
談?wù)凪YSQL索引是如何提高查詢效率的
文章已收錄Github精選,歡迎Star:https://github.com/yehongzhi/learningSummary
前言
我們都知道當查詢數(shù)據(jù)庫變慢時,需要建索引去優(yōu)化。但是只知道索引能優(yōu)化顯然是不夠的,我們更應(yīng)該知道索引的原理,因為不是加了索引就一定會提升性能。那么接下來就一起探索MYSQL索引的原理吧。
什么是索引
索引其實是一種能高效幫助MYSQL獲取數(shù)據(jù)的數(shù)據(jù)結(jié)構(gòu),通常保存在磁盤文件中,好比一本書的目錄,能加快數(shù)據(jù)庫的查詢速度。除此之外,索引是有序的,所以也能提高數(shù)據(jù)的排序效率。
通常MYSQL的索引包括聚簇索引,覆蓋索引,復(fù)合索引,唯一索引,普通索引,通常底層是B+樹的數(shù)據(jù)結(jié)構(gòu)。
總結(jié)一下,索引的優(yōu)勢在于:
提高查詢效率。 降低數(shù)據(jù)排序的成本。
缺點在于:
索引會占用磁盤空間。 索引會降低更新表的效率。因為在更新數(shù)據(jù)時,要額外維護索引文件。
索引的類型
聚簇索引
索引列的值必須是唯一的,并且不能為空,一個表只能有一個聚簇索引。
唯一索引
索引列的值是唯一的,值可以為空。
普通索引
沒有什么限制,允許在定義索引的列中插入重復(fù)值和空值。
復(fù)合索引
也叫組合索引,用戶可以在多個列上組合建立索引,遵循“最左匹配原則”,在條件允許的情況下使用復(fù)合索引可以替代多個單列索引的使用。
索引的數(shù)據(jù)結(jié)構(gòu)
我們都知道索引的底層數(shù)據(jù)結(jié)構(gòu)采用的是B+樹,但是在講B+樹之前,要先知道B樹,因為B+樹是在B樹上面進行改進優(yōu)化的。
首先講一下B樹的特點:
B樹的每個節(jié)點都存儲了多個元素,每個內(nèi)節(jié)點都有多個分支。 節(jié)點中元素包含鍵值和數(shù)據(jù),節(jié)點中的鍵值從小到大排序。 父節(jié)點的數(shù)據(jù)不會出現(xiàn)在子節(jié)點中。 所有的葉子節(jié)點都在同一層,葉節(jié)點具有相同的深度。
