
12篇論文看盡深度學(xué)習(xí)目標(biāo)檢測(cè)史
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
本文轉(zhuǎn)自|視覺算法

極市導(dǎo)讀
本文梳理了目標(biāo)檢測(cè)領(lǐng)域2013年至2019年的12篇必讀論文,為希望學(xué)習(xí)相關(guān)知識(shí)的新手提供了很好的入門路徑。同時(shí),作者還提供了一個(gè)附加論文列表。作為拓展閱讀的內(nèi)容,它們或?yàn)槟繕?biāo)檢測(cè)提供了新的視角,或用更強(qiáng)大的功能擴(kuò)展了這個(gè)領(lǐng)域。>>極市直播預(yù)告:CSIG-ECCV2020 論文預(yù)交流會(huì),29位ECCV2020一作聯(lián)合直播
12 Papers You Should Read to Understand Object Detection in the Deep Learning Era
原作者:Ethan Yanjia Li
編譯:McGL
鏈接:https://towardsdatascience.com/12-papers-you-should-read-to-understand-object-detection-in-the-deep-learning-era-3390d4a28891
前言
計(jì)算機(jī)視覺研究中,目標(biāo)檢測(cè)是一個(gè)比分類更困難的領(lǐng)域,我們將回顧它的歷史和最近的發(fā)展。在深度學(xué)習(xí)時(shí)代之前,像 HOG 和特征金字塔這樣的手工特性被廣泛用于獲取圖像中的定位信號(hào)。然而,這些方法通常不能很好地?cái)U(kuò)展到通用的目標(biāo)檢測(cè),所以大多數(shù)的應(yīng)用僅限于人臉識(shí)別或者行人檢測(cè)。利用深度學(xué)習(xí)的力量,我們可以訓(xùn)練一個(gè)網(wǎng)絡(luò)來(lái)學(xué)習(xí)要獲取的特征,并預(yù)測(cè)目標(biāo)的坐標(biāo)。這最終帶來(lái)了基于視覺感知的應(yīng)用的繁榮,比如商業(yè)人臉識(shí)別系統(tǒng)和無(wú)人機(jī)。在這篇文章里,我為那些想要學(xué)習(xí)目標(biāo)檢測(cè)的新手挑選了12篇必讀論文。盡管構(gòu)建目標(biāo)檢測(cè)系統(tǒng)最具挑戰(zhàn)性的部分隱藏在實(shí)現(xiàn)細(xì)節(jié)中,但是閱讀這些論文仍然可以讓你對(duì)這些想法的來(lái)源以及未來(lái)目標(biāo)檢測(cè)將如何發(fā)展有一個(gè)很好的大致理解。
作為閱讀本文的前提條件,你需要了解卷積神經(jīng)網(wǎng)絡(luò)的基本思想,以及常用的優(yōu)化方法,如帶反向傳播的梯度下降法。還有圖像分類的基礎(chǔ)知識(shí),因?yàn)槟繕?biāo)檢測(cè)的許多很酷的想法都來(lái)源于更基礎(chǔ)的圖像分類研究。
2013:OverFeat
OverFeat: 使用卷積網(wǎng)絡(luò)集成識(shí)別、定位和檢測(cè)

源自論文 “OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks”
在2012年的 ImageNet 競(jìng)賽中,基于 CNN 特征提取的AlexNet擊敗了所有手工設(shè)計(jì)的特征提取器。受到 AlexNet 成功的啟發(fā),OverFeat 迅速將 CNN 引入到目標(biāo)檢測(cè)領(lǐng)域。這個(gè)想法非常直接: 如果我們可以用 CNN 對(duì)一張圖片進(jìn)行分類,那么用不同大小的窗口滑動(dòng)瀏覽整張圖片,然后嘗試用 CNN 逐一對(duì)它們進(jìn)行分類呢?該算法利用了 CNN 的特征提取和分類能力,并通過(guò)預(yù)定義的滑動(dòng)窗口繞過(guò)了硬 region proposal 問題。另外,由于鄰近的卷積核可以共享部分計(jì)算結(jié)果,因此不需要計(jì)算重疊區(qū)域的卷積,從而大大降低了成本。OverFeat 是單階段目標(biāo)檢測(cè)器的先驅(qū)。它試圖在同一個(gè) CNN 中結(jié)合特征提取、位置回歸和區(qū)域分類。不幸的是,這種單階段的方法由于使用較少的先驗(yàn)知識(shí),精確度也相對(duì)較差。因此,OverFeat 未能引領(lǐng)單階段檢測(cè)器研究的熱潮,直到兩年后出現(xiàn)了一個(gè)更優(yōu)雅的解決方案。
2013: R-CNN
