
常用的模型集成方法介紹:bagging、boosting 、stacking
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

本文轉(zhuǎn)自:深度學(xué)習(xí)工坊
「團(tuán)結(jié)就是力量」。這句老話很好地表達(dá)了機(jī)器學(xué)習(xí)領(lǐng)域中強(qiáng)大「集成方法」的基本思想。總的來說,許多機(jī)器學(xué)習(xí)競賽(包括 Kaggle)中最優(yōu)秀的解決方案所采用的集成方法都建立在一個(gè)這樣的假設(shè)上:將多個(gè)模型組合在一起通常可以產(chǎn)生更強(qiáng)大的模型。
本文介紹了集成學(xué)習(xí)的各種概念,并給出了一些必要的關(guān)鍵信息,以便讀者能很好地理解和使用相關(guān)方法,并且能夠在有需要的時(shí)候設(shè)計(jì)出合適的解決方案。

本文將討論一些眾所周知的概念,如自助法、自助聚合(bagging)、隨機(jī)森林、提升法(boosting)、堆疊法(stacking)以及許多其它的基礎(chǔ)集成學(xué)習(xí)模型。
為了使所有這些方法之間的聯(lián)系盡可能清晰,我們將嘗試在一個(gè)更廣闊和邏輯性更強(qiáng)的框架中呈現(xiàn)它們,希望這樣會(huì)便于讀者理解和記憶。
集成學(xué)習(xí)是一種機(jī)器學(xué)習(xí)范式。在集成學(xué)習(xí)中,我們會(huì)訓(xùn)練多個(gè)模型(通常稱為「弱學(xué)習(xí)器」)解決相同的問題,并將它們結(jié)合起來以獲得更好的結(jié)果。最重要的假設(shè)是:當(dāng)弱模型被正確組合時(shí),我們可以得到更精確和/或更魯棒的模型。
在集成學(xué)習(xí)理論中,我們將弱學(xué)習(xí)器(或基礎(chǔ)模型)稱為「模型」,這些模型可用作設(shè)計(jì)更復(fù)雜模型的構(gòu)件。在大多數(shù)情況下,這些基本模型本身的性能并不是非常好,這要么是因?yàn)樗鼈兙哂休^高的偏置(例如,低自由度模型),要么是因?yàn)樗麄兊姆讲钐髮?dǎo)致魯棒性不強(qiáng)(例如,高自由度模型)。
集成方法的思想是通過將這些弱學(xué)習(xí)器的偏置和/或方差結(jié)合起來,從而創(chuàng)建一個(gè)「強(qiáng)學(xué)習(xí)器」(或「集成模型」),從而獲得更好的性能。
