
實操教程|yolov5模型部署落地:Nvidia Jetson TX2使用TensorRT部署yolov5s模型

極市導(dǎo)讀
本篇教程將主要討論如何利用TensorRT來在TX2端實際部署模型并在前向推理階段進行加速,也是系列教程中最為重要、最少資料的模型落地部分。 >>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿
一、TensorRT是什么?
TensorRT 是由 Nvidia 推出的 GPU 推理引擎(GIE: GPU Inference Engine)。和通用的深度學(xué)習(xí)框架不同,TensorRT 只提供前向傳播,即推理的功能,而沒有訓(xùn)練的功能。實際上,訓(xùn)練的場景下,資源通常不會特別緊張,因為是離線的操作(不要求實時反饋),即使出現(xiàn)了一時的資源不足也可以通過增加計算時長來彌補,所以訓(xùn)練框架的資源消耗一般不會有很強的優(yōu)化。而網(wǎng)絡(luò)的部署通常對資源更加敏感,算力與內(nèi)存都是需要考慮的因素。TensorRT 是一個旨在極致優(yōu)化 GPU 資源使用的深度學(xué)習(xí)推理計算框架。其工作主要分為兩個階段:建造階段(build phase)和執(zhí)行階段(compile phase)。
在建造階段,TensorRT 接收外部提供的網(wǎng)絡(luò)定義(也可包含權(quán)值 weights)和超參數(shù),根據(jù)當前編譯的設(shè)備進行網(wǎng)絡(luò)運行的優(yōu)化(optimization), 并生成推理引擎 inference engine(可以以 PLAN 形式存在在硬盤上);
在執(zhí)行階段,通過運行推理引擎調(diào)用 GPU 計算資源——整個流程如下所示:
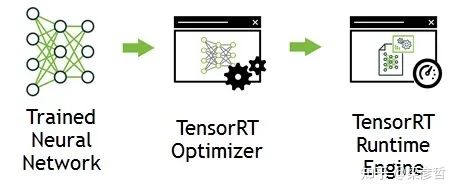
二、為什么要使用TensorRT
1.滿足實時性要求
使用TensorRT加速推理是嵌入式AI非常重要的一環(huán)。具體來說以我自己1660Ti筆記本跑模型尚且不能達到滿足要求的幀率,更別指望TX2有多好的效果。經(jīng)實際測試,TX2端TensorRT加速后可至40幀左右,滿足實時性要求。
2.TX2環(huán)境限制(關(guān)鍵!)
以最新的TX2刷機包Jetpack4.5.1為例,其封裝好的CUDA版本為10.0,而我使用的yolov5 4.0版本需CUDA11.0,且yolov5所依賴的某些依賴尚無支持arm架構(gòu)的版本,在TX2上直接跑yolov5是根本不可能的!必須使用TensorRT API對網(wǎng)絡(luò)進行“復(fù)現(xiàn)”。
三、如何使用TensorRT
1.前期準備與說明
使用TensorRT的過程,實際就是在其API下復(fù)現(xiàn)yolov5的過程。對于任意一個已訓(xùn)練好的神經(jīng)網(wǎng)絡(luò),我們需要得知其網(wǎng)絡(luò)結(jié)構(gòu)(backbone, neck等)與訓(xùn)練權(quán)重。訓(xùn)練權(quán)重已由系列教程的第二篇中得到,網(wǎng)絡(luò)結(jié)構(gòu)的獲取方法主要有以下幾種:1.使用TF-TRT,將TensorRT集成在TensorFlow中 2.使用ONNX2TensorRT,即ONNX轉(zhuǎn)換trt的工具 3.手動構(gòu)造模型結(jié)構(gòu),然后手動將權(quán)重信息挪過去,非常靈活但是時間成本略高,有大佬已經(jīng)嘗試過了:tensorrtx 其中前兩種常常會有遇到不支持的結(jié)構(gòu)/層的情況,解決該問題非常費時。而使用TensorRT API手動構(gòu)造模型結(jié)構(gòu)是最為穩(wěn)妥、對模型還原度最高、精度損失最少的一種方法。萬幸有dalao已將此開源,在此列出項目鏈接并表示感謝!
