
數(shù)據(jù)湖 Iceberg | 在網(wǎng)易云音樂(lè)的實(shí)踐
iceberg 詳細(xì)設(shè)計(jì)
Apache iceberg 是Netflix開(kāi)源的全新的存儲(chǔ)格式,我們已經(jīng)有了parquet、orc、arvo等非常優(yōu)秀的存儲(chǔ)格式以后,Netfix為什么還要設(shè)計(jì)出iceberg呢?和parquet、orc等文件格式不同, iceberg在業(yè)界被稱(chēng)之為T(mén)able Foramt,parquet、orc、avro等文件等格式幫助我們高效的修改、讀取單個(gè)文件;同樣Table Foramt幫助我們高效的修改和讀取一類(lèi)文件集合,大家可以類(lèi)比的Hive的元數(shù)據(jù)系統(tǒng), Hive的Schema幫助我們了解數(shù)據(jù), Hive的分區(qū)幫助我們高效過(guò)濾數(shù)據(jù)。那么iceberg和hive相比的優(yōu)勢(shì)是什么呢?且看下文詳細(xì)介紹,Netfilx對(duì)iceberg的定義為:
Iceberg is a scalable format for tables with a lot of best practices built in.希望大家在看完本篇文章以后都能夠在腦子里面印證上面這句定義。
1.1 Hive的一些問(wèn)題
1.1.1 不可靠的更新操作
我們針對(duì)某張HIVE表的數(shù)據(jù)做 load data overwrite into 操作時(shí), 整個(gè)操作分兩個(gè)部分, 刪除已存在的文件,移動(dòng)新的文件到分區(qū)目錄下,此時(shí)如果有人任務(wù)正在讀取這個(gè)數(shù)據(jù), 受文件刪除操作的影響,整個(gè)任務(wù)就GG了,HIVE的操作整體是沒(méi)有ACID保障的。
1.1.2 column rename 問(wèn)題
在使用parquet、json、orc、avro等文件格式時(shí), 如果我們重命名某個(gè)column的名字時(shí),整個(gè)數(shù)據(jù)表都要重新復(fù)寫(xiě),代價(jià)很大, 一些大的數(shù)據(jù)表基本是不可接受的。
1.1.3 太多分區(qū)造成的性能問(wèn)題
hive的分區(qū)元數(shù)據(jù)都是保存到目錄級(jí)別,在讀取hive表做完分區(qū)下推查詢(xún)以后,需要對(duì)所有過(guò)濾出來(lái)的分區(qū)做一次list操作,得到所有的明細(xì)文件然后生成任務(wù),對(duì)于分區(qū)非常多表的來(lái)說(shuō),在云音樂(lè)目前的量級(jí)下,大量的list操作非常的耗時(shí)的,高峰期的NameNode壓力非常大,大量的list操作的耗時(shí)的占比甚至和任務(wù)在計(jì)算上花費(fèi)的時(shí)長(zhǎng)相當(dāng),這也是為什么一些公司的hive表只允許兩層分區(qū)的原因之一。
1.1.4 元數(shù)據(jù)保存在元數(shù)據(jù)和文件系統(tǒng)兩個(gè)地方
