
幾種實時數(shù)倉架構(gòu)設(shè)計思路
01 什么是實時數(shù)倉
首先需要明確什么是實時數(shù)倉,百度百科與維基百科都沒有給出具體說明,哪究竟什么才是實時數(shù)倉呢?是不是可以通過實時流實時獲取數(shù)據(jù)就是實時數(shù)倉?或者說流批一體就是實時數(shù)倉?在或者全面采用實時方式,采集和實時計算才是實時數(shù)倉?
這個問題在不同企業(yè)可能會有不同答案,有些會認為提供實時看板或?qū)崟r報表就算是實時數(shù)倉;另外一些可能覺得數(shù)倉提供出去數(shù)據(jù)必須都是實時才算實時數(shù)倉。其實這個問題沒有一個標準答案,不同人、場景、企業(yè)對它理解是不一樣的。記得之前有位上司講管理崗與技術(shù)崗區(qū)別,其中一點是:
對待一件事情或需求,T 崗答案都是明確:要么可以做,要么不可以做;M 崗的回答看似明確,其實會有多種解讀角度。【這不就是老油條么,哈哈】
所以從不同角度去解讀實時數(shù)倉,對什么是實時數(shù)倉定義是不一樣;一般會有一些幾種定義:
具備實時數(shù)據(jù)處理能力,并能夠根據(jù)業(yè)務(wù)需求提供實時數(shù)據(jù)的數(shù)倉能力,如可以為運營側(cè)提供實時業(yè)務(wù)變化、實時營銷效果數(shù)據(jù)。
數(shù)倉中所有數(shù)據(jù),從數(shù)據(jù)采集、加工處理、數(shù)據(jù)分發(fā)都采用實時方式。
從數(shù)據(jù)建設(shè)、數(shù)據(jù)質(zhì)量、數(shù)據(jù)血緣、數(shù)據(jù)治理等都是采用實時方式。
從中可以看出不同理解,建設(shè)實時數(shù)倉復(fù)雜程度是不一樣。但最終建設(shè)一套什么樣實時數(shù)倉還是由業(yè)務(wù)驅(qū)動,需要綜合考慮投入產(chǎn)出。
02 實時數(shù)倉架構(gòu)設(shè)計思路
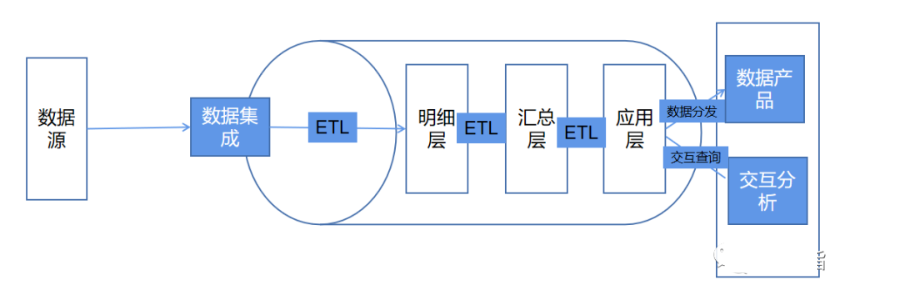
是否數(shù)據(jù)集成流批一體:離線與實時是否使用統(tǒng)一數(shù)據(jù)采集方式;如統(tǒng)一通過 CDC 或者 OGG 將數(shù)據(jù)實時捕獲推送到 kafka,批與流在從 kafka 中消費數(shù)據(jù),載入明細層。
是否存儲層流批一體:離線與實時數(shù)據(jù)是否統(tǒng)一分層、統(tǒng)一存儲;如離線與實時數(shù)據(jù)經(jīng)過 ETL 處理之后根據(jù)統(tǒng)一分層(ODS、DMD、DMS)持久化到同一個數(shù)據(jù)存儲中。
