
基于 Flink 打造的伴魚實時計算平臺 Palink 的設(shè)計與實現(xiàn)
在伴魚發(fā)展早期,出現(xiàn)了一系列實時性相關(guān)的需求,比如算法工程師期望可以拿到用戶的實時特征數(shù)據(jù)做實時推薦,產(chǎn)品經(jīng)理希望數(shù)據(jù)方可以提供實時指標(biāo)看板做實時運營分析。
一、核心原則
通過調(diào)研阿里云、網(wǎng)易等各大廠商提供的實時計算服務(wù),我們基本確定了 Palink 的整個產(chǎn)品形態(tài)。同時,在系統(tǒng)設(shè)計過程中緊緊圍繞以下幾個核心原則:
極簡性:保持簡易設(shè)計,快速落地,不過度追求功能的完整性,滿足核心需求為主;
高質(zhì)量:保持項目質(zhì)量嚴(yán)要求,核心模塊思慮周全;
可擴(kuò)展:保持較高的可擴(kuò)展性,便于后續(xù)方案的迭代升級。
二、系統(tǒng)設(shè)計
平臺整體架構(gòu)
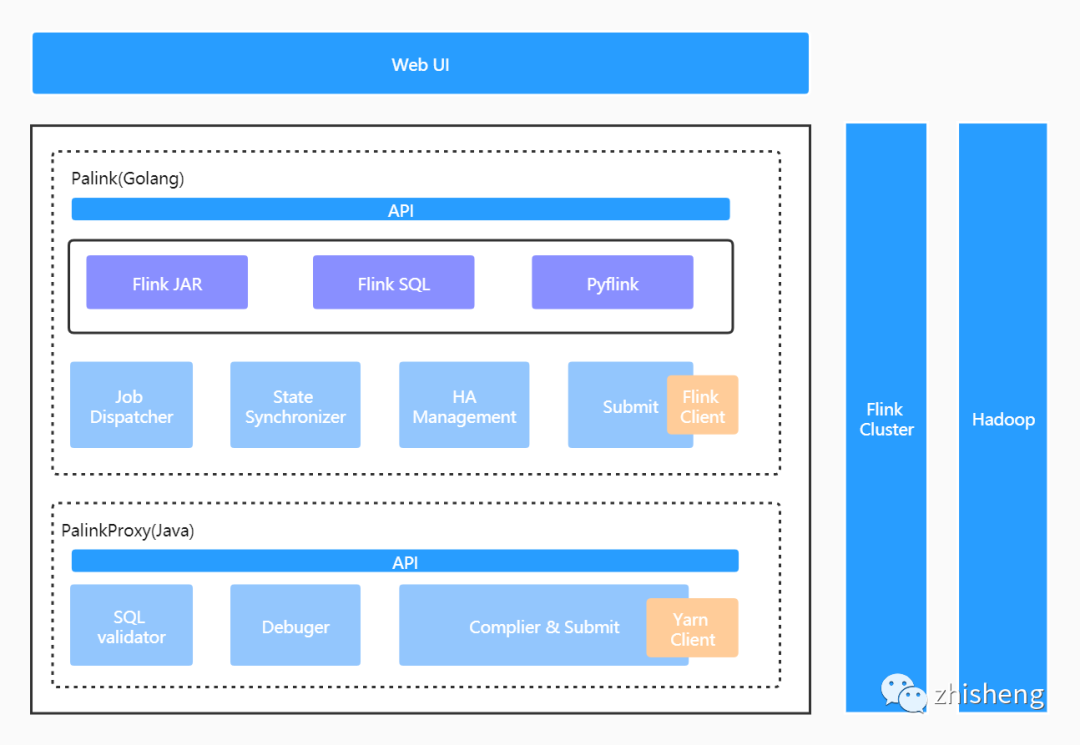
Web UI:前端操作頁面;
Palink (GO) 服務(wù):實時作業(yè)管理服務(wù),負(fù)責(zé)作業(yè)元信息及作業(yè)生命周期內(nèi)全部狀態(tài)的管理,承接全部的前端流量。包括作業(yè)調(diào)度、作業(yè)提交、作業(yè)狀態(tài)同步及作業(yè) HA 管理幾個核心模塊;
PalinkProxy(JAVA) 服務(wù):SQL 化服務(wù),F(xiàn)link SQL 作業(yè)將由此模塊編譯、提交至遠(yuǎn)端集群。包括 SQL 語法校驗、SQL 作業(yè)調(diào)試及 SQL 作業(yè)編譯和提交幾個核心模塊;
