
索引為什么能提高查詢性能....

前言
昨天,有個女孩子問我提高數(shù)據(jù)庫查詢性能有什么立竿見影的好方法?
這簡直是一道送分題,我自豪且略帶鄙夷的說,當(dāng)然是加「索引」了。
她又不緊不慢的問,索引為什么就能提高查詢性能。
這還用問,索引就像一本書的目錄,用目錄查當(dāng)然很快。
她失望地?fù)u了搖頭,你說的只是一個類比,可為什么通過目錄就能提高查詢速度呢。
唉,對啊,通過書目可以快速查詢,這只是一個現(xiàn)象,真正原因到底是什么呢。
那女孩看著詫異且表情僵硬的我,滿意而又意味深長的笑笑:原來你這個男程序員也不會,看來我還得靠自己研究了。
哎,熬夜又要憔悴了我這該死的美貌。
來自同行的羞辱,是可忍孰不可忍?!
于是,我踏上了數(shù)據(jù)庫索引學(xué)習(xí)的不歸路,原來數(shù)據(jù)庫索引使用了一種叫 B+ 樹的古老數(shù)據(jù)結(jié)構(gòu),當(dāng)然也有 Hash 等類型,暫且不說,可 B+ 樹 這是個什么妖魔鬼怪呢?
下面就來淺嘗輒止的扒一扒樹的前世今生。
正文
二叉樹
由 n( n > 0)個有限節(jié)點組成一個具有層次關(guān)系的集合,看起來就像一個倒掛的樹,因此稱這樣的數(shù)據(jù)結(jié)構(gòu)為樹。
一個節(jié)點的子節(jié)點個數(shù)叫做度,通俗的講就是樹叉的個數(shù)。樹中最大的度叫做樹的度,也叫做階。一個 2 階樹最多有 2 個子節(jié)點即最多有 2 叉,因此這樣的樹稱為二叉樹,二叉樹是樹家族中最簡單的樹。
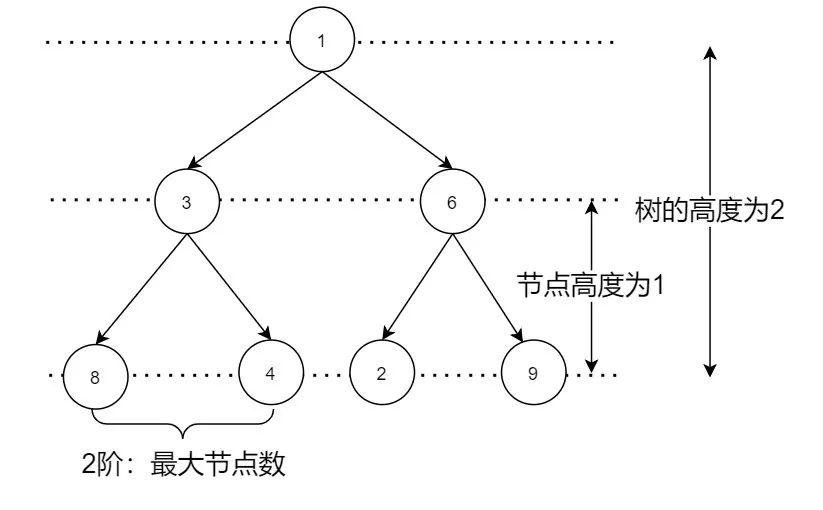
兩個叉的樹就是二叉樹,可這除了用來按一定結(jié)構(gòu)存放數(shù)據(jù)外,跟查詢性能好像也沒關(guān)系,不會又是一個沒用的噱頭吧。
二分查找
聽說二叉樹的原始威力來源于一種叫做二分查找的算法。
相傳在鸚鵡的原始社會,存在著森嚴(yán)的等級制度,每只鳥必須按高矮順序分出等級和尊卑。
那么問題來了,如下圖,怎樣才能找出最高、最矮、中等高的那些鸚鵡呢、以及指定高度的那只呢?

