
【機(jī)器學(xué)習(xí)】圖解 72 個(gè)機(jī)器學(xué)習(xí)基礎(chǔ)知識(shí)點(diǎn)
1. 機(jī)器學(xué)習(xí)概述
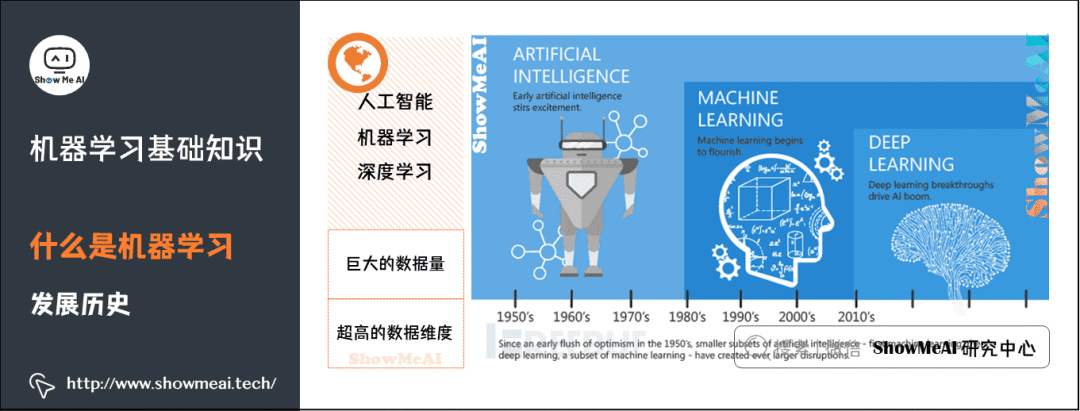
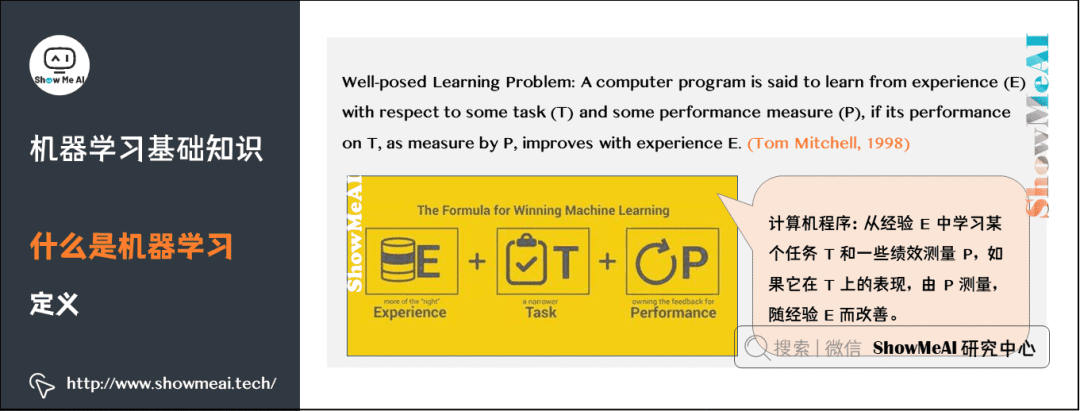
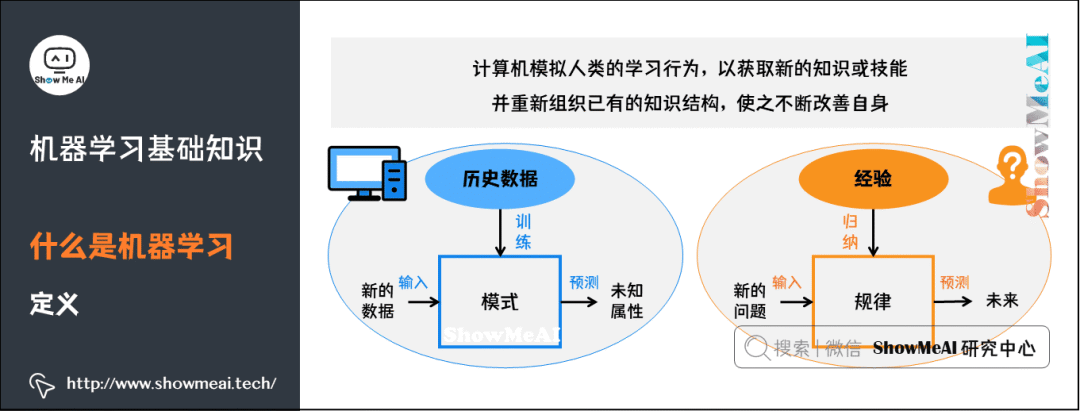
1)什么是機(jī)器學(xué)習(xí)

2)機(jī)器學(xué)習(xí)三要素
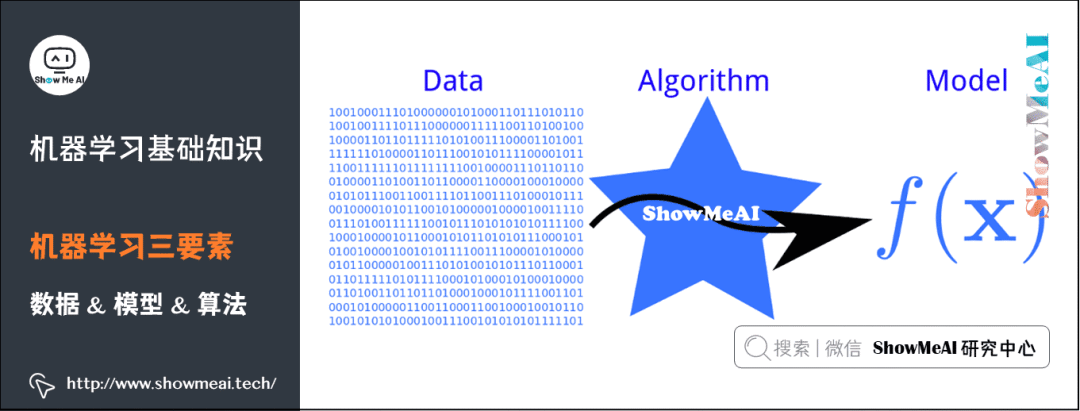
(1)數(shù)據(jù)

(2)模型&算法

3)機(jī)器學(xué)習(xí)發(fā)展歷程