基于區(qū)域卷積網(wǎng)絡(luò)的精確目標(biāo)檢測(cè)和分割
R-CNN 也是在2013年提出的,比 OverFeat 晚了點(diǎn)。然而,這種基于區(qū)域的方法最終以其兩階段的框架,即 region proposal 階段和區(qū)域分類與精細(xì)化階段,引發(fā)了目標(biāo)檢測(cè)研究的大浪潮。
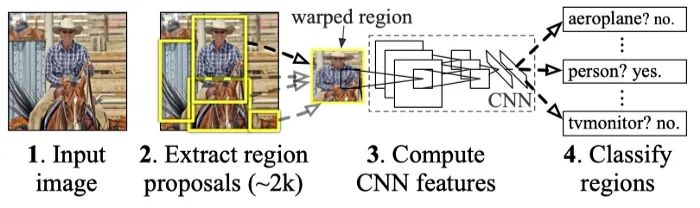
源自論文“Region-based Convolutional Networks for Accurate Object Detection and Segmentation”
在上圖中,R-CNN 首先使用一種稱為selective search的技術(shù)從輸入圖像中提取出感興趣的潛在區(qū)域。selective search并不真正嘗試?yán)斫馇熬澳繕?biāo),相反,它依靠啟發(fā)式方法對(duì)相似的像素進(jìn)行分組: 相似的像素通常屬于同一個(gè)目標(biāo)。因此,selective search的結(jié)果很有可能包含一些有意義的內(nèi)容。接下來(lái),R-CNN 將這些 region proposals 變換成帶有一些填充的固定大小的圖像,并將這些圖像提供給網(wǎng)絡(luò)的第二階段,以便進(jìn)行更細(xì)粒度的識(shí)別。與那些使用selective search的舊方法不同,R-CNN 在第二階段將 HOG 替換為 CNN,從所有 region proposals 中提取特征。這種方法需要注意的是,許多 region proposals 實(shí)際上并不是一個(gè)完整的目標(biāo),因此 R-CNN 不僅需要學(xué)習(xí)如何對(duì)包含的類別進(jìn)行分類,還需要學(xué)習(xí)如何拒絕負(fù)類。為了解決這個(gè)問題,R-CNN 將所有與一個(gè)ground truth框重疊度≥0.5 IoU 的 region proposal 視為正,其余視為負(fù)。
selective search 的 region proposal 高度依賴于相似性假設(shè),因此只能提供大致的位置估計(jì)。為了進(jìn)一步提高定位精度,R-CNN 借鑒了“Deep Neural Networks for Object Detection”(又名 DetectorNet)的思想,引入了額外的邊界框回歸來(lái)預(yù)測(cè)框的中心坐標(biāo)、寬度和高度。這種回歸器被廣泛應(yīng)用于未來(lái)的目標(biāo)檢測(cè)器中。
然而,像 R-CNN 這樣的兩階段檢測(cè)器存在兩個(gè)大問題: 1) selective search并不是卷積,因?yàn)樗皇嵌说蕉丝捎?xùn)練的。2) region proposal 階段與 OverFeat 等其他單階段檢測(cè)器相比通常非常慢,而且在每個(gè) region proposal上分別運(yùn)行會(huì)使其更慢。稍后,我們將看到 R-CNN 如何隨著時(shí)間的推移逐步演變以解決這兩個(gè)問題的。
2015: Fast R-CNN
Fast R-CN
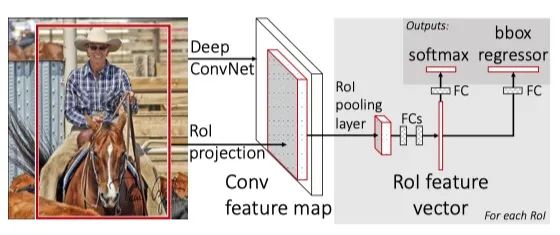
源自論文“Fast R-CNN”
R-CNN 的一個(gè)快速后續(xù)是減少對(duì)多個(gè) region proposals 的重復(fù)卷積。由于這些 region proposals 都來(lái)自一個(gè)圖像,自然而然地想到,可以通過(guò)對(duì)整個(gè)圖像運(yùn)行一次 CNN,并在許多 region proposals 之間共享計(jì)算,來(lái)改進(jìn) R-CNN。然而,不同的 region proposals 有不同的大小,如果我們使用相同的 CNN 特征提取器,會(huì)導(dǎo)致不同的輸出特征圖大小。這些具有不同大小的特征圖將阻止我們使用全連接層進(jìn)行進(jìn)一步的分類和回歸,因?yàn)槿B接層的輸入只能是固定大小。
幸運(yùn)的是,論文“Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition”解決了全連接層的動(dòng)態(tài)縮放問題。在 SPPNet 中,在卷積層和 FC 層之間引入了特征金字塔池化,以創(chuàng)建bag-of-words式的特征向量。這個(gè)向量有固定的大小和不同尺度的特征特征,所以我們的卷積層現(xiàn)在可以接受任意尺寸的圖像作為輸入,而不用擔(dān)心 FC 層的不兼容性。受此啟發(fā),F(xiàn)ast R-CNN 提出了一個(gè)類似的層稱為 ROI Pooling 層。這個(gè)池化層將不同大小的特征圖 downsample 為一個(gè)固定大小的向量。這樣我們就可以使用相同的 FC 層進(jìn)行分類和框回歸,不管 ROI 是大還是小。