第一種方法: 掃描法
一個一個依次測量,完畢后所有的問題都迎刃而解。
這種一個一個依次全部測量的方法叫做掃描,他的缺點很明顯,最高和最矮,需要全部測量完畢才能知曉。
而對于指定高度,最好的情況是第一次就找到;最壞的情況是最后一次才找到,時間復(fù)雜度為 n,也就是說從 13 個鸚鵡中找到指定身高的那只,最壞的情況是查 13 次。
第二種方法:二分法
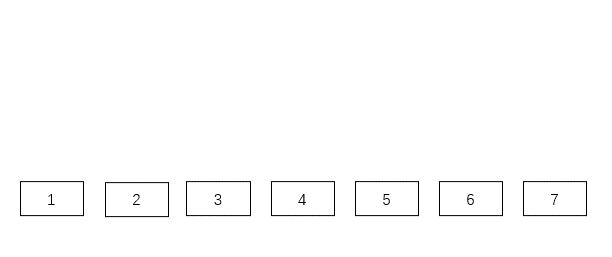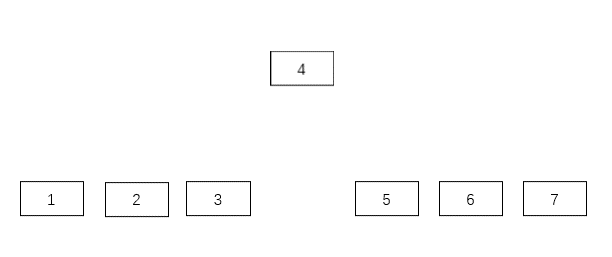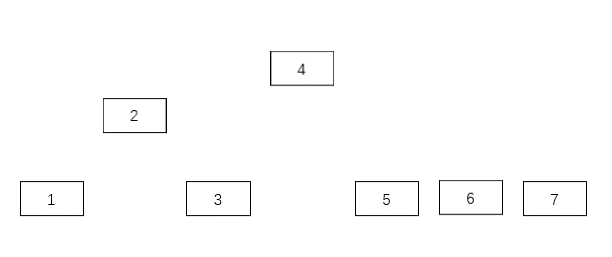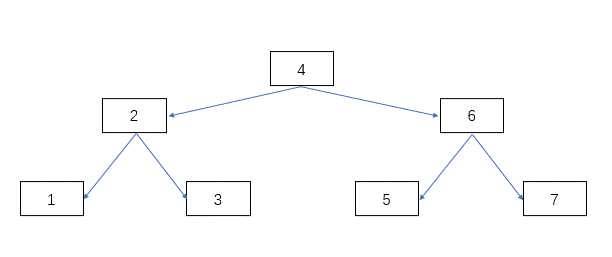
13 個鸚鵡全部聽令,按從矮到高列隊,向左看齊,報數(shù)。

報數(shù)字 1 的就是最矮的,報數(shù)字 13 的就是最高的,報數(shù)字 7 的就是中等身高的那只。
最好和最壞的情況都是一次找到。而查詢性能一下子提高 13 倍,我的個乖乖,無論多個只鸚鵡,時間復(fù)雜度都是 1,好可怕。
問題:我不服,你這是偷換概念,有本事對比一個查找指定高度鸚鵡的性能。
因為鸚鵡們已經(jīng)按高矮排好了隊,所以指定高度的鸚鵡,要么是站中間那個只,要么就是在它的左邊或右邊的那群里。
如果是中間那個,一次就找到,如果不是只需要從中間左邊或右邊那一半中找,再在這一半中找中間那只,對比身高。
以此類推,每次都把查詢的范圍減半,時間復(fù)雜度log2(n)。
那么 log2(13) 就是 4,最壞的情況也才 4 次,時間復(fù)雜度確實不是 1 了,但好像也不糟,簡化如下:

問題:如果按高矮排隊,仍然需要一個一個比較,跟掃描有什么區(qū)別,那還不如直接掃描呢?
事實確實如此,單純的一次查詢,先排序,再二分查找,不見得比掃描快,甚至還不如。
但是,在數(shù)據(jù)的世界,大部分?jǐn)?shù)據(jù)一生會被查詢無數(shù)次,如果只在數(shù)據(jù)降生的時候排一次序,往后余生,是不是就可以直接用二分查找,這似乎就是傳說的讀多寫少,以及對應(yīng)的復(fù)用。
優(yōu)點:
查找快
缺點:
必須有序,需要提前排序
每次查找都需要不斷計算中間位置
二分查找樹
如果一組數(shù)據(jù)不會或不常變更,那么他們的位置也基本不變。可是每次查詢都需要重新計算中間位置是一種浪費,而浪費可恥。
我們能不能把所有中間節(jié)點組織起來,每次使用時,直接取中間節(jié)點?
