步驟,盡管通過訓練基于卷積神經(jīng)網(wǎng)絡(luò)的單字符識別引擎可以有效提升字符識別率,但切分對于字符粘連、模糊和形變的情況的容錯性較差,而且切分錯誤對于識別是不可修復的。因此在該框架下,文本行識別的準確率主要受限于字符切分。假設(shè)已訓練單字符識別引擎的準確率p=99%,字符切分準確率為q= 95%,則對于一段長度為L的文字行,其識別的平均準確率為P= (pq)的L次方,其中L = 10時,P = 54.1%。
由于獨立優(yōu)化字符切分提升空間有限,因此有相關(guān)方法試圖聯(lián)合優(yōu)化切分和識別兩個任務。現(xiàn)有技術(shù)主要可分為基于切分的方法(Segmentation-Based)和不依賴切分的方法(Segmentation-Free)兩類方法。
基于切分的方法
該類方法還是保留主動切分的步驟,但引入了動態(tài)合并機制,通過識別置信度等信息來指導切分,如圖5所示。
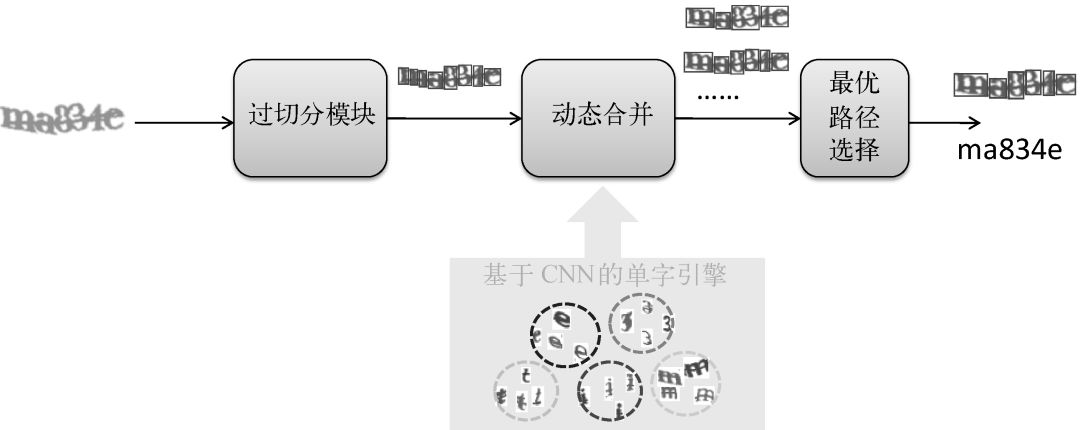
過切分模塊將文字行在垂直于基線方向上分割成碎片,使得其中每個碎片至多包含一個字符。通常來說,過切分模塊會將字符分割為多個連續(xù)筆劃。過切分可以采用基于規(guī)則或機器學習的方法。規(guī)則方法主要是直接在圖像二值化的結(jié)果上進行連通域分析和投影分析來確定候補切點位置,通過調(diào)整參數(shù)可以控制粒度來使得字符盡可能被切碎。基于規(guī)則的方法實現(xiàn)簡單,但在成像/背景復雜的條件下其效果不好。機器學習方法通過離線訓練鑒別切點的二類分類器,然后基于該分類器在文字行圖像上進行滑窗檢測。
動態(tài)合并模塊將相鄰的筆劃根據(jù)識別結(jié)果組合成可能的字符區(qū)域,最優(yōu)組合方式即對應最佳切分路徑和識別結(jié)果。直觀來看,尋找最優(yōu)組合方式可轉(zhuǎn)換為路徑搜索問題,對應有深度優(yōu)先和廣度優(yōu)先兩種搜索策略。深度優(yōu)先策略在每一步選擇擴展當前最優(yōu)的狀態(tài),因此全局來看它是次優(yōu)策略,不適合過長的文字行。