為了建立一個(gè)集成學(xué)習(xí)方法,我們首先要選擇待聚合的基礎(chǔ)模型。在大多數(shù)情況下(包括在眾所周知的 bagging 和 boosting 方法中),我們會(huì)使用單一的基礎(chǔ)學(xué)習(xí)算法,這樣一來我們就有了以不同方式訓(xùn)練的同質(zhì)弱學(xué)習(xí)器。
這樣得到的集成模型被稱為「同質(zhì)的」。然而,也有一些方法使用不同種類的基礎(chǔ)學(xué)習(xí)算法:將一些異質(zhì)的弱學(xué)習(xí)器組合成「異質(zhì)集成模型」。
很重要的一點(diǎn)是:我們對弱學(xué)習(xí)器的選擇應(yīng)該和我們聚合這些模型的方式相一致。如果我們選擇具有低偏置高方差的基礎(chǔ)模型,我們應(yīng)該使用一種傾向于減小方差的聚合方法;而如果我們選擇具有低方差高偏置的基礎(chǔ)模型,我們應(yīng)該使用一種傾向于減小偏置的聚合方法。
這就引出了如何組合這些模型的問題。我們可以用三種主要的旨在組合弱學(xué)習(xí)器的「元算法」:
bagging,該方法通常考慮的是同質(zhì)弱學(xué)習(xí)器,相互獨(dú)立地并行學(xué)習(xí)這些弱學(xué)習(xí)器,并按照某種確定性的平均過程將它們組合起來。
boosting,該方法通常考慮的也是同質(zhì)弱學(xué)習(xí)器。它以一種高度自適應(yīng)的方法順序地學(xué)習(xí)這些弱學(xué)習(xí)器(每個(gè)基礎(chǔ)模型都依賴于前面的模型),并按照某種確定性的策略將它們組合起來。
stacking,該方法通常考慮的是異質(zhì)弱學(xué)習(xí)器,并行地學(xué)習(xí)它們,并通過訓(xùn)練一個(gè)「元模型」將它們組合起來,根據(jù)不同弱模型的預(yù)測結(jié)果輸出一個(gè)最終的預(yù)測結(jié)果。
非常粗略地說,我們可以說 bagging 的重點(diǎn)在于獲得一個(gè)方差比其組成部分更小的集成模型,而 boosting 和 stacking 則將主要生成偏置比其組成部分更低的強(qiáng)模型(即使方差也可以被減小)。
在接下來的章節(jié)中,我們將具體介紹 bagging 和 boosting 方法(它們比 stacking 方法使用更廣泛,并且讓我們可以討論一些集成學(xué)習(xí)的關(guān)鍵概念),然后簡要概述 stacking 方法。
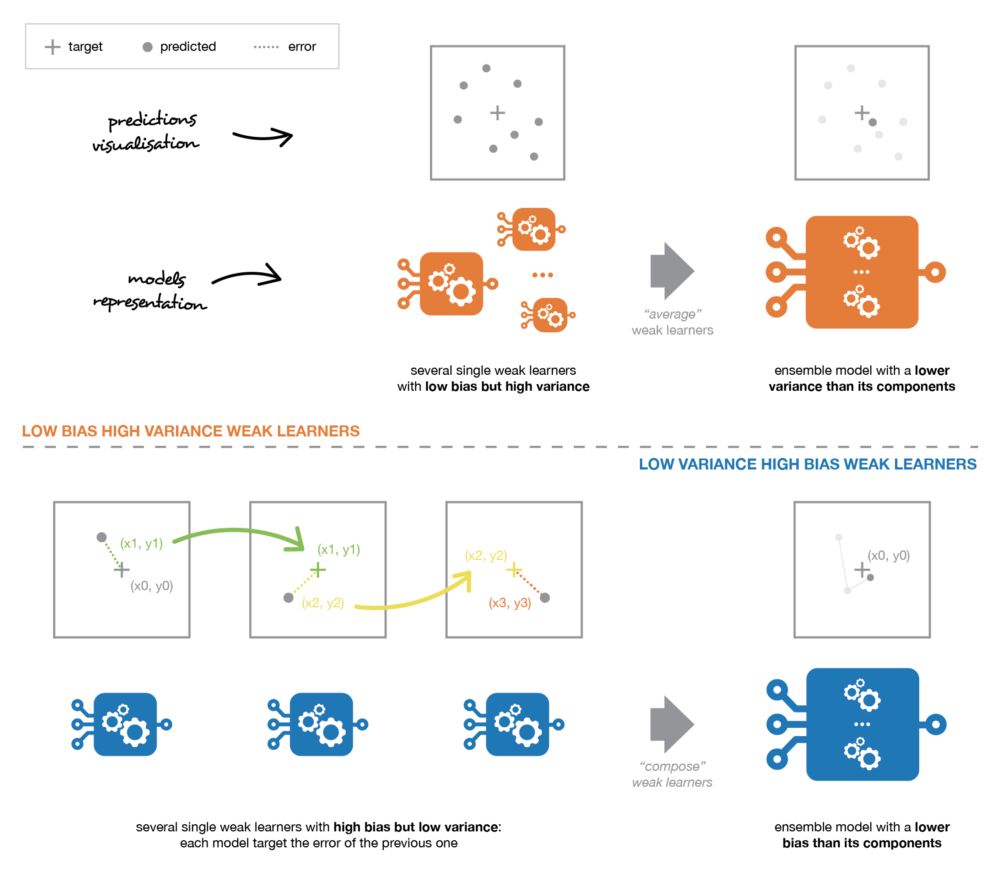