請看下圖,找到所有單次二分查找的中間節(jié)點,把他們連起來,并用手提起最中間的那個節(jié)點,就是一棵二分查找樹。
優(yōu)點:二分查找樹就是通過數(shù)據(jù)結(jié)構(gòu)的方式實現(xiàn)了二分查找算法,通過存儲中間節(jié)點的數(shù)據(jù),彌補了二分查找每次都要計算中間位置的缺點。
平衡二叉樹:
如果二分查找樹不斷進(jìn)行修改,比如刪除某些節(jié)點,經(jīng)過一段時間后,最早那個中間節(jié)點的數(shù)據(jù)(根),很可能就不在中間了。
中間位置就像一個天平的支點,如果他不在中間了,那么整個天平就會失衡,失衡的世界就會坍塌成不倫不類的瘸樹,甚至是降維成一個鏈表或者數(shù)組。
二分查找算法的關(guān)鍵在于有序和中間節(jié)點,而二分查找樹的關(guān)鍵是中間節(jié)點的維護(hù),如果維護(hù)的節(jié)點已經(jīng)不在中間了,那么它就失去了意義。
所以必須保證「二分查找樹」是一個正確的樹,一個根節(jié)點在中心的樹,一個左右子樹層級(高度)基本相等(高度相差不超過1)的樹,一個平衡的樹。
平衡二叉樹中最常見的就是紅黑樹:
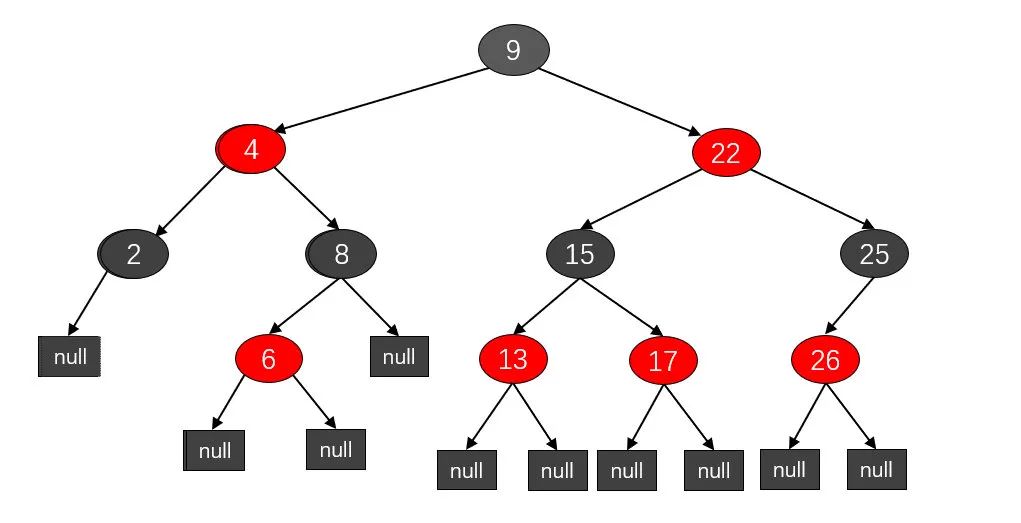
紅黑樹規(guī)定了一系列節(jié)點顏色規(guī)則,以及對應(yīng)的左旋和右旋操作來保證顏色規(guī)則,從而達(dá)到樹的平衡性。
看到這花里胡哨的顏色以及復(fù)雜的規(guī)則,讓人第一眼就望而卻步,但所有的這些,也不過是為了保證二叉樹的平衡性,由于維持平衡的操作太過麻煩,無法用一句話簡單概括,只好用一堆人鬼難分的規(guī)則和步驟來實現(xiàn),只要按著這些步驟就一定能實現(xiàn)二叉樹的平衡。
平衡二叉樹 ?= ?二分查找樹 + 平衡(左右高度相差不超過 1 )
平衡二叉樹并未提高二分查找樹的性能,它只是保正樹不會被二向箔(多次增刪改)打擊降維成鏈表或不對稱的殘缺樹,永遠(yuǎn)維持平衡。
另外,不僅僅是二叉樹,其他種類的樹,也是需要有序和平衡,才能發(fā)揮最大的威力。
多叉樹之 B-tree
兩個叉的樹就能折半查詢,理論可以提高一倍性能,那么多個叉是不是能提高更多倍性能?