Flink On Yarn:基于 Hadoop Yarn 做集群的資源管理。
一是伴魚擁有一套非常完善的基于 GO 語言實現(xiàn)的微服務(wù)基礎(chǔ)框架,基于它可以快速構(gòu)建服務(wù)并擁有包括服務(wù)監(jiān)控在內(nèi)的一系列周邊配套,公司目前 95% 以上的服務(wù)是基于此服務(wù)框架構(gòu)建的;
二是 SQL 化模塊是基于開源項目二次開發(fā)實現(xiàn)的(這個在后文會做詳細(xì)介紹),而該開源項目使用的是 JAVA 語言;
三是內(nèi)部服務(wù)增加一次遠(yuǎn)程調(diào)用的成本是可以接受的。
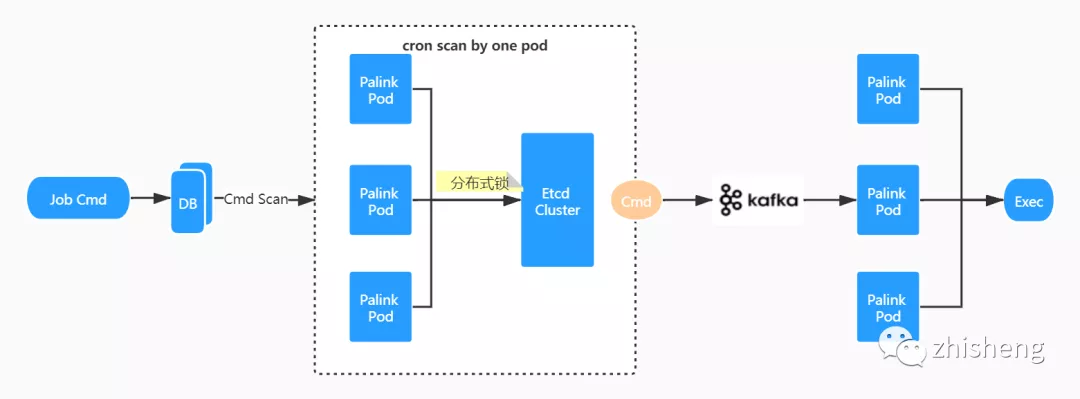
作業(yè)調(diào)度&執(zhí)行
type PalinkJobCommand struct {ID uint64 `json:"id"`PalinkJobID uint64 `json:"palink_job_id"`CommandParams string `json:"command_params"`CommandState int8 `json:"command_state"`Log string `json:"log"`CreatedAt int64 `json:"created_at"`UpdatedAt int64 `json:"updated_at"`}
調(diào)度流程
執(zhí)行流程
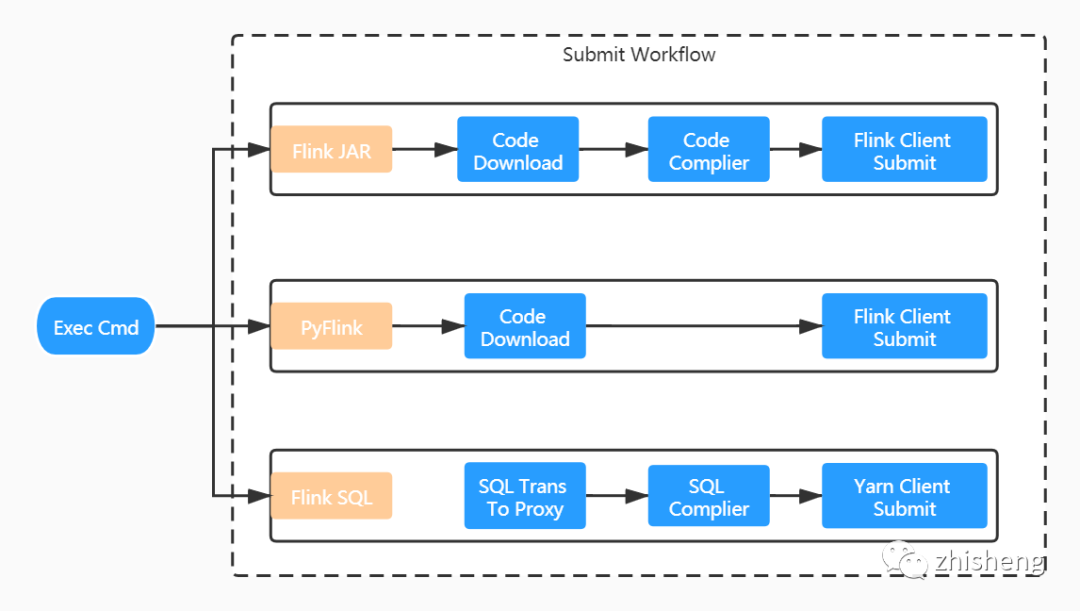
