實時數(shù)倉項目架構分層
一、滴滴實時數(shù)倉項目
在公司內部,我們數(shù)據(jù)團隊有幸與順風車業(yè)務線深入合作,在滿足業(yè)務方實時數(shù)據(jù)需求的同時,不斷完善實時數(shù)倉內容,通過多次迭代,基本滿足了順風車業(yè)務方在實時側的各類業(yè)務需求,初步建立起順風車實時數(shù)倉,完成了整體數(shù)據(jù)分層,包含明細數(shù)據(jù)和匯總數(shù)據(jù),統(tǒng)一了DWD層,降低了大數(shù)據(jù)資源消耗,提高了數(shù)據(jù)復用性,可對外輸出豐富的數(shù)據(jù)服務。
數(shù)倉具體架構如下圖所示:
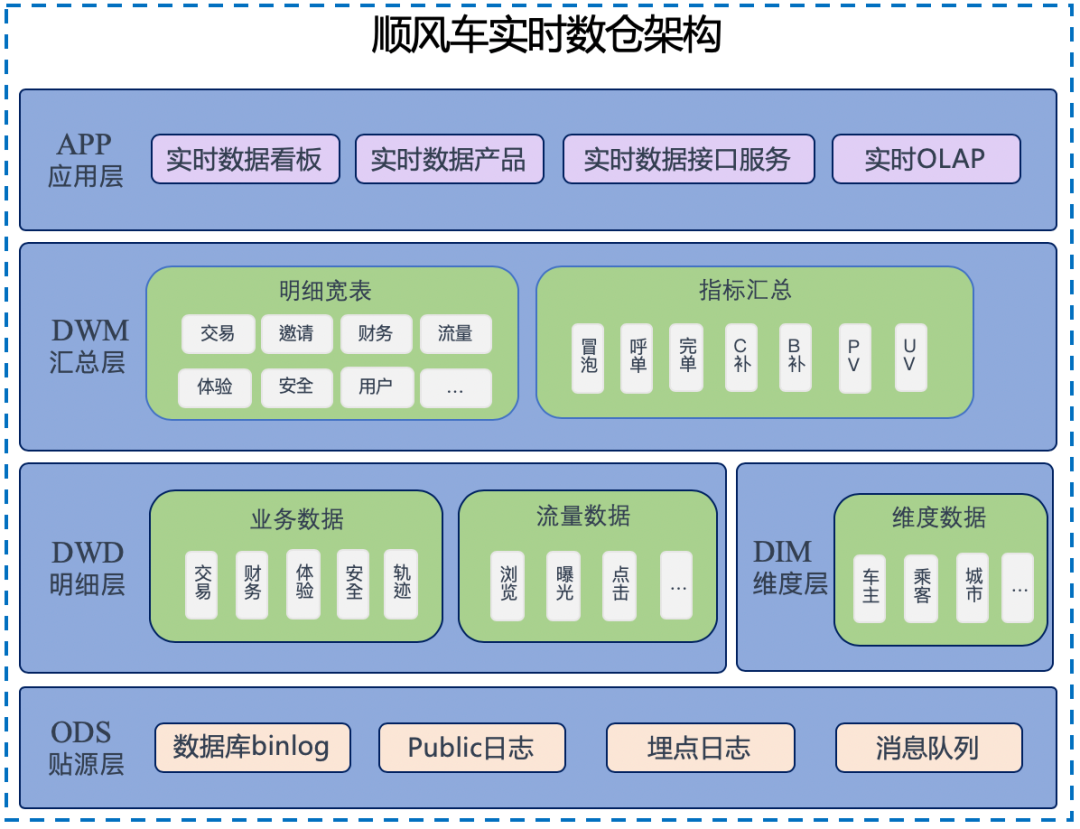
從數(shù)據(jù)架構圖來看,順風車實時數(shù)倉和對應的離線數(shù)倉有很多類似的地方。例如分層結構;比如ODS層,明細層,匯總層,乃至應用層,他們命名的模式可能都是一樣的。但仔細比較不難發(fā)現(xiàn),兩者有很多區(qū)別:
與離線數(shù)倉相比,實時數(shù)倉的層次更少一些
從目前建設離線數(shù)倉的經驗來看,數(shù)倉的數(shù)據(jù)明細層內容會非常豐富,處理明細數(shù)據(jù)外一般還會包含輕度匯總層的概念,另外離線數(shù)倉中應用層數(shù)據(jù)在數(shù)倉內部,但實時數(shù)倉中,app應用層數(shù)據(jù)已經落入應用系統(tǒng)的存儲介質中,可以把該層與數(shù)倉的表分離。
應用層少建設的好處:實時處理數(shù)據(jù)的時候,每建一個層次,數(shù)據(jù)必然會產生一定的延遲。
匯總層少建的好處:在匯總統(tǒng)計的時候,往往為了容忍一部分數(shù)據(jù)的延遲,可能會人為的制造一些延遲來保證數(shù)據(jù)的準確。舉例,在統(tǒng)計跨天相關的訂單事件中的數(shù)據(jù)時,可能會等到 00:00:05 或者 00:00:10再統(tǒng)計,確保 00:00 前的數(shù)據(jù)已經全部接受到位了,再進行統(tǒng)計。所以,匯總層的層次太多的話,就會更大的加重人為造成的數(shù)據(jù)延遲。* 與離線數(shù)倉相比,實時數(shù)倉的數(shù)據(jù)源存儲不同
在建設離線數(shù)倉的時候,目前滴滴內部整個離線數(shù)倉都是建立在 Hive 表之上。但是,在建設實時數(shù)倉的時候,同一份表,會使用不同的方式進行存儲。比如常見的情況下,明細數(shù)據(jù)或者匯總數(shù)據(jù)都會存在 Kafka 里面,但是像城市、渠道等維度信息需要借助Hbase,mysql或者其他KV存儲等數(shù)據(jù)庫來進行存儲。?接下來,根據(jù)順風車實時數(shù)倉架構圖,對每一層建設做具體展開:
2.1?ODS 貼源層建設