4)機(jī)器學(xué)習(xí)核心技術(shù)
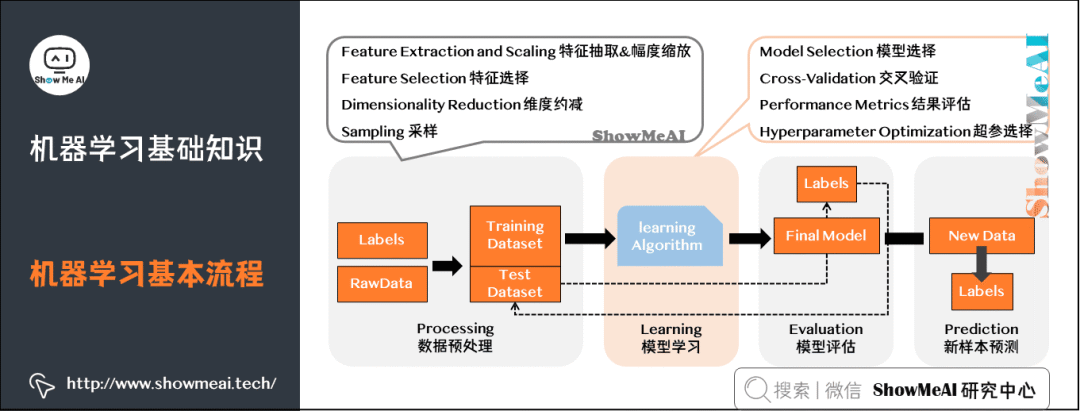
5)機(jī)器學(xué)習(xí)基本流程
6)機(jī)器學(xué)習(xí)應(yīng)用場(chǎng)景

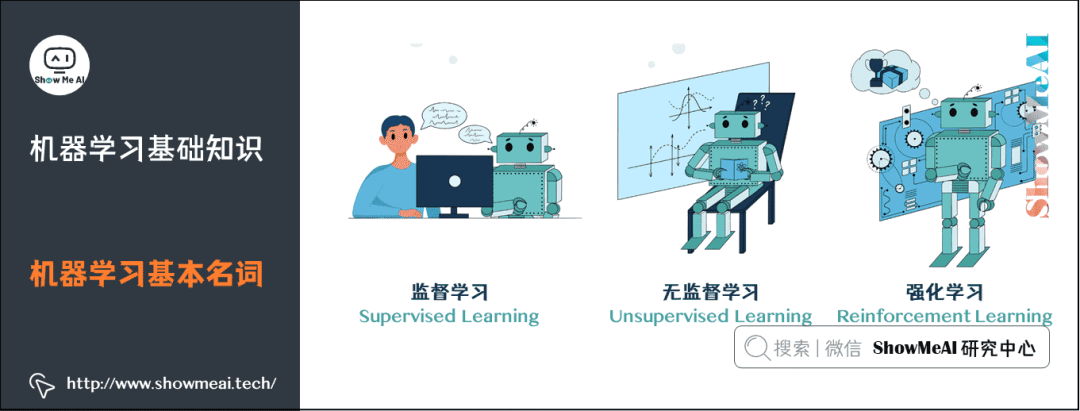
2.機(jī)器學(xué)習(xí)基本名詞
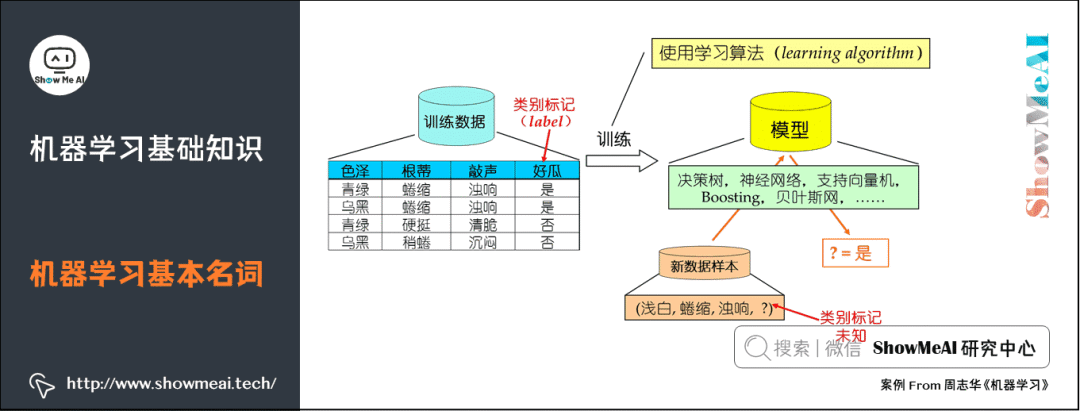
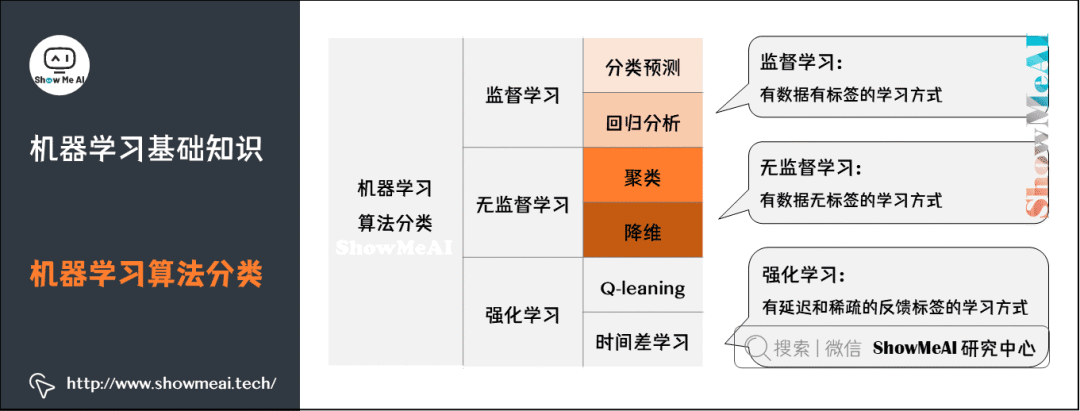
3.機(jī)器學(xué)習(xí)算法分類
1)機(jī)器學(xué)習(xí)算法依托的問(wèn)題場(chǎng)景