Flink JAR 作業(yè):我們摒棄了用戶直接上傳 JAR 文件的交互方式。用戶只需提供作業(yè) gitlab 倉庫地址即可,打包構(gòu)建全流程平臺直接完成。由于每一個服務(wù)實例都內(nèi)嵌 Flink 客戶端,任務(wù)是直接通過 Flink run 方式提交的。 PyFlink 作業(yè):與 Flink JAR 方式類似,少了編譯的過程,提交命令也有所不同。 Flink SQL 作業(yè):與上兩種方式區(qū)別較大。對于 Flink SQL 作業(yè)而言,用戶只需提交相對簡單的 SQL 文本信息,這個內(nèi)容我們是直接維護(hù)在平臺的元信息中,故沒有和 gitlab 倉庫交互的地方。SQL 文本將進(jìn)一步提交給 PalinkProxy 服務(wù)進(jìn)行后續(xù)的編譯,然后使用 Yarn Client 方式提交。
Command 狀態(tài)機(jī)
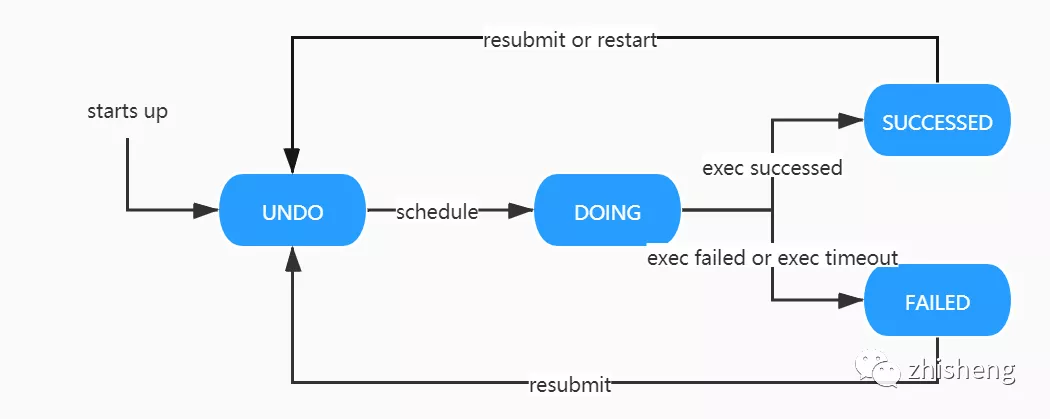
UNDO:初始狀態(tài),將被調(diào)度實例監(jiān)測。 DOING:執(zhí)行中狀態(tài),同樣會調(diào)度實例監(jiān)測,防止長期處于進(jìn)行中的臟狀態(tài)產(chǎn)生。 SUCCESSED:執(zhí)行成功狀態(tài)。隨著用戶的后續(xù)行為,如重新提交、重新啟動操作,狀態(tài)會再次回到 UNDO 態(tài)。 FAILED:執(zhí)行失敗狀態(tài)。同上,狀態(tài)可能會再次回到 UNDO 態(tài)。
作業(yè)狀態(tài)同步
狀態(tài)同步流程
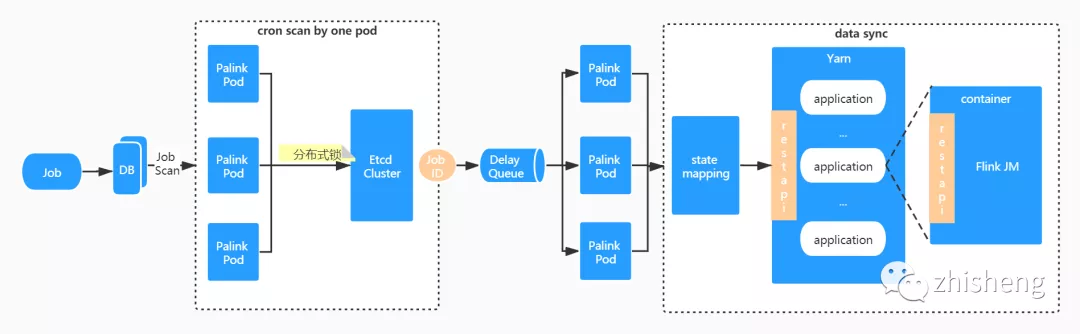