是否 ETL 邏輯流批一體:流與批處理是否使用統(tǒng)一 SQL 語法或者 ETL 組件,再通過底層分別適配流與批計算引擎。
是否 ETL 計算引擎流批一體:流與批使用同一套計算引擎,從根本上避免同一個處理邏輯流批兩套代碼問題。
數(shù)據(jù)集成與存儲層流批一體主要產(chǎn)生以下問題:
流處理更容易出現(xiàn)數(shù)據(jù)丟失,丟失的查詢操作。
一般使用消息中間件對流數(shù)據(jù)進行存儲,消息中間件的存儲特點也決定了,丟失的查詢操作,非常苦難,難以對數(shù)。
Schema 的同步與轉(zhuǎn)換問題,基于流處理來確保 Schema 保持一致,并且數(shù)據(jù)不受影響其實并不容易。面對頻繁變動的業(yè)務(wù)系統(tǒng),往往維護量會變高。
03 幾種實時數(shù)倉架構(gòu)分析
Lambda 數(shù)倉架構(gòu)
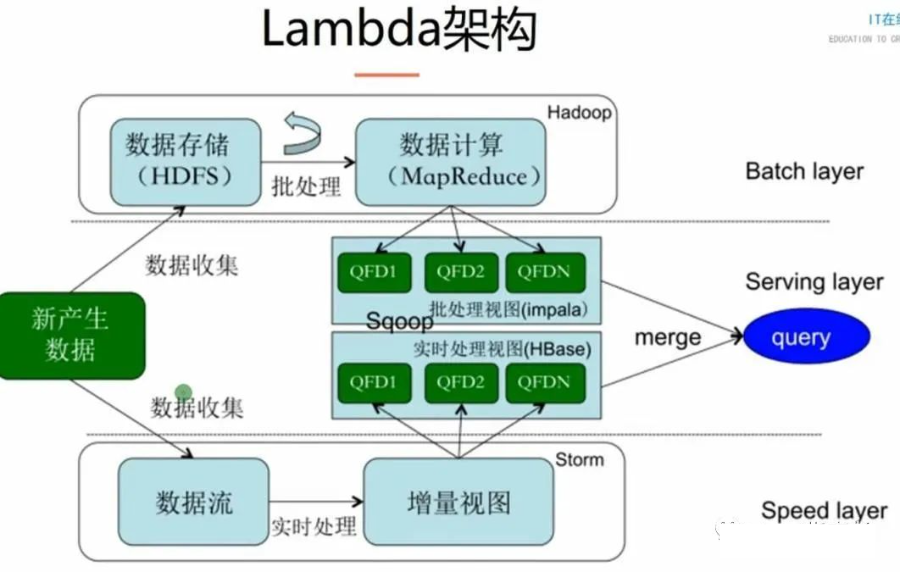
Lambda 有 Batch Layer(批處理)和 Speed Layer(流式處理)。然后通過將批、和流的結(jié)果拼接在一起。Lambda 架構(gòu)具備有數(shù)據(jù)不可變性質(zhì)避免人為引入錯誤問題、支持數(shù)據(jù)重跑、將復(fù)雜的流處理分離出來。而 Batch Layer 和 Speed Layer 由于需要滿足不同的場景,往往會選擇不同的組件。
而且,大家寫過 Storm 就會知道,Storm 的代碼寫起來的是挺痛苦的(Trident 會有所改善)。所以,我們需要準備兩套代碼。同樣的邏輯,針對批處理、和流處理要實現(xiàn)兩次。
Lambda 架構(gòu)問題:
兩套架構(gòu)、各自獨立
一種邏輯兩套代碼
組件太多
數(shù)據(jù)散布在多個系統(tǒng)中,互相訪問困難
Kappa 架構(gòu)
Kreps 提出了另一個維度的思考,我們是否能夠改進,采用流處理系統(tǒng)來建設(shè)大數(shù)據(jù)系統(tǒng)呢?提出完全可以通過建設(shè)以流為核心來建設(shè)數(shù)據(jù)系統(tǒng)。并且,通過重放歷史數(shù)據(jù)來實現(xiàn)數(shù)據(jù)重跑。
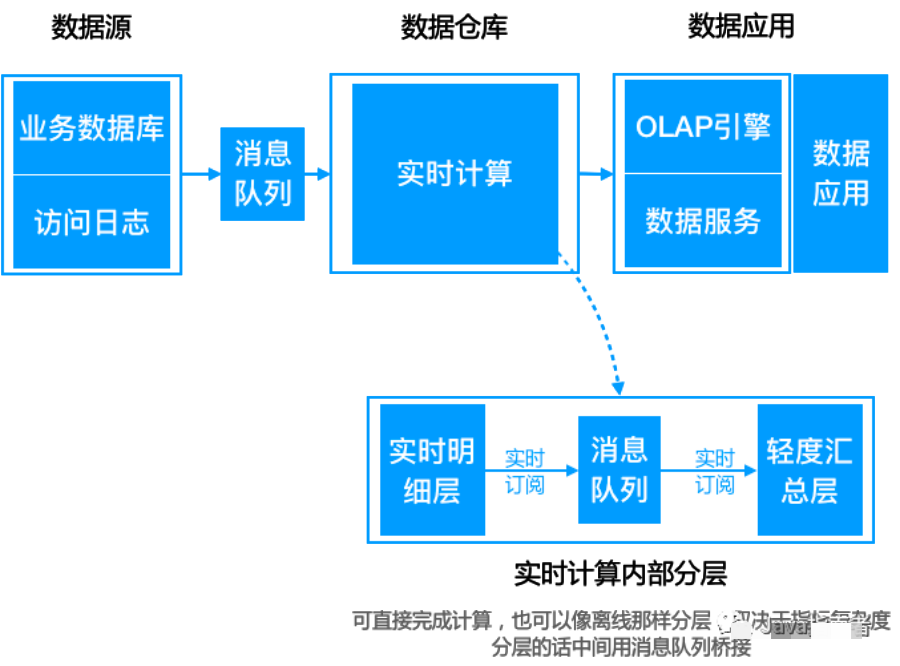
Lambda 架構(gòu)問題:
大數(shù)據(jù)量回溯成本高,生產(chǎn)壓力大
遺留離線數(shù)據(jù)數(shù)倉的遷移問題,要將成千上萬的 ETL 作業(yè)遷往流處理系統(tǒng),其工作量之大、成本之大、風險之大
數(shù)據(jù)丟失的問題,流處理平臺,數(shù)據(jù)丟失問題相對于批處理,更容易出現(xiàn)。而且,要進行對數(shù)非常困難