廣度優(yōu)先策略在每一步會對當前多個狀態(tài)同時進行擴展,比如在語音識別領(lǐng)域廣泛應用的Viterbi解碼和Beam Search。但考慮到性能,Beam Search通常會引入剪枝操作來控制路徑長度,剪枝策略包含限制擴展的狀態(tài)數(shù)(比如,每一步只擴展TopN的狀態(tài))和加入狀態(tài)約束(比如,合并后字符形狀)等。
由于動態(tài)合并會產(chǎn)生多個候選路徑,所以需要設(shè)計合適的評價函數(shù)來進行路徑選擇。評價函數(shù)的設(shè)計主要從路徑結(jié)構(gòu)損失和路徑識別打分兩方面出發(fā)。路徑結(jié)構(gòu)損失主要從字符形狀特征方面衡量切分路徑的合理性,路徑識別打分則對應于特定切分路徑下的單字平均識別置信度和語言模型分。
該方案試圖將字符切分和單字符識別融合在同一個框架下解決,但由于過分割是獨立的步驟,因此沒有從本質(zhì)上實現(xiàn)端到端學習。
不依賴切分的方法
該類方法完全跨越了字符切分,通過滑動窗口或序列建模直接對文字行進行識別。
滑窗識別借鑒了滑動窗口檢測的思路,基于離線訓練的單字識別引擎,對文字行圖像從左到右進行多尺度掃描,以特定窗口為中心進行識別。在路徑?jīng)Q策上可采用貪心策略或非極大值抑制(NMS)策略來得到最終的識別路徑。圖6給出了滑窗識別的示意流程。可見滑窗識別存在兩個問題:滑動步長的粒度過細則計算代價大,過粗則上下文信息易丟失;無論采用何種路徑?jīng)Q策方案,它們對單字識別的置信度依賴較高。
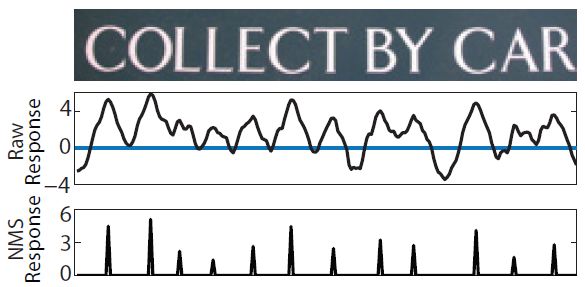
序列學習起源于手寫識別、語音識別領(lǐng)域,因為這類問題的共同特點是需要對時序數(shù)據(jù)進行建模。盡管文字行圖像是二維的,但如果把從左到右的掃描動作類比為時序,文字行識別從本質(zhì)上也可歸為這類問題。通過端到端的學習,摒棄矯正/切分/字符識別等中間步驟,以此提升序列學習的效果,這已經(jīng)成為當前研究的熱點。
基于現(xiàn)有技術(shù)和美團業(yè)務涉及的OCR場景,我們在文字檢測和文字行識別采用如圖7所示的深度學習框架。
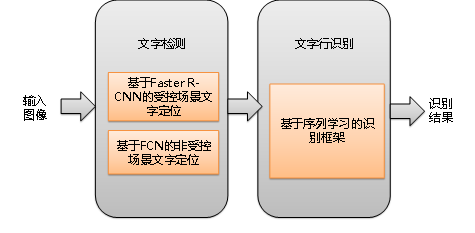