更多監(jiān)督學(xué)習(xí)的算法模型總結(jié),可以查看ShowMeAI的文章 AI知識(shí)技能速查 | 機(jī)器學(xué)習(xí)-監(jiān)督學(xué)習(xí)(公眾號(hào)不能跳轉(zhuǎn),本文鏈接見(jiàn)文末)。
更多無(wú)監(jiān)督學(xué)習(xí)的算法模型總結(jié)可以查看ShowMeAI的文章 AI知識(shí)技能速查 | 機(jī)器學(xué)習(xí)-無(wú)監(jiān)督學(xué)習(xí)。
2)分類問(wèn)題
了解更多機(jī)器學(xué)習(xí)分類算法:KNN算法、邏輯回歸算法、樸素貝葉斯算法、決策樹(shù)模型、隨機(jī)森林分類模型、GBDT模型、XGBoost模型、支持向量機(jī)模型等。(公眾號(hào)不能跳轉(zhuǎn),本文鏈接見(jiàn)文末)
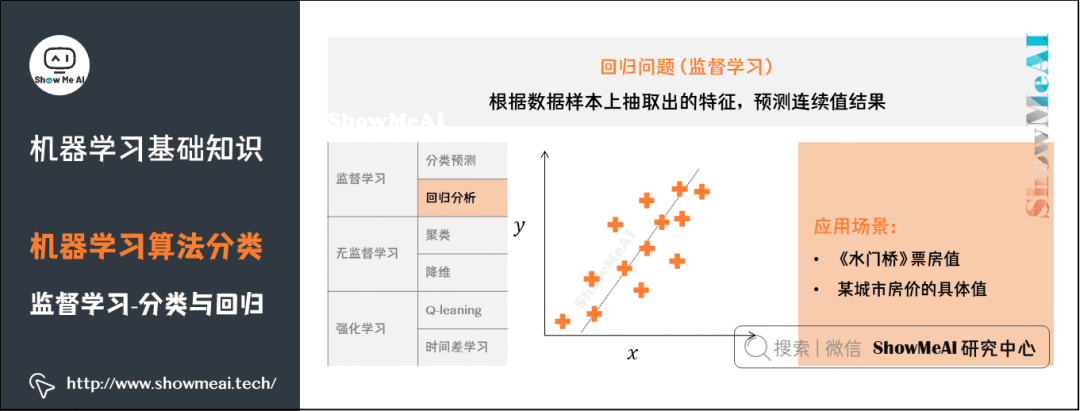
3)回歸問(wèn)題
了解更多機(jī)器學(xué)習(xí)回歸算法:決策樹(shù)模型、隨機(jī)森林分類模型、GBDT模型、回歸樹(shù)模型、支持向量機(jī)模型等。
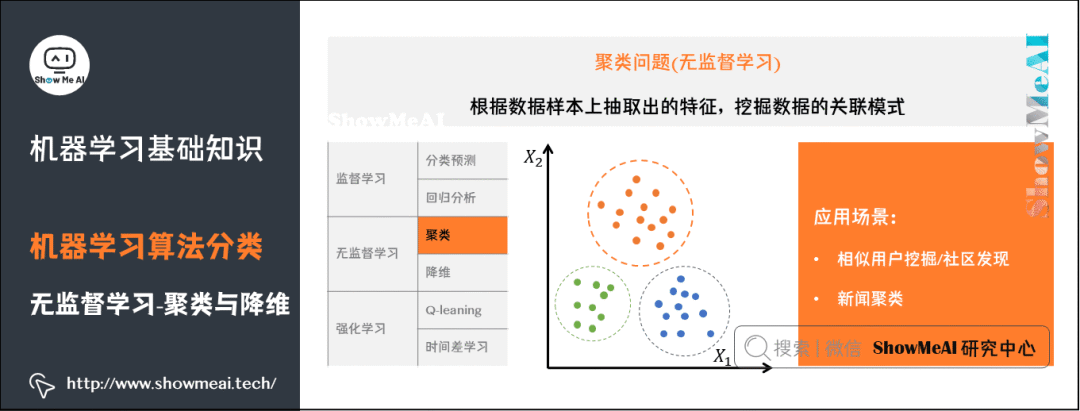
4)聚類問(wèn)題
了解更多機(jī)器學(xué)習(xí)聚類算法:聚類算法。
5)降維問(wèn)題
了解更多機(jī)器學(xué)習(xí)降維算法:PCA降維算法。

4.機(jī)器學(xué)習(xí)模型評(píng)估與選擇
1)機(jī)器學(xué)習(xí)與數(shù)據(jù)擬合
2)訓(xùn)練集與數(shù)據(jù)集
3)經(jīng)驗(yàn)誤差