我們可以將弱學(xué)習(xí)器結(jié)合起來以得到性能更好的模型。組合基礎(chǔ)模型的方法應(yīng)該與這些模型的類型相適應(yīng)。
在「并行化的方法」中,我們單獨(dú)擬合不同的學(xué)習(xí)器,因此可以同時(shí)訓(xùn)練它們。最著名的方法是「bagging」(代表「自助聚合」),它的目標(biāo)是生成比單個(gè)模型更魯棒的集成模型。
這種統(tǒng)計(jì)技術(shù)先隨機(jī)抽取出作為替代的 B 個(gè)觀測值,然后根據(jù)一個(gè)規(guī)模為 N 的初始數(shù)據(jù)集生成大小為 B 的樣本(稱為自助樣本)。
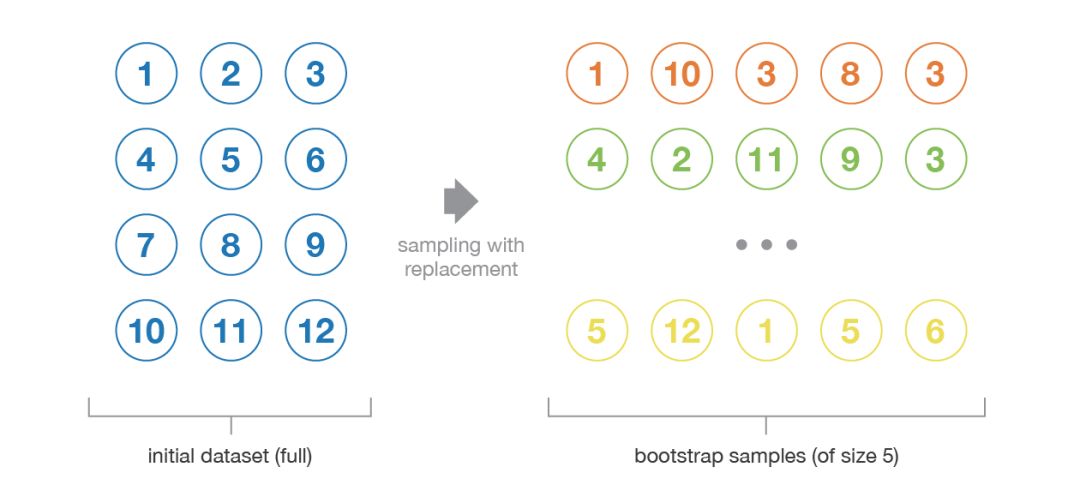
自助抽樣過程示意圖。
在某些假設(shè)條件下,這些樣本具有非常好的統(tǒng)計(jì)特性:在一級近似中,它們可以被視為是直接從真實(shí)的底層(并且往往是未知的)數(shù)據(jù)分布中抽取出來的,并且彼此之間相互獨(dú)立。因此,它們被認(rèn)為是真實(shí)數(shù)據(jù)分布的代表性和獨(dú)立樣本(幾乎是獨(dú)立同分布的樣本)。
為了使這種近似成立,必須驗(yàn)證兩個(gè)方面的假設(shè)。
首先初始數(shù)據(jù)集的大小 N 應(yīng)該足夠大,以捕獲底層分布的大部分復(fù)雜性。這樣,從數(shù)據(jù)集中抽樣就是從真實(shí)分布中抽樣的良好近似(代表性)。
其次,與自助樣本的大小 B 相比,數(shù)據(jù)集的規(guī)模 N 應(yīng)該足夠大,這樣樣本之間就不會(huì)有太大的相關(guān)性(獨(dú)立性)。注意,接下來我可能還會(huì)提到自助樣本的這些特性(代表性和獨(dú)立性),但讀者應(yīng)該始終牢記:「這只是一種近似」。
舉例而言,自助樣本通常用于評估統(tǒng)計(jì)估計(jì)量的方差或置信區(qū)間。根據(jù)定義,統(tǒng)計(jì)估計(jì)量是某些觀測值的函數(shù)。因此,隨機(jī)變量的方差是根據(jù)這些觀測值計(jì)算得到的。
為了評估這種估計(jì)量的方差,我們需要對從感興趣分布中抽取出來的幾個(gè)獨(dú)立樣本進(jìn)行估計(jì)。在大多數(shù)情況下,相較于實(shí)際可用的數(shù)據(jù)量來說,考慮真正獨(dú)立的樣本所需要的數(shù)據(jù)量可能太大了。