Fast R-CNN 由于采用了共享特征提取器和尺度不變(scale-invariant)的 ROI 池化層,達(dá)到類似的定位精度,訓(xùn)練快了10 ~ 20倍,且推理快了100 ~ 200倍。接近實(shí)時(shí)推理和一個(gè)更易用的端到端檢測(cè)部分訓(xùn)練協(xié)議使Fast R-CNN 成為業(yè)界的熱門選擇。
2015: Faster R-CNN
Faster R-CNN: 通過(guò)Region Proposal Networks實(shí)現(xiàn)實(shí)時(shí)目標(biāo)檢測(cè)
正如我們上面介紹的,在2015年初,Ross Girshick 提出了一個(gè)改進(jìn)版本的 R-CNN,稱為 Fast R-CNN,對(duì)建議的區(qū)域使用共享的特征提取器。僅僅幾個(gè)月后,Ross和他的團(tuán)隊(duì)又帶著另一個(gè)改進(jìn)回來(lái)了。這個(gè)新的網(wǎng)絡(luò)Faster R-CNN 不僅比以前的版本更快,而且標(biāo)志著目標(biāo)檢測(cè)深度學(xué)習(xí)方法的一個(gè)里程碑。
源自論文“Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”
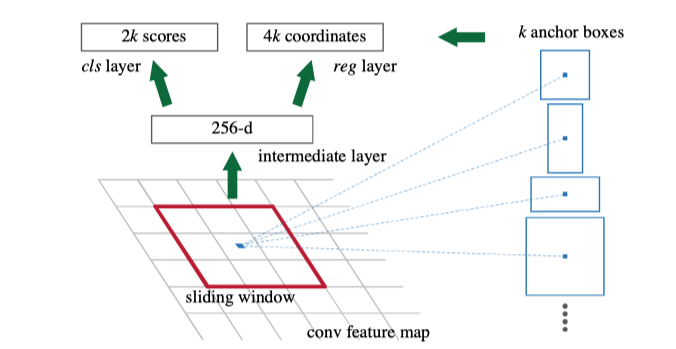
有了 Fast R-CNN,網(wǎng)絡(luò)中唯一的非卷積部分就是 selective search 的 region proposal了。2015年,研究人員開始意識(shí)到深層神經(jīng)網(wǎng)絡(luò)是如此神奇,只要有足夠的數(shù)據(jù),它就可以學(xué)習(xí)任何東西。那么,是否有可能訓(xùn)練一個(gè) region proposal 的神經(jīng)網(wǎng)絡(luò),而不是依賴于 selective search 等啟發(fā)式和手工的方法?Faster R-CNN 遵循這個(gè)方向和思路,并成功地創(chuàng)建了Region Proposal Network(RPN)。簡(jiǎn)單地說(shuō),RPN 是一個(gè) CNN,以圖像作為輸入,并輸出一組矩形目標(biāo)建議,每個(gè)都有一個(gè) objectiveness 得分。論文最初使用的是 VGG,但其他主干網(wǎng)絡(luò)如 ResNet 后來(lái)變得更加普及。為了生成 region proposals,在 CNN 特征圖輸出上應(yīng)用一個(gè)3x3滑動(dòng)窗口每個(gè)位置生成2個(gè)得分(前景和背景)和4個(gè)坐標(biāo)值。實(shí)際上,這個(gè)滑動(dòng)窗口是用一個(gè)帶有1x1卷積核的3x3卷積核來(lái)實(shí)現(xiàn)的。
雖然滑動(dòng)窗口有一個(gè)固定的大小,我們的目標(biāo)可能有不同的尺度。因此,F(xiàn)aster R-CNN 引入了一種稱為 anchor box 的技術(shù)。Anchor boxes 是預(yù)先定義的具有不同寬高比和尺寸的框,但共享相同的中心位置。在 Faster R-CNN 中,每個(gè)滑動(dòng)窗口位置都有 k = 9個(gè)anchors,每個(gè)anchor 覆蓋3個(gè)高寬比和3個(gè)尺度。這些不同尺度的重復(fù) anchor boxes 在共享同一特征圖輸出的同時(shí),為網(wǎng)絡(luò)帶來(lái)了良好的平移不變性和比例不變性。請(qǐng)注意,邊界框回歸將從這些anchor box 而不是從整個(gè)圖來(lái)計(jì)算。
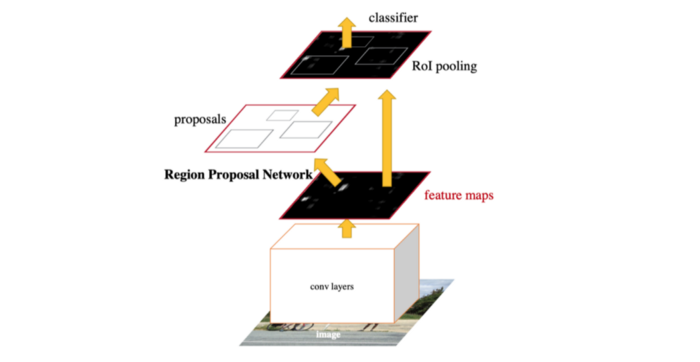
源自論文“Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”