Job 狀態(tài)機(jī)
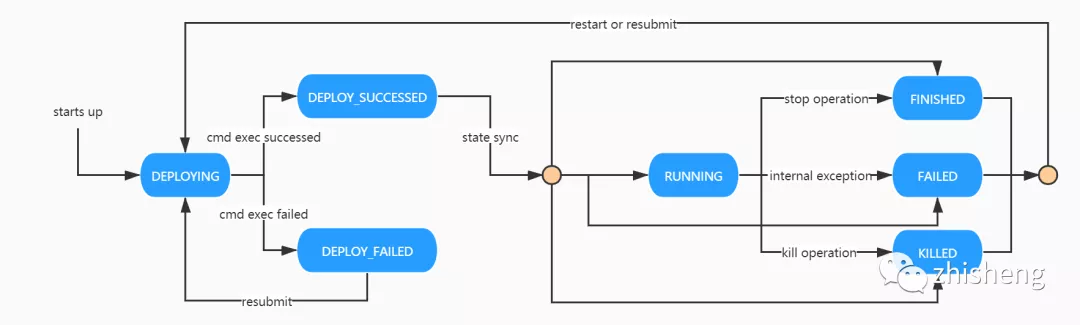
DEPLOYING:作業(yè)初始狀態(tài),將隨著 PalinkJobCommand 的狀態(tài)驅(qū)動向 DEPLOY_SUCCESSED 和 DEPLOY_FAILED 流轉(zhuǎn)。 DEPLOY_SUCCESSED:部署成功狀態(tài),依賴作業(yè)「狀態(tài)同步」驅(qū)動向 RUNNING 狀態(tài)或者其他終態(tài)流轉(zhuǎn)。 DEPLOY_FAILED:部署失敗狀態(tài),依賴用戶重新提交向 DEPLOYING 狀態(tài)流轉(zhuǎn)。 RUNNING:運行中狀態(tài)。可通過用戶執(zhí)行暫停操作向 FINISHED 狀態(tài)流轉(zhuǎn),或執(zhí)行終止操作向 KILLED 狀態(tài)流轉(zhuǎn),或因為內(nèi)部異常向 FAILED 狀態(tài)流轉(zhuǎn)。 FINISHED:完成狀態(tài),作業(yè)終態(tài)之一。通過用戶執(zhí)行暫停操作,作業(yè)將回到此狀態(tài)。 KILLED:終止?fàn)顟B(tài),作業(yè)終態(tài)之一。通過用戶執(zhí)行終止操作,作業(yè)將回到此狀態(tài)。 FAILED:失敗狀態(tài),作業(yè)終態(tài)之一。作業(yè)異常會轉(zhuǎn)為此狀態(tài)。
作業(yè) HA 管理
作業(yè)是有狀態(tài)的,但是作業(yè)需要代碼升級,如何處理? 作業(yè)異常失敗了,怎么做到從失敗的時間點恢復(fù)?