如下圖的 3 階(叉)樹(所有數(shù)據(jù)僅用于演示,非真實分布)
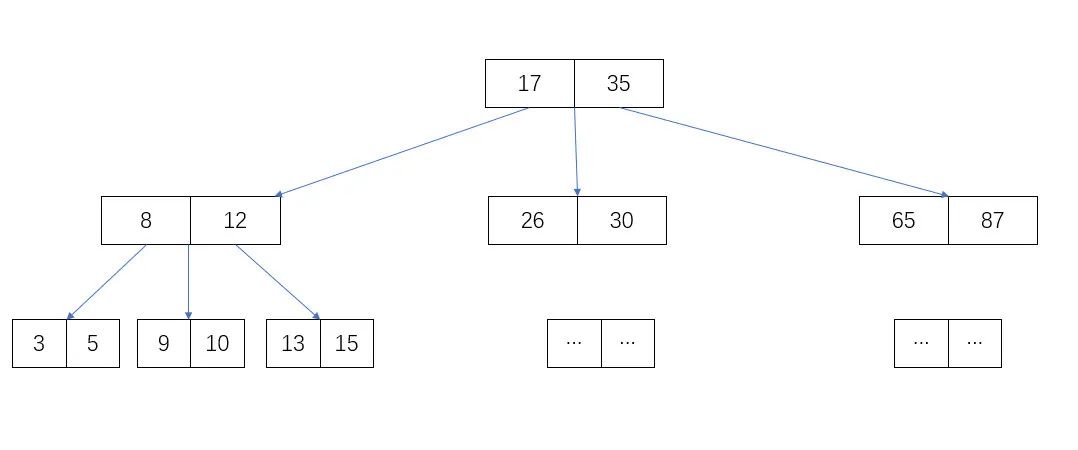
每個節(jié)點維護(hù)兩個數(shù)據(jù),并指向最多 3 個子節(jié)點。如圖 3 個子節(jié)點的數(shù)據(jù)分別為:小于 17, 17 ~ 35 ,大于 35。
假設(shè),從上圖中查找 10 這個數(shù),步驟如下:
找到根節(jié)點,對比 10 與 17 和 35 的大小,發(fā)現(xiàn) 10 < 17 在左子節(jié)點,也就是第 2 層節(jié)點;
從根節(jié)點的指針,找到左子節(jié)點,對比 10 與 8 和 12 的大小,發(fā)現(xiàn) 8 < 10 < 12,數(shù)據(jù)在當(dāng)前節(jié)點的中間子節(jié)點,也就是第 3 層節(jié)點;
通過上步節(jié)點的指針,找到中間子節(jié)點(第 3 層節(jié)點),對比 10 與 9 和 10 的大小,發(fā)現(xiàn) 9 < 10 == 10,因此找到當(dāng)前節(jié)點的第二數(shù)即為結(jié)果。
加上忽略的 12 個數(shù)據(jù),從 26 個數(shù)據(jù)中查找一個數(shù)字 10,僅僅用了?log3(26) 3 次,而如果用平衡二叉樹,則需要 log2(26) 5 次,事實證明,多叉樹確實可以再次提高查找性能。
多叉樹是在二分查找樹的基礎(chǔ)上,增加單個節(jié)點的數(shù)據(jù)存儲數(shù)量,同時增加了樹的子節(jié)點數(shù),一次計算可以把查找范圍縮小更多。
優(yōu)點:二叉平衡樹的基礎(chǔ)上,使加載一次節(jié)點,可以加載更多路徑數(shù)據(jù),同時把查詢范圍縮減到更小。
復(fù)雜節(jié)點:
至此,我們列舉的數(shù)據(jù)都是孤零零的單個數(shù)字。試想,你手里已經(jīng)有一個數(shù)據(jù) 10,為什么還要費力吧唧的再從一堆數(shù)據(jù)中找到這個 10,自己找自己?這不是有病嗎?