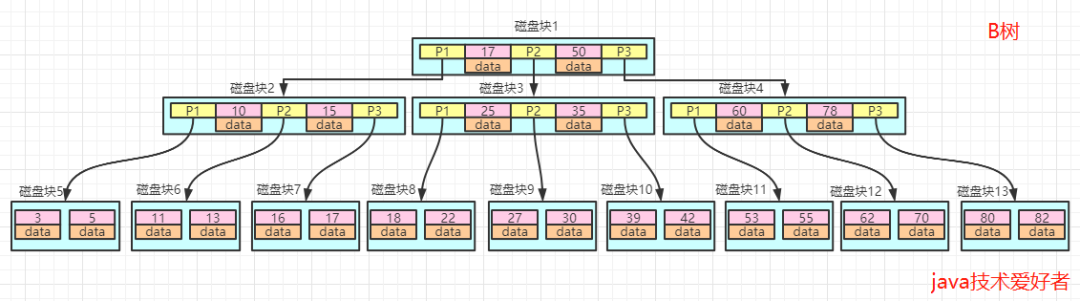
在上面的B樹中,假如我們要找值等于18的數(shù)據(jù),查找路徑就是磁盤塊1->磁盤塊3->磁盤塊8。
過程如下:
第一次磁盤IO:首先加載磁盤塊1到內(nèi)存中,在內(nèi)存中遍歷比較,因為17<18<50,所以走中間P2,定位到磁盤塊3。
第二次磁盤IO:加載磁盤塊3到內(nèi)存,依然是遍歷比較,18<25,所以走左邊P1,定位到磁盤塊8。
第三次磁盤IO:加載磁盤塊8到內(nèi)存,在內(nèi)存中遍歷,18=18,找到18,取出data。
如圖所示:
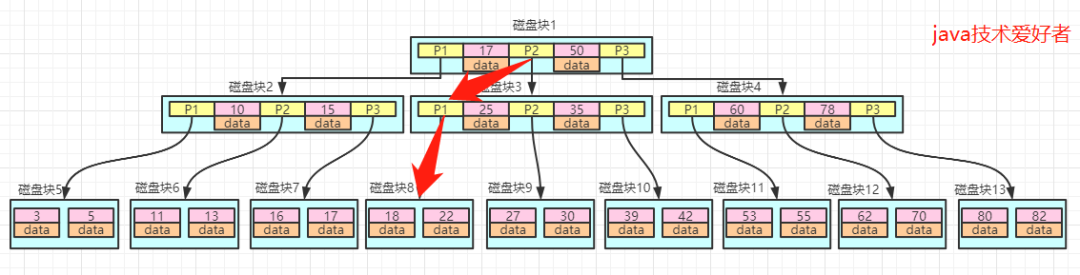
如果data存儲的是行數(shù)據(jù),直接返回,如果存的是磁盤地址則根據(jù)磁盤地址到磁盤中取出數(shù)據(jù)。可以看出B樹的查詢效率是很高的。
B樹存在著什么問題,需要改進優(yōu)化呢?
第一個問題:B樹在范圍查詢時,性能并不理想。假如要查詢13到30之間的數(shù)據(jù),查詢到13后又要回到根節(jié)點再去查詢后面的數(shù)據(jù),就會產(chǎn)生多次的查詢遍歷。
第二個問題:因為非葉子節(jié)點和葉子節(jié)點都會存儲數(shù)據(jù),所以占用的空間大,一個頁可存儲的數(shù)據(jù)量就會變少,樹的高度就會變高,磁盤的IO次數(shù)就會變多。
基于以上兩個問題,就出現(xiàn)了B樹的升級版,B+樹。
B+樹與B樹最大的區(qū)別在于兩點:
B+樹只有葉子節(jié)點存儲數(shù)據(jù),非葉子節(jié)點只存儲鍵值。而B樹的非葉子節(jié)點和葉子節(jié)點都會存儲數(shù)據(jù)。 B+樹的最底層的葉子節(jié)點會形成一個雙向有序鏈表,而B樹不會。
如圖所示:
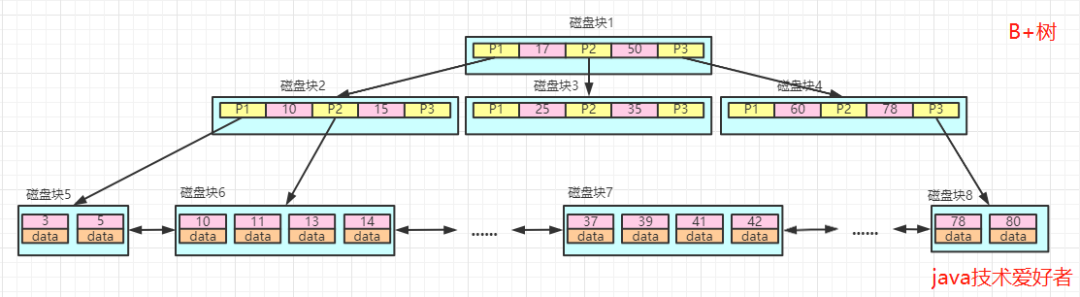
B+樹的等值查詢過程是怎么樣的?