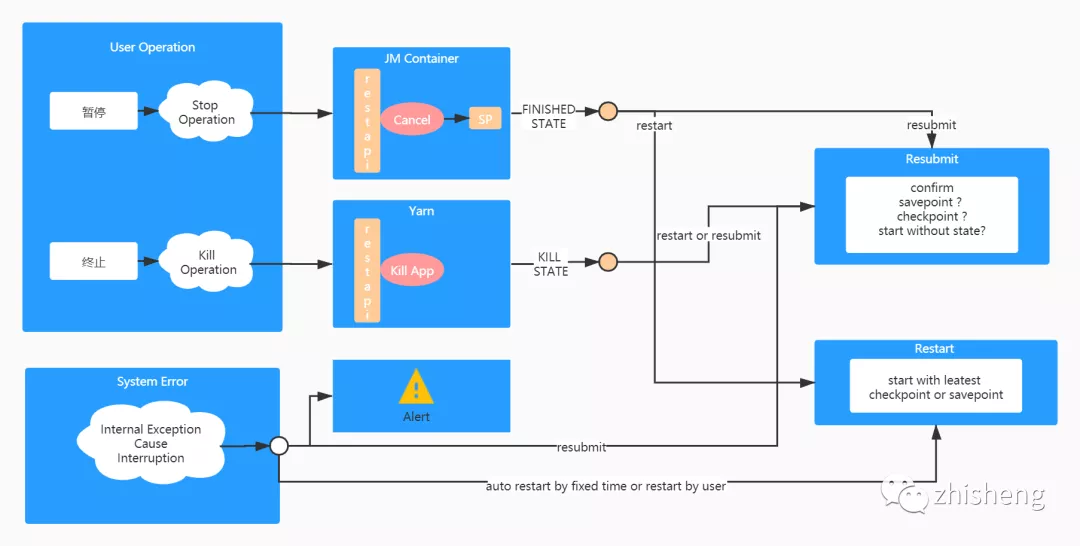
暫停操作通過調(diào)用 Flink cancel api 實現(xiàn),將觸發(fā)作業(yè)生成 Savepoint。 終止操作則是通過調(diào)用 yarn kill application api 實現(xiàn),用于快速結(jié)束一個任務(wù)。
一是任務(wù)自身可以設(shè)置重啟策略自動恢復(fù),外部平臺無感知; 二是,對于內(nèi)部重啟依舊失敗的任務(wù)在平臺側(cè)可再次設(shè)置上層重啟策略; 三是,手動重啟或重新提交。僅在重新提交時,由用戶決定按照那種方式啟動,其余場景皆按照最近的保存點啟動。
任務(wù) SQL 化
實現(xiàn)機(jī)制
構(gòu)建 PackagedProgram
PackagedProgram.newBuilder().setJarFile(coreJarFile).setArguments(execArgs).setSavepointRestoreSettings(savepointRestoreSettings).build();
定制開發(fā)
服務(wù)化:整個 SQL 化模塊作為 proxy 獨立部署和管理,以 HTTP 形式暴露服務(wù); 支持語法校驗特性; 支持調(diào)試特性:通過解析 SQL 結(jié)構(gòu)可直接獲取到 source 表和 sink 表的結(jié)構(gòu)信息。平臺可通過人工構(gòu)造或線上抓取源表數(shù)據(jù)的方式得到測試數(shù)據(jù)集,sink 算子被 localTest connector 算子直接替換,以截取結(jié)果數(shù)據(jù)輸出; 支持更多的 connector plugin,如 pulsar connector; 其他特性。