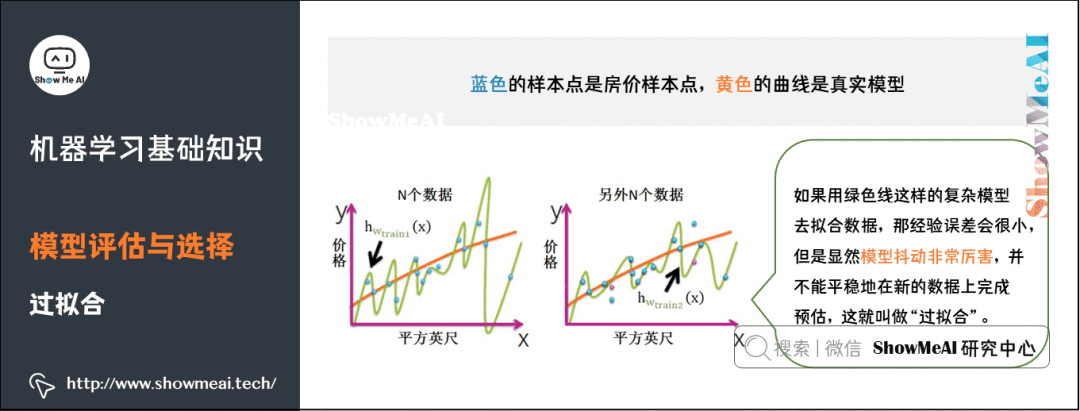
4)過(guò)擬合
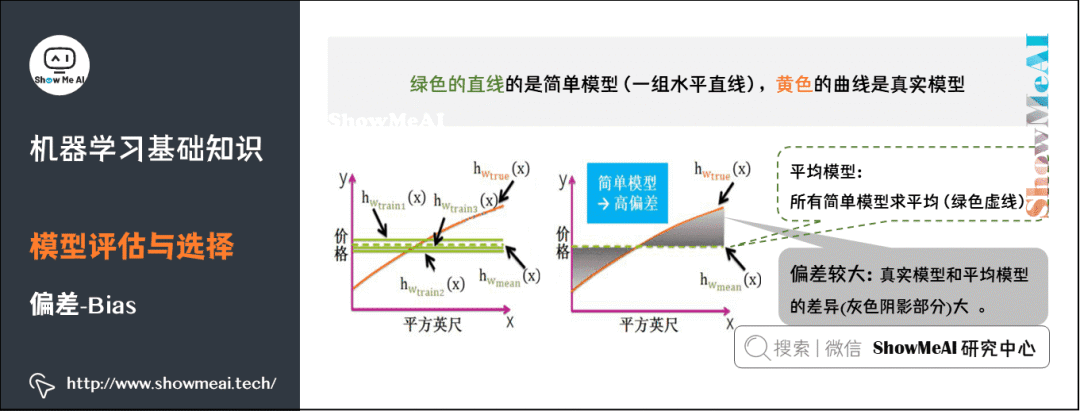
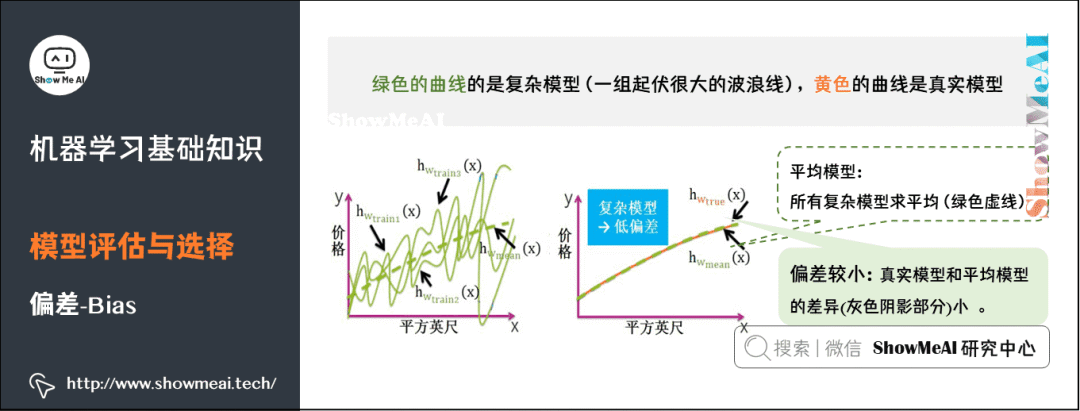
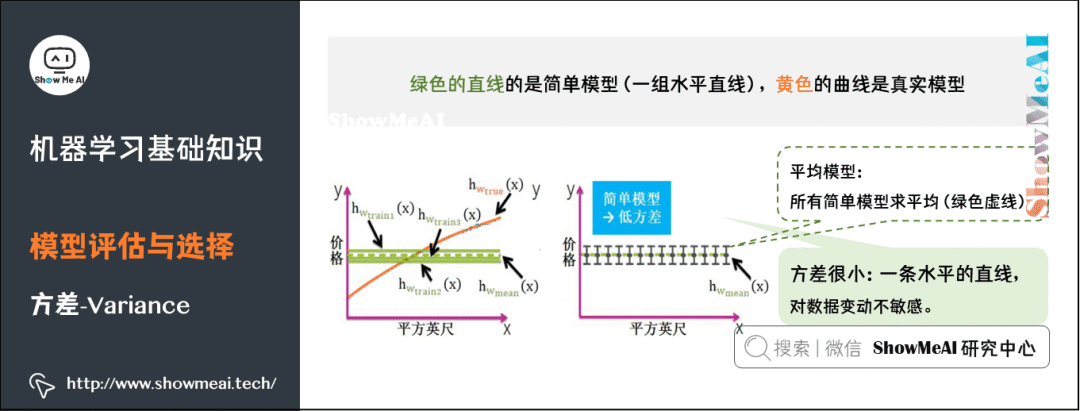
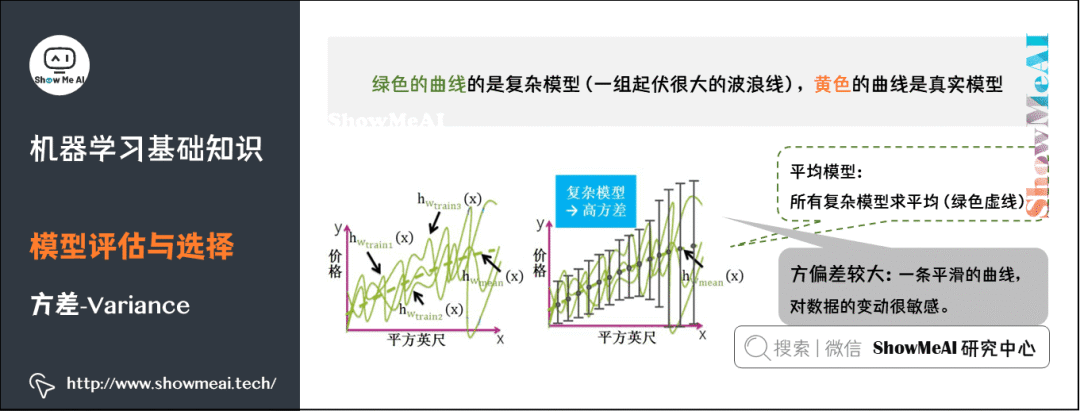
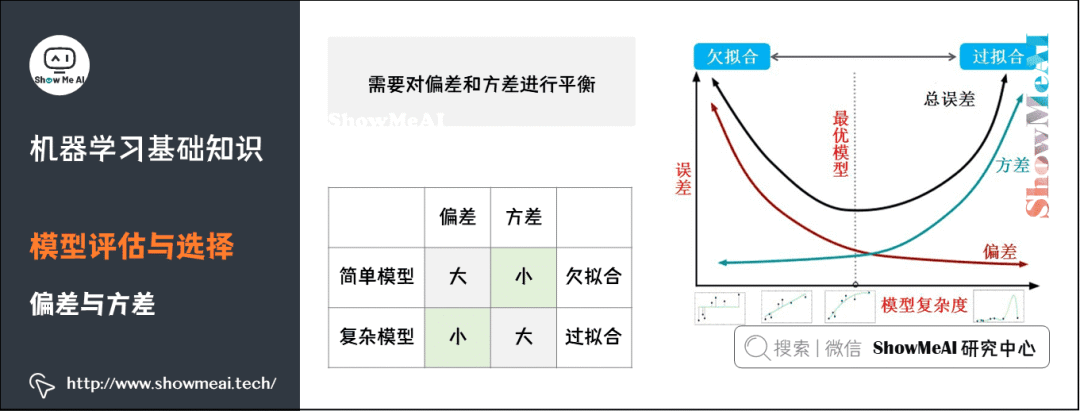
5)偏差
8)性能度量指標(biāo)
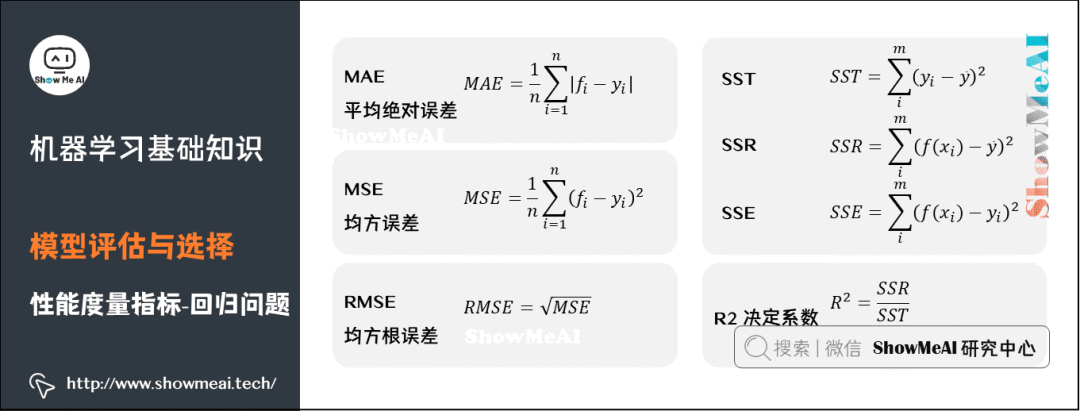
(1)回歸問(wèn)題
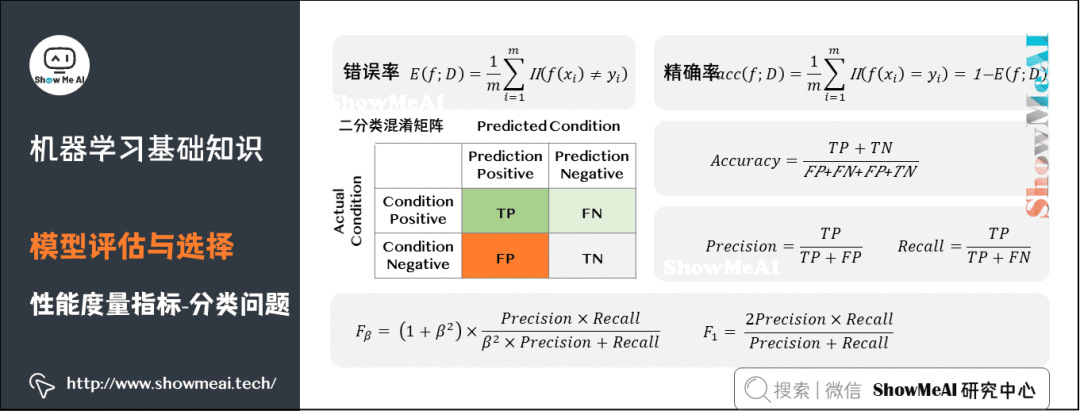