然而,我們可以使用自助法生成一些自助樣本,它們可被視為「最具代表性」以及「最具獨(dú)立性」(幾乎是獨(dú)立同分布的樣本)的樣本。這些自助樣本使我們可以通過估計(jì)每個(gè)樣本的值,近似得到估計(jì)量的方差。
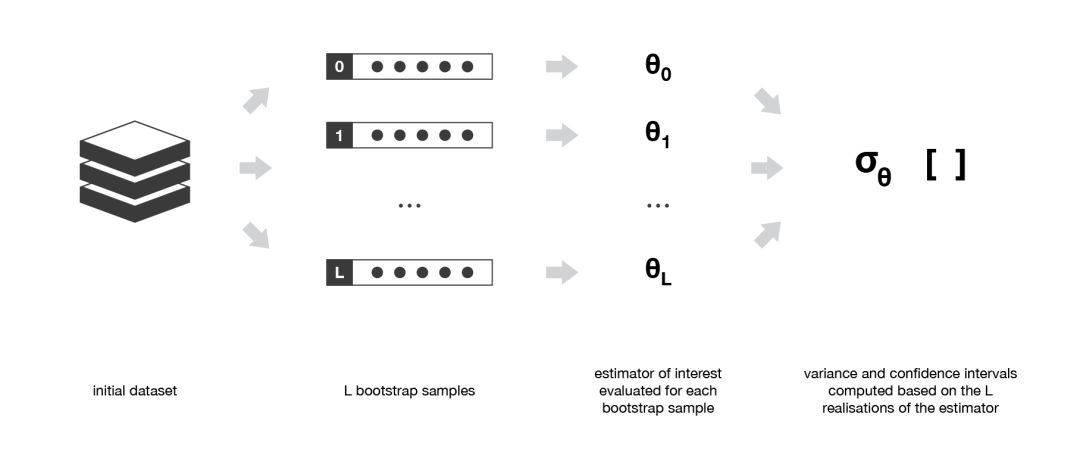
自助法經(jīng)常被用于評估某些統(tǒng)計(jì)估計(jì)量的方差或置信區(qū)間。
在「順序化的方法中」,組合起來的不同弱模型之間不再相互獨(dú)立地?cái)M合。其思想是「迭代地」擬合模型,使模型在給定步驟上的訓(xùn)練依賴于之前的步驟上擬合的模型。「Boosting」是這些方法中最著名的一種,它生成的集成模型通常比組成該模型的弱學(xué)習(xí)器偏置更小。
Boosting 方法和bagging 方法的工作思路是一樣的:我們構(gòu)建一系列模型,將它們聚合起來得到一個(gè)性能更好的強(qiáng)學(xué)習(xí)器。然而,與重點(diǎn)在于減小方差的 bagging 不同,boosting 著眼于以一種適應(yīng)性很強(qiáng)的方式順序擬合多個(gè)弱學(xué)習(xí)器:序列中每個(gè)模型在擬合的過程中,會(huì)更加重視那些序列中之前的模型處理地很糟糕的觀測數(shù)據(jù)。
直觀地說,每個(gè)模型都把注意力集中在目前最難擬合的觀測數(shù)據(jù)上。這樣一來,在這個(gè)過程的最后,我們就獲得了一個(gè)具有較低偏置的強(qiáng)學(xué)習(xí)器(我們會(huì)注意到,boosting 也有減小方差的效果)。和 bagging 一樣,Boosting 也可以用于回歸和分類問題。
由于其重點(diǎn)在于減小偏置,用于 boosting 的基礎(chǔ)模型通常是那些低方差高偏置的模型。例如,如果想要使用樹作為基礎(chǔ)模型,我們將主要選擇只有少許幾層的較淺決策樹。
而選擇低方差高偏置模型作為 boosting 弱學(xué)習(xí)器的另一個(gè)重要原因是:這些模型擬合的計(jì)算開銷較低(參數(shù)化時(shí)自由度較低)。
實(shí)際上,由于擬合不同模型的計(jì)算無法并行處理(與 bagging 不同),順序地?cái)M合若干復(fù)雜模型會(huì)導(dǎo)致計(jì)算開銷變得非常高。