后面將分別介紹文字檢測和文字行識別這兩部分的具體方案。
基于深度學習的文字檢測
對于美團的OCR場景,根據(jù)版面是否有先驗信息(卡片的矩形區(qū)域、證件的關(guān)鍵字段標識)以及文字自身的復雜性(如水平文字、多角度),圖像可劃分為受控場景(如身份證、營業(yè)執(zhí)照、銀行卡)和非受控場景(如菜單、門頭圖),如圖8所示。

考慮到這兩類場景的特點不同,我們借鑒不同的檢測框架。由于受控場景文字諸多約束條件可將問題簡化,因此利用在通用目標檢測領(lǐng)域廣泛應用的Faster R-CNN框架進行檢測。而對于非受控場景文字,由于形變和筆畫寬度不一致等原因,目標輪廓不具備良好的閉合邊界,我們需要借助圖像語義分割來標記文字區(qū)域與背景區(qū)域。
1. 受控場景的文字檢測
對于受控場景(如身份證),我們將文字檢測轉(zhuǎn)換為對關(guān)鍵字目標(如姓名、身份證號、地址)或關(guān)鍵條目(如銀行卡號)的檢測問題。基于Faster R-CNN的關(guān)鍵字檢測流程如圖9所示。為了保證回歸框的定位精度,同時提升運算速度,我們對原有框架和訓練方式進行了微調(diào)。
考慮到關(guān)鍵字或關(guān)鍵條目的類內(nèi)變化有限,網(wǎng)絡(luò)結(jié)構(gòu)只采用了3個卷積層。
訓練過程中提高正樣本的重疊率閾值。
根據(jù)關(guān)鍵字或關(guān)鍵條目的寬高比范圍來適配RPN層Anchor的寬高比。
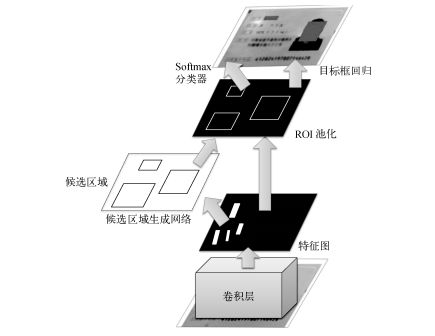
Faster R-CNN框架由RPN(候選區(qū)域生成網(wǎng)絡(luò))和RCN(區(qū)域分類網(wǎng)絡(luò))兩個子網(wǎng)絡(luò)組成。RPN通過監(jiān)督學習的方法提取候選區(qū)域,給出的是無標簽的區(qū)域和粗定位結(jié)果。RCN引入類別概念,同時進行候選區(qū)域的分類和位置回歸,給出精細定位結(jié)果。訓練時兩個子網(wǎng)絡(luò)通過端到端的方式聯(lián)合優(yōu)化。圖10以銀行卡卡號識別為例,給出了RPN層和RCN層的輸出。