分區(qū)信息保存在元數(shù)據(jù)庫(kù), 文件信息保存在NameNode當(dāng)中,整體沒(méi)有原子性保障,如果文件發(fā)生變化,多了數(shù)據(jù)或者少了數(shù)據(jù),對(duì)于元數(shù)據(jù)是不感知的,數(shù)據(jù)雖然能被正常讀取,但數(shù)據(jù)的可靠性是缺乏保障的。
1.2 iceberg設(shè)計(jì)
1.2.1 設(shè)計(jì)目標(biāo)
和HIVE一樣成為開(kāi)放的靜態(tài)數(shù)據(jù)存儲(chǔ)標(biāo)準(zhǔn), 標(biāo)準(zhǔn)清晰, 和語(yǔ)言無(wú)關(guān)和項(xiàng)目無(wú)關(guān)
強(qiáng)大的擴(kuò)展性以及可靠性: 透明簡(jiǎn)單的使用, 用戶(hù)只需寫(xiě)入數(shù)據(jù)所有元數(shù)據(jù)的變更都是自動(dòng)和底層序列化方式無(wú)關(guān)的, 支持并發(fā)寫(xiě)
解決存儲(chǔ)可用性問(wèn)題: 更好的schema管理方式、時(shí)間旅行、多版本回滾支持等
1.2.2 詳細(xì)設(shè)計(jì)
每次寫(xiě)入都會(huì)成一個(gè)snapshot, 每個(gè)snapshot包含著一系列的文件列表

基于MVCC(Multi Version Concurrency Control)的機(jī)制,默認(rèn)讀取文件會(huì)從最新的的版本, 每次寫(xiě)入都會(huì)產(chǎn)生一個(gè)新的snapshot, 讀寫(xiě)相互不干擾
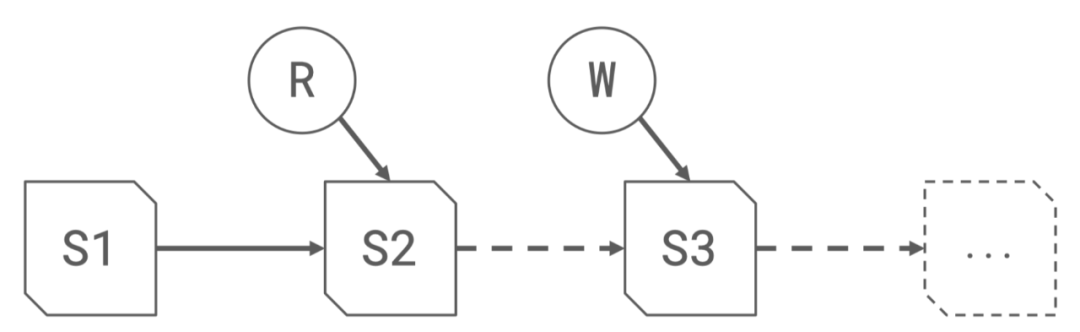
1.2.3 基于多版本的機(jī)制可以可用輕松實(shí)現(xiàn)回滾和時(shí)間旅行的功能, 讀取或者回滾任意版本的snapshot數(shù)據(jù)
1.2.4 精準(zhǔn)完善的元數(shù)據(jù)信息:
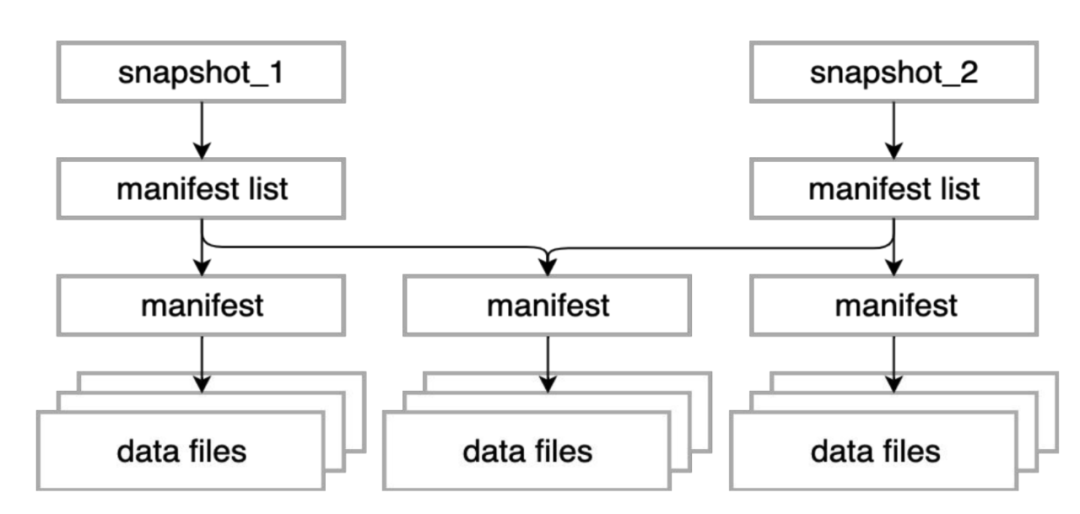
如上圖所示, snapshot信息、manifest信息以及文件信息, 一個(gè)snapot包含一系列的manifest信息, 每個(gè)manifest存儲(chǔ)了一系列的文件列表
snapshot列表信息:包含了詳細(xì)的manifest列表,產(chǎn)生snapshot的操作,以及詳細(xì)記錄數(shù)、文件數(shù)、甚至任務(wù)信息,充分考慮到了數(shù)據(jù)血緣的追蹤

manifest列表信息:保存了每個(gè)manifest包含的分區(qū)信息

文件列表信息:保存了每個(gè)文件字段級(jí)別的統(tǒng)計(jì)信息,以及分區(qū)信息

如此完善的統(tǒng)計(jì)信息,利用查詢(xún)引擎層的條件下推,可以快速的過(guò)濾掉不必要文件,提高查詢(xún)效率,熟悉了iceberg的機(jī)制,在寫(xiě)入iceberg的表時(shí)按照需求以及字段的分布,合理的寫(xiě)入有序的數(shù)據(jù),能夠達(dá)到非常好的過(guò)濾效果。
1.2.5 ID映射的方式管理Schema:
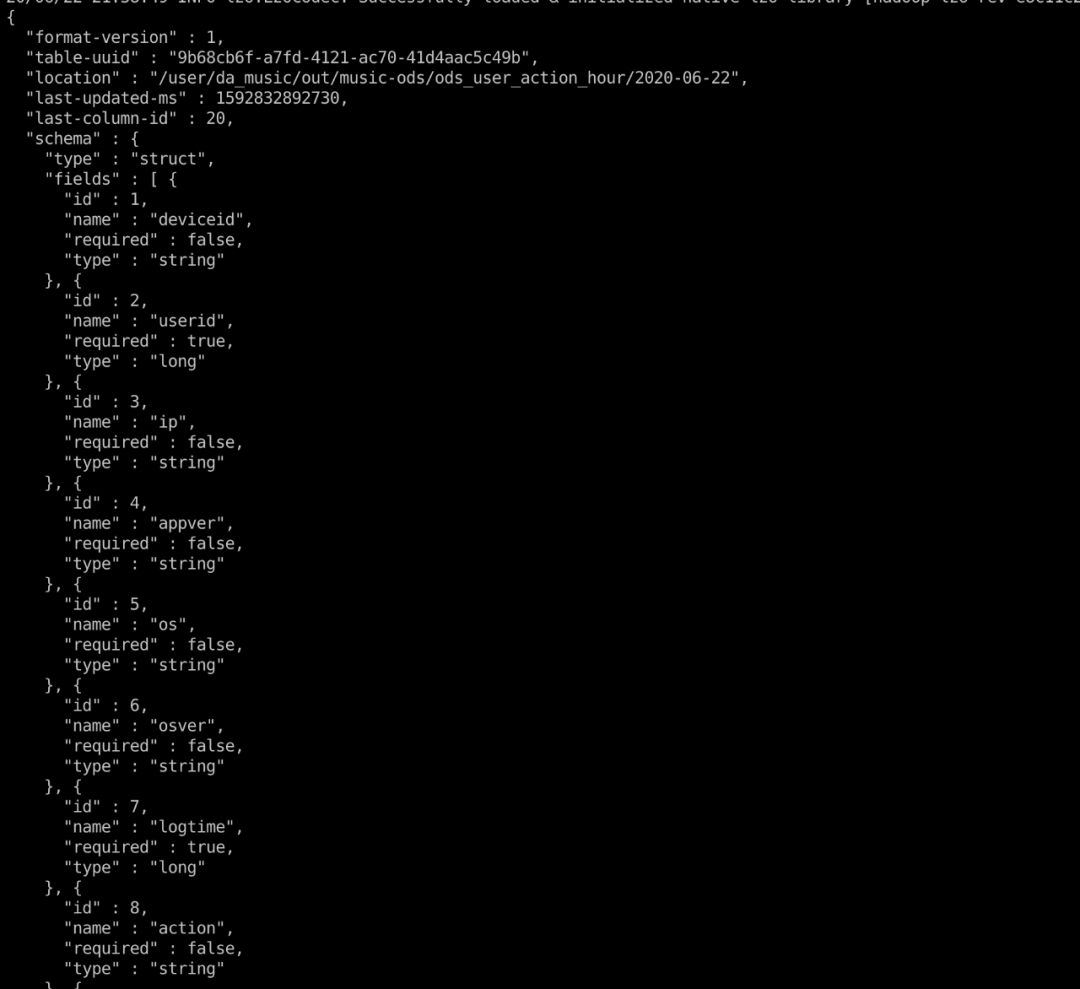
在iceberg的實(shí)際的存儲(chǔ)文件中,schema的那么都是id,讀取時(shí)和上圖的元數(shù)據(jù)經(jīng)過(guò)整合生成用戶(hù)想要的schema,利用這種方式iceberg可以輕松的做的column rename,數(shù)據(jù)文件不需要修改的目錄,且歷史文件也能夠完美的兼容的新的schema。
iceberg在云音樂(lè)的實(shí)踐
云音樂(lè)僅主站的用戶(hù)行為日志每天就會(huì)產(chǎn)生25T~30T,每天歸檔的文件數(shù)11萬(wàn)+,如果用spark直讀這個(gè)11萬(wàn)+的文件的話,單單分區(qū)計(jì)算任務(wù)初始化的時(shí)間就要超過(guò)1個(gè)小時(shí),如果每個(gè)業(yè)務(wù)域的DWD的數(shù)據(jù)都直接從原始的DS歸檔數(shù)據(jù)抽取數(shù)據(jù)的話,基本是不現(xiàn)實(shí)的,所以我們對(duì)底層數(shù)據(jù)按照小時(shí)的粒度進(jìn)行預(yù)處理的工作,預(yù)處理工作主要包含兩個(gè)部分:臟數(shù)據(jù)的清洗過(guò)濾和日志的分區(qū),保障下游任務(wù)能夠正確的只讀取自己想要的數(shù)據(jù)。
但是即使是這樣,我們依然有一些任務(wù)需要讀取全量的日志數(shù)據(jù),經(jīng)過(guò)清洗的數(shù)據(jù)包含上百個(gè)分區(qū),5萬(wàn)+個(gè)文件,加上凌晨高峰期的時(shí)候音樂(lè)的NameNode壓力非常大,NameNode的請(qǐng)求隊(duì)列經(jīng)常處于滿(mǎn)負(fù)荷狀態(tài),上百個(gè)分區(qū)需要Call NameNode上百次,這導(dǎo)致讀取全量數(shù)據(jù)的時(shí)在任務(wù)初始化階段就要耗費(fèi)30分鐘左右,在任務(wù)高峰期時(shí)整個(gè)時(shí)長(zhǎng)高達(dá)1個(gè)小時(shí),占了將近一半的任務(wù)執(zhí)行時(shí)長(zhǎng),如果在執(zhí)行期間機(jī)器發(fā)生故障,導(dǎo)致任務(wù)重試的話,整個(gè)延遲高達(dá)兩個(gè)小時(shí)以上,整體不可接受。我們面臨的問(wèn)題和NetFlix早期面臨的問(wèn)題一致,也是iceberg想要解決的問(wèn)題之一,所以我們利用iceberg的特性做了一些重構(gòu)工作:
利用iceberg提供的HadoopCatalog的API新建了一張iceberg表,按照小時(shí)和行為分區(qū),然后按照小時(shí)粒度清洗日志數(shù)據(jù),并將數(shù)據(jù)結(jié)果寫(xiě)入到iceberg的表中,整體實(shí)踐下來(lái),由于iceberg不需要Call NameNode來(lái)獲取文件信息以及其完善精準(zhǔn)的統(tǒng)計(jì)信息,讀取整表的速度有了質(zhì)的提升,任務(wù)初始化的速度從以前的30分鐘到一個(gè)小時(shí),提升到5到10分鐘,我們整體ETL任務(wù)的速度和穩(wěn)定性也有了很大的提升,解決了長(zhǎng)久以來(lái)困擾已久的穩(wěn)定性問(wèn)題。
