
數(shù)據(jù)特征預(yù)處理——數(shù)據(jù)降維
一、數(shù)據(jù)的降維方法
? ? ? 這里的意思不是說(shuō)將多維數(shù)據(jù)降為低維數(shù)據(jù),比如說(shuō),將三維降為二維這種,而是減少相關(guān)度低的特征數(shù)據(jù)。
1)特征選擇
冗余: 部分特征的相關(guān)度高,容易消耗計(jì)算性能。噪聲: 部分特征對(duì)預(yù)測(cè)結(jié)果有影響。
主要方法:Filter(過(guò)濾式):VarianceThreshol;Embeded(嵌入式):正則化,決策樹(shù);Wrapper(包裹式);神經(jīng)網(wǎng)絡(luò)==> 后續(xù)深入。? ? ? ? ? ? API:sklearn.feature_selection.VarianceThreshold(threshold=0.0)
刪除所有低方差特征;Variance.fit_transform(X),X:numpy array 格式的數(shù)據(jù);返回值: 訓(xùn)練集差異低于threshold的特征將會(huì)被刪除;默認(rèn)值是保留所有非零方差特征,即刪除所有樣本中具有相同值的特征。
from?sklearn.feature_selection?import?VarianceThreshold
from?sklearn.decomposition?import?PCA
import?pandas?as?pd
def?filter_Variance():
????'''
????刪除低方差的數(shù)據(jù)
????????指定閾值方差
????????調(diào)用fit_transform
????:return:
????'''
????var?=?VarianceThreshold(threshold=1.0)
????data?=?var.fit_transform([[0,2,0,3],[0,1,4,3],[0,1,1,3]])
????print(data)
????'''
????默認(rèn)?threshold=0.0
????[[2?0]
?????[1?4]
?????[1?1]]
?????取方差為1.0
?????[[0]
??????[4]
??????[1]?]
????'''
????return?None
?2)主成分分析
本質(zhì):PCA是一種分析、簡(jiǎn)化數(shù)據(jù)集的技術(shù)。
目的:是數(shù)據(jù)維數(shù)壓縮,盡可能降低原數(shù)據(jù)的維數(shù)(復(fù)雜度),損失少量信息。
作用:可以削減回歸分析或者聚類分析中特征的數(shù)量。特征數(shù)量達(dá)到上百的時(shí)候,考慮數(shù)據(jù)的簡(jiǎn)化(即PCA)。API:skelarn.decomposition。PCA(n_compoents = None):當(dāng)n_compoents為小數(shù)時(shí),降維到百分比(0-1之間,90%-95%最好);整數(shù)時(shí)降到相應(yīng)個(gè)數(shù),將數(shù)據(jù)分解為較低維度空間PCA.fit_transform(X);返回值:轉(zhuǎn)換后指定維度的array。
def?pca():
'''
主成分分析,數(shù)據(jù)特征降維
指定減少后的維度
調(diào)用fit_transform
:return:
'''
pca?=?PCA(n_components?=?0.9)
data?=?pca.fit_transform([[2,8,4,5],[6,3,0,8],[5,4,9,1]])
print(data)
'''
[[?1.28620952e-15?3.82970843e+00]