單個數(shù)字只能活在演示中,現(xiàn)實的世界要復(fù)雜的多,我們來看一個接近真實場景的案例。
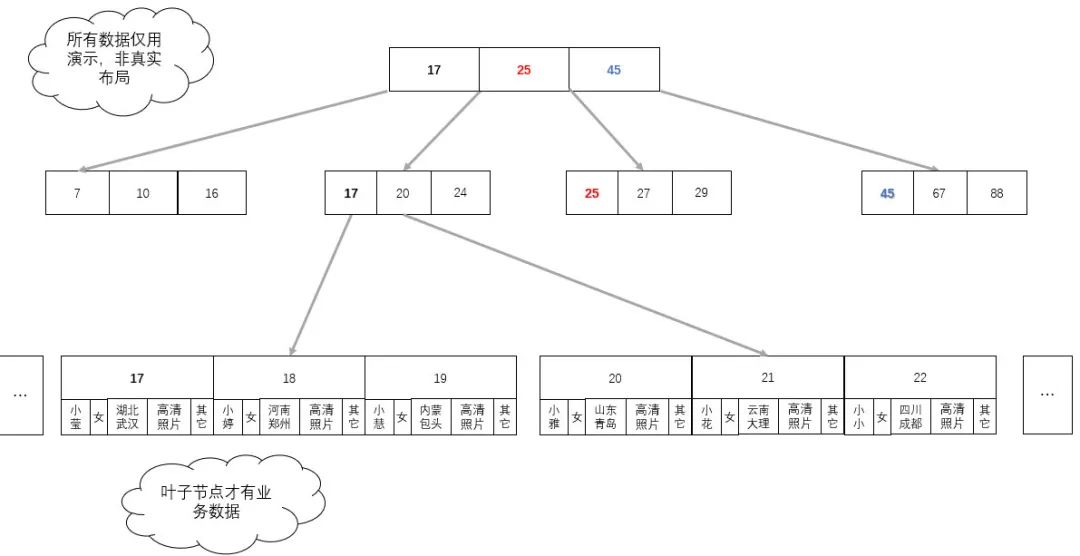
現(xiàn)有一個以年齡為索引的 3 階樹,存儲了一批用戶信息,如下圖:
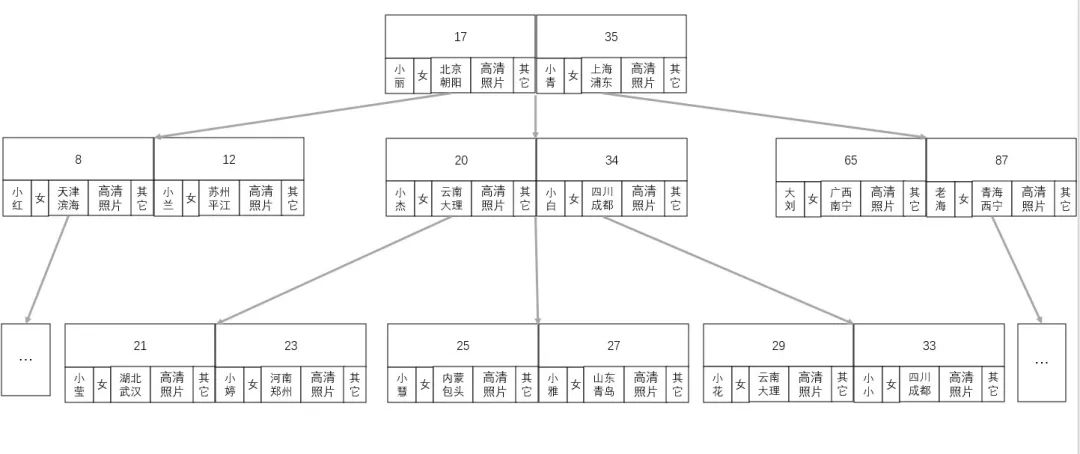
數(shù)字為用戶的年齡,其它為與樹排序查找無關(guān)的業(yè)務(wù)數(shù)據(jù),像這種索引數(shù)據(jù)與樹排序查找無關(guān)的業(yè)務(wù)一起維護(hù)在節(jié)點的平衡多叉(階)樹稱為 B- 樹( B 樹)。
缺點:業(yè)務(wù)數(shù)據(jù)的大小可能遠(yuǎn)遠(yuǎn)超過了索引數(shù)據(jù)的大小,每次為了查找對比計算,需要把數(shù)據(jù)加載到內(nèi)存以及 CPU 高速緩存中時,都要把索引數(shù)據(jù)和無關(guān)的業(yè)務(wù)數(shù)據(jù)全部查出來。本來一次就可以把所有索引數(shù)據(jù)加載進(jìn)來,現(xiàn)在卻要多次才能加載完。如果所對比的節(jié)點不是所查的數(shù)據(jù),那么這些加載進(jìn)內(nèi)存的業(yè)務(wù)數(shù)據(jù)就毫無用處,全部拋棄。
磁盤I/O
計算機(jī)的功能主要為:計算、存儲和網(wǎng)絡(luò)。而用于計算的數(shù)據(jù)以及計算后的結(jié)果很大一部分都需要存儲起來,以備后續(xù)再次使用。向磁盤中存儲和讀取的過程叫磁盤 I/O。磁盤的讀取方式和速度會嚴(yán)重影響到整個業(yè)務(wù)的計算性能。
下面我們簡單了解一下磁盤是如何工作的。
磁盤大概長這個樣子:

磁盤主要由磁盤盤片、傳動手臂、讀寫磁頭和馬達(dá)組成。
為了存儲容量,主軸像穿糖葫蘆一樣把多個磁盤片組成一個陣列。通過馬達(dá)驅(qū)動主軸轉(zhuǎn)動以及傳動手臂移動,使讀寫磁頭在磁盤片上讀寫數(shù)據(jù)。大概如下:
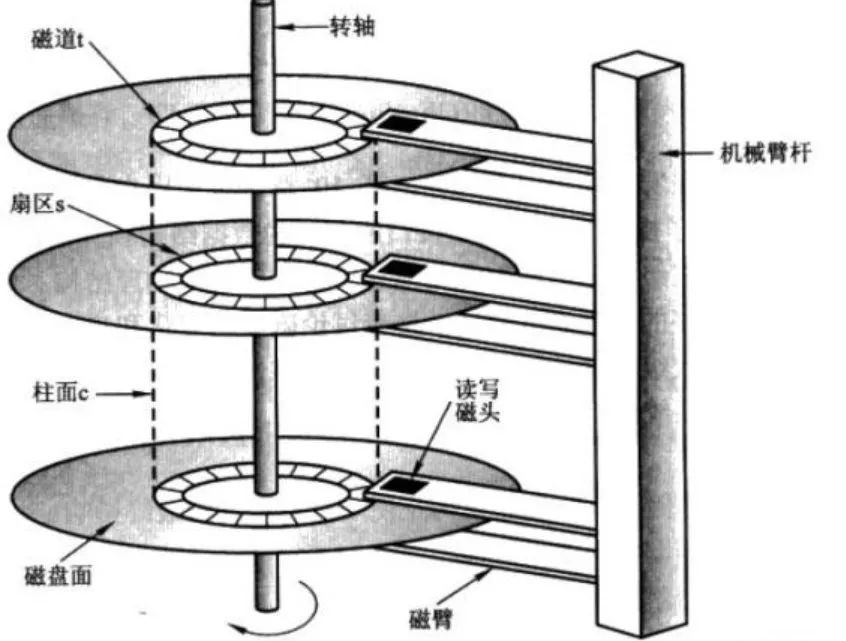
磁盤片由很多半徑不等的同心圓組成,這些圓被稱為磁道,數(shù)據(jù)就是寫在這些磁道上。

每個磁道又劃分成塊稱為扇區(qū)。
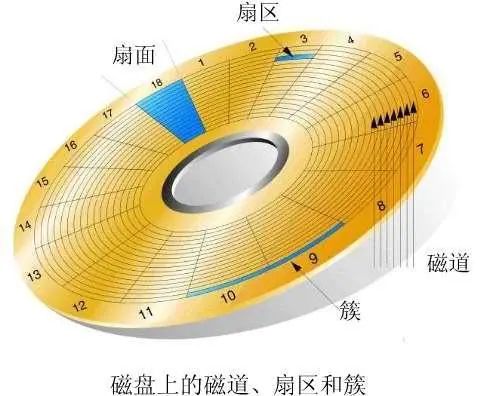
如果磁盤是一記事本,那么一張磁盤片就是本子的一頁紙,而主軸就是本子的裝訂線;磁道就是紙頁的行,而扇區(qū)可以看作是很寬的列。

如果在磁盤中存儲一首詩,想象中大概這個樣子。

磁盤的讀 I/O 操作,需要找到數(shù)據(jù)所在的磁盤片,以及對應(yīng)的磁道和扇區(qū)。這些操作類似于從一本書中找到數(shù)據(jù)所在的頁,行,列。
因為每個磁盤片都對應(yīng)一個磁頭,所以性能的關(guān)鍵就在于找行和列,即尋道和磁盤旋轉(zhuǎn)。尋道即通過磁頭找到數(shù)據(jù)所在的磁道,相當(dāng)于換行到數(shù)據(jù)所在行。由于磁頭只能水平移動,即只能換行尋道,無法在指定磁道上移動,因此需要磁盤高速旋轉(zhuǎn)移動到指定扇區(qū),類似寫春聯(lián)時,筆不動,紙動。

綜上所述,磁盤的讀寫是通過機(jī)械運動來定位數(shù)據(jù)所在位置,而 cpu 是通過電信號進(jìn)行數(shù)字運算。粗略的認(rèn)為,機(jī)械查詢數(shù)據(jù),與光速處理數(shù)據(jù)的性能完全不是在一個量級,總之一句話就是磁盤處理太慢太慢了。