當(dāng)然這里使用iceberg只是我們優(yōu)化的一小部分,在此就不為iceberg做過(guò)多的吹噓,了解其中的原理,什么時(shí)候適合使用iceberg重構(gòu)現(xiàn)有的存儲(chǔ),什么情況下能帶來(lái)多大的提升基本心里應(yīng)該也是有數(shù)的;在完成以上的改造以后也有一些使用的收獲:
iceberg表的文件結(jié)構(gòu):iceberg表包含兩個(gè)目錄,metadata和data,metadata包含了所有的元數(shù)據(jù)文件,data中包含了數(shù)據(jù)文件:

其中data文件結(jié)果和hive的文件目錄結(jié)構(gòu)基本相同,在此不做過(guò)多的描述,metadata文件目錄主要包含了三類(lèi)文件,基本層級(jí)結(jié)構(gòu)和上面第三張圖的結(jié)果基本一致。
metadata文件:

每個(gè)meta文件相當(dāng)于一個(gè)snapshot,其中包含了當(dāng)前版本的schema信息、產(chǎn)生此版本的任務(wù)信息、以及manifest文件地址信息。
manifest-list文件:

包含了所有mainfest的文件的元數(shù)據(jù)信息,包含了manifest地址,分區(qū)范圍以及一些統(tǒng)計(jì)信息:
java -jar avro-tools-1.9.2.jar tojson --pretty snap-8844883026140670978-1-0e32a3de-51d1-4641-9235-181c87a8a2f8.avro----------------------------------------------------------------------------------------{ "manifest_path" : "/user/da_music/out/music-ods/ods_user_action_hour/2020-06-26/metadata/0e32a3de-51d1-4641-9235-181c87a8a2f8-m0.avro","manifest_length" : 790541,"partition_spec_id" : 0,"added_snapshot_id" : {"long" : 8844883026140670978 },"added_data_files_count" : {"int" : 0 },"existing_data_files_count" : {"int" : 3639 },"deleted_data_files_count" : {"int" : 0 },"partitions" : {"array" : [ {"contains_null" : false,"lower_bound" : {"bytes" : "\u0000\u0000\u0000\u0000" },"upper_bound" : {"bytes" : "\u0001\u0000\u0000\u0000" } }, {"contains_null" : false,"lower_bound" : {"bytes" : "future" },"upper_bound" : {"bytes" : "user" } }, {"contains_null" : false,"lower_bound" : {"bytes" : "ABTest" },"upper_bound" : {"bytes" : "zan" } }, {"contains_null" : false,"lower_bound" : {"bytes" : "\u0000\u0000\u0000\u0000" },"upper_bound" : {"bytes" : "S\u0002\u0000\u0000" } } ] },"added_rows_count" : {"long" : 0 },"existing_rows_count" : {"long" : 6963879270 },"deleted_rows_count" : {"long" : 0 }}
manifest文件:
java -jar avro-tools-1.9.2.jar tojson --pretty 0e32a3de-51d1-4641-9235-181c87a8a2f8-m0.avro---------------------------------------------------------------------------------------------{ "status" : 0,"snapshot_id" : {"long" : 4472068361392595880 },"data_file" : {"file_path" : "/user/da_music/out/music-ods/ods_user_action_hour/2020-06-26/data/hour=1/group=future/action_partition=other/action_bucket=0/00000-22771-6dc69840-9f4f-4605-a297-3e63312bdf8a-00000.parquet","file_format" : "PARQUET","partition" : {"hour" : {"int" : 1 },"group" : {"string" : "future" },"action_partition" : {"string" : "other" },"action_bucket" : {"int" : 0 } },"record_count" : 48469,"file_size_in_bytes" : 3031083,"block_size_in_bytes" : 67108864,//每個(gè)字段存儲(chǔ)大小信息"column_sizes" : {.... },//每個(gè)字段的COUNT信息"value_counts" : {.... }//每個(gè)字段的最小值信息"lower_bounds" : {... },//每個(gè)字段的最大值信息"upper_bounds" : {... },//文件分區(qū)信息"split_offsets" : {"array" : [ 4, 132073718, 265190437 ] }....