對于人手持證件場景,由于證件目標在圖像中所占比例過小,直接提取微小候選目標會導致一定的定位精度損失。為了保證高召回和高定位精度,可采用由粗到精的策略進行檢測。首先定位卡片所在區(qū)域位置,然后在卡片區(qū)域范圍內(nèi)進行關(guān)鍵字檢測,而區(qū)域定位也可采用Faster R-CNN框架,如圖11所示。
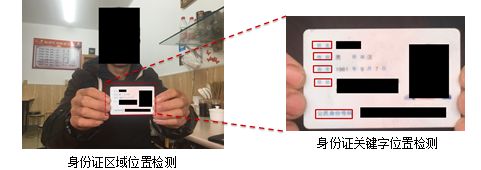
圖11 由粗到精的檢測策略
2. 非受控場景的文字檢測
對于菜單、門頭圖等非受控場景,由于文字行本身的多角度且字符的筆畫寬度變化大,該場景下的文字行定位任務挑戰(zhàn)很大。由于通用目標檢測方法的定位粒度是回歸框級,此方法適用于剛體這類有良好閉合邊界的物體。然而文字往往由一系列松散的筆畫構(gòu)成,尤其對于任意方向或筆畫寬度的文字,僅以回歸框結(jié)果作為定位結(jié)果會有較大偏差。另外剛體檢測的要求相對較低,即便只定位到部分主體(如定位結(jié)果與真值的重疊率是50%),也不會對剛體識別產(chǎn)生重大影響,而這樣的定位誤差對于文字識別則很可能是致命的。
為了實現(xiàn)足夠精細的定位,我們利用語義分割中常用的全卷積網(wǎng)絡(luò)(FCN)來進行像素級別的文字/背景標注,整體流程如圖12所示。
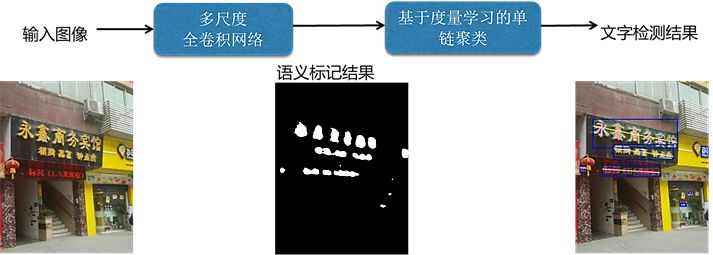
多尺度全卷積網(wǎng)絡(luò)通過對多個階段的反卷積結(jié)果的融合,實現(xiàn)了全局特征和局部特征的聯(lián)合,進而達到了由粗到精的像素級別標注,適應于任意非受控場景(門頭圖、菜單圖片)。
基于多尺度全卷積網(wǎng)絡(luò)得到的像素級標注,通過連通域分析技術(shù)可得到一系列連通區(qū)域(筆劃信息)。但由于無法確定哪些連通域?qū)儆谕晃淖中校虼诵枰柚鷨捂溇垲惣夹g(shù)來進行文字行提取。至于聚類涉及的距離度量,主要從連通域間的距離、形狀、顏色的相似度等方面提取特征,并通過度量學習自適應地得到特征權(quán)重和閾值,如圖13所示。
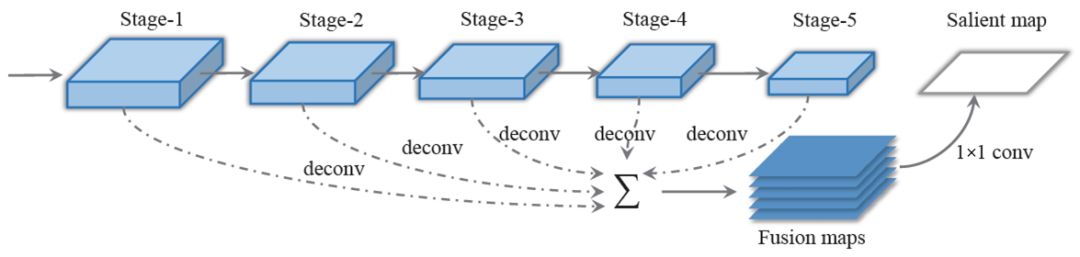