雖然磁盤處理數(shù)據(jù)太慢了,但是它是目前相對廉價且穩(wěn)定的存儲設(shè)備,所以又不能舍棄不用,但大致可以通過以下方法進(jìn)行優(yōu)化。
盡量減少 I/O 次數(shù),比如可以使用緩存;
每次 I/O 盡量獲取更多的數(shù)據(jù);
每次 I/O 盡量獲取有用的數(shù)據(jù),當(dāng)然相應(yīng)的也間接減少總 I/O 次數(shù);
多叉樹之 B+tree
做為數(shù)據(jù)庫的索引,無論用什么樣的數(shù)據(jù)結(jié)構(gòu)維護(hù),這些數(shù)據(jù)最終都會存儲到磁盤中。
鑒于磁盤 ?I/O 的性能問題,以及每次 I/O 獲取數(shù)據(jù)量上限所限,提高索引本身 I/O 的方法最好是,減少 I/O 次數(shù)和每次獲取有用的數(shù)據(jù)。
B-tree 已經(jīng)大大改進(jìn)了樹家族的性能,它把多個數(shù)據(jù)集中存儲在一個節(jié)點中,本身就可能減少了 I/O 次數(shù)或者尋道次數(shù)。
但是仍然有一個致命的缺陷,那就是它的索引數(shù)據(jù)與業(yè)務(wù)綁定在一塊,而業(yè)務(wù)數(shù)據(jù)的大小很有可能遠(yuǎn)遠(yuǎn)超過了索引數(shù)據(jù),這會大大減小一次 I/O 有用數(shù)據(jù)的獲取,間接的增加 I/O 次數(shù)去獲取有用的索引數(shù)據(jù)。
因為業(yè)務(wù)數(shù)據(jù)才是我們查詢最終的目的,但是它又是在「二分」查找中途過程無用的數(shù)據(jù),因此,如果只把業(yè)務(wù)數(shù)據(jù)存儲在最終查詢到的那個節(jié)點是不是就可以了?
理想很豐滿,現(xiàn)實很骨瘦如柴,誰知道哪個節(jié)點就是最終要查詢的節(jié)點呢?