到目前為止,我們討論了新的 Region Proposal Network 來(lái)取代舊的 selective search 進(jìn)行region proposal。為了進(jìn)行最終的檢測(cè),F(xiàn)aster R-CNN 使用與 Fast R-CNN 相同的檢測(cè)頭進(jìn)行分類和細(xì)粒度定位。你還記得 Fast R-CNN 還使用共享的 CNN 特性提取器嗎?既然 RPN 本身也是一個(gè)特征提取 CNN,我們可以像上面的圖表那樣與檢測(cè)頭共享它。這種分享設(shè)計(jì)并不會(huì)帶來(lái)什么麻煩。如果我們一起訓(xùn)練 RPN 和 Fast R-CNN 檢測(cè)器,我們將把 RPN proposals 作為 ROI 池化的一個(gè)常量輸入,并且不可避免地忽略 RPN 邊界框proposals的梯度。一個(gè)繞開方法被稱為替代訓(xùn)練,即輪流訓(xùn)練 RPN 和Fast R-CNN 。在后來(lái)的論文“Instance-aware semantic segmentation via multi-task network cascades”中,我們可以看到 ROI 池化層也可以對(duì)框坐標(biāo)proposals微分。
2015: YOLO v1
你只看一次: 統(tǒng)一,實(shí)時(shí)的目標(biāo)檢測(cè)
雖然 R-CNN 系列在研究界引起了關(guān)于兩階段目標(biāo)檢測(cè)的大肆炒作,但其復(fù)雜的實(shí)現(xiàn)給維護(hù)它的工程師們帶來(lái)了許多頭疼的問題。目標(biāo)檢測(cè)有必要這么麻煩嗎?如果我們?cè)敢鉅奚稽c(diǎn)準(zhǔn)確率,我們能換來(lái)更快的速度嗎?帶著這些問題,Joseph Redmon 在 Faster R-CNN 發(fā)布僅僅四天后就向http://arxiv.org提交了一個(gè)名為 YOLO 的網(wǎng)絡(luò),并且在 OverFeat 首次亮相兩年后,終于將人氣帶回到了單階段目標(biāo)檢測(cè)。
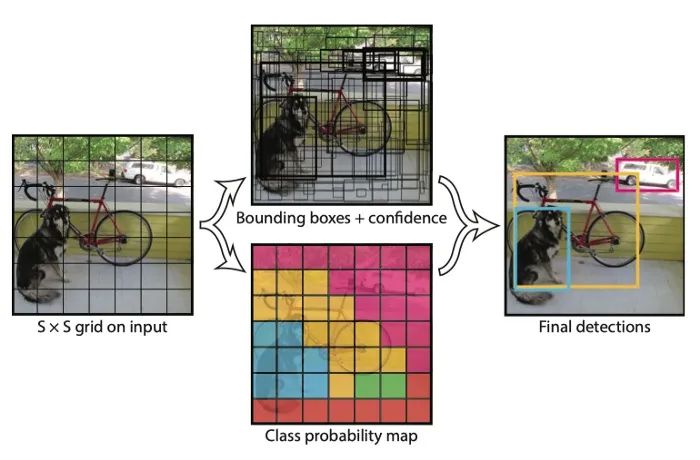
源自論文“You Only Look Once: Unified, Real-Time Object Detection”
與 R-CNN 不同的是,YOLO 決定在同一個(gè) CNN 上一起處理region proposal和分類。換句話說(shuō),它把目標(biāo)檢測(cè)問題看作是一個(gè)回歸問題,而不是一個(gè)依賴于region proposal的分類問題。其基本思想是將輸入分割成一個(gè) SxS 網(wǎng)格,并讓每個(gè)單元直接回歸邊界框的位置以及如果目標(biāo)中心落入該單元時(shí)的置信度得分。因?yàn)槟繕?biāo)可能有不同的大小,將有一個(gè)以上的邊界框回歸器落到每個(gè)單元。在訓(xùn)練過(guò)程中,將指定IOU最高的回歸器與ground-truth 標(biāo)簽進(jìn)行比較,因此同一位置的回歸器將學(xué)會(huì)隨著時(shí)間的推移處理不同的尺度。同時(shí),當(dāng)網(wǎng)格單元包含一個(gè)目標(biāo)(高置信度得分)時(shí),每個(gè)單元也將預(yù)測(cè) C 類概率。這種方法后來(lái)被描述為稠密的預(yù)測(cè),因?yàn)?YOLO 試圖預(yù)測(cè)圖像中所有可能位置的類和邊界框。相比之下,R-CNN 依賴于region proposals來(lái)過(guò)濾背景區(qū)域,因此最終的預(yù)測(cè)更加稀疏。
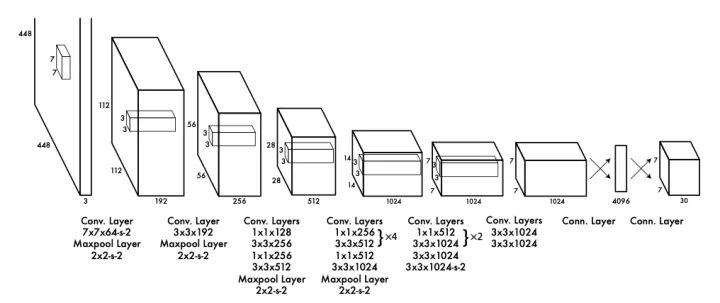
源自論文“You Only Look Once: Unified, Real-Time Object Detection”
在整張圖片上的密集預(yù)測(cè)的計(jì)算成本很大,為了避免這個(gè)問題,YOLO 采用了 GooLeNet 的瓶頸結(jié)構(gòu)。YOLO 的另一個(gè)問題是,兩個(gè)對(duì)象可能落入同一個(gè)粗糙的網(wǎng)格單元,所以它不能很好地處理小目標(biāo),如一群鳥。盡管精確度較低,但 YOLO 簡(jiǎn)單易懂的設(shè)計(jì)和實(shí)時(shí)推理能力使得單階段目標(biāo)檢測(cè)在研究中再次流行起來(lái),同時(shí)也是業(yè)界的首選解決方案。
2015: SSD
SSD: 單發(fā)多框檢測(cè)器
YOLO v1顯示了單階段檢測(cè)的潛力,但和兩階段檢測(cè)的性能差距仍然很明顯。在 YOLO v1中,可以將多個(gè)目標(biāo)分配給同一個(gè)網(wǎng)格單元。這對(duì)于探測(cè)微小物體來(lái)說(shuō)是一個(gè)巨大的挑戰(zhàn),也成為提高單階段檢測(cè)器性能到與兩階段檢測(cè)器相當(dāng)?shù)年P(guān)鍵問題。SSD是一個(gè)挑戰(zhàn)者,從三個(gè)角度解決這個(gè)問題。
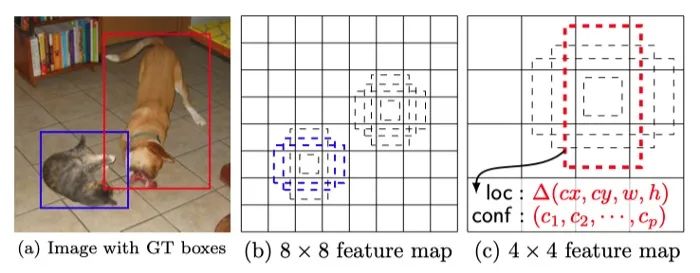