一旦選定了弱學(xué)習(xí)器,我們?nèi)孕枰x它們的擬合方式(在擬合當(dāng)前模型時(shí),要考慮之前模型的哪些信息?)和聚合方式(如何將當(dāng)前的模型聚合到之前的模型中?)在接下來的兩小節(jié)中,我們將討論這些問題,尤其是介紹兩個(gè)重要的 boosting 算法:自適應(yīng)提升(adaboost )和梯度提升(gradient boosting)。
簡而言之,這兩種元算法在順序化的過程中創(chuàng)建和聚合弱學(xué)習(xí)器的方式存在差異。自適應(yīng)增強(qiáng)算法會(huì)更新附加給每個(gè)訓(xùn)練數(shù)據(jù)集中觀測數(shù)據(jù)的權(quán)重,而梯度提升算法則會(huì)更新這些觀測數(shù)據(jù)的值。這里產(chǎn)生差異的主要原因是:兩種算法解決優(yōu)化問題(尋找最佳模型——弱學(xué)習(xí)器的加權(quán)和)的方式不同。
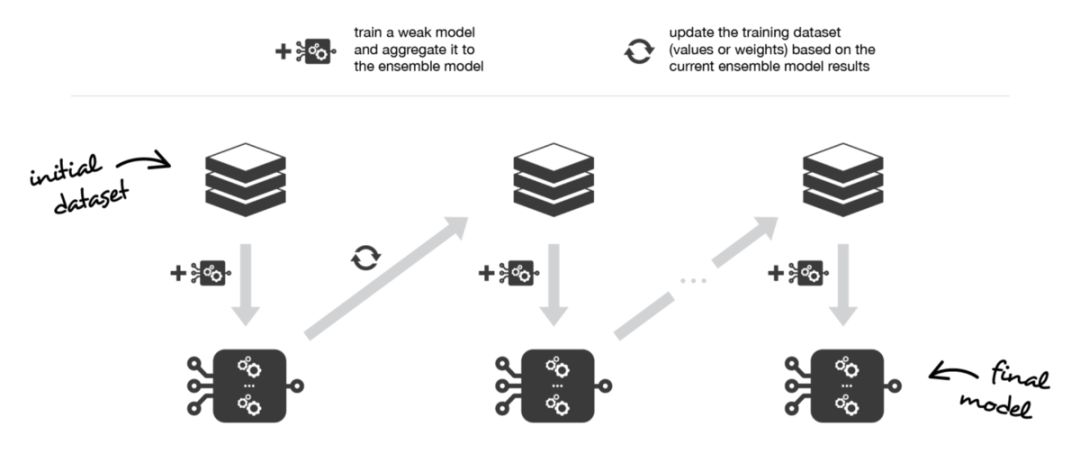
Boosting 會(huì)迭代地?cái)M合一個(gè)弱學(xué)習(xí)器,將其聚合到集成模型中,并「更新」訓(xùn)練數(shù)據(jù)集,從而在擬合下一個(gè)基礎(chǔ)模型時(shí)更好地考慮當(dāng)前集成模型的優(yōu)缺點(diǎn)。
在自適應(yīng) boosting(通常被稱為「adaboost」)中,我們將集成模型定義為 L 個(gè)弱學(xué)習(xí)器的加權(quán)和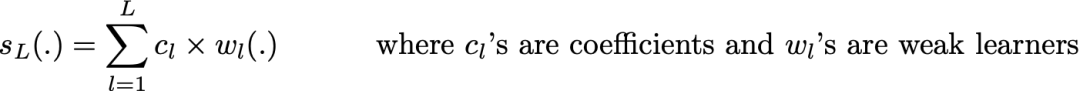 ,其中 c_l 是系數(shù)而 w_l 是弱學(xué)習(xí)器
,其中 c_l 是系數(shù)而 w_l 是弱學(xué)習(xí)器
尋找這種最佳集成模型是一個(gè)「困難的優(yōu)化問題」。因此,我們并沒打算一次性地解決該問題(找到給出最佳整體加法模型的所有系數(shù)和弱學(xué)習(xí)器),而是使用了一種更易于處理的「迭代優(yōu)化過程」(即使它有可能導(dǎo)致我們得到次優(yōu)解)。
另外,我們將弱學(xué)習(xí)器逐個(gè)添加到當(dāng)前的集成模型中,在每次迭代中尋找可能的最佳組合(系數(shù)、弱學(xué)習(xí)器)。換句話說,我們循環(huán)地將 s_l 定義如下:
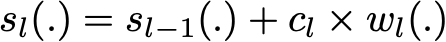
其中,c_l 和 w_l 被挑選出來,使得 s_l 是最適合訓(xùn)練數(shù)據(jù)的模型,因此這是對 s_(l-1) 的最佳可能改進(jìn)。我們可以進(jìn)一步將其表示為:
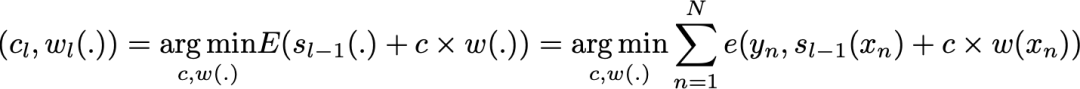
其中,E(.) 是給定模型的擬合誤差,e(.,.)是損失/誤差函數(shù)。因此,我們并沒有在求和過程中對所有 L 個(gè)模型進(jìn)行「全局優(yōu)化」,而是通過「局部」優(yōu)化來近似最優(yōu)解并將弱學(xué)習(xí)器逐個(gè)添加到強(qiáng)模型中。
更特別的是,在考慮二分類問題時(shí),我們可以將 adaboost 算法重新寫入以下過程:首先,它將更新數(shù)據(jù)集中觀測數(shù)據(jù)的權(quán)重,訓(xùn)練一個(gè)新的弱學(xué)習(xí)器,該學(xué)習(xí)器重點(diǎn)關(guān)注當(dāng)前集成模型誤分類的觀測數(shù)據(jù)。其次,它會(huì)根據(jù)一個(gè)表示該弱模型性能的更新系數(shù),將弱學(xué)習(xí)器添加到加權(quán)和中:弱學(xué)習(xí)器的性能越好,它對強(qiáng)學(xué)習(xí)器的貢獻(xiàn)就越大。
因此,假設(shè)我們面對的是一個(gè)二分類問題:數(shù)據(jù)集中有 N 個(gè)觀測數(shù)據(jù),我們想在給定一組弱模型的情況下使用 adaboost 算法。在算法的起始階段(序列中的第一個(gè)模型),所有的觀測數(shù)據(jù)都擁有相同的權(quán)重「1/N」。然后,我們將下面的步驟重復(fù) L 次(作用于序列中的 L 個(gè)學(xué)習(xí)器):
用當(dāng)前觀測數(shù)據(jù)的權(quán)重?cái)M合可能的最佳弱模型
計(jì)算更新系數(shù)的值,更新系數(shù)是弱學(xué)習(xí)器的某種標(biāo)量化評估指標(biāo),它表示相對集成模型來說,該弱學(xué)習(xí)器的分量如何
通過添加新的弱學(xué)習(xí)器與其更新系數(shù)的乘積來更新強(qiáng)學(xué)習(xí)器
計(jì)算新觀測數(shù)據(jù)的權(quán)重,該權(quán)重表示我們想在下一輪迭代中關(guān)注哪些觀測數(shù)據(jù)(聚和模型預(yù)測錯(cuò)誤的觀測數(shù)據(jù)的權(quán)重增加,而正確預(yù)測的觀測數(shù)據(jù)的權(quán)重減小)
