
數(shù)學(xué)推導(dǎo)+純Python實(shí)現(xiàn)機(jī)器學(xué)習(xí)算法19:CatBoost
Python機(jī)器學(xué)習(xí)算法實(shí)現(xiàn)
Author:louwill
Machine Learning Lab
? ? ?
本文介紹GBDT系列的最后一個(gè)強(qiáng)大的工程實(shí)現(xiàn)模型——CatBoost。CatBoost與XGBoost、LightGBM并稱為GBDT框架下三大主流模型。CatBoost是俄羅斯搜索巨頭公司Yandex于2017年開源出來的一款GBDT計(jì)算框架,因其能夠高效處理數(shù)據(jù)中的類別特征而取名為CatBoost(Categorical+Boosting)。相較于XGBoost和LightGBM,CatBoost的主要?jiǎng)?chuàng)新點(diǎn)在于類別特征處理和排序提升(Ordered Boosting)。?

處理類別型特征
對于類別特征的處理是CatBoost的一大特點(diǎn),這也是其命名的由來。CatBoost通過對常規(guī)的目標(biāo)變量統(tǒng)計(jì)方法添加先驗(yàn)項(xiàng)來對其進(jìn)行改進(jìn)。除此之外,CatBoost還考慮使用類別特征的不同組合來擴(kuò)大數(shù)據(jù)集特征維度。
通用處理方法
類別型特征在結(jié)構(gòu)化數(shù)據(jù)集中是一個(gè)非常普遍的特征。這類特征區(qū)別于常見的數(shù)值型特征,它是一個(gè)離散的集合,比如說性別(男、女),學(xué)歷(本科、碩士、博士等),地點(diǎn)(杭州、北京、上海等),有些時(shí)候我們還會(huì)碰到幾十上百個(gè)取值的類別特征。
對于類別型特征,以往最通用的方法就是one-hot編碼,如果類別型特征取值數(shù)目較少的話,one-hot編碼不失為一種比較高效的方法。但當(dāng)類別型特征取值數(shù)目較多的話,one-hot編碼就不劃算了,它會(huì)產(chǎn)生大量冗余特征,試想一下一個(gè)類別數(shù)目為100個(gè)的類別型特征,one-hot編碼會(huì)產(chǎn)生100個(gè)稀疏特征,茫茫零海中的一個(gè)1,這對訓(xùn)練算法本身而言就是個(gè)累贅。
所以,對于特征取值數(shù)目較多的類別型特征,一種折中的方法是將類別數(shù)目進(jìn)行重新歸類,使其類別數(shù)目降到較少數(shù)目再進(jìn)行one-hot編碼。另一種最常用的方法則是目標(biāo)變量統(tǒng)計(jì)(Target Statisitics,TS),TS計(jì)算每個(gè)類別對于的目標(biāo)變量的期望值并將類別特征轉(zhuǎn)換為新的數(shù)值特征。CatBoost在常規(guī)TS方法上做了改進(jìn)。
目標(biāo)變量統(tǒng)計(jì)
CatBoost算法設(shè)計(jì)一個(gè)最大的目的就是要更好的處理GBDT特征中的類別特征。常規(guī)的TS方法最直接的做法就是將類別對應(yīng)的標(biāo)簽平均值來進(jìn)行替換。在GBDT構(gòu)建決策樹的過程中,替換后的類別標(biāo)簽平均值作為節(jié)點(diǎn)分裂的標(biāo)準(zhǔn),這種做法也被稱為Greedy Target-based Statistics , 簡稱Greedy TS,其計(jì)算公式可表示為:
Greedy TS一個(gè)比較明顯的缺陷就是當(dāng)特征比標(biāo)簽包含更多信息時(shí),統(tǒng)一用標(biāo)簽平均值來代替分類特征表達(dá)的話,訓(xùn)練集和測試集可能會(huì)因?yàn)閿?shù)據(jù)分布不一樣而產(chǎn)生條件偏移問題。CatBoost對Greedy TS方法的改進(jìn)就是添加先驗(yàn)分布項(xiàng),用以減少噪聲和低頻類別型數(shù)據(jù)對于數(shù)據(jù)分布的影響。改進(jìn)后的Greedy TS方法數(shù)學(xué)表達(dá)如下:
其中為添加的先驗(yàn)項(xiàng),為大于的權(quán)重系數(shù)。
除了上述方法之外,CatBoost還提供了Holdout TS、Leave-one-out TS、Ordered TS等幾種改進(jìn)的TS方法,這里不一一詳述。
特征組合
CatBoost另外一種對類別特征處理方法的創(chuàng)新在于可以構(gòu)建任意幾個(gè)類別型特征的任意組合為新的特征。比如說用戶ID和廣告主題之間的聯(lián)合信息。如果單純地將二者轉(zhuǎn)換為數(shù)值特征,二者之間的聯(lián)合信息可能就會(huì)丟失掉。CatBoost則考慮將這兩個(gè)分類特征進(jìn)行組合構(gòu)成新的分類特征。但組合的數(shù)量會(huì)隨著數(shù)據(jù)集中類別型特征的數(shù)量成指數(shù)增長,因此不可能考慮所有的組合。
