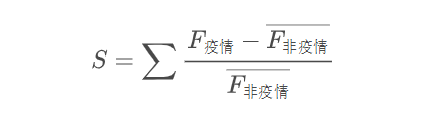
其中 S 的含義是這樣的:如果發(fā)燒的搜索是發(fā)燒人口的一個相對穩(wěn)定的比例,且在非疫情期間發(fā)燒人口是總?cè)丝诘南鄬Ψ€(wěn)定的比例。那么 S 就正比于疫情感染的人口占總?cè)丝诘谋壤覀儼阉凶?“超額發(fā)燒搜索指數(shù)累計面積”。②下圖列出了臺灣地區(qū)、香港特別行政區(qū)以及日本的 “超額發(fā)燒搜索指數(shù)累計面積”,即下圖橙色面積、藍(lán)色面積和灰色面積。
我們發(fā)現(xiàn)在這三個地區(qū),當(dāng)疫情達(dá)到頂峰時,這個“超額發(fā)燒搜索指數(shù)累計面積” 的數(shù)值全部剛好達(dá)到 80。這兩個地區(qū)第一波疫情結(jié)束時,香港特別行政區(qū)的面積達(dá)到了 160,臺灣地區(qū)的面積達(dá)到了 200,日本的最終面積是 250。③如果用百度搜索指數(shù)做類似的研究會有什么效果呢?我使用了本輪疫情進(jìn)入群體感染最快、最早的石家莊、邢臺和保定做了計算: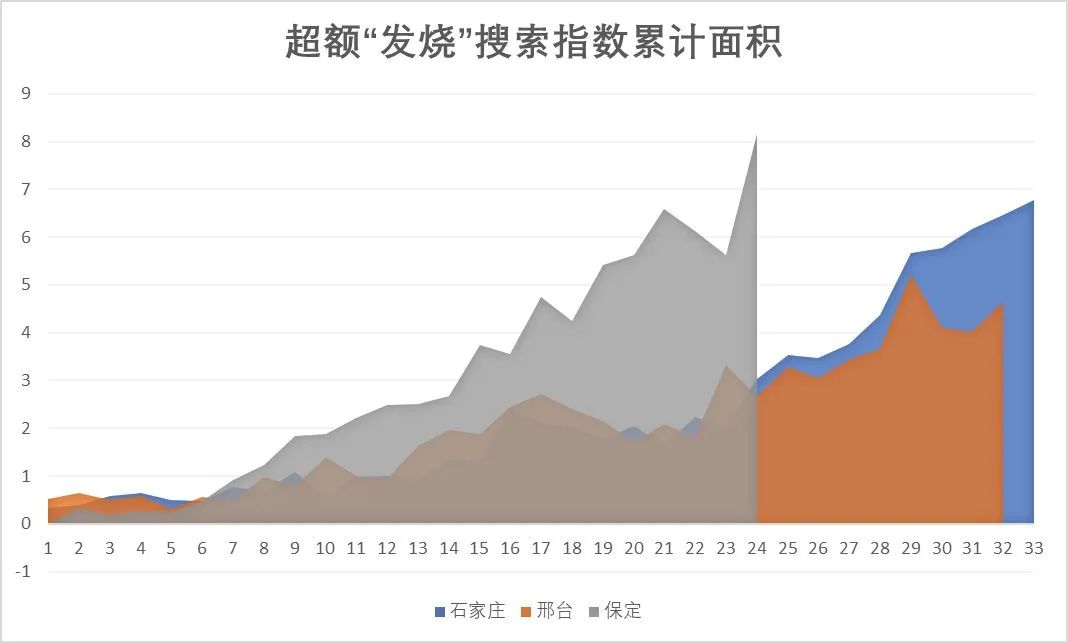
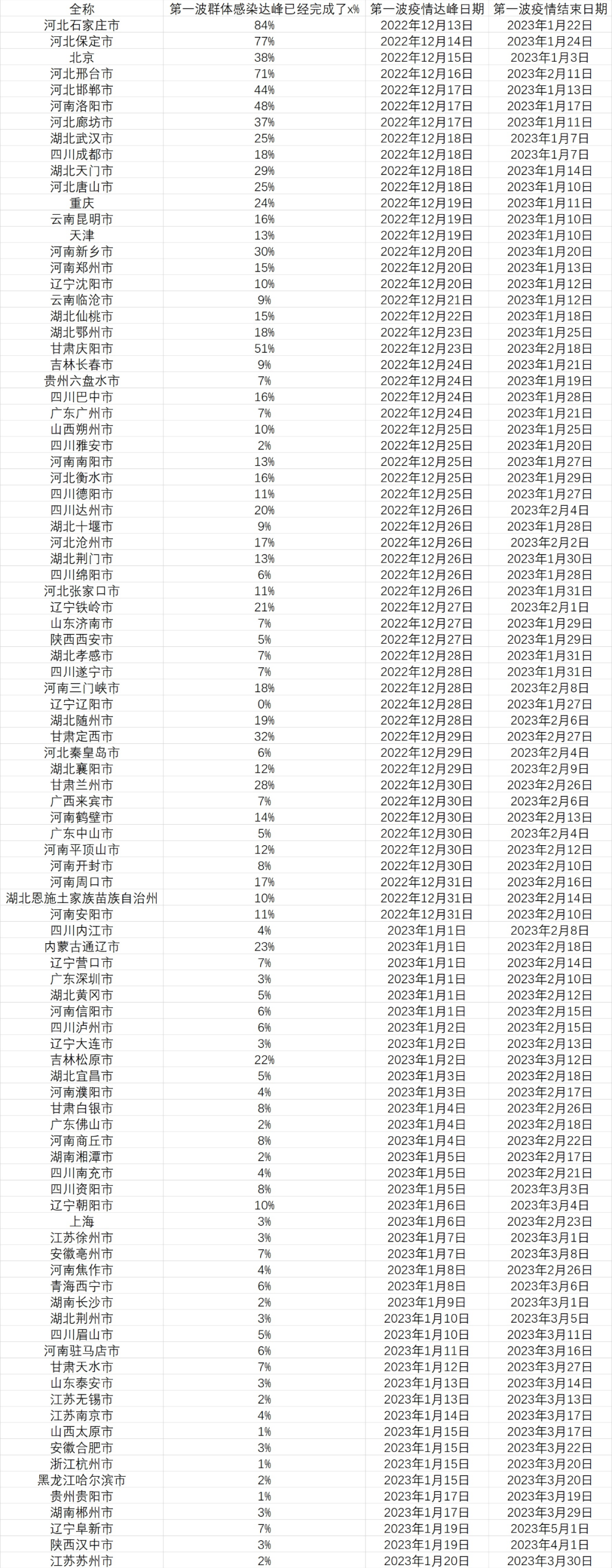
