
【面試招聘】快手 AI算法崗面試及答案解析
文章共2000字,預計閱讀時間10min
參考目錄:
1 自我介紹+項目
2 樣本不均衡的處理方法
3 隨機森林中隨機的意義
4 卷積層的缺點
5 最大池化層 vs 平均池化層?
6 ?隨機森林中bagging的比例為什么是63.2%
7 卷積網(wǎng)絡感受野怎么擴大
8 什么模型需要數(shù)據(jù)標準化?
9 數(shù)據(jù)標準化的目的是什么?
10 如果模型欠擬合怎么辦
11 模型中dropout在訓練和測試的區(qū)別?
12 算法題:數(shù)組的回文遍歷
1 自我介紹+項目
參考答案:略
2 樣本不均衡的處理方法
之前文章講過8種常見的方法:上采樣,下采樣,二分類變成多分類等多模型方法。
3 隨機森林中隨機的意義
隨機對數(shù)據(jù)進行樣本采樣和特征采樣。這個隨機森林的內容之前的文章也講解的非常詳細啦。下面文章比較長,內容比較全。
【小白學ML】隨機森林 全解 (從bagging到variance)
4 卷積層的缺點
反向傳播更新參數(shù)對數(shù)據(jù)的需求量非常大;卷積的沒有平移不變性,稍微改變同一物體的朝向或者位置,會對結果有巨大的改變,雖然數(shù)據(jù)增強會有一定緩解;池化層讓大量圖像特丟失,只關注整體特征,而忽略到局部。比方說,在識別人臉的時候,只要人的五官同時出現(xiàn),那么就會認為這是人臉,因此按照澤中卷積池化的判別方式,下面兩種情況可能會被判斷成同一圖片.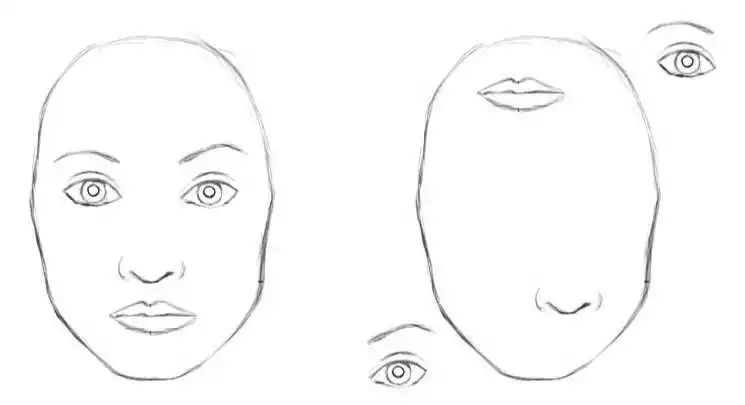
總之,CNN最大的兩個問題在于平移不變性和池化層。
5 最大池化層 vs 平均池化層?
這個我不太確定,當時的回答是:平均池化層會讓特征圖變得更加模糊;最大池化層反向傳播中,計算量會小于平均池化層;最大池化層會增加一定的平移不變性和旋轉不變性給卷積網(wǎng)絡。
根據(jù)相關理論,特征提取的誤差主要來自兩個方面:
鄰域大小受限造成的估計值方差增大; 卷積層參數(shù)誤差造成估計均值的偏移。
一般來說,mean-pooling能減小第一種誤差,更多的保留圖像的背景信息,max-pooling能減小第二種誤差,更多的保留紋理信息。
6 ?隨機森林中bagging的比例為什么是63.2%
關鍵公式:
這個詳細的計算過程也在隨即森林全解的文章中。
【小白學ML】隨機森林 全解 (從bagging到variance)
7 卷積網(wǎng)絡感受野怎么擴大
池化層。maxpool,avepool,感受野大一倍。 空洞卷積。 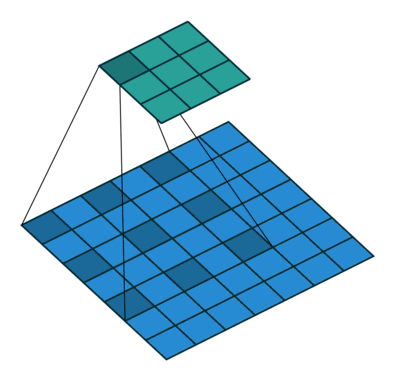
多個3*3的卷積層可以構成5*5和7*7的視野域。 GCN圖卷積網(wǎng)絡也可以起到這樣的效果,但是對GCN了解的不多。
8 什么模型需要數(shù)據(jù)標準化?
我們可以知道當原始數(shù)據(jù)不同維度上的特征的尺度(單位)不一致時 ,需要標準化步驟對數(shù)據(jù)進行預處理。
聚類模型,kmeans,DBSCAN等聚類算法;2,神經(jīng)網(wǎng)絡 分類模型,邏輯回歸和SVM等
決策樹模型則不需要進行標準化,回歸模型不用標準化。
9 數(shù)據(jù)標準化的目的是什么?