重復(fù)這些步驟,我們順序地構(gòu)建出 L 個(gè)模型,并將它們聚合成一個(gè)簡單的線性組合,然后由表示每個(gè)學(xué)習(xí)器性能的系數(shù)加權(quán)。注意,初始 adaboost 算法有一些變體,比如 LogitBoost(分類)或 L2Boost(回歸),它們的差異主要取決于損失函數(shù)的選擇。
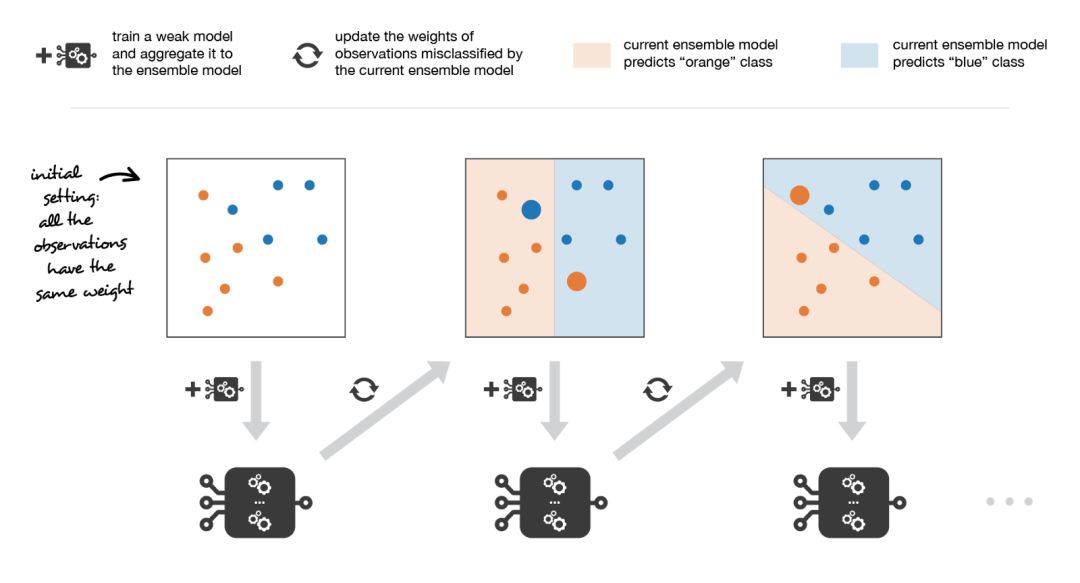
Adaboost 在每次迭代中更新觀測數(shù)據(jù)的權(quán)重。正確分類的觀測數(shù)據(jù)的權(quán)重相對于錯(cuò)誤分類的觀測數(shù)據(jù)的權(quán)重有所下降。在最終的集成模型中,性能更好的模型具有更高的權(quán)重。
Stacking 與 bagging 和 boosting 主要存在兩方面的差異。首先,Stacking 通常考慮的是異質(zhì)弱學(xué)習(xí)器(不同的學(xué)習(xí)算法被組合在一起),而bagging 和 boosting 主要考慮的是同質(zhì)弱學(xué)習(xí)器。其次,stacking 學(xué)習(xí)用元模型組合基礎(chǔ)模型,而bagging 和 boosting 則根據(jù)確定性算法組合弱學(xué)習(xí)器。
正如上文已經(jīng)提到的,stacking 的概念是學(xué)習(xí)幾個(gè)不同的弱學(xué)習(xí)器,并通過訓(xùn)練一個(gè)元模型來組合它們,然后基于這些弱模型返回的多個(gè)預(yù)測結(jié)果輸出最終的預(yù)測結(jié)果。
因此,為了構(gòu)建 stacking 模型,我們需要定義兩個(gè)東西:想要擬合的 L 個(gè)學(xué)習(xí)器以及組合它們的元模型。
例如,對于分類問題來說,我們可以選擇 KNN 分類器、logistic 回歸和SVM 作為弱學(xué)習(xí)器,并決定學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)作為元模型。然后,神經(jīng)網(wǎng)絡(luò)將會(huì)把三個(gè)弱學(xué)習(xí)器的輸出作為輸入,并返回基于該輸入的最終預(yù)測。
所以,假設(shè)我們想要擬合由 L 個(gè)弱學(xué)習(xí)器組成的 stacking 集成模型。我們必須遵循以下步驟:
將訓(xùn)練數(shù)據(jù)分為兩組
選擇 L 個(gè)弱學(xué)習(xí)器,用它們擬合第一組數(shù)據(jù)