圖14分別給出了在菜單和門頭圖場景中的全卷積網(wǎng)絡(luò)定位效果。第二列為全卷積網(wǎng)絡(luò)的像素級標注結(jié)果,第三列為最終文字檢測結(jié)果。可以看出,全卷積網(wǎng)絡(luò)可以較好地應對復雜版面或多角度文字定位。

基于序列學習的文字識別
我們將整行文字識別問題歸結(jié)為一個序列學習問題。利用基于雙向長短期記憶神經(jīng)網(wǎng)絡(luò)(Bi-directional Long Short-term Memory,BLSTM)的遞歸神經(jīng)網(wǎng)絡(luò)作為序列學習器,來有效建模序列內(nèi)部關(guān)系。為了引入更有效的輸入特征,我們采用卷積神經(jīng)網(wǎng)絡(luò)模型來進行特征提取,以描述圖像的高層語義。此外在損失函數(shù)的設(shè)計方面,考慮到輸出序列與輸入特征幀序列無法對齊,我們直接使用結(jié)構(gòu)化的Loss(序列對序列的損失),另外引入了背景(Blank)類別以吸收相鄰字符的混淆性。
整體網(wǎng)絡(luò)結(jié)構(gòu)分為三層:卷積層、遞歸層和翻譯層,如圖15所示。其中卷積層提取特征;遞歸層既學習特征序列中字符特征的先后關(guān)系,又學習字符的先后關(guān)系;翻譯層實現(xiàn)對時間序列分類結(jié)果的解碼。
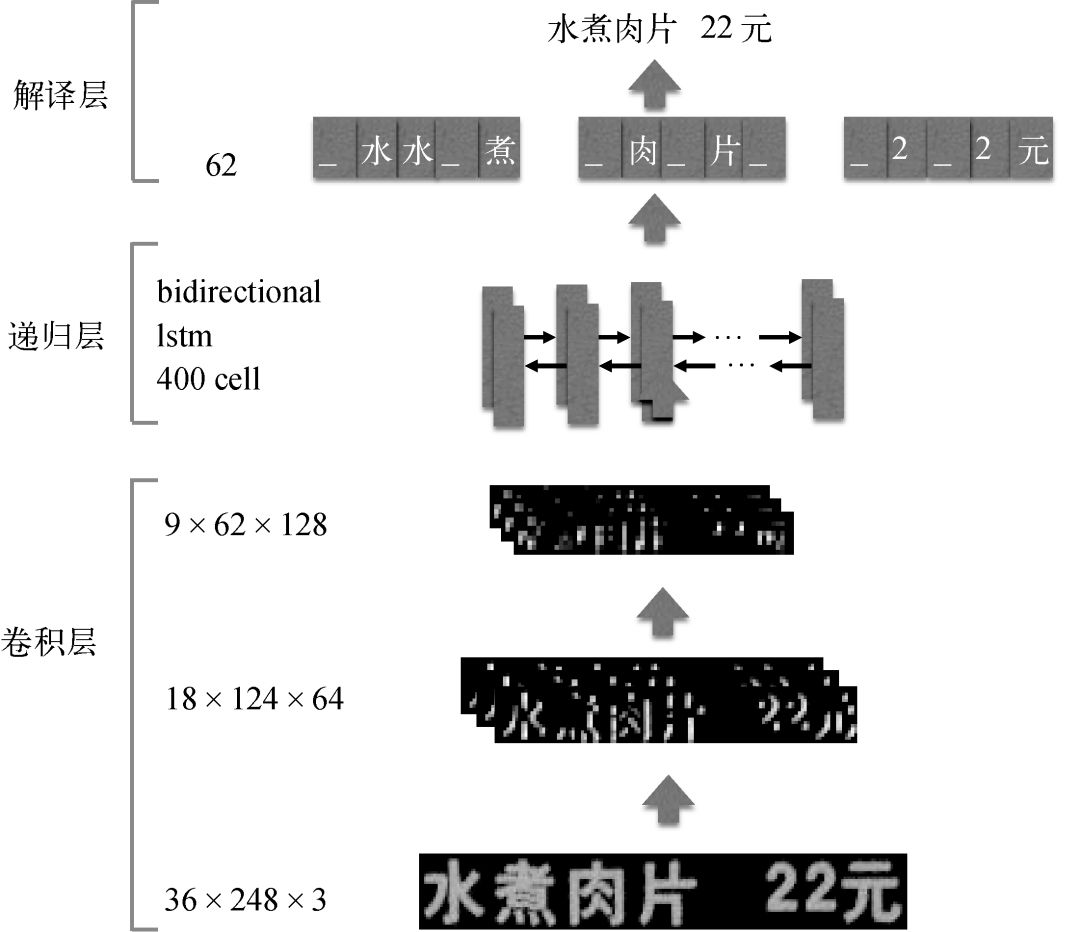
對于輸入的固定高度h0= 36的圖像(寬度任意,如W0 = 248),我們通過CNN網(wǎng)絡(luò)結(jié)構(gòu)提取特征,得到9×62×128的特征圖,可將其看作一個長度為62的時間序列輸入到RNN層。RNN層有400個隱藏節(jié)點,其中每個隱藏節(jié)點的輸入是9×128維的特征,是對圖像局部區(qū)域的描述。考慮到對應于某個時刻特征的圖像區(qū)域,它與其前后內(nèi)容都具有較強的相關(guān)性,所以我們一般采用雙向RNN網(wǎng)絡(luò),如圖16所示。
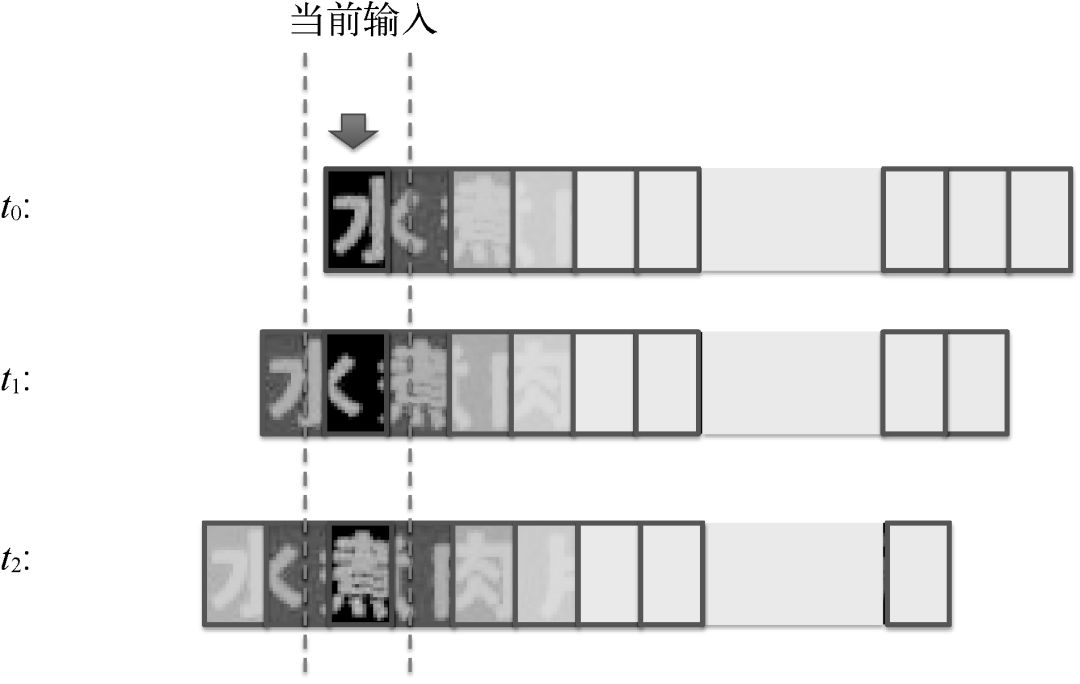