先說個人理解的答案:
消除圖片過曝,質量不佳等對模型權重的影響; 讓梯度下降更穩(wěn)定
對于卷積網(wǎng)路來說,如果兩個相同的圖片之間的對比度等不同,就會導致像素值不同,模型對于不同像素值的同一圖片會認定為是兩個不同的圖片。如下圖:
大家看上面兩只豬,對于人來說,它就是兩只一樣的豬,只是圖片的灰度或者曝光度不一樣罷了,于是我們都給它們都標注為“社會人”。雖然我們人眼看起來沒有什么毛病,但是對于CNN網(wǎng)絡來說,他們的特征很可能不同。這時候一般會對圖片事先進行一個Z-Score的標準化(減去均值處以標準差,是不是很多朋友都不知道這個方法的學名。) 把不同的圖片映射到同一尺度下,因此上述問題就從像素值不同的問題轉化成相似的特征分布的問題,一定程度上消除了因為過度曝光,質量不佳,或者噪音等各種原因對模型權值更新的影響。
另外一個原因是,一個圖片RGB三個通道,往往三個通道的數(shù)據(jù)分布不同。比方說可能一個圖片的R的數(shù)值偏大,這樣就會導致反向傳播的時候,圖片R通道的梯度大,更新快。R通道就會占據(jù)模型判斷的主導地位。而下一張圖片可能是綠色G比較大,更新較快,從而產(chǎn)生一個類似學習率不穩(wěn)定的問題。
通過Z-Score,把每個通道都變成0均值1方差,讓梯度下降更穩(wěn)定。
10 如果模型欠擬合怎么辦
這道題一開始問懵了。因為之前的幾次面試基本上問的都是如何解決過擬合問題。過擬合問題之前也整理的很好了,突然問欠擬合宕機了。不過這個問題也不難,這里簡單說一下個人回答的思路:
首先欠擬合就是模型沒有很好地捕捉到數(shù)據(jù)特征,不能夠很好地擬合數(shù)據(jù),例如下面的例子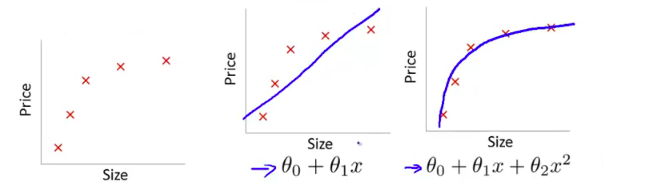 左圖表示size與prize關系的數(shù)據(jù),中間的圖就是出現(xiàn)欠擬合的模型,不能夠很好地擬合數(shù)據(jù),如果在中間的圖的模型后面再加一個二次項,就可以很好地擬合圖中的數(shù)據(jù)了,如右面的圖所示。(其實就是增加特征嘛)
左圖表示size與prize關系的數(shù)據(jù),中間的圖就是出現(xiàn)欠擬合的模型,不能夠很好地擬合數(shù)據(jù),如果在中間的圖的模型后面再加一個二次項,就可以很好地擬合圖中的數(shù)據(jù)了,如右面的圖所示。(其實就是增加特征嘛)
解決方法:
添加其他特征項,有時候我們模型出現(xiàn)欠擬合的時候是因為特征項不夠導致的, 可以添加其他特征項來很好地解決。
添加多項式特征,這個在機器學習算法里面用的很普遍,例如將線性模型通過添加二次項或者三次項使模型泛化能力更強。例如上面的圖片的例子。
減少正則化參數(shù),正則化的目的是用來防止過擬合的,但是現(xiàn)在模型出現(xiàn)了欠擬合,則需要減少正則化參數(shù)。減小其他的正則化參數(shù),比如樹模型中的參數(shù):葉子結點中中最小樣本限制,樹深度限制,等等
增加模型的復雜度,卷積網(wǎng)路哦加深加寬,boost模型增加訓練的迭代次數(shù)。
不過關鍵還是在于更多特征的構建把。
11 模型中dropout在訓練和測試的區(qū)別?
Dropout 是在訓練過程中以一定的概率的使神經(jīng)元失活,即輸出為0,以提高模型的泛化能力,減少過擬合。
Dropout 在訓練時采用,是為了減少神經(jīng)元對部分上層神經(jīng)元的依賴,類似將多個不同網(wǎng)絡結構的模型集成起來,減少過擬合的風險。而在測試時,應該用整個訓練好的模型,因此不需要dropout。
如何平衡訓練和測試時的差異呢?在訓練時以一定的概率使神經(jīng)元失活,實際上就是讓對應神經(jīng)元的輸出為0。假設失活概率為 p ,就是這一層中的每個神經(jīng)元都有p的概率失活,如下圖的三層網(wǎng)絡結構中,如果失活概率為0.5,則平均每一次訓練有3個神經(jīng)元失活,所以輸出層每個神經(jīng)元只有3個輸入,而實際測試時是不會有dropout的,輸出層每個神經(jīng)元都有6個輸入,這樣在訓練和測試時,輸出層每個神經(jīng)元的輸入和的期望會有量級上的差異。因此在訓練時還要對第二層的輸出數(shù)據(jù)除以(1-p)之后再傳給輸出層神經(jīng)元,作為神經(jīng)元失活的補償,以使得在訓練時和測試時每一層輸入有大致相同的期望。
這里我回答錯誤了,因為我回答成了是在測試的時候,對輸出數(shù)據(jù)乘上p保證訓練和輸出有大致的期望。其實是在訓練的時候除以(1-p)作為補償,而測試階段不做處理,相當于去掉dropout層
12 算法題:數(shù)組的回文遍歷
參考答案:略
- END -往期精彩回顧
獲取一折本站知識星球優(yōu)惠券,復制鏈接直接打開:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群請掃碼進群(如果是博士或者準備讀博士請說明):