可以算出,從疫情開始后計算,石家莊的 “超額發(fā)燒搜索指數(shù)累計面積” 已經(jīng)達(dá)到了 76,邢臺已經(jīng)達(dá)到了 67,保定也達(dá)到了 71。由此來看,百度搜索指數(shù)和 Google 指數(shù)分別算出的“超額發(fā)燒搜索指數(shù)累計面積”,至少是在一個差不多的數(shù)量級上。④考慮到保定、石家莊、邢臺等地的發(fā)燒指數(shù)仍然在上升,以及百度搜索指數(shù)和 Google 指數(shù)的差異。我們比較保守地將 100 作為疫情達(dá)峰時的 “超額發(fā)燒搜索指數(shù)累計面積”,將 250 作為第一輪疫情結(jié)束時的 “超額發(fā)燒搜索指數(shù)累計面積”。那么我們通過每個城市的搜索指數(shù)累計增長,累計速度,就可以算出現(xiàn)在每一個有疫情的城市疫情達(dá)峰的時間,以及疫情結(jié)束的時間。這是計算的結(jié)果,列出了所有能在明年春節(jié)前達(dá)峰的城市以及這些城市在達(dá)峰前已經(jīng)感染的人口比例(截止至 12 月 10 日)。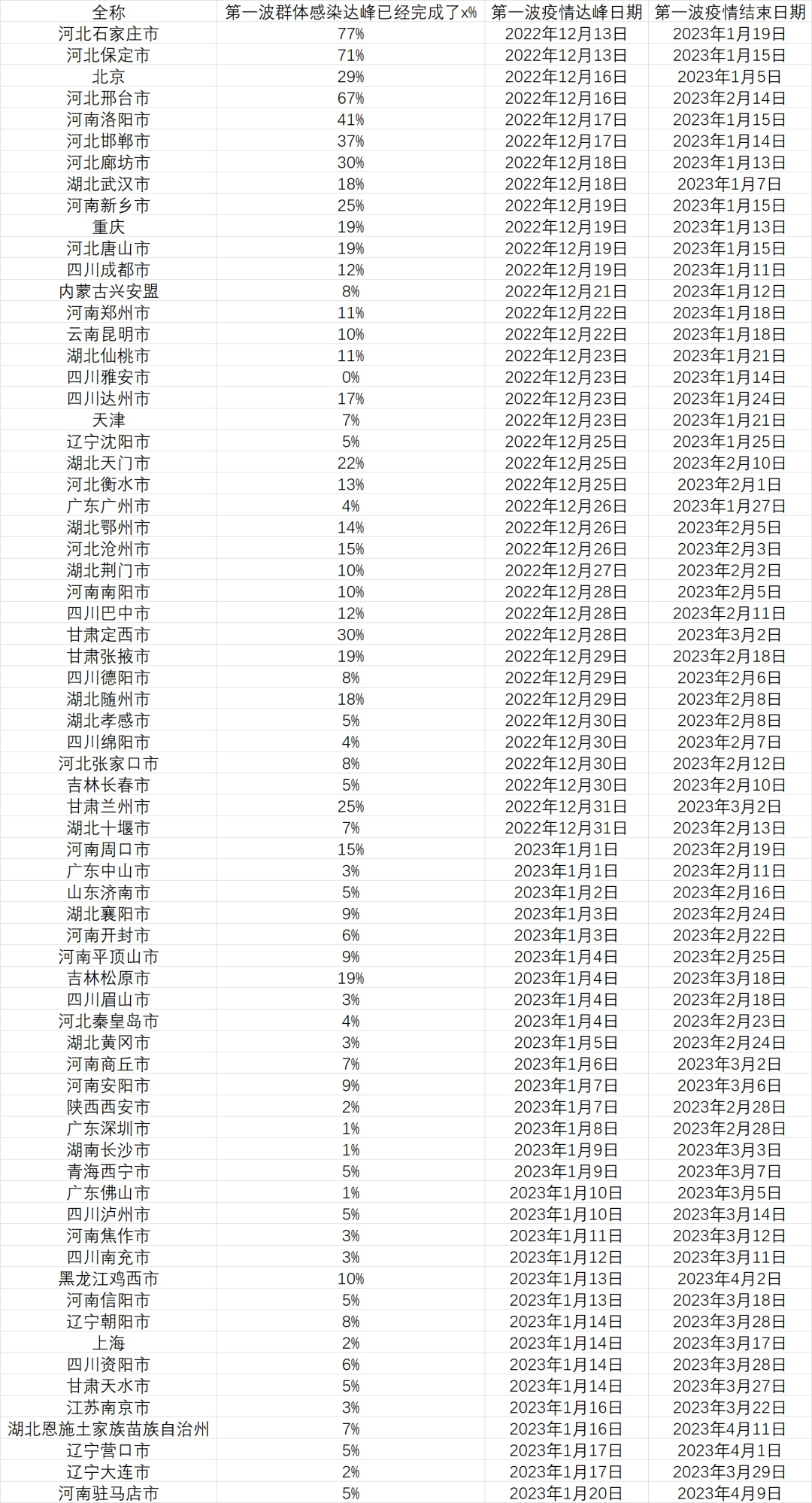

第一是加入了巨量算數(shù)指標(biāo)修正了一些城市,加入了一些之前數(shù)據(jù)不足的城市。第二是我將過峰的“超額發(fā)燒搜索累計面積”修正回了 80。之前的幾張表格中,保守起見,這個數(shù)值我使用的是 100,他會使一些城市過峰偏慢。但從這幾天的數(shù)據(jù)看,石家莊、保定等地已經(jīng)過峰,這說明中國內(nèi)地城市居民,在非疫情-疫情的變化中,搜索行為的變化上和香港特別行政區(qū)、臺灣地區(qū)的居民在同樣時期的變化是非常類似的。因此一些城市會在今天的表格中有所提前。第三是加入了“結(jié)束進(jìn)度條”這一變量,代表已經(jīng)度過疫情頂峰的城市在第一波疫情結(jié)束前可能還要走的路程。