雙向RNN后接一個全連接層,輸入為RNN層(在某個時刻)輸出的特征圖,輸出為該位置是背景、字符表中文字的概率。全連接層后接CTC(聯(lián)結(jié)主義時間分類器)作為損失函數(shù)。在訓練時,根據(jù)每個時刻對應的文字、背景概率分布,得到真值字符串在圖像中出現(xiàn)的概率P(ground truth),將-log(P(ground truth))作為損失函數(shù)。在測試時,CTC可以看作一個解碼器,將每一時刻的預測結(jié)果(當前時刻的最大后驗概率對應的字符)聯(lián)合起來,然后去掉空白和重復的模式,就形成了最終的序列預測結(jié)果,如圖17所示。
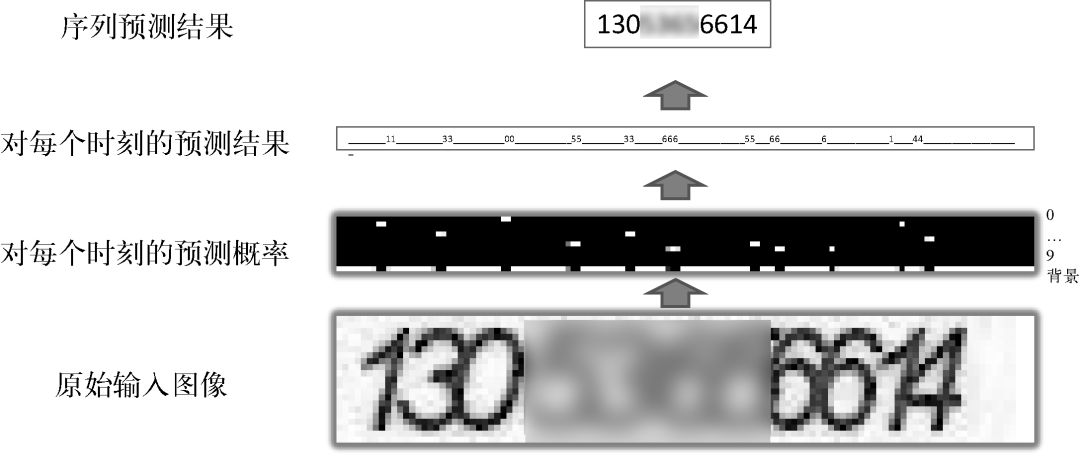
從圖17中也可以看出,對應輸入序列中的每個字符,LSTM輸出層都會產(chǎn)生明顯的尖峰,盡管該尖峰未必對應字符的中心位置。換句話說,引入CTC機制后,我們不需要考慮每個字符出現(xiàn)的具體位置,只需關(guān)注整個圖像序列對應的文字內(nèi)容,最終實現(xiàn)深度學習的端到端訓練與預測。
由于序列學習框架對訓練樣本的數(shù)量和分布要求較高,我們采用了真實樣本+合成樣本的方式。真實樣本以美團業(yè)務來源(例如,菜單、身份證、營業(yè)執(zhí)照)為主,合成樣本則考慮了字體、形變、模糊、噪聲、背景等因素。
基于上述序列學習框架,我們給出了在不同場景下的文字行識別結(jié)果,如圖18所示。其中前兩行的圖片為驗證碼場景,第三行為銀行卡,第四行為資質(zhì)證件,第五行為門頭圖,第六行為菜單。可以看到,識別模型對于文字形變、粘連、成像的模糊和光線變化、背景的復雜等都有較好的健壯性。

基于上述試驗,與傳統(tǒng)OCR相比,我們在多種場景的文字識別上都有較大幅度的性能提升,如圖19所示。
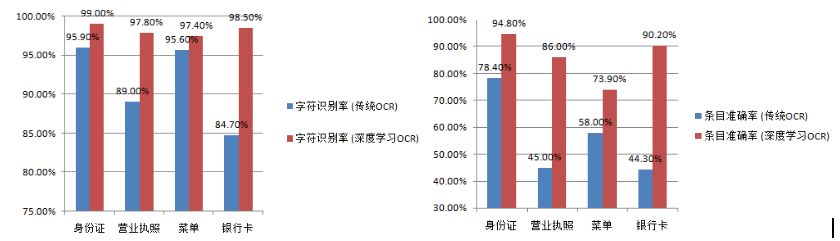
與傳統(tǒng)OCR相比,基于深度學習的OCR在識別率方面有了大幅上升。但對于特定的應用場景(營業(yè)執(zhí)照、菜單、銀行卡等),條目準確率還有待提升。一方面需要融合基于深度學習的文字檢測與傳統(tǒng)版面分析技術(shù),以進一步提升限制場景下的檢測性能。另一方面需要豐富真實訓練樣本和語言模型,以提升文字識別準確率。
原文鏈接:https://kuaibao.qq.com/s/20180915A05FQO00?refer=cp_1026