DDL 語句注入 UDF 管理 租戶管理 版本管理 作業(yè)監(jiān)控 日志收集
三、線上效果
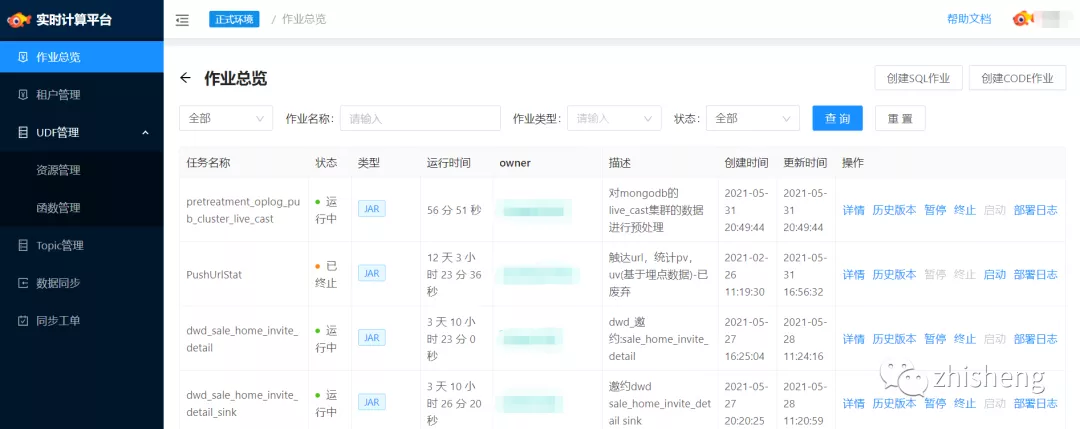
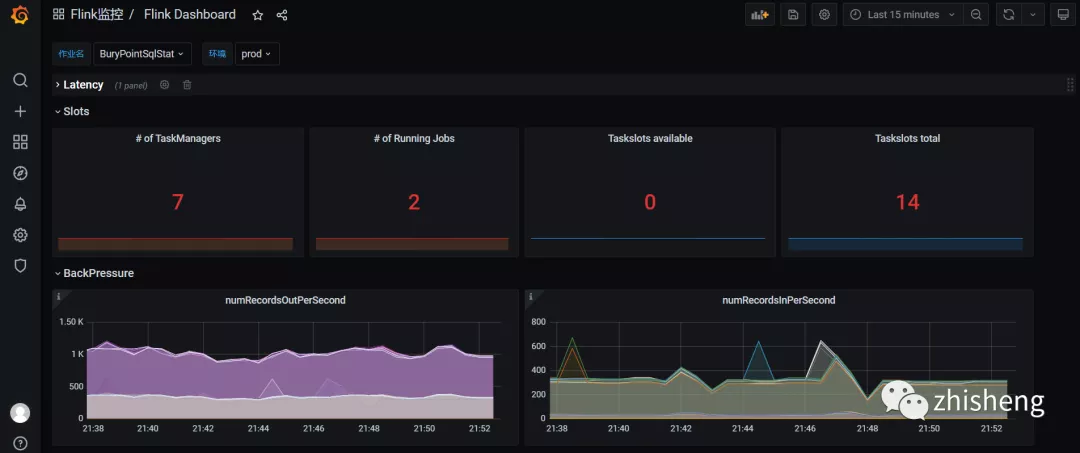
■ 作業(yè)總覽
四、未來工作
隨著業(yè)務(wù)的繼續(xù)推進(jìn),平臺將在以下幾方面繼續(xù)迭代優(yōu)化:
穩(wěn)定性建設(shè):實時任務(wù)的穩(wěn)定性建設(shè)必然是未來工作中的首要事項。作業(yè)參數(shù)如何設(shè)置,作業(yè)如何自動調(diào)優(yōu),作業(yè)在流量高峰如何保持穩(wěn)定的性能,這些問題需要不斷探索并沉淀更多的最佳實踐;
提升開發(fā)效率:SQL 化建設(shè)。盡管 SQL 化已初具雛形,但開發(fā)起來依舊具備一定的學(xué)習(xí)成本,其中最明顯的就是 DDL 的構(gòu)建,用戶對于 source、sink 的 schema 并不清楚,最好的方式是平臺可以和我們的元數(shù)據(jù)中心打通將構(gòu)建 DDL 的過程自動化,這一點也是我們目前正在做的;
優(yōu)化使用體驗:體驗上的問題在一定程度上也直接影響到了開發(fā)的效率。通過不斷收集用戶反饋,持續(xù)改進(jìn);
探索更多業(yè)務(wù)場景:目前伴魚內(nèi)部已開始基于 Flink 開展 AI 、實時數(shù)倉等場景的建設(shè)。未來我們將繼續(xù)推進(jìn) Flink 在更多場景上的實踐。