[?5.74456265e+00?-1.91485422e+00]
[-5.74456265e+00?-1.91485422e+00]]
'''
return?None
二、數(shù)據(jù)降維實(shí)例
InstaInstacart市場(chǎng)籃子分析cart市場(chǎng)籃子分析
products 商品信息:product_id,aisle_id,department_id
order_products__prior 訂單與商品的信息:order_id,product_id,
orders 用戶的訂單信息:? order_id,user_id,
aisles 商品所屬具體物品類別:aisle_id
products ,order_products_prior,以及兩表合并的數(shù)據(jù)如圖:
def?groupByUser():
'''
products?商品信息?product_id,aisle_id,department_id
order_products__prior?訂單與商品的信息?order_id,product_id,
orders?用戶的訂單信息:?order_id,user_id,
aisles?商品所屬具體物品類別?aisle_id
數(shù)據(jù)降維,將用戶分類
:return:
'''
#數(shù)據(jù)處理:先讀取四張表
products?=?pd.read_csv(r"./files/products.csv")
prior?=?pd.read_csv(r'./files/order_products__prior.csv')
oriders?=?pd.read_csv(r'./files/orders.csv')
aisles?=?pd.read_csv(r"./files/aisles.csv")
#將四張表數(shù)據(jù)合并為一張表
#?print(products.head())
#?print(prior.head())
df1?=?pd.merge(products,prior,left_on="product_id",right_on="product_id")
#?print(df1.head())
df2?=?pd.merge(df1,oriders,on=["order_id","order_id"])
df3?=?pd.merge(df2,aisles,on=["aisle_id","aisle_id"])
print(df3.head())
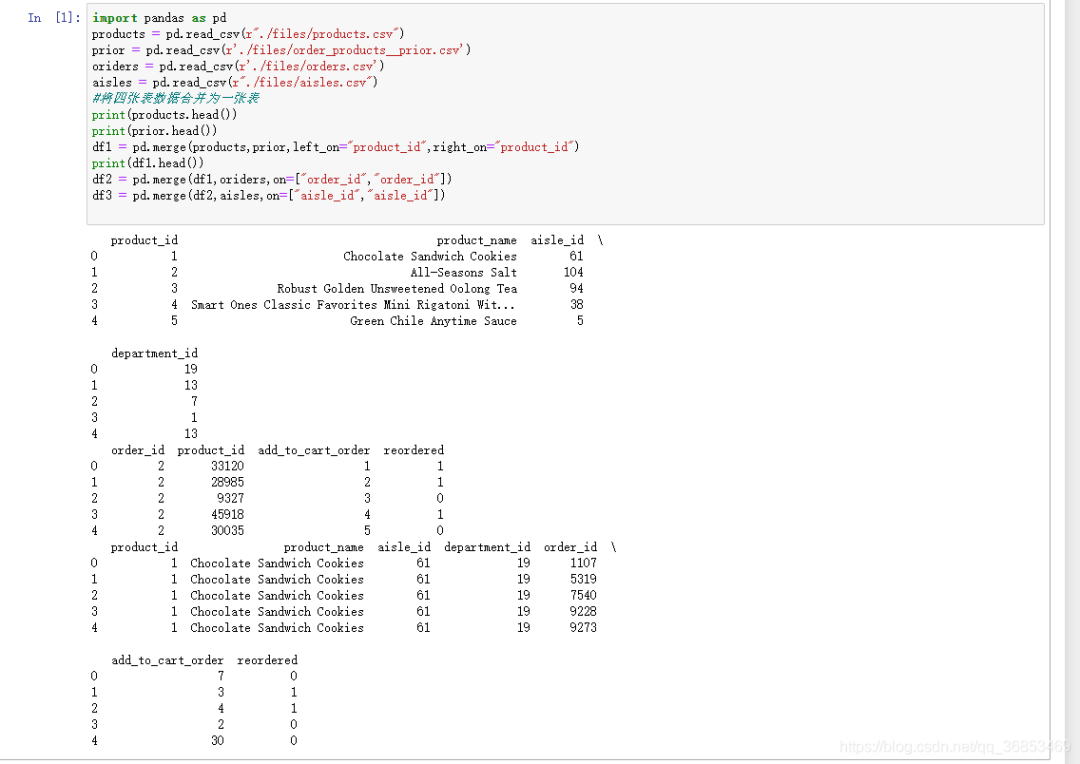
數(shù)據(jù)交叉
#交叉表:特殊的分組工具
cross?=?pd.crosstab(df3.user_id,df3.aisle)
print(cross.head())?#每個(gè)人買了多少個(gè)某個(gè)商品?10行?134個(gè)樣本特征
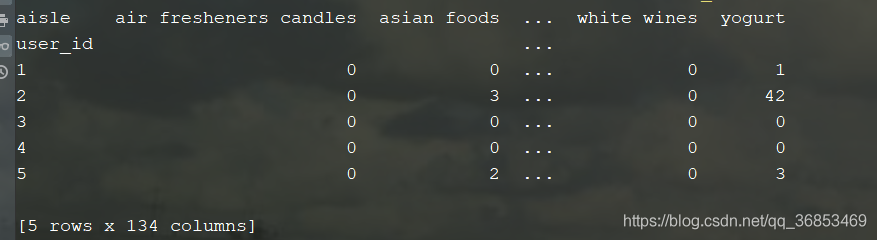
進(jìn)行主成分分析
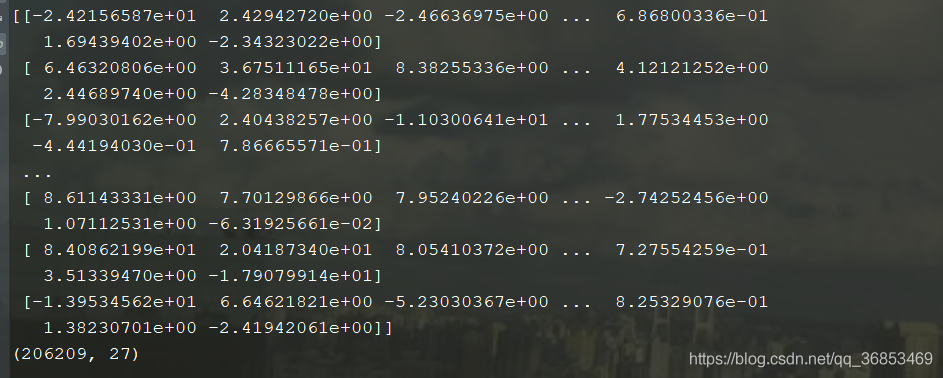
pca?=?PCA(n_components=0.9)
data?=?pca.fit_transform(cross)
print(data)
print(data.shape)?#27個(gè)特征
《數(shù)據(jù)科學(xué)與人工智能》公眾號(hào)推薦朋友們學(xué)習(xí)和使用Python語(yǔ)言,需要加入Python語(yǔ)言群的,請(qǐng)掃碼加我個(gè)人微信,備注【姓名-Python群】,我誠(chéng)邀你入群,大家學(xué)習(xí)和分享。
? ? 關(guān)于Python語(yǔ)言,有任何問(wèn)題或者想法,請(qǐng)留言或者加群討論。