機器學習算法AI大數(shù)據(jù)技術(shù)
搜索公眾號添加: datanlp
長按圖片,識別二維碼
閱讀過本文的人還看了以下文章:
基于40萬表格數(shù)據(jù)集TableBank,用MaskRCNN做表格檢測
《深度學習入門:基于Python的理論與實現(xiàn)》高清中文PDF+源碼
python就業(yè)班學習視頻,從入門到實戰(zhàn)項目
2019最新《PyTorch自然語言處理》英、中文版PDF+源碼
《21個項目玩轉(zhuǎn)深度學習:基于TensorFlow的實踐詳解》完整版PDF+附書代碼
PyTorch深度學習快速實戰(zhàn)入門《pytorch-handbook》
【下載】豆瓣評分8.1,《機器學習實戰(zhàn):基于Scikit-Learn和TensorFlow》
《Python數(shù)據(jù)分析與挖掘?qū)崙?zhàn)》PDF+完整源碼
汽車行業(yè)完整知識圖譜項目實戰(zhàn)視頻(全23課)
李沐大神開源《動手學深度學習》,加州伯克利深度學習(2019春)教材
筆記、代碼清晰易懂!李航《統(tǒng)計學習方法》最新資源全套!
《神經(jīng)網(wǎng)絡(luò)與深度學習》最新2018版中英PDF+源碼
重要開源!CNN-RNN-CTC 實現(xiàn)手寫漢字識別
【Keras】完整實現(xiàn)‘交通標志’分類、‘票據(jù)’分類兩個項目,讓你掌握深度學習圖像分類
VGG16遷移學習,實現(xiàn)醫(yī)學圖像識別分類工程項目
特征工程(二) :文本數(shù)據(jù)的展開、過濾和分塊
如何利用全新的決策樹集成級聯(lián)結(jié)構(gòu)gcForest做特征工程并打分?
Machine Learning Yearning 中文翻譯稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在線識別手寫中文網(wǎng)站
中科院Kaggle全球文本匹配競賽華人第1名團隊-深度學習與特征工程
不斷更新資源
深度學習、機器學習、數(shù)據(jù)分析、python
搜索公眾號添加: datayx