如果在B+樹中進行等值查詢,比如查詢等于13的數(shù)據(jù)。
查詢路徑為:磁盤塊1->磁盤塊2->磁盤塊6。
第一次IO:加載磁盤塊1,在內(nèi)存中遍歷比較,13<17,走左邊,找到磁盤塊2。
第二次IO:加載磁盤塊2,在內(nèi)存中遍歷比較,10<13<15,走中間,找到磁盤塊6。
第三次IO:加載磁盤塊6,依次遍歷,找到13=13,取出data。
所以B+樹在等值查詢的效率是很高的。
B+樹的范圍查詢過程又是怎么樣呢?
比如我們要進行范圍查詢,查詢大于5并且小于15的數(shù)據(jù)。
查詢路徑為:磁盤塊1->磁盤塊2->磁盤塊5->磁盤塊6。
第一次IO:加載磁盤塊1,比較得出5<17,然后走左邊,找到磁盤塊2。
第二次IO:加載磁盤塊2,比較5<10,然后還是走左邊,找到磁盤塊5。
第三次IO:加載磁盤塊5,然后找大于5的數(shù)據(jù)。
第四次IO:由于最底層是有序的雙向鏈表,所以繼續(xù)往右遍歷即可,直到不符合小于15的數(shù)據(jù)為止。
過程如圖所示:
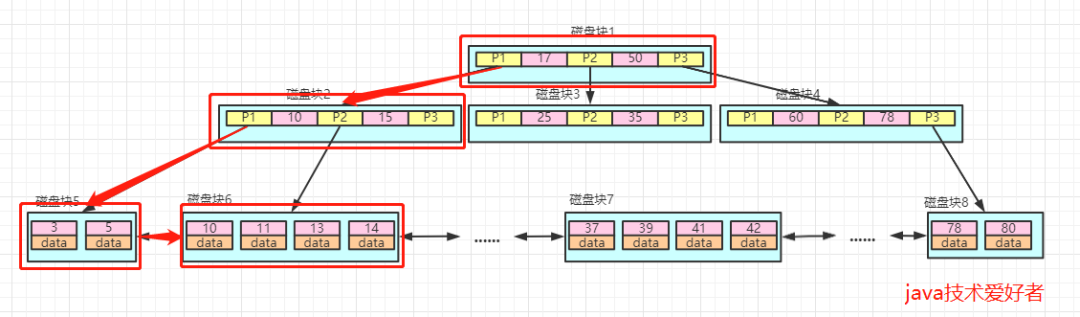
所以在范圍查詢的時候,是不需要像B樹一樣,再回到根節(jié)點,這就是底層采用雙向鏈表的好處。
所以B+樹的優(yōu)勢在于,能保證等值查詢和范圍查詢的快速查找。
InnoDB索引
我們常用的MySQL存儲引擎一般是InnoDB,所以接下來講講幾種不同的索引的底層數(shù)據(jù)結(jié)構(gòu),以及查找過程。
聚簇索引
前面講過,每個InnoDB表有且僅有一個聚簇索引。除此之外,聚簇索引在表的創(chuàng)建有以下幾點規(guī)則:
在表中,如果定義了主鍵,InnoDB會將主鍵索引作為聚簇索引。 如果沒有定義主鍵,則會選擇第一個不為NULL的唯一索引列作為聚簇索引。 如果以上兩個都沒有。InnoDB 會使用一個6 字節(jié)長整型的隱式字段 ROWID字段構(gòu)建聚簇索引。該ROWID字段會在插入新行時自動遞增。
除了聚簇索引之外的索引都稱為非聚簇索引,區(qū)別在于,聚簇索引的葉子節(jié)點存儲的數(shù)據(jù)是整行數(shù)據(jù),而非聚簇索引存儲的是該行的主鍵值。
比如有一張user表,如圖所示:
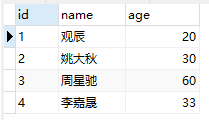
