
【面試招聘】拼多多 AI算法崗面試(附帶解析)
字?jǐn)?shù)統(tǒng)計(jì):2500,預(yù)計(jì)閱讀時(shí)間:12min
參考目錄:
1 介紹項(xiàng)目
2 EfficientNet的特色
3 python撕BN層前向算法
4 線程和進(jìn)程的區(qū)別
5 SVM和邏輯回歸在分類(lèi)上的區(qū)別
6. 有什么人臉檢測(cè)的數(shù)據(jù)集
7. YOLO訓(xùn)練的數(shù)據(jù)集是什么
8. CNN參數(shù)初始化的方法
1 介紹項(xiàng)目
答案:略。
2 EfficientNet的特色
這個(gè)EfficientNet的核心思想是尋找標(biāo)準(zhǔn)化的模型縮放方法,一般來(lái)說(shuō),模型深度、寬度、分辨率越大,那么模型的效果就會(huì)有提高。以前的網(wǎng)絡(luò)一般在某一個(gè)維度上進(jìn)行嘗試,而EfficientNet因?yàn)閳F(tuán)隊(duì)有錢(qián)(google的),愣是在三個(gè)維度上找到了一個(gè)平衡。EfficientNet在圖像競(jìng)賽中也是直接拿來(lái)用,用的也多,所以之后有空把之前寫(xiě)的《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》論文筆記整理整理發(fā)出來(lái)。總之這里回答的關(guān)鍵在于這個(gè)公式:
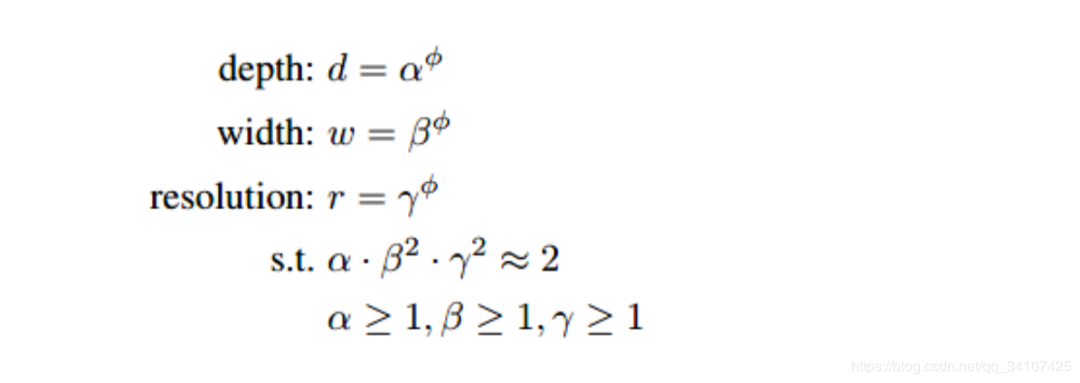
首先讓深度寬度和分辨率滿(mǎn)足一定的條件,當(dāng)的時(shí)候,,然后不斷擴(kuò)大,就可以得到更復(fù)雜的模型了。
3 python撕BN層前向算法
之前的文章詳細(xì)講解了BN的算法,所以這個(gè)不算太難哈哈。核心思想就是把數(shù)據(jù)沿著batch的維度,標(biāo)準(zhǔn)化成均值,標(biāo)準(zhǔn)差的分布。減均值處以方差那種。
小白學(xué)圖像 | BatchNormalization詳解與比較
小白學(xué)圖像 | Group Normalization詳解+PyTorch代碼
(這兩個(gè)一起食用效果更佳哦)
突然一身冷汗,如果要讓我寫(xiě)反向傳播算法的代碼。。。手推能算,代碼的話。。。嘖嘖嘖。
4 線程和進(jìn)程的區(qū)別
進(jìn)程:進(jìn)程是系統(tǒng)進(jìn)行資源分配和調(diào)度的一個(gè)獨(dú)立單位。每個(gè)進(jìn)程都有自己的獨(dú)立內(nèi)存空間。比較穩(wěn)定。線程:線程是CPU調(diào)度和分派的基本單位,它是比進(jìn)程更小的能獨(dú)立運(yùn)行的基本單位.它可與同屬一個(gè)進(jìn)程的其他的線程共享進(jìn)程所擁有的全部資源。但是不夠穩(wěn)定容易丟失數(shù)據(jù)。
【進(jìn)程多與線程比較】
地址空間:線程是進(jìn)程內(nèi)的一個(gè)執(zhí)行單元,進(jìn)程內(nèi)至少有一個(gè)線程,它們共享進(jìn)程的地址空間,而進(jìn)程有自己獨(dú)立的地址空間 資源擁有:進(jìn)程是資源分配和擁有的單位,同一個(gè)進(jìn)程內(nèi)的線程共享進(jìn)程的資源 線程是處理器調(diào)度的基本單位,但進(jìn)程不是 每個(gè)獨(dú)立的線程有一個(gè)程序運(yùn)行的入口、順序執(zhí)行序列和程序的出口,但是線程不能夠獨(dú)立執(zhí)行,必須依存在應(yīng)用程序中,由應(yīng)用程序提供多個(gè)線程執(zhí)行控制
5 SVM和邏輯回歸在分類(lèi)上的區(qū)別
這個(gè)問(wèn)題我也被問(wèn)了兩次了,這里好好整理一下回答的核心:SVM和邏輯回歸其實(shí)是只有損失函數(shù)有不同。這個(gè)問(wèn)題其實(shí)就是讓你分析損失函數(shù)不同對(duì)分類(lèi)的影響。
我們先來(lái)看一下SVM和邏輯回歸的損失函數(shù)(這里帶上了正則項(xiàng)):
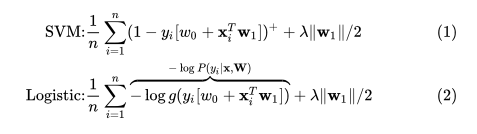
這損失函數(shù)看起來(lái)可能有些別扭,但是其實(shí)是和你內(nèi)心想的那個(gè)是等價(jià)的(把這兩個(gè)公式在紙上抄三遍,你就發(fā)現(xiàn)其實(shí)很好理解的)。在公式(1)中,SVM的損失函數(shù)那個(gè)+號(hào),表示負(fù)數(shù)取0整數(shù)不變的一個(gè)成處理符號(hào)。公式(2)中的是Sigmoid激活函數(shù)。
這兩個(gè)公式其實(shí)可以統(tǒng)一起來(lái):

也就是說(shuō),它們的區(qū)別就在于邏輯回歸采用的是 log loss(對(duì)數(shù)損失函數(shù)),svm采用的是hinge loss = max(0,1-z)。
z是,z越大,說(shuō)明分類(lèi)越準(zhǔn)確,z越小,分類(lèi)越錯(cuò)誤。這里類(lèi)別標(biāo)簽是+1和-1.