源自論文 “SSD: Single Shot MultiBox Detector”
首先,來(lái)自 Faster R-CNN 的anchor box 技術(shù)可以緩解這個(gè)問題。同一區(qū)域中的對(duì)象通常具有不同的可見長(zhǎng)寬比。引入anchor box 不僅增加了每個(gè)單元的目標(biāo)檢測(cè)數(shù)量,而且利用這個(gè)長(zhǎng)寬比假設(shè)可以更好地區(qū)分重疊的小目標(biāo)。
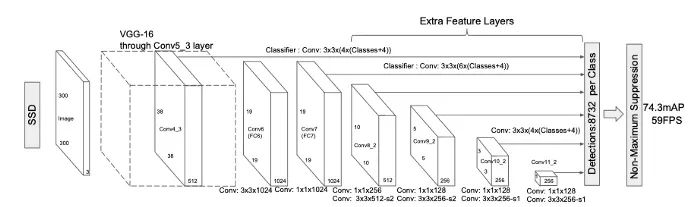
源自論文 “SSD: Single Shot MultiBox Detector”
SSD 進(jìn)一步在檢測(cè)之前聚合多尺度特征。這是一個(gè)提取細(xì)粒度的局部特征非常常見的方法,同時(shí)保留粗糙的全局特征在 CNN 中。例如,CNN 語(yǔ)義分割的先驅(qū) FCN 也從多個(gè)層次對(duì)特征進(jìn)行融合,以提取分割的邊界。此外,多尺度特征聚合可以方便地在所有常用的分類網(wǎng)絡(luò)上進(jìn)行,從而方便了主干網(wǎng)與其他網(wǎng)絡(luò)的替換。
最后,SSD 利用了大量的數(shù)據(jù)增強(qiáng),特別是針對(duì)小目標(biāo)。例如,在隨機(jī)裁剪之前,圖像被隨機(jī)擴(kuò)展到更大的尺寸,這給訓(xùn)練數(shù)據(jù)帶來(lái)了縮放效果,以模擬小目標(biāo)。此外,大的邊界框通常很容易學(xué)習(xí)。為了避免這些簡(jiǎn)單的樣本主導(dǎo)損失函數(shù),SSD 采用了一種hard negative mining技術(shù),為每個(gè)anchor box選出損失最大的樣本。
2016: FPN
目標(biāo)檢測(cè)的特色金字塔網(wǎng)絡(luò)
隨著 Faster-RCNN、 YOLO 和 SSD 在2015年的發(fā)布,似乎確定了目標(biāo)檢測(cè)器的總體結(jié)構(gòu)。研究人員開始著眼于改善這些網(wǎng)絡(luò)的每個(gè)單獨(dú)部分。特征金字塔網(wǎng)絡(luò)是利用不同層次的特征構(gòu)成特征金字塔,從而改進(jìn)檢測(cè)頭的一種嘗試。這種特征金字塔的想法在計(jì)算機(jī)視覺研究中并不新奇。當(dāng)特征還是手工設(shè)計(jì)的時(shí)候,特征金字塔已經(jīng)是識(shí)別不同尺度模式的一種非常有效的方法。在深度學(xué)習(xí)中使用特征金字塔也不是一個(gè)新的想法: SSPNet、 FCN 和 SSD 都證明了在分類之前聚合多層特征的好處。然而,如何在 RPN 和基于區(qū)域的檢測(cè)器之間共享特征金字塔仍然有待于確認(rèn)。
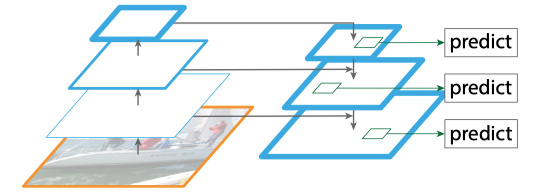
源自論文 “Feature Pyramid Networks for Object Detection”
首先,為了使用如上圖所示的 FPN 結(jié)構(gòu)重新構(gòu)建 RPN,我們需要有一個(gè)在多個(gè)不同尺度的特征輸出上運(yùn)行的region proposal。此外,我們現(xiàn)在每個(gè)位置只需要3個(gè)不同長(zhǎng)寬比的anchors,因?yàn)椴煌笮〉奈矬w將由不同層次的特征金字塔處理。接下來(lái),為了在 Fast R-CNN 檢測(cè)器中使用 FPN 結(jié)構(gòu),我們還需要對(duì)其進(jìn)行改造,以便在多種尺度的特征圖上進(jìn)行檢測(cè)。由于region proposals也可能有不同的尺度,我們也應(yīng)該在 FPN 的相應(yīng)層級(jí)上使用它們。簡(jiǎn)而言之,如果Faster R-CNN 是一對(duì)運(yùn)行在一個(gè)尺度上的 RPN 和基于區(qū)域的檢測(cè)器,F(xiàn)PN 將其轉(zhuǎn)換成在不同尺度上運(yùn)行的多個(gè)并行分支,并最終從所有分支中收集最終結(jié)果。
2016: YOLO v2
YOLO9000: 更好,更快,更強(qiáng)
當(dāng)何凱明、Ross Girshick和他們的團(tuán)隊(duì)不斷改進(jìn)他們的兩階段 R-CNN 探測(cè)器時(shí),另一邊,約Joseph Redmon也在忙于改進(jìn)他的單階段 YOLO 檢測(cè)器。最初版本的 YOLO 存在許多缺點(diǎn): 基于粗網(wǎng)格的預(yù)測(cè)帶來(lái)了較低的定位精度,每個(gè)網(wǎng)格單元有兩個(gè)尺度不確定的回歸器也使得識(shí)別小目標(biāo)變得困難。幸運(yùn)的是,2015年我們?cè)谠S多計(jì)算機(jī)視覺領(lǐng)域看到了太多偉大的創(chuàng)新。YOLO v2只是需要找到一種方法來(lái)整合它們,使它們變得更好、更快、更強(qiáng)。以下是修改的一些亮點(diǎn):