底層的數(shù)據(jù)結(jié)構(gòu)就像這樣:
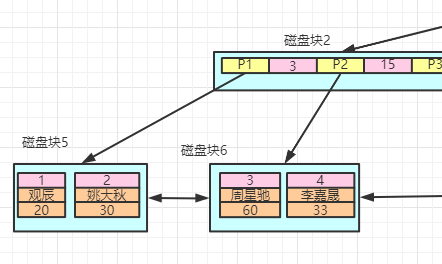
當我們用主鍵值去查詢的時候,查詢效率是很快的,因為可以直接返回數(shù)據(jù)。

普通索引
也就是用得最多的一種索引,比如我要為user表的age列創(chuàng)建索引,SQL語句可以這樣寫:
CREATE INDEX INDEX_USER_AGE ON `user`(age);
普通索引屬于非聚簇索引,所以葉子節(jié)點存儲的是主鍵值,底層的數(shù)據(jù)結(jié)構(gòu)大概長這個樣子:
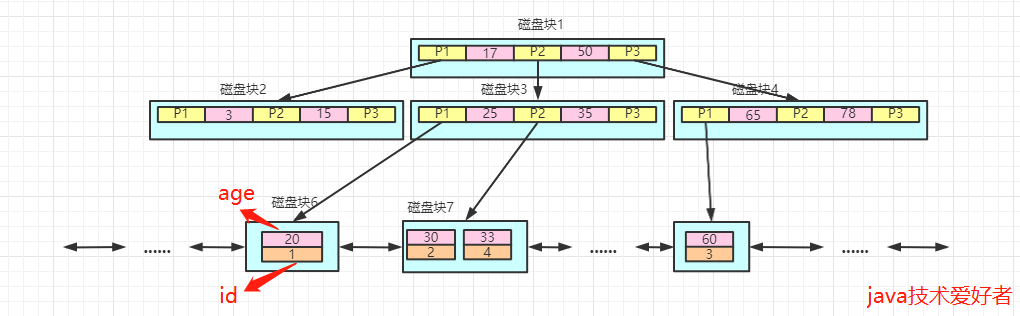
比如要查詢age=33的數(shù)據(jù),那么首先查到磁盤塊7的age=33的數(shù)據(jù),獲取到主鍵值,主鍵值為4。
接著再通過主鍵值等于4,查詢到該行的數(shù)據(jù)。所以總得來說,底層會進行兩次查詢。
這種先通過查詢主鍵值,再通過主鍵值查詢到數(shù)據(jù)的過程就叫做回表查詢。
覆蓋索引
既然上面提到了回表查詢,那么自然而然會想到,有沒有什么辦法能避免回表查詢呢?答案肯定是有的,那就是使用覆蓋索引。
覆蓋索引不是一種索引的類型,而是一種使用索引的方式。假設(shè)你需要查詢的列是建立了索引,查詢的結(jié)果在索引列上就能獲取,那就可以用覆蓋索引。
比如上面的例子,我們通過age=33查詢,我需要查詢的結(jié)果就只要age這一列,那就可以用到覆蓋索引,如圖所示:

使用到覆蓋索引的話,就能避免回表查詢,所以在寫SQL語句時盡量不要寫SELECT *。
總結(jié)
這篇文章主要講的是索引的類型,索引的數(shù)據(jù)結(jié)構(gòu),以及InnoDB表中常用的幾種索引。當然,除了上述講的這些之外,還有很多關(guān)于索引的知識,比如索引失效的場景,索引創(chuàng)建的原則等等,由于篇幅過長,留著以后再講。
那么這篇文章就寫到這里了,感謝大家的閱讀。
覺得有用就點個贊吧,你的點贊是我創(chuàng)作的最大動力~
我是一個努力讓大家記住的程序員。我們下期再見!!!
能力有限,如果有什么錯誤或者不當之處,請大家批評指正,一起學(xué)習(xí)交流!