SVM損失函數(shù): logistic損失函數(shù):
兩者損失函數(shù)的圖像就是:
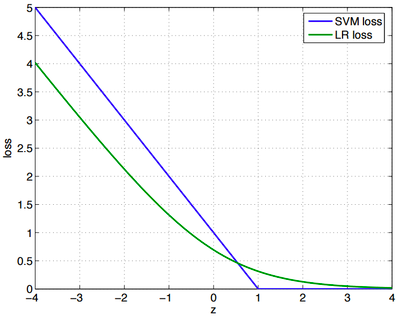
其實(shí),這兩個(gè)損失函數(shù)的目的都是給分類(lèi)錯(cuò)誤的樣本大的損失,給分類(lèi)正確的樣本小的損失。SVM的處理方法是只考慮分類(lèi)效果不夠好的樣本,對(duì)于已經(jīng)分類(lèi)正確的樣本,就不再更新他們了,給他們0損失;邏輯回歸希望正樣本盡可能的大,副樣本盡可能的小,所以就算已經(jīng)分類(lèi)正確了,也還是會(huì)給分類(lèi)正確的樣本一個(gè)損失。
輔導(dǎo)員(SVM)關(guān)心的是掛科邊緣的人,常常找他們談話,告誡他們一定得好好學(xué)習(xí),不要浪費(fèi)大好青春,掛科了會(huì)拿不到畢業(yè)證、學(xué)位證等等,相反,對(duì)于那些相對(duì)優(yōu)秀或者良好的學(xué)生,他們卻很少去問(wèn),因?yàn)檩o導(dǎo)員相信他們一定會(huì)按部就班的做好分內(nèi)的事;有的教師(邏輯回歸)卻不是這樣的,他們關(guān)心的是班里的整體情況,不管你是60分還是90分,都要給我繼續(xù)提升。
6. 有什么人臉檢測(cè)的數(shù)據(jù)集
回答了IMDB-WIKI數(shù)據(jù)庫(kù)。
IMDB-WIKI人臉數(shù)據(jù)庫(kù)是有IMDB數(shù)據(jù)庫(kù)和Wikipedia數(shù)據(jù)庫(kù)組成,其中IMDB人臉數(shù)據(jù)庫(kù)包含了460,723張人臉圖片,而Wikipedia人臉數(shù)據(jù)庫(kù)包含了62,328張人臉數(shù)據(jù)庫(kù),總共523,051張人臉數(shù)據(jù)庫(kù),IMDB-WIKI人臉數(shù)據(jù)庫(kù)中的每張圖片都被標(biāo)注了人的年齡和性別,對(duì)于年齡識(shí)別和性別識(shí)別的研究有著重要的意義。
7. YOLO訓(xùn)練的數(shù)據(jù)集是什么
ImageNet和VOC2007.YOLO v1 好像只用了VOC2007,后面YOLOv2使用了ImageNet作為預(yù)訓(xùn)練。
8. CNN參數(shù)初始化的方法
我說(shuō)了Xavier,然后均勻分布,0初始化,高斯分布初始化,預(yù)訓(xùn)練初始化。
Xavier這個(gè)我之前也在文章中詳細(xì)講解了,就是在這個(gè)范圍內(nèi)均勻分布,其中表示第k層卷積層的參數(shù)。
白話Xavier | 神經(jīng)網(wǎng)絡(luò)初始化的工程選擇
其實(shí)還有一個(gè)HE初始化,這個(gè)的思想和Xavier其實(shí)相同,都是為了讓正向傳播和反向傳播的過(guò)程中,輸入數(shù)據(jù)和輸出數(shù)據(jù)的方差保持不變。最終Xavier是一個(gè)均勻分布,而He初始化是一個(gè)以0為均值,以為標(biāo)準(zhǔn)差的高斯分布。
- END -往期精彩回顧
獲取一折本站知識(shí)星球優(yōu)惠券,復(fù)制鏈接直接打開(kāi):
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群請(qǐng)掃碼進(jìn)群(如果是博士或者準(zhǔn)備讀博士請(qǐng)說(shuō)明):