“達(dá)峰進(jìn)度條”說明的是在疫情達(dá)到日增頂峰前已經(jīng)感染了多少人,這是城市疫情逐漸加劇,院感增加,醫(yī)療資源逐漸擠兌的一段日子,數(shù)字達(dá)到 100 時日增感染者就達(dá)到了頂峰。
而“結(jié)束進(jìn)度條”說明的是在疫情過峰后,在這一波疫情結(jié)束前已經(jīng)感染了多少人,這段時間的疫情雖然整體緩解,但感染還是會繼續(xù)增加,并且大部分死亡會出現(xiàn)在這個階段。在數(shù)字達(dá)到 100 時,城市的這一波疫情就基本結(jié)束了。
疫情達(dá)峰時間的推算,原本只是搜索指數(shù)的一次嘗試,初衷是覺得有趣,但無心插柳,竟然能幫助許多人緩解焦慮。
焦慮來自哪里?來自未知。既然和疫情共存了,那么不怕他不來,肯定得來,就怕它在計劃外亂來。
那么有一個數(shù)據(jù),雖然簡陋,但也比沒有數(shù)據(jù)好,至少大致上是和真實趨勢吻合的。
既然如此,在衛(wèi)健委有能力提供真實數(shù)據(jù)之前,我還是會希望繼續(xù)更新下去,讓這份粗糙的數(shù)據(jù)陪伴大家渡過第一次沖擊。