所以,CatBoost在構(gòu)建新的分裂節(jié)點(diǎn)時(shí),會(huì)采用貪心的策略考慮特征之間的組合。CatBoost將當(dāng)前樹的所有組合、類別型特征與數(shù)據(jù)集中的所有類別型特征相結(jié)合,并將新的類別組合型特征動(dòng)態(tài)地轉(zhuǎn)換為數(shù)值型特征。
預(yù)測偏移與排序提升
CatBoost另一大創(chuàng)新點(diǎn)在于提出使用排序提升(Ordered Boosting)的方法解決預(yù)測偏移(Prediction Shift)的問題。
預(yù)測偏移
所謂預(yù)測偏移,即訓(xùn)練樣本的分布與測試樣本的分布之間產(chǎn)生的偏移。
CatBoost首次揭示了梯度提升中的預(yù)測偏移問題。認(rèn)為預(yù)測偏移就像是TS處理方法一樣,是由一種特殊的特征target leakage和梯度偏差造成的,我們來看一下在梯度提升過程中這種預(yù)測偏移是這么傳遞的。
假設(shè)前一輪訓(xùn)練得到強(qiáng)學(xué)習(xí)器為,當(dāng)前損失函數(shù)為,則本輪迭代則要擬合的弱學(xué)習(xí)器為:
進(jìn)一步的梯度表達(dá)為:
的數(shù)據(jù)近似表達(dá)為:
最終的鏈?zhǔn)降念A(yù)測偏移可以描述為:
- 梯度的條件分布和測試數(shù)據(jù)的分布存在偏移;
- 的數(shù)據(jù)近似估計(jì)與梯度表達(dá)式之間存在偏差;
- 預(yù)測偏移會(huì)影響到的泛化性能。
排序提升
CatBoost采用基于Ordered TS的Ordered Boosting方法來處理預(yù)測偏移問題。排序提升算法流程如下圖所示。

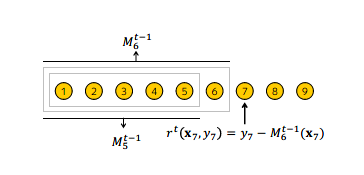
對于訓(xùn)練數(shù)據(jù),排序提升先生成一個(gè)隨機(jī)排列,隨機(jī)配列用于之后的模型訓(xùn)練,即在訓(xùn)練第個(gè)模型時(shí),使用排列中前個(gè)樣本進(jìn)行訓(xùn)練。在迭代過程中,為得到第個(gè)樣本的殘差估計(jì)值,使用第個(gè)模型進(jìn)行估計(jì)。
但這種訓(xùn)練個(gè)模型的做法會(huì)大大增加內(nèi)存消耗和時(shí)間復(fù)雜度,實(shí)際上可操作性不強(qiáng)。因此,CatBoost在以決策樹為基學(xué)習(xí)器的梯度提升算法的基礎(chǔ)上,對這種排序提升算法進(jìn)行了改進(jìn)。
CatBoost提供了兩種Boosting模式,Ordered和Plain。Plain就是在標(biāo)準(zhǔn)的GBDT算法上內(nèi)置了排序TS操作。而Ordered模式則是則排序提升算法上做出了改進(jìn)。
完整的Ordered模式描述如下:CatBoost對訓(xùn)練集產(chǎn)生個(gè)獨(dú)立隨機(jī)序列用來定義和評估樹結(jié)構(gòu)的分裂,用來計(jì)算分裂所得到葉子節(jié)點(diǎn)的值。CatBoost采用對稱樹作為基學(xué)習(xí)器,對稱意味著在樹的同一層,其分裂標(biāo)準(zhǔn)都是相同的。對稱樹具有平衡、不易過擬合并能夠大大減少測試時(shí)間的特點(diǎn)。CatBoost構(gòu)建樹的算法流程如下圖所示。
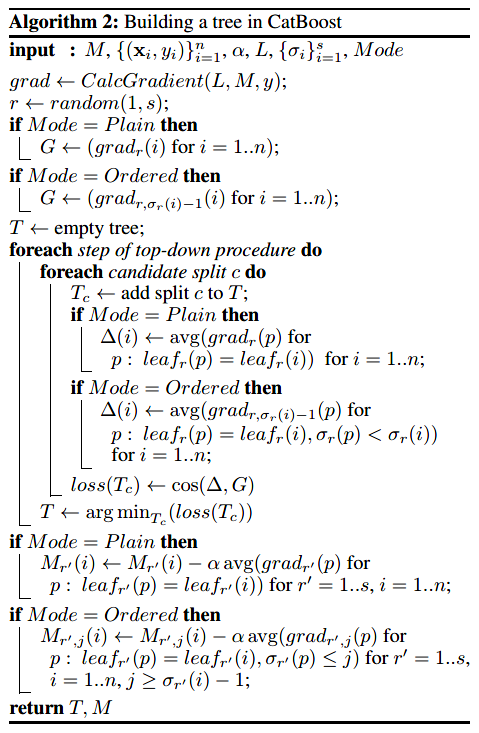
在Ordered模式學(xué)習(xí)過程中:
- 我們訓(xùn)練了一個(gè)模型,其中表示在序列中前個(gè)樣本學(xué)習(xí)得到的模型對于第個(gè)樣本的預(yù)測。
- 在每一次迭代中,算法從中抽樣一個(gè)序列,并基于此構(gòu)建第步的學(xué)習(xí)樹。
- 基于計(jì)算對應(yīng)梯度。
- 使用余弦相似度來近似梯度,對于每個(gè)樣本,取梯度。
- 在評估候選分裂節(jié)點(diǎn)過程中,第個(gè)樣本的葉子節(jié)點(diǎn)值由與同屬一個(gè)葉子的的所有樣本的前個(gè)樣本的梯度值求平均得到。
- 當(dāng)?shù)诓降臉浣Y(jié)構(gòu)確定以后,便可用其來提升所有模型。
注:這一段比較晦澀難懂,筆者也沒有完全深入理解,建議各位讀者一定去讀一下CatBoost論文原文。
基于構(gòu)建樹算法的完整CatBoost算法流程如下圖所示。