B+tree 橫空出世,B+ 樹就是為了拆分索引數(shù)據(jù)與業(yè)務(wù)數(shù)據(jù)的平衡多叉樹。
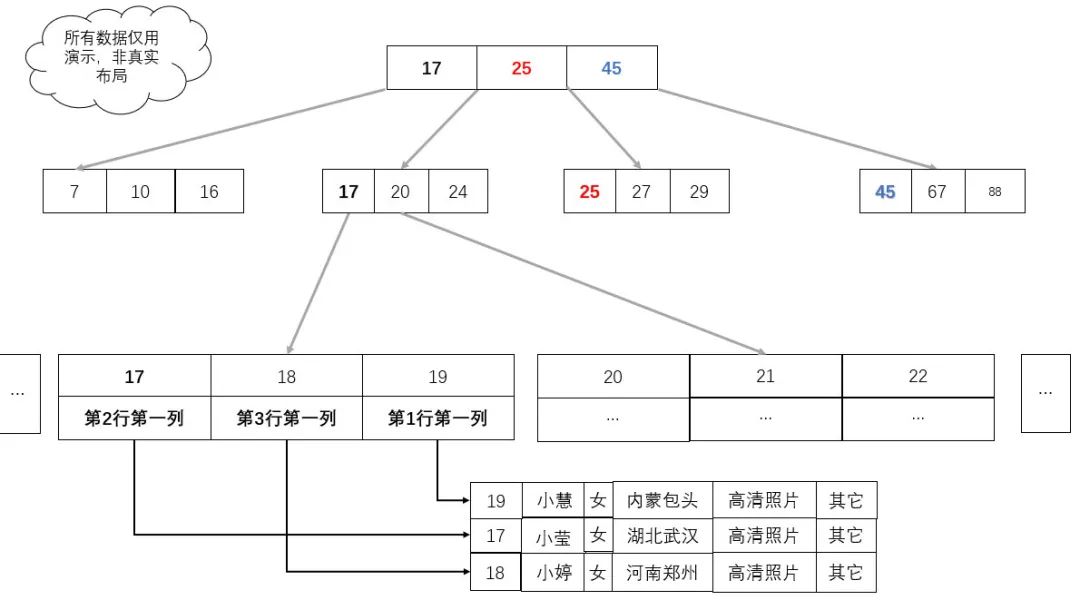
B+ 樹中,非葉子節(jié)點只保存索引數(shù)據(jù),葉子節(jié)點保存索引數(shù)據(jù)與業(yè)務(wù)數(shù)據(jù)。這樣即保證了葉子節(jié)點的簡約干凈,數(shù)據(jù)量大大減小,又保證了最終能查到對應(yīng)的業(yè)務(wù)數(shù)。既提高了單次 I/O 數(shù)據(jù)的有效性,又減少了 I/O 次數(shù),還實現(xiàn)了業(yè)務(wù)。
但是,在數(shù)據(jù)中索引與數(shù)據(jù)是分離的,不像示例那樣的?
如圖:我們只需要把真實的業(yè)務(wù)數(shù)據(jù),換成數(shù)據(jù)所在地址就可以了,此時,業(yè)務(wù)數(shù)據(jù)所在的地址在 B+ 樹中充當(dāng)業(yè)務(wù)數(shù)據(jù)。
總結(jié)
數(shù)據(jù)存儲在磁盤( SSD 跟 CPU 性能也不在一個量級),而磁盤處理數(shù)據(jù)很慢;
提高磁盤性能主要通過減少 I/O 次數(shù),以及單次 I/O 有效數(shù)據(jù)量;
索引通過多階(一個節(jié)點保存多個數(shù)據(jù),指向多個子節(jié)點)使樹的結(jié)構(gòu)更矮胖,從而減少 I/O 次數(shù);
索引通過 B+ 樹,把業(yè)務(wù)數(shù)據(jù)與索引數(shù)據(jù)分離,來提高單次 I/O 有效數(shù)據(jù)量,從而減少 I/O 次數(shù);
索引通過樹數(shù)據(jù)的有序和「二分查找」(多階樹可以假設(shè)為多分查找),大大縮小查詢范圍;
索引針對的是單個字段或部分字段,數(shù)據(jù)量本身比一條記錄的數(shù)據(jù)量要少的多,這樣即使通過掃描的方式查詢索引也比掃描數(shù)據(jù)庫表本身快的多;
知識擴(kuò)展
樹的結(jié)構(gòu)最大的優(yōu)點就是查詢性能高,因此所有需要提高查詢性能的都可以考慮樹。
而現(xiàn)實中也確實有這樣的例子,比如:
HashMap 中的數(shù)據(jù)沖突時,鏈表轉(zhuǎn)化成紅黑樹;
數(shù)據(jù)庫索引使用的 B+ 樹;
搜索引擎倒排索引使用的字典樹;
以上只是淺嘗輒止、點到為止的描述了數(shù)據(jù)庫使用 B+ 樹索引為什么能提高查詢性能原因及簡單過程。
并沒有深入各種數(shù)據(jù)結(jié)構(gòu)的細(xì)節(jié),也未提及其它索引類型和索引的具體存儲格式,目的僅僅是,為了讓大家對索引有一個感性的認(rèn)識。
好文推薦
涼了!張三同學(xué)沒答好「進(jìn)程間通信」,被面試官掛了….
哈嘍,我是小林,就愛圖解計算機(jī)基礎(chǔ),如果覺得文章對你有幫助,歡迎分享給你的朋友,也給小林點個「在看」,這對小林非常重要,謝謝你們,給各位小姐姐小哥哥們抱拳了,我們下次見!