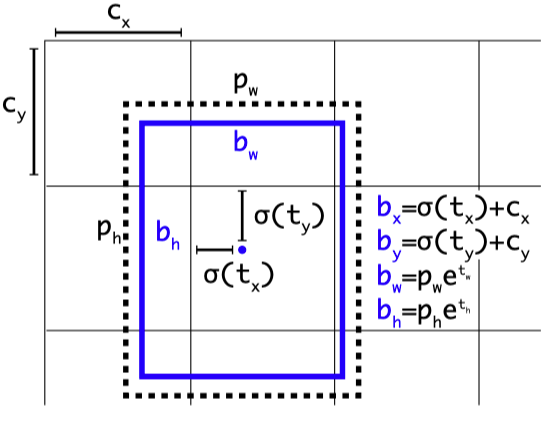
Anchor boxes,源自論文“YOLO9000: Better, Faster, Stronger”
注意,YOLO v2還試驗(yàn)了一個(gè)版本,該版本在9000個(gè)類的分層數(shù)據(jù)集上訓(xùn)練,這也代表了目標(biāo)檢測(cè)器中多標(biāo)簽分類的早期試驗(yàn)。
2017: RetinaNet
針對(duì)密集目標(biāo)檢測(cè)的Focal Loss
為了理解為什么單階段檢測(cè)器通常不如兩階段檢測(cè)器好,RetinaNet 研究了單階段檢測(cè)器密集預(yù)測(cè)的前景-背景類不均衡問題。以 YOLO 為例,它試圖同時(shí)預(yù)測(cè)所有可能位置的類和邊界框,因此在訓(xùn)練過(guò)程中大多數(shù)輸出與負(fù)類相匹配。SSD 通過(guò) hard example mining解決了這個(gè)問題。在訓(xùn)練的早期階段,YOLO 使用objectiveness評(píng)分隱式訓(xùn)練前景分類器。RetinaNet認(rèn)為他們都沒有找到解決問題的關(guān)鍵,所以它發(fā)明了一種新的損失函數(shù),稱為Focal Loss,以幫助網(wǎng)絡(luò)學(xué)習(xí)什么是真正重要的。
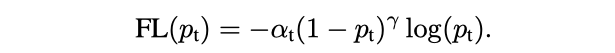
源自論文“Focal Loss for Dense Object Detection”
Focal Loss 增加了一個(gè)指數(shù) γ (他們稱之為聚焦參數(shù))的交叉熵?fù)p失。自然,隨著置信度分?jǐn)?shù)的增加,損失值會(huì)比正常的交叉熵值低得多。參數(shù) α 用于平衡這種聚焦效應(yīng)。
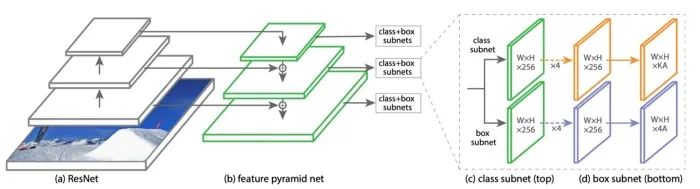
源自論文“Focal Loss for Dense Object Detection”
這個(gè)想法很簡(jiǎn)單,即使是小學(xué)生也能理解。為了進(jìn)一步證明他們的工作,他們調(diào)整了之前提出的 FPN 模型,并創(chuàng)建了一個(gè)新的單階段檢測(cè)器,稱為 RetinaNet。它由 ResNet 主干網(wǎng)、不同尺度信道特征的 FPN 檢測(cè)頸、作為檢測(cè)頭的分類子網(wǎng)和框回歸子網(wǎng)組成。類似于 SSD 和 YOLO v3,RetinaNet 使用anchor boxes 覆蓋不同尺度和長(zhǎng)寬比的目標(biāo)。
稍微離題一下,RetinaNet 使用了 ResNeXT-101和800輸入分辨率的 COCO 精確度來(lái)對(duì)比 YOLO v2,而YOLO v2只有一個(gè)輕量的 Darknet-19主干和448輸入分辨率。這種不真誠(chéng)表明團(tuán)隊(duì)強(qiáng)調(diào)獲得的更好的基準(zhǔn)測(cè)試結(jié)果,而不是解決像速度準(zhǔn)確性 trade-off這樣的實(shí)際問題。這可能是 RetinaNet 發(fā)布后沒有起飛的部分原因。
2018: YOLO v3
YOLOv3: 漸進(jìn)式改進(jìn)
YOLO v3 是官方 YOLO 系列的最后一個(gè)版本。遵循 YOLO v2的傳統(tǒng),YOLO v3從以前的研究中借鑒了更多的想法,并且得到了一個(gè)難以置信的像怪物一樣強(qiáng)大的單階段檢測(cè)器。YOLO v3很好地平衡了速度、準(zhǔn)確率和實(shí)現(xiàn)的復(fù)雜性。由于它的快速和簡(jiǎn)單的組件,它在行業(yè)中非常受歡迎。
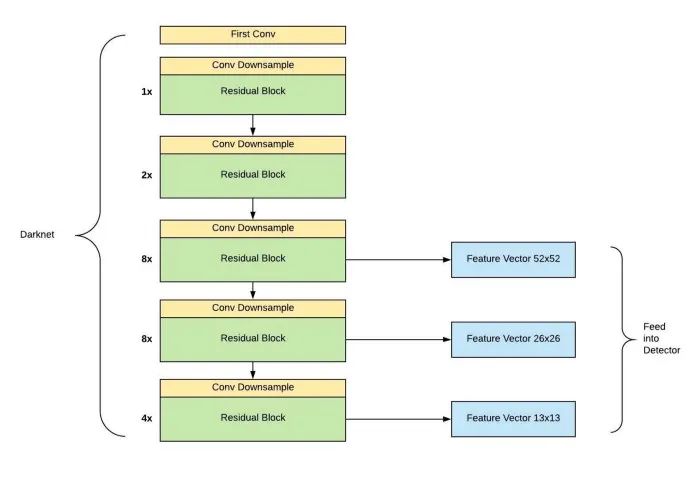
源自論文“Dive Really Deep into YOLO v3: A Beginner’s Guide”
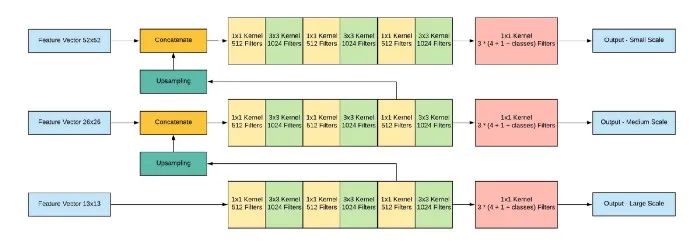
源自論文“Dive Really Deep into YOLO v3: A Beginner’s Guide”