今天按照行政區(qū)劃代碼的順序做了排序,增加了一個變量“累計感染占總?cè)丝诒戎怠薄?/span>這個數(shù)值也是根據(jù)累計的超額搜索面積計算的。在“數(shù)據(jù)團(tuán)+”小程序中也做了相應(yīng)更新。一些人口較少的城市的搜索指數(shù)變化幅度較大,可能會導(dǎo)致數(shù)據(jù)波動。
今天修改了許多之前計算的 bug,比如多段疫情被合并計算(例如新疆的一些城市被合并三個月疫情后出現(xiàn)了超過 100 的感染率),疫情結(jié)束時間的算法尾部過寬,一些小城市的缺失(比如濟(jì)源、仙桃、吉林省吉林市)以及巨量算數(shù)的權(quán)重。頭條系產(chǎn)品的許多數(shù)據(jù)來自被動推送,比如點擊搜索框,出現(xiàn)一個“內(nèi)馬爾發(fā)燒了”,吸引用戶點擊后,可能就會造成一些地方的“發(fā)燒”搜索異常。我使用百度的全國指數(shù)作為基準(zhǔn)整體修正了巨量算數(shù),得到了一個更為穩(wěn)健的結(jié)果。有些讀者可能會注意到今天有一些城市的疫情過峰時間、結(jié)束時間都變長了,這一方面來自上面的幾項 bug 修改的結(jié)果。當(dāng)然,更重要的一方面原因是一些城市確實在壓平曲線,盡量降低疫情的增速。快速過峰當(dāng)然會使得這個城市能夠較快地離開第一波疫情,但是同樣也會造成醫(yī)療資源大量擠兌。力所能及地增加一些社交距離,雖然會讓這個城市的疫情更持久,但總死亡也會降低,在第一波感染中,還是值得的。這也是我們的模型最后一次大幅度修改,之后的數(shù)據(jù)就能保持相對穩(wěn)定了。
數(shù)據(jù)不足,方法簡陋,僅供參考。