wang-xinyu/tensorrtxgithub.com
可以看到該項目除支持yolov5外,resnet, yolov3, yolov4等均支持,如果使用其他網(wǎng)絡(luò)結(jié)構(gòu)的同學(xué)也可以加以利用。
2. 使用流程
下載好該項目的項目的源碼后,我們僅需要用到其中yolov5的子文件夾,其他為無關(guān)項。下載過程中要注意所下載的tensorrtx版本應(yīng)與所選用的yolov5版本相匹配。
2.1 權(quán)重轉(zhuǎn)換
打開gen_wts.py文件,修改對應(yīng)權(quán)重路徑
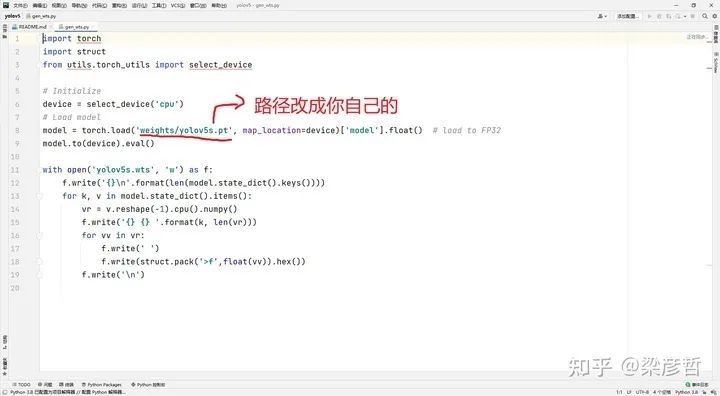
此步將會得到wts格式的yolov5權(quán)重,以供下一步生成engine文件
2.2 生成TensorRT Engine
// put yolov5s.wts into tensorrtx/yolov5// go to tensorrtx/yolov5// update CLASS_NUM in yololayer.h if your model is trained on custom dataset//注意在yololayer.h中改類別數(shù)!!mkdir buildcd buildcmake ..make //編譯完成//由wts生成engine文件sudo ./yolov5 -s [.wts] [.engine] [s/m/l/x or c gd gw] // serialize model to plan file//利用engine文件進行推理,此處輸入圖片所在文件夾,即可得到預(yù)測輸出sudo ./yolov5 -d [.engine] [image folder] // deserialize and run inference, the images in [image folder] will be processed.// For example yolov5ssudo ./yolov5 -s yolov5s.wts yolov5s.engine ssudo ./yolov5 -d yolov5s.engine ../samples// For example Custom model with depth_multiple=0.17, width_multiple=0.25 in yolov5.yamlsudo ./yolov5 -s yolov5_custom.wts yolov5.engine c 0.17 0.25sudo ./yolov5 -d yolov5.engine ../samples
四、效果評估 如下是我在TX2端的實測視頻
五、后續(xù)說明
1.得到engine文件后即可進行推理,但默認輸入是圖片文件夾,而一般來說實時性項目多用攝像頭做輸入源,故在yolov5.cpp中魔改一下再重新編譯就行。此外IRuntime, ICudaEngine, IExecutionContext等核心類源碼中每次有圖片輸入都會創(chuàng)建一次,嚴重拖慢速度,改成僅初始化階段創(chuàng)建,后續(xù)再有圖片輸入時保持可以提高推理速度。
2.以后可能會融合deepsort做一下目標跟蹤,敬請期待~
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“CVPR21檢測”獲取CVPR2021目標檢測論文下載~

# CV技術(shù)社群邀請函 #
備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標檢測-深圳)
即可申請加入極市目標檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