(2)分類問(wèn)題
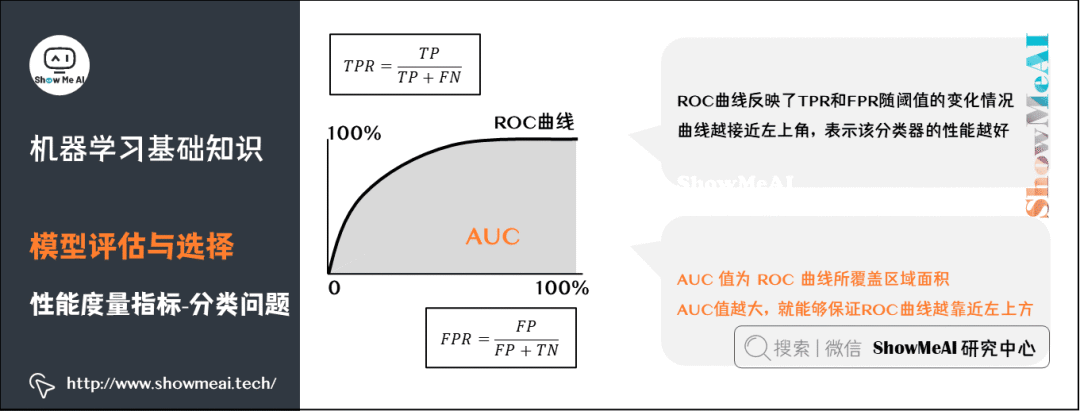
從一個(gè)比較高的角度來(lái)認(rèn)識(shí)AUC:仍然以異常用戶的識(shí)別為例,高的AUC值意味著,模型在能夠盡可能多地識(shí)別異常用戶的情況下,仍然對(duì)正常用戶有著一個(gè)較低的誤判率(不會(huì)因?yàn)闉榱俗R(shí)別異常用戶,而將大量的正常用戶給誤判為異常。
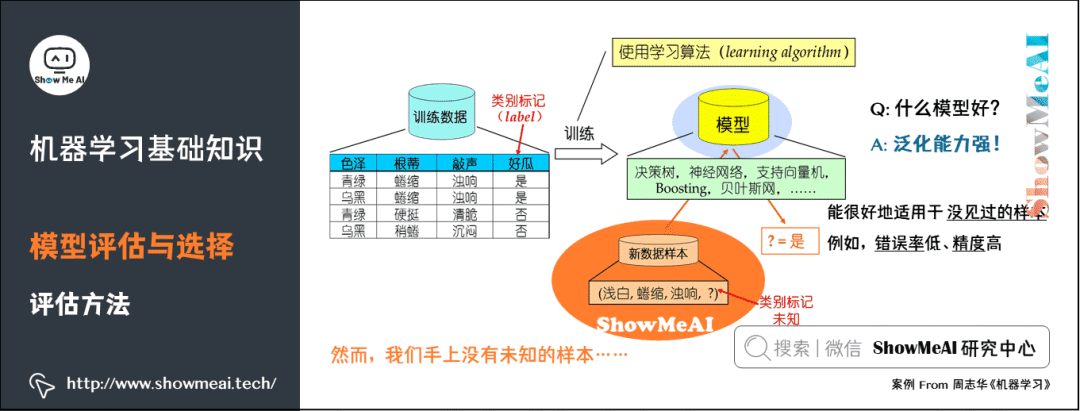
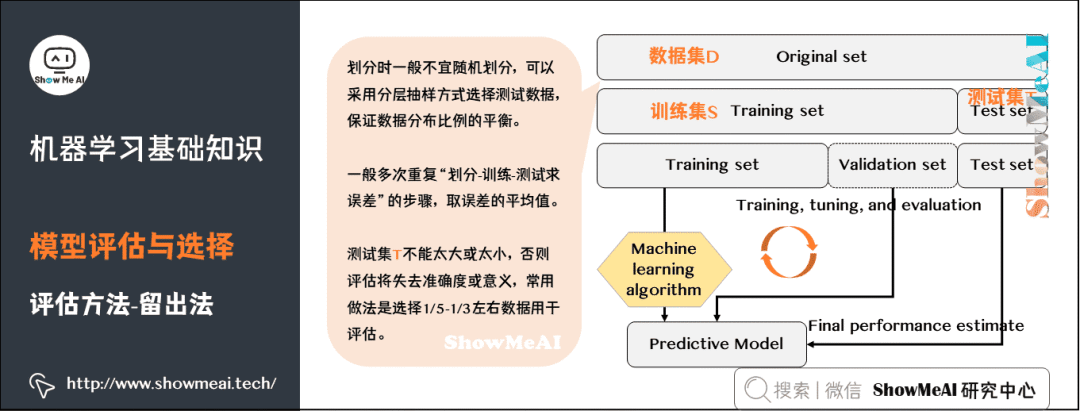
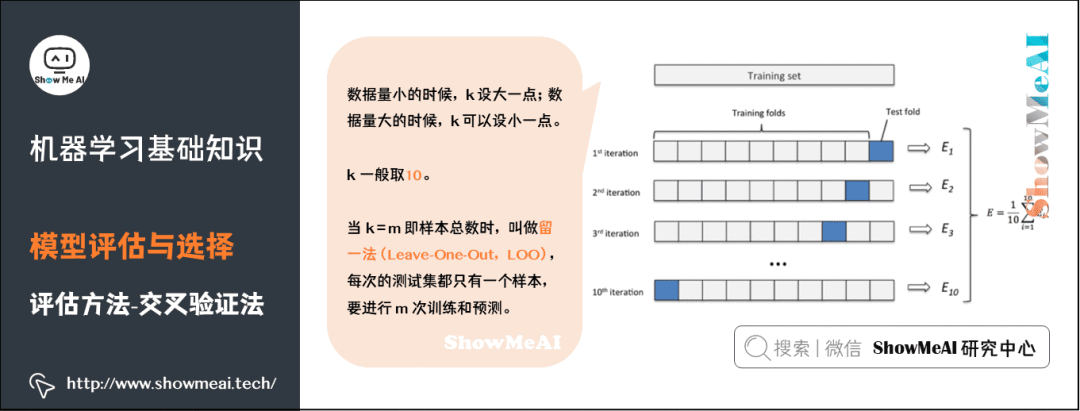
9)評(píng)估方法