使 L 個(gè)學(xué)習(xí)器中的每個(gè)學(xué)習(xí)器對第二組數(shù)據(jù)中的觀測數(shù)據(jù)進(jìn)行預(yù)測
在第二組數(shù)據(jù)上擬合元模型,使用弱學(xué)習(xí)器做出的預(yù)測作為輸入
在前面的步驟中,我們將數(shù)據(jù)集一分為二,因?yàn)閷τ糜谟?xùn)練弱學(xué)習(xí)器的數(shù)據(jù)的預(yù)測與元模型的訓(xùn)練不相關(guān)。因此,將數(shù)據(jù)集分成兩部分的一個(gè)明顯缺點(diǎn)是,我們只有一半的數(shù)據(jù)用于訓(xùn)練基礎(chǔ)模型,另一半數(shù)據(jù)用于訓(xùn)練元模型。
為了克服這種限制,我們可以使用某種「k-折交叉訓(xùn)練」方法(類似于 k-折交叉驗(yàn)證中的做法)。這樣所有的觀測數(shù)據(jù)都可以用來訓(xùn)練元模型:對于任意的觀測數(shù)據(jù),弱學(xué)習(xí)器的預(yù)測都是通過在 k-1 折數(shù)據(jù)(不包含已考慮的觀測數(shù)據(jù))上訓(xùn)練這些弱學(xué)習(xí)器的實(shí)例來完成的。
換句話說,它會(huì)在 k-1 折數(shù)據(jù)上進(jìn)行訓(xùn)練,從而對剩下的一折數(shù)據(jù)進(jìn)行預(yù)測。迭代地重復(fù)這個(gè)過程,就可以得到對任何一折觀測數(shù)據(jù)的預(yù)測結(jié)果。這樣一來,我們就可以為數(shù)據(jù)集中的每個(gè)觀測數(shù)據(jù)生成相關(guān)的預(yù)測,然后使用所有這些預(yù)測結(jié)果訓(xùn)練元模型。
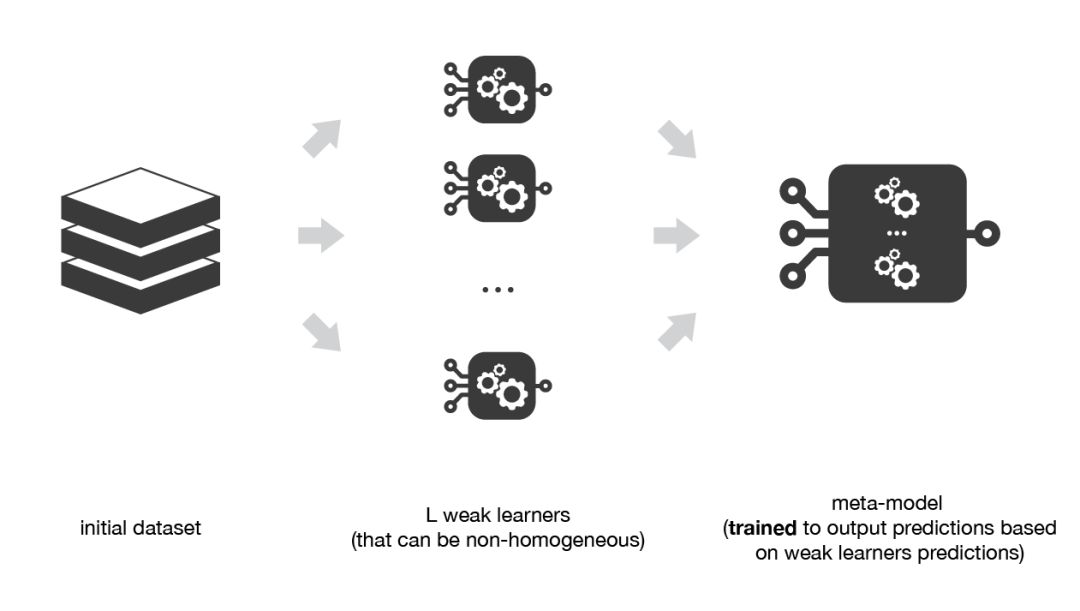
Stacking 方法會(huì)訓(xùn)練一個(gè)元模型,該模型根據(jù)較低層的弱學(xué)習(xí)器返回的輸出結(jié)果生成最后的輸出。
原文鏈接:https://towardsdatascience.com/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會(huì)逐漸細(xì)分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會(huì)根據(jù)研究方向邀請進(jìn)入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會(huì)請出群,謝謝理解~