簡(jiǎn)單地說(shuō),YOLO v3的成功來(lái)自于它更強(qiáng)大的主干功能提取器和帶有 FPN 頸部的類似 RetinaNet 的檢測(cè)頭。新的主干網(wǎng)絡(luò) Darknet-53利用了 ResNet 的skip連接,以達(dá)到與 ResNet-50相當(dāng)?shù)臏?zhǔn)確度,但速度要快得多。此外,YOLO v3拋棄了 v2的pass through層,完全采用 FPN 的多尺度預(yù)測(cè)設(shè)計(jì)。從那時(shí)起,YOLO v3終于扭轉(zhuǎn)了人們對(duì)它在處理小目標(biāo)時(shí)表現(xiàn)不佳的印象。
此外,關(guān)于 YOLO v3還有一些有趣的事實(shí)。它diss了 COCO mAP 0.5:0.95度量標(biāo)準(zhǔn),證明了條件密集預(yù)測(cè)時(shí)Focal Loss沒啥用。一年后作者Joseph甚至決定放棄整個(gè)計(jì)算機(jī)視覺研究,因?yàn)樗麚?dān)心會(huì)用到軍事上。
2019: Objects As Points
盡管近年來(lái)圖像分類領(lǐng)域變得不那么活躍,但目標(biāo)檢測(cè)的研究還遠(yuǎn)未成熟。2018年,一篇名為“CornerNet: Detecting Objects as Paired Keypoints””的論文為檢測(cè)器訓(xùn)練提供了一個(gè)新的視角。由于準(zhǔn)備anchor box目標(biāo)是一個(gè)相當(dāng)繁瑣的工作,是否真的有必要使用他們作為先決條件?這種拋棄 anchor boxes的新趨勢(shì)被稱為“anchor-free”目標(biāo)檢測(cè)。

源自論文“Stacked Hourglass Networks for Human Pose Estimation”
受Hourglass網(wǎng)絡(luò)中熱圖用于人體姿態(tài)估計(jì)的啟發(fā),CornerNet 使用框角生成的熱圖來(lái)監(jiān)督邊界框回歸。

源自論文“Objects as Points”
Objects As Points,又名 CenterNet,更進(jìn)了一步。它使用熱圖峰值來(lái)表示物體中心,網(wǎng)絡(luò)將直接從這些框中心回歸框的寬度和高度。實(shí)際上,CenterNet 使用每個(gè)像素作為網(wǎng)格單元。使用高斯分布的熱圖,與之前直接回歸邊界框大小的嘗試相比,訓(xùn)練也比較容易收斂。
消除anchor boxes還有另一個(gè)有用的副作用。以前,我們依賴anchor boxe和ground truth框之間的IOU(如 > 0.7)來(lái)分配訓(xùn)練目標(biāo)。這樣一些相鄰的anchors都被分配了同一個(gè)目標(biāo)的正目標(biāo)。網(wǎng)絡(luò)也將學(xué)會(huì)為同一個(gè)物體預(yù)測(cè)多個(gè)正框。解決這個(gè)問題的常用方法是使用一種稱為非極大值抑制(Non-maximum Suppression,NMS)的技術(shù)。這是一個(gè)貪婪算法,過(guò)濾掉太靠近的框。現(xiàn)在anchors消失了,我們?cè)跓釄D中每個(gè)目標(biāo)只有一個(gè)峰值,不再需要使用 NMS 了。由于 NMS 有時(shí)難以實(shí)現(xiàn)且運(yùn)行緩慢,因此對(duì)于在資源有限的各種環(huán)境中運(yùn)行的應(yīng)用程序來(lái)說(shuō),擺脫 NMS 是一個(gè)很大的好處。
2019: EfficientDet
EfficientDet: 可擴(kuò)展和高效的目標(biāo)檢測(cè)
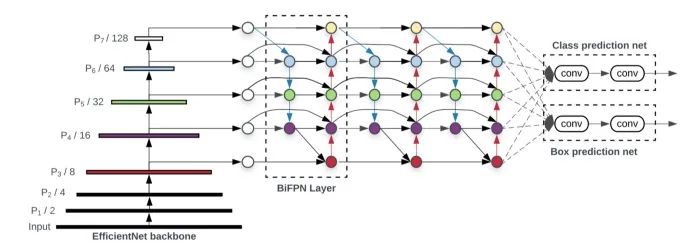
源自論文“EfficientDet: Scalable and Efficient Object Detection”
在最近的 CVPR’20中,EfficientDet 向我們展示了目標(biāo)檢測(cè)領(lǐng)域更令人興奮的發(fā)展。FPN 結(jié)構(gòu)已被證明是提高檢測(cè)網(wǎng)絡(luò)在不同尺度下對(duì)目標(biāo)檢測(cè)性能的有力技術(shù)。著名的檢測(cè)網(wǎng)絡(luò),如 RetinaNet 和 YOLO v3,在框回歸和分類之前都采用了 FPN 頸。后來(lái),NAS-FPN 和 PANet (請(qǐng)參閱閱讀更多部分)都證明了一個(gè)普通的多層 FPN 結(jié)構(gòu)可能會(huì)受益于更多的設(shè)計(jì)優(yōu)化。EfficientDet繼續(xù)朝這個(gè)方向探索,最終創(chuàng)造了一個(gè)新的脖,叫做 BiFPN。基本上,BiFPN 提供了額外的跨層連接,以鼓勵(lì)來(lái)回的特性聚合。為了證明網(wǎng)絡(luò)的效率,BiFPN 從原始的PANet設(shè)計(jì)中刪除了一些不太有用的連接。FPN 結(jié)構(gòu)上的另一個(gè)創(chuàng)新改進(jìn)是權(quán)重特征融合。BiFPN 增加了額外的可學(xué)習(xí)的權(quán)重來(lái)實(shí)現(xiàn)聚合,這樣網(wǎng)絡(luò)就可以學(xué)習(xí)不同分支的重要性。