根據(jù)順風車具體場景,目前順風車數(shù)據(jù)源主要包括訂單相關的binlog日志,冒泡和安全相關的public日志,流量相關的埋點日志等。這些數(shù)據(jù)部分已采集寫入kafka或ddmq等數(shù)據(jù)通道中,部分數(shù)據(jù)需要借助內部自研同步工具完成采集,最終基于順風車數(shù)倉ods層建設規(guī)范分主題統(tǒng)一寫入kafka存儲介質中。
命名規(guī)范:ODS層實時數(shù)據(jù)源主要包括兩種。
一種是在離線采集時已經自動生產的DDMQ或者是Kafka topic,這類型的數(shù)據(jù)命名方式為采集系統(tǒng)自動生成規(guī)范為:cn-binlog-數(shù)據(jù)庫名-數(shù)據(jù)庫名 eg:cn-binlog-ihap_fangyuan-ihap_fangyuan
一種是需要自己進行采集同步到kafka topic中,生產的topic命名規(guī)范同離線類似:ODS層采用:realtime_ods_binlog_{源系統(tǒng)庫/表名}/ods_log_{日志名} eg: realtime_ods_binlog_ihap_fangyuan
2.2 DWD 明細層建設
根據(jù)順風車業(yè)務過程作為建模驅動,基于每個具體的業(yè)務過程特點,構建最細粒度的明細層事實表;結合順風車分析師在離線側的數(shù)據(jù)使用特點,將明細事實表的某些重要維度屬性字段做適當冗余,完成寬表化處理,之后基于當前順風車業(yè)務方對實時數(shù)據(jù)的需求重點,重點建設交易、財務、體驗、安全、流量等幾大模塊;該層的數(shù)據(jù)來源于ODS層,通過大數(shù)據(jù)架構提供的Stream SQL完成ETL工作,對于binlog日志的處理主要進行簡單的數(shù)據(jù)清洗、處理數(shù)據(jù)漂移和數(shù)據(jù)亂序,以及可能對多個ODS表進行Stream Join,對于流量日志主要是做通用的ETL處理和針對順風車場景的數(shù)據(jù)過濾,完成非結構化數(shù)據(jù)的結構化處理和數(shù)據(jù)的分流;該層的數(shù)據(jù)除了存儲在消息隊列Kafka中,通常也會把數(shù)據(jù)實時寫入Druid數(shù)據(jù)庫中,供查詢明細數(shù)據(jù)和作為簡單匯總數(shù)據(jù)的加工數(shù)據(jù)源。
命名規(guī)范:DWD層的表命名使用英文小寫字母,單詞之間用下劃線分開,總長度不能超過40個字符,并且應遵循下述規(guī)則:realtime_dwd_{業(yè)務/pub}{數(shù)據(jù)域縮寫}[{業(yè)務過程縮寫}]_[{自定義表命名標簽縮寫}]
{業(yè)務/pub}:參考業(yè)務命名
{數(shù)據(jù)域縮寫}:參考數(shù)據(jù)域劃分部分
{自定義表命名標簽縮寫}:實體名稱可以根據(jù)數(shù)據(jù)倉庫轉換整合后做一定的業(yè)務抽象的名稱,該名稱應該準確表述實體所代表的業(yè)務含義
樣例:realtime_dwd_trip_trd_order_base
2.3 DIM 層