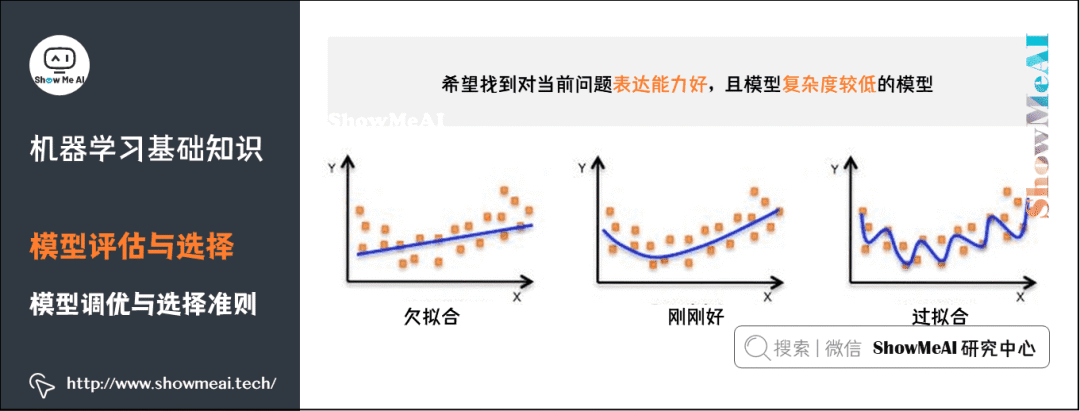
10)模型調(diào)優(yōu)與選擇準(zhǔn)則
表達(dá)力好的模型,可以較好地對(duì)訓(xùn)練數(shù)據(jù)中的規(guī)律和模式進(jìn)行學(xué)習(xí);
-
復(fù)雜度低的模型,方差較小,不容易過(guò)擬合,有較好的泛化表達(dá)。
11)如何選擇最優(yōu)的模型
(1)驗(yàn)證集評(píng)估選擇
切分?jǐn)?shù)據(jù)為訓(xùn)練集和驗(yàn)證集。
對(duì)于準(zhǔn)備好的候選超參數(shù),在訓(xùn)練集上進(jìn)行模型,在驗(yàn)證集上評(píng)估。
(2)網(wǎng)格搜索/隨機(jī)搜索交叉驗(yàn)證
通過(guò)網(wǎng)格搜索/隨機(jī)搜索產(chǎn)出候選的超參數(shù)組。
對(duì)參數(shù)組的每一組超參數(shù),使用交叉驗(yàn)證評(píng)估效果。
選出效果最好的超參數(shù)。
(3)貝葉斯優(yōu)化
-
基于貝葉斯優(yōu)化的超參數(shù)調(diào)優(yōu)。
往期精彩回顧
-
適合初學(xué)者入門人工智能的路線及資料下載
-
(圖文+視頻)機(jī)器學(xué)習(xí)入門系列下載
-
機(jī)器學(xué)習(xí)及深度學(xué)習(xí)筆記等資料打印
-
《統(tǒng)計(jì)學(xué)習(xí)方法》的代碼復(fù)現(xiàn)專輯
機(jī)器學(xué)習(xí)交流qq群772479961,加入微信群請(qǐng)掃碼
評(píng)論
圖片
表情