包含了所有的數(shù)據(jù)地址細(xì)化到具體文件,所以讀取時(shí)不需list所有的文件,包含了分區(qū)信息,所有字段的存儲(chǔ)大小、每個(gè)字段的行數(shù)信息、空值統(tǒng)計(jì)信息、每個(gè)字段的最大值、最小值信息、分區(qū)信息等等,上層引擎可以利用這些做JOIN的Cache優(yōu)化、做文件級(jí)別的下推過(guò)濾,精準(zhǔn)的分區(qū)信息,大大提高了上層引擎查詢(xún)初始化的速度。
分區(qū)寫(xiě)入時(shí)必須按照分區(qū)字段寫(xiě)入有序的數(shù)據(jù),iceberg本身應(yīng)該采用了順序?qū)懭氲姆绞剑诜謪^(qū)字段發(fā)生變化時(shí),關(guān)閉當(dāng)前寫(xiě)入的分區(qū)文件,創(chuàng)建并開(kāi)始寫(xiě)入下一個(gè)分區(qū)的文件,如果數(shù)據(jù)不是有序的,寫(xiě)入時(shí)就會(huì)拋出寫(xiě)入已關(guān)閉文件的錯(cuò)誤,所以在寫(xiě)入iceberg表之前必須按照分區(qū)的字段進(jìn)行全局的sort操作,spark全局排序?qū)懭胄枰⒁庖韵聨c(diǎn):
調(diào)大spark.driver.maxResultSize: spark的全局sort方法使用了RangePartition的策略,寫(xiě)入前會(huì)對(duì)每個(gè)分區(qū)抽樣一定量的數(shù)據(jù)來(lái)確定整體數(shù)據(jù)的范圍,所以如果寫(xiě)入數(shù)據(jù)量很大,分區(qū)很多時(shí),必須調(diào)大spark.driver.maxResultSize防止driver端內(nèi)存溢出。
文件數(shù)控制:通過(guò)調(diào)整spark.sql.shuffle.partitions的大小來(lái)控制全局排序后輸出的文件數(shù)量,防止輸出太多的小文件。
在按照分區(qū)字段排序以外,可以按照需求方的查詢(xún)習(xí)慣額外加一些字段排序,利用精準(zhǔn)的統(tǒng)計(jì)信息,來(lái)提升查詢(xún)速度。
寫(xiě)入有序數(shù)據(jù)還有一個(gè)額外的好處就是能夠獲得更好的壓縮率,這一點(diǎn)大家可以自己測(cè)試下,結(jié)果可能讓人驚喜;iceberg這樣的設(shè)計(jì)的可能就是有意為之,也是作者想要融合的最佳實(shí)踐之一。
uaDF.sort(expr("hour"), expr("group"), expr("action"), expr("logtime")).write.format("iceberg").option("write.parquet.row-group-size-bytes", 256 * 1024 * 1024).mode(SaveMode.Overwrite).save(output)
iceberg的設(shè)計(jì)本身不受底層文件格式限制,目前支持avro、orc、parquet等文件格式, 本身parquet的元數(shù)據(jù)也包含了很多和iceberg類(lèi)似的精準(zhǔn)的統(tǒng)計(jì)元信息,在數(shù)據(jù)量較小時(shí),iceberg提升不會(huì)特別明顯,甚至沒(méi)有提升,iceberg比較適合超大數(shù)據(jù)量的表。
未來(lái)規(guī)劃
3.1 合并支持,解決FLINK歸檔到iceberg的大量小文件問(wèn)題。
3.2 MergeInto支持,和Hudi、DeltaLake類(lèi)似,支持?jǐn)?shù)據(jù)的更新刪除操作,支持merge on read 以及 merge on write,將iceberg作為以后批流一體的數(shù)倉(cāng)的主力存儲(chǔ)。
以上規(guī)劃目前杭研的同學(xué)都已經(jīng)在推進(jìn)當(dāng)中,期待后續(xù)的落地分享。
參考文檔
官網(wǎng):https://iceberg.apache.org/
關(guān)于TableFormat:https://www.youtube.com/watch?v=iRXNtsayENg
關(guān)于Iceberg:https://www.youtube.com/watch?v=mf8Hb0coI6o&t=939s
NetFilx使用iceberg歸檔流數(shù)據(jù)的分享:https://www.youtube.com/watch?v=-Q4UcXcIv1o
汪磊,網(wǎng)易云音樂(lè)/數(shù)據(jù)平臺(tái)開(kāi)發(fā)專(zhuān)家。
