
數(shù)學(xué)推導(dǎo)+純Python實現(xiàn)機器學(xué)習(xí)算法14:Ridge嶺回歸
點擊上方“小白學(xué)視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

上一節(jié)我們講到預(yù)防過擬合方法的Lasso回歸模型,也就是基于L1正則化的線性回歸。本講我們繼續(xù)來看基于L2正則化的線性回歸模型。
L2正則化
相較于L0和L1,其實L2才是正則化中的天選之子。在各種防止過擬合和正則化處理過程中,L2正則化可謂第一候選。L2范數(shù)是指矩陣中各元素的平方和后的求根結(jié)果。采用L2范數(shù)進行正則化的原理在于最小化參數(shù)矩陣的每個元素,使其無限接近于0但又不像L1那樣等于0,也許你又會問了,為什么參數(shù)矩陣中每個元素變得很小就能防止過擬合?這里我們就拿深度神經(jīng)網(wǎng)絡(luò)來舉例說明吧。在L2正則化中,如何正則化系數(shù)變得比較大,參數(shù)矩陣W中的每個元素都在變小,線性計算的和Z也會變小,激活函數(shù)在此時相對呈線性狀態(tài),這樣就大大簡化了深度神經(jīng)網(wǎng)絡(luò)的復(fù)雜性,因而可以防止過擬合。
加入L2正則化的線性回歸損失函數(shù)如下所示。其中第一項為MSE損失,第二項就是L2正則化項。
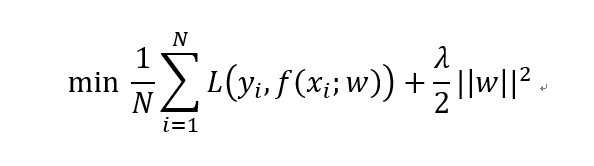
L2正則化相比于L1正則化在計算梯度時更加簡單。直接對損失函數(shù)關(guān)于w求導(dǎo)即可。這種基于L2正則化的回歸模型便是著名的嶺回歸(Ridge Regression)。
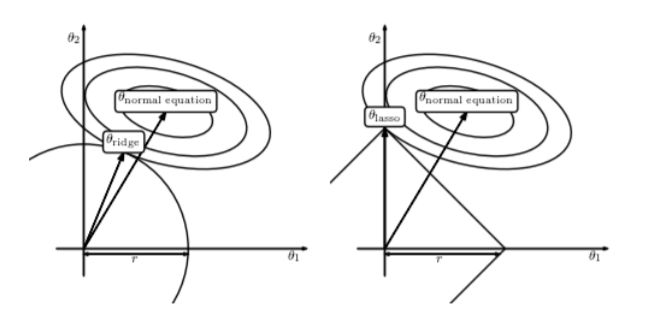
Ridge
有了上一講的代碼框架,我們直接在原基礎(chǔ)上對損失函數(shù)和梯度計算公式進行修改即可。下面來看具體代碼。
導(dǎo)入相關(guān)模塊:
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_split
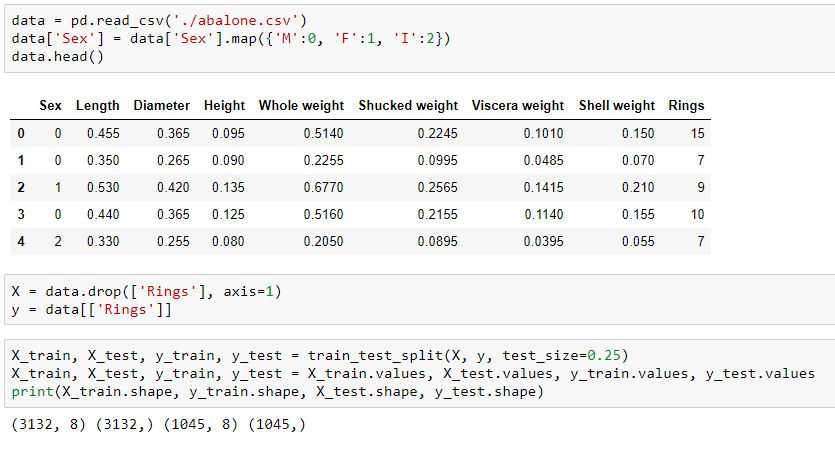
讀入示例數(shù)據(jù)并劃分:
data = pd.read_csv('./abalone.csv')data['Sex'] = data['Sex'].map({'M':0, 'F':1, 'I':2})X = data.drop(['Rings'], axis=1)y = data[['Rings']]X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)X_train, X_test, y_train, y_test = X_train.values, X_test.values, y_train.values, y_test.valuesprint(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
模型參數(shù)初始化:
# 定義參數(shù)初始化函數(shù)def initialize(dims):w = np.zeros((dims, 1))b = 0return w, b
定義L2損失函數(shù)和梯度計算:
# 定義ridge損失函數(shù)def l2_loss(X, y, w, b, alpha):num_train = X.shape[0]num_feature = X.shape[1]y_hat = np.dot(X, w) + bloss = np.sum((y_hat-y)**2)/num_train + alpha*(np.sum(np.square(w)))dw = np.dot(X.T, (y_hat-y)) /num_train + 2*alpha*wdb = np.sum((y_hat-y)) /num_trainreturn y_hat, loss, dw, db
定義Ridge訓(xùn)練過程:
def ridge_train(X, y, learning_rate=0.001, epochs=5000):loss_list = []w, b = initialize(X.shape[1])for i in range(1, epochs):y_hat, loss, dw, db = l2_loss(X, y, w, b, 0.1)w += -learning_rate * dwb += -learning_rate * dbloss_list.append(loss)if i % 100 == 0:print('epoch %d loss %f' % (i, loss))params = {'w': w,'b': b}grads = {'dw': dw,'db': db}return loss, loss_list, params, grads
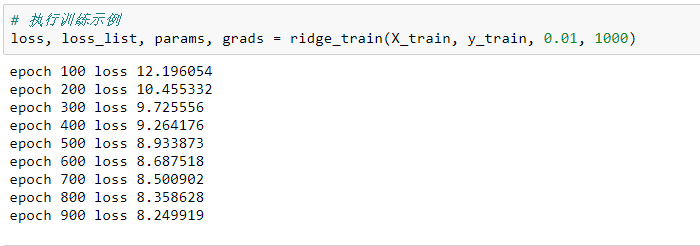
執(zhí)行示例訓(xùn)練:
loss, loss_list, params, grads = ridge_train(X_train, y_train, 0.01, 1000)
模型參數(shù):
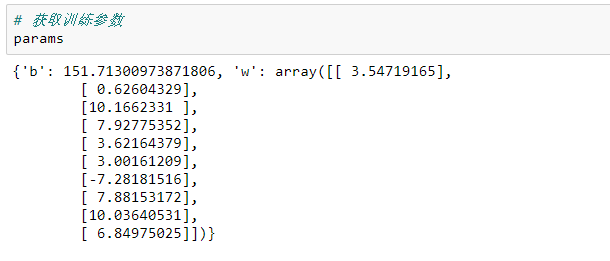
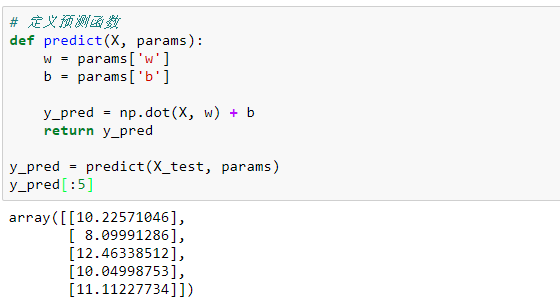
定義模型預(yù)測函數(shù):
def predict(X, params):w=params['w']b = params['b']y_pred = np.dot(X, w) + breturn y_predy_pred = predict(X_test, params)y_pred[:5]
測試集數(shù)據(jù)和模型預(yù)測數(shù)據(jù)的繪圖展示:
import matplotlib.pyplot as pltf = X_test.dot(params['w']) + params['b']plt.scatter(range(X_test.shape[0]), y_test)plt.plot(f, color = 'darkorange')plt.xlabel('X')plt.ylabel('y')plt.show();
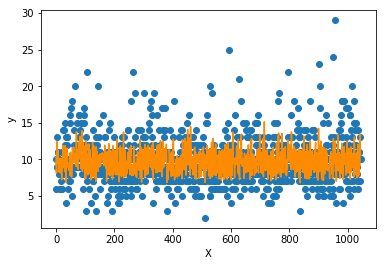
可以看到模型預(yù)測對于高低值的擬合較差,但能擬合大多數(shù)值。這樣的模型相對具備較強的泛化能力,不會產(chǎn)生嚴重的過擬合問題。
最后進行簡單的封裝:
import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitclass Ridge():def __init__(self):passdef prepare_data(self):data = pd.read_csv('./abalone.csv')data['Sex'] = data['Sex'].map({'M': 0, 'F': 1, 'I': 2})X = data.drop(['Rings'], axis=1)y = data[['Rings']]X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)X_train, X_test, y_train, y_test = X_train.values, X_test.values, y_train.values, y_test.valuesreturn X_train, y_train, X_test, y_testdef initialize(self, dims):w = np.zeros((dims, 1))b = 0return w, bdef l2_loss(self, X, y, w, b, alpha):num_train = X.shape[0]num_feature = X.shape[1]y_hat = np.dot(X, w) + bloss = np.sum((y_hat - y) ** 2) / num_train + alpha * (np.sum(np.square(w)))dw = np.dot(X.T, (y_hat - y)) / num_train + 2 * alpha * wdb = np.sum((y_hat - y)) / num_trainreturn y_hat, loss, dw, dbdef ridge_train(self, X, y, learning_rate=0.01, epochs=1000):loss_list = []w, b = self.initialize(X.shape[1])for i in range(1, epochs):y_hat, loss, dw, db = self.l2_loss(X, y, w, b, 0.1)w += -learning_rate * dwb += -learning_rate * dbloss_list.append(loss)if i % 100 == 0:print('epoch %d loss %f' % (i, loss))params = {'w': w,'b': b}grads = {'dw': dw,'db': db}return loss, loss_list, params, gradsdef predict(self, X, params):w = params['w']b = params['b']y_pred = np.dot(X, w) + breturn y_predif __name__ == '__main__':ridge = Ridge()X_train, y_train, X_test, y_test = ridge.prepare_data()loss, loss_list, params, grads = ridge.ridge_train(X_train, y_train, 0.01, 1000)print(params)
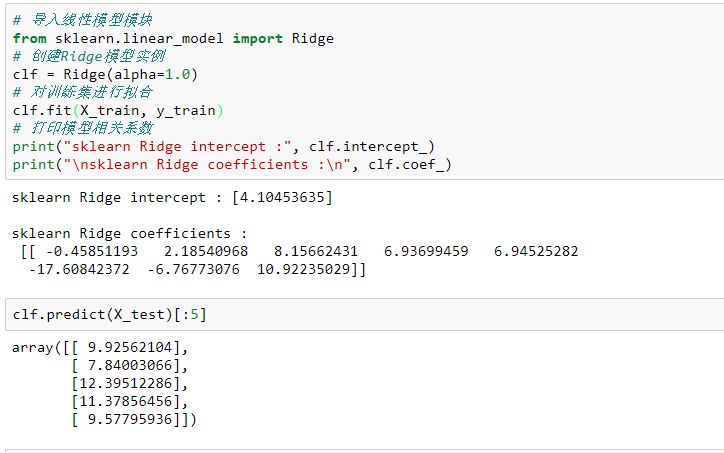
sklearn中也提供了Ridge的實現(xiàn)方式:
# 導(dǎo)入線性模型模塊from sklearn.linear_model import Ridge# 創(chuàng)建Ridge模型實例clf = Ridge(alpha=1.0)# 對訓(xùn)練集進行擬合clf.fit(X_train, y_train)# 打印模型相關(guān)系數(shù)print("sklearn Ridge intercept :", clf.intercept_)print("\nsklearn Ridge coefficients :\n", clf.coef_)
以上就是本節(jié)內(nèi)容,下一節(jié)我們將延伸樹模型,重點關(guān)注集成學(xué)習(xí)和GBDT系列。
更多內(nèi)容可參考筆者GitHub地址:
https://github.com/luwill/machine-learning-code-writing
代碼整體較為粗糙,還望各位不吝賜教。
好消息!
小白學(xué)視覺知識星球
開始面向外開放啦??????
下載1:OpenCV-Contrib擴展模塊中文版教程 在「小白學(xué)視覺」公眾號后臺回復(fù):擴展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺實戰(zhàn)項目52講 在「小白學(xué)視覺」公眾號后臺回復(fù):Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內(nèi)容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學(xué)校計算機視覺。 下載3:OpenCV實戰(zhàn)項目20講 在「小白學(xué)視覺」公眾號后臺回復(fù):OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現(xiàn)20個實戰(zhàn)項目,實現(xiàn)OpenCV學(xué)習(xí)進階。 交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~