公共維度層,基于維度建模理念思想,建立整個業(yè)務過程的一致性維度,降低數(shù)據(jù)計算口徑和算法不統(tǒng)一風險;
DIM 層數(shù)據(jù)來源于兩部分:一部分是Flink程序實時處理ODS層數(shù)據(jù)得到,另外一部分是通過離線任務出倉得到;
DIM 層維度數(shù)據(jù)主要使用 MySQL、Hbase、fusion(滴滴自研KV存儲)?三種存儲引擎,對于維表數(shù)據(jù)比較少的情況可以使用 MySQL,對于單條數(shù)據(jù)大小比較小,查詢 QPS 比較高的情況,可以使用 fusion 存儲,降低機器內存資源占用,對于數(shù)據(jù)量比較大,對維表數(shù)據(jù)變化不是特別敏感的場景,可以使用HBase 存儲。
命名規(guī)范:DIM層的表命名使用英文小寫字母,單詞之間用下劃線分開,總長度不能超過30個字符,并且應遵循下述規(guī)則:dim_{業(yè)務/pub}{維度定義}[{自定義命名標簽}]:
{業(yè)務/pub}:參考業(yè)務命名
{維度定義}:參考維度命名
{自定義表命名標簽縮寫}:實體名稱可以根據(jù)數(shù)據(jù)倉庫轉換整合后做一定的業(yè)務抽象的名稱,該名稱應該準確表述實體所代表的業(yè)務含義?樣例:dim_trip_dri_base
2.4?DWM 匯總層建設
在建設順風車實時數(shù)倉的匯總層的時候,跟順風車離線數(shù)倉有很多一樣的地方,但其具體技術實現(xiàn)會存在很大不同。
第一:對于一些共性指標的加工,比如pv,uv,訂單業(yè)務過程指標等,我們會在匯總層進行統(tǒng)一的運算,確保關于指標的口徑是統(tǒng)一在一個固定的模型中完成。對于一些個性指標,從指標復用性的角度出發(fā),確定唯一的時間字段,同時該字段盡可能與其他指標在時間維度上完成拉齊,例如行中異常訂單數(shù)需要與交易域指標在事件時間上做到拉齊。
第二:在順風車匯總層建設中,需要進行多維的主題匯總,因為實時數(shù)倉本身是面向主題的,可能每個主題會關心的維度都不一樣,所以需要在不同的主題下,按照這個主題關心的維度對數(shù)據(jù)進行匯總,最后來算業(yè)務方需要的匯總指標。在具體操作中,對于pv類指標使用Stream SQL實現(xiàn)1分鐘匯總指標作為最小匯總單位指標,在此基礎上進行時間維度上的指標累加;對于uv類指標直接使用druid數(shù)據(jù)庫作為指標匯總容器,根據(jù)業(yè)務方對匯總指標的及時性和準確性的要求,實現(xiàn)相應的精確去重和非精確去重。
第三:匯總層建設過程中,還會涉及到衍生維度的加工。在順風車券相關的匯總指標加工中我們使用Hbase的版本機制來構建一個衍生維度的拉鏈表,通過事件流和Hbase維表關聯(lián)的方式得到實時數(shù)據(jù)當時的準確維度
命名規(guī)范:DWM層的表命名使用英文小寫字母,單詞之間用下劃線分開,總長度不能超過40個字符,并且應遵循下述規(guī)則:realtime_dwm_{業(yè)務/pub}{數(shù)據(jù)域縮寫}{數(shù)據(jù)主粒度縮寫}[{自定義表命名標簽縮寫}]{統(tǒng)計時間周期范圍縮寫}:
{業(yè)務/pub}:參考業(yè)務命名
{數(shù)據(jù)域縮寫}:參考數(shù)據(jù)域劃分部分
{數(shù)據(jù)主粒度縮寫}:指數(shù)據(jù)主要粒度或數(shù)據(jù)域的縮寫,也是聯(lián)合主鍵中的主要維度
{自定義表命名標簽縮寫}:實體名稱可以根據(jù)數(shù)據(jù)倉庫轉換整合后做一定的業(yè)務抽象的名稱,該名稱應該準確表述實體所代表的業(yè)務含義
{統(tǒng)計時間周期范圍縮寫}:1d:天增量;td:天累計(全量);1h:小時增量;th:小時累計(全量);1min:分鐘增量;tmin:分鐘累計(全量)
樣例:realtime_dwm_trip_trd_pas_bus_accum_1min
2.5 APP 應用層
該層主要的工作是把實時匯總數(shù)據(jù)寫入應用系統(tǒng)的數(shù)據(jù)庫中,包括用于大屏顯示和實時OLAP的Druid數(shù)據(jù)庫(該數(shù)據(jù)庫除了寫入應用數(shù)據(jù),也可以寫入明細數(shù)據(jù)完成匯總指標的計算)中,用于實時數(shù)據(jù)接口服務的Hbase數(shù)據(jù)庫,用于實時數(shù)據(jù)產品的mysql或者redis數(shù)據(jù)庫中。
命名規(guī)范:基于實時數(shù)倉的特殊性不做硬性要求

二、美團OneData數(shù)倉項目
OneData: 阿里巴巴提出的數(shù)倉建設標準

摘要
美團基于OneData思想和現(xiàn)有業(yè)務架構情況,提出了新的標準和目標:

實現(xiàn)方法:統(tǒng)一歸口和出口 統(tǒng)一歸口:業(yè)務歸口統(tǒng)一、設計歸口統(tǒng)一和應用歸口統(tǒng)一,從底層保證了數(shù)倉建設的三特性和三效果
統(tǒng)一出口:
交付標準化
數(shù)據(jù)資產管理:統(tǒng)一維度,指標元數(shù)據(jù)出口等

基于此,實現(xiàn)了分層模型:

正常開發(fā)應遵循ODS-DWD—DWT-DWA-APP的流程,同時根據(jù)架構做出 開發(fā)規(guī)范:
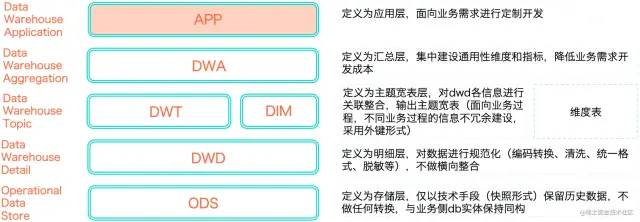
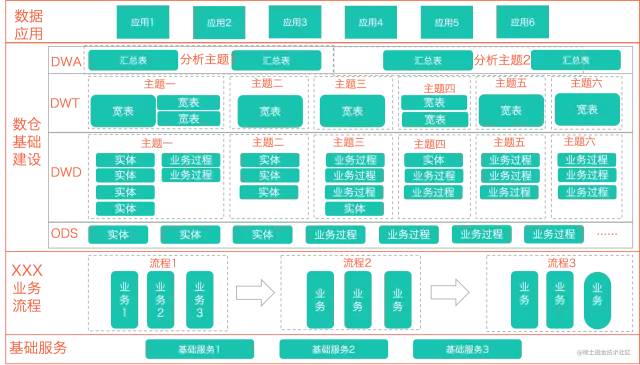
正常流向:ODS>DWD->DWT->DWA->APP,當出現(xiàn)ODS >DWD->DWA->APP這種關系時,說明主題域未覆蓋全。應將DWD數(shù)據(jù)落到DWT中,對于使用頻度非常低的表允許DWD->DWA。盡量避免出現(xiàn)DWA寬表中使用DWD又使用(該DWD所歸屬主題域)DWT的表。
同一主題域內對于DWT生成DWT的表,原則上要盡量避免,否則會影響ETL的效率。
DWT、DWA和APP中禁止直接使用ODS的表,
ODS的表只能被DWD引用。
禁止出現(xiàn)反向依賴,例如DWT的表依賴DWA的表。