除了類別特征處理和排序提升以外,CatBoost還有許多其他亮點(diǎn)。比如說基于對稱樹(Oblivious Trees)的基學(xué)習(xí)器,提供多GPU訓(xùn)練加速支持等。
CatBoost與XGBoost、LightGBM對比
CatBoost與LightGBM開源前后時(shí)間相差不到3個(gè)月,二者都是在XGBoost基礎(chǔ)上做出的改進(jìn)和優(yōu)化。除了算法整體性能上的差異之外,基于CatBoost最主要的類別型特征處理特色,三者的主要差異如下:
- CatBoost支持最全面的類別型特征處理,可直接傳入類別型特征所在列標(biāo)識(shí)然后進(jìn)行自動(dòng)化處理。
- LightGBM同樣也支持對類別型特征的快速處理,訓(xùn)練時(shí)傳入類別型特征列所在標(biāo)識(shí)符即可。但LightGBM對于類別特征只是采用直接的硬編碼處理,雖然速度較快但不如CatBoost的處理方法細(xì)致。
- XGBoost作為最早的GBDT工程實(shí)現(xiàn),其本身并不支持處理類別型特征,只能傳入數(shù)值型數(shù)據(jù)。所以一般都需要手動(dòng)對類別型特征進(jìn)行one-hot等預(yù)處理。
CatBoost論文也給出了在多個(gè)開源數(shù)據(jù)集上與XGBoost和LightGBM性能對比。如下圖所示。
CatBoost算法實(shí)現(xiàn)
? 手動(dòng)實(shí)現(xiàn)一個(gè)CatBoost系統(tǒng)過于復(fù)雜,限于時(shí)間精力這里筆者選擇放棄。CatBoost源? ? 碼可參考:
https://github.com/catboost/catboost
CatBoost官方為我們提供相關(guān)的開源實(shí)現(xiàn)庫catboost,直接pip安裝即可。
下面以catboost一個(gè)分類例子作為演示。完整的catboost用法文檔參考:
https://catboost.ai/docs/concepts/tutorials.html
import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitimport catboost as cbfrom sklearn.metrics import f1_score# 讀取數(shù)據(jù)data = pd.read_csv('./adult.data', header=None)# 變量重命名data.columns = ['age', 'workclass', 'fnlwgt', 'education', 'education-num','marital-status', 'occupation', 'relationship', 'race', 'sex','capital-gain', 'capital-loss', 'hours-per-week', 'native-country', 'income']# 標(biāo)簽轉(zhuǎn)換data['income'] = data['income'].astype("category").cat.codes# 劃分?jǐn)?shù)據(jù)集X_train, X_test, y_train, y_test = train_test_split(data.drop(['income'], axis=1), data['income'],random_state=10, test_size=0.3)# 配置訓(xùn)練參數(shù)clf = cb.CatBoostClassifier(eval_metric="AUC", depth=4, iterations=500, l2_leaf_reg=1,learning_rate=0.1)# 類別特征索引cat_features_index = [1, 3, 5, 6, 7, 8, 9, 13]# 訓(xùn)練clf.fit(X_train, y_train, cat_features=cat_features_index)# 預(yù)測y_pred = clf.predict(X_test)# 測試集f1得分print(f1_score(y_test, y_pred))
參考資料:
https://catboost.ai/
CatBoost: unbiased boosting with categorical features
往期精彩:
數(shù)學(xué)推導(dǎo)+純Python實(shí)現(xiàn)機(jī)器學(xué)習(xí)算法18:LightGBM
數(shù)學(xué)推導(dǎo)+純Python實(shí)現(xiàn)機(jī)器學(xué)習(xí)算法27:LDA線性判別分析
一個(gè)算法工程師的成長之路

長按二維碼.關(guān)注機(jī)器學(xué)習(xí)實(shí)驗(yàn)室