
Presto介紹及常用查詢優(yōu)化方法總結
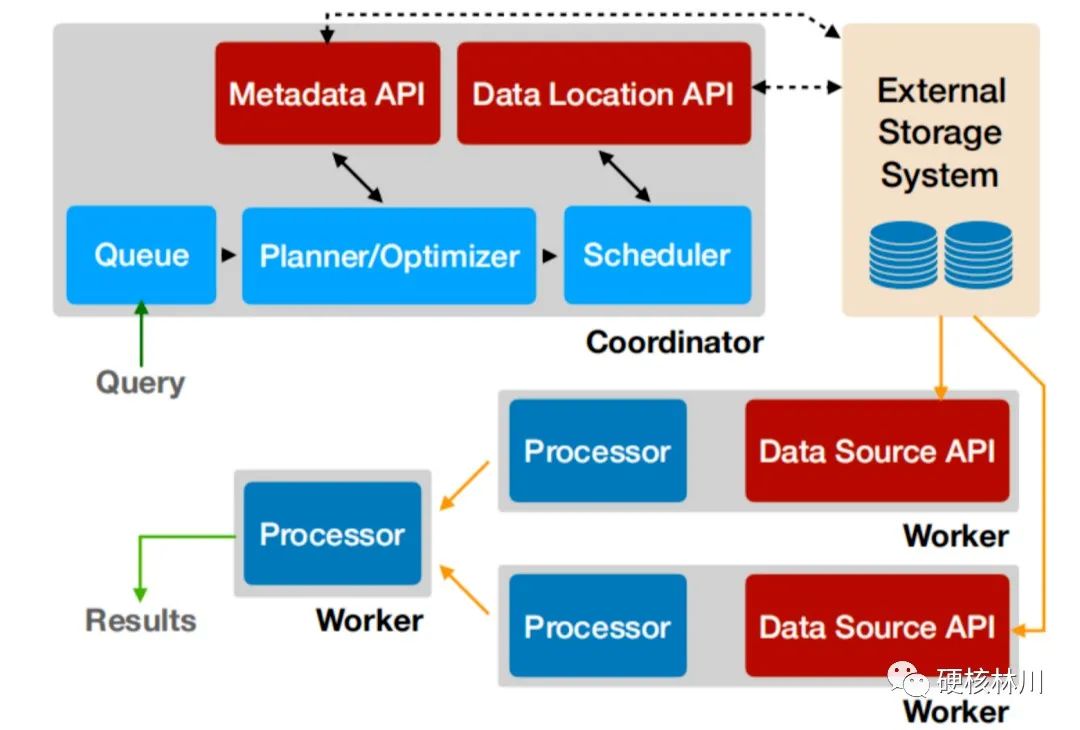
完全基于內(nèi)存的并行計算 流水線 本地化計算 動態(tài)編譯執(zhí)行計劃 小心使用內(nèi)存和數(shù)據(jù)結構 GC控制 無容錯
[GOOD]: SELECT GROUP BY uid, gender[BAD]:??SELECT?GROUP?BY?gender,?uid
[GOOD]SELECT?...?FROM?access?WHERE regexp_like(method, 'GET|POST|PUT|DELETE')[BAD]SELECT?...?FROM?access?WHERE?method?LIKE?'%GET%'?OR??method?LIKE?'%POST%'?OR??method?LIKE?'%PUT%'?OR??method?LIKE?'%DELETE%'
set?session?distributed_join?=?'true'SELECT?...?FROMlarge_table1join large_table2on?large_table1.id?=?large_table2.id
SELECT?...?FROM?t1?JOIN?t2ON?t1.a1?=?t2.a1?ORt1.a2?=?t2.a2?改為SELECT?...FROM?t1?JOIN?t2?ON?t1.a1?=?t2.a1unionSELECT?...FROM?t1?JOIN?t2ON?t1.a2?=?t2.a2
WITH tmp AS (SELECT DISTINCT a1, a2FROM t2)SELECT ...FROM t1JOIN tmpON t1.a1 = tmp.a1unionSELECT ...FROM t1JOIN tmpON t1.a2 = tmp.a2;

八千里路云和月 | 從零到大數(shù)據(jù)專家學習路徑指南
Flink生產(chǎn)環(huán)境TOP難題與優(yōu)化,阿里巴巴藏經(jīng)閣YYDS
Flink CDC我吃定了耶穌也留不住他!| Flink CDC線上問題小盤點
硬剛Hive | 4萬字基礎調(diào)優(yōu)面試小總結
4萬字長文 | ClickHouse基礎&實踐&調(diào)優(yōu)全視角解析
【面試&個人成長】2021年過半,社招和校招的經(jīng)驗之談
大數(shù)據(jù)方向另一個十年開啟 |《硬剛系列》第一版完結
評論
圖片
表情