實時數(shù)據(jù)生產(chǎn) + 實時分析引擎
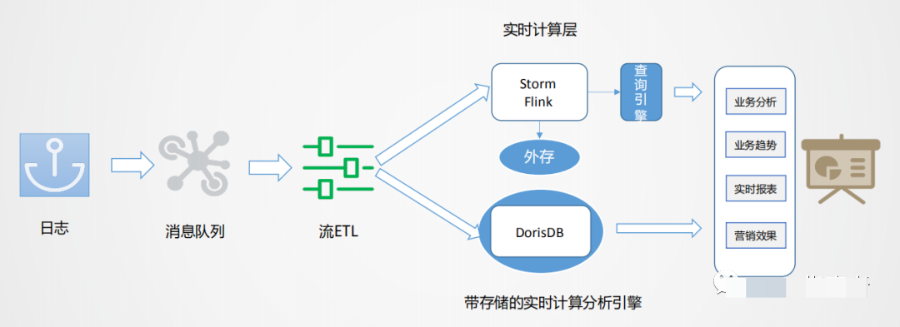
上圖是美團實時數(shù)倉架構(gòu)設(shè)計,數(shù)據(jù)從日志統(tǒng)一采集到消息隊列,再到數(shù)據(jù)流的 ETL 過程,作為基礎(chǔ)數(shù)據(jù)流的建設(shè)是統(tǒng)一的。之后對于日志類實時特征,實時大屏類應(yīng)用走實時流計算。
對于 Binlog 類業(yè)務(wù)分析走實時 OLAP 批處理。美團實時數(shù)倉架構(gòu)主要是將一些在實時處理面臨的難點,由實時 OLAP 處理。
實時處理面臨的幾個難點:
業(yè)務(wù)的多狀態(tài)性:業(yè)務(wù)過程從開始到結(jié)束是不斷變化的,比如從下單->支付->配送,業(yè)務(wù)庫是在原始基礎(chǔ)上進行變更的,Binlog 會產(chǎn)生很多變化的日志。而業(yè)務(wù)分析更加關(guān)注最終狀態(tài),由此產(chǎn)生數(shù)據(jù)回撤計算的問題,例如 10 點下單,13 點取消,但希望在 10 點減掉取消單。
業(yè)務(wù)集成:業(yè)務(wù)分析數(shù)據(jù)一般無法通過單一主體表達,往往是很多表進行關(guān)聯(lián),才能得到想要的信息,在實時流中進行數(shù)據(jù)的合流對齊,往往需要較大的緩存處理且復(fù)雜。
分析是批量的,處理過程是流式的:對單一數(shù)據(jù),無法形成分析,因此分析對象一定是批量的,而數(shù)據(jù)加工是逐條的。
Lambda+Kappa

從上圖可以看出,阿里的實時數(shù)倉架構(gòu)是同時 Lambda 與 Kappa 結(jié)合;數(shù)據(jù)集成沒有使用流批一體,分別通過實時采集、數(shù)據(jù)同步方式實現(xiàn)流與批數(shù)據(jù)采集。ETL 邏輯流批一體,實現(xiàn)用戶只寫一套代碼,平臺自動翻譯成 Flink Batch 任務(wù)和 Flink Stream 任務(wù),同時寫到一張 Holo 表,完成計算層表達的統(tǒng)一。存儲層流與批是分開存儲,但可以實現(xiàn)流批存儲透明化,查詢邏輯完全一致。
04 總結(jié)
推薦閱讀:
不是你需要中臺,而是一名合格的架構(gòu)師(附各大廠中臺建設(shè)PPT)
企業(yè)IT技術(shù)架構(gòu)規(guī)劃方案
論數(shù)字化轉(zhuǎn)型——轉(zhuǎn)什么,如何轉(zhuǎn)?
企業(yè)10大管理流程圖,數(shù)字化轉(zhuǎn)型從業(yè)者必備!