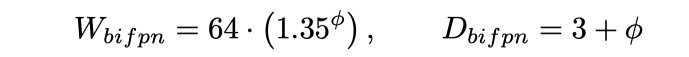
源自論文“EfficientDet: Scalable and Efficient Object Detection”
此外,就像我們?cè)趫D像分類網(wǎng)絡(luò) EfficientNet 中看到的一樣,EfficientDet 也引入了一種合理的方法來(lái)縮放目標(biāo)檢測(cè)網(wǎng)絡(luò)。上述公式中的參數(shù)φ 同時(shí)控制了 BiFPN 頸部和檢測(cè)頭的寬度(通道)和深度(層)。
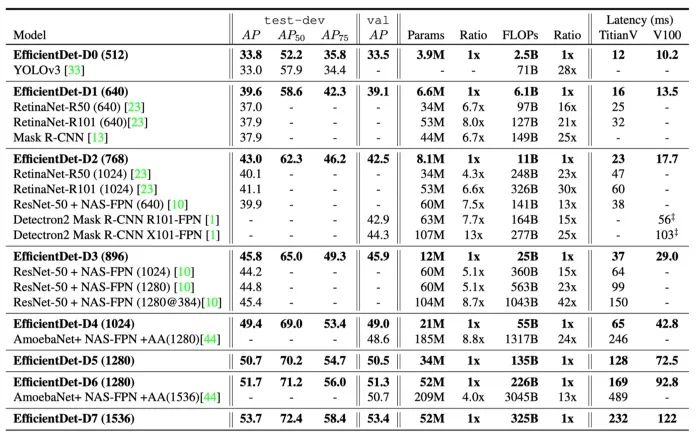
源自論文“EfficientDet: Scalable and Efficient Object Detection”
這個(gè)新參數(shù)產(chǎn)生了8個(gè)不同的 EfficientDet 變種,從 D0到 D7。一個(gè)輕量級(jí)的 D0變種可以達(dá)到與 YOLO v3相似的精度,而FLOPs更少。一個(gè)重型的 D7變種,加上可怕的1536x1536輸入,甚至在 COCO 上可以達(dá)到53.7 AP ,使所有其他競(jìng)爭(zhēng)者相形見絀。
閱讀更多
從 R-CNN、 YOLO 到最近的 CenterNet 和 EfficientDet,我們見證了深度學(xué)習(xí)時(shí)代目標(biāo)檢測(cè)研究領(lǐng)域最重大的創(chuàng)新。除了上面的論文,我還提供了一個(gè)附加論文的列表,你可以繼續(xù)閱讀,以獲得更深入的理解。他們或者為目標(biāo)檢測(cè)提供了不同的視角,或者用更強(qiáng)大的功能擴(kuò)展了這個(gè)領(lǐng)域。
2009: DPM
基于分離部分訓(xùn)練的目標(biāo)檢測(cè)模型
通過(guò)為每個(gè)可變形的部件匹配很多 HOG 特征,DPM 是深度學(xué)習(xí)時(shí)代之前最有效的目標(biāo)檢測(cè)模型之一。以行人檢測(cè)為例,首先采用星型結(jié)構(gòu)識(shí)別通用人模式,然后用不同的子濾波器識(shí)別各部分并計(jì)算總分。即使在今天,在我們從 HOG 特征轉(zhuǎn)換到 CNN 特征之后,通過(guò)各個(gè)可變形部件來(lái)識(shí)別目標(biāo)的想法仍然很流行。
2012: Selective Search
物體識(shí)別的Selective Search
和 DPM 一樣,Selective Search 也不是深度學(xué)習(xí)時(shí)代的產(chǎn)物。然而,這種方法將許多經(jīng)典的計(jì)算機(jī)視覺方法結(jié)合在一起,也用于早期的 R-CNN 檢測(cè)器。selective search的核心思想來(lái)自于語(yǔ)義分割,即通過(guò)相似度對(duì)像素進(jìn)行分組。selective search使用不同的相似度標(biāo)準(zhǔn),如顏色空間和基于 SIFT 的紋理來(lái)迭代合并相似的區(qū)域在一起。這些合并后的區(qū)域用作前景預(yù)測(cè),然后用支持向量機(jī)分類器進(jìn)行目標(biāo)識(shí)別。
2016: R-FCN
R-FCN: 通過(guò)基于區(qū)域的全卷積網(wǎng)絡(luò)實(shí)現(xiàn)目標(biāo)檢測(cè)
Faster R-CNN 最終結(jié)合了 RPN 和 ROI 特征提取,大大提高了速度。然而,對(duì)于每個(gè)region proposal,我們?nèi)匀恍枰B接層來(lái)分別計(jì)算類和邊界框。如果有300個(gè) ROIs,我們需要重復(fù)300次,這也是單階段和兩階段檢測(cè)器之間速度差異的主要原因。R-FCN 借鑒了 FCN 語(yǔ)義分割的思想,但是 R-FCN 沒有計(jì)算類掩碼,而是計(jì)算了一個(gè)正敏感的得分圖。這張圖將預(yù)測(cè)物體在每個(gè)位置出現(xiàn)的概率,并且所有位置將投票(平均)來(lái)決定最終的類和邊界框。此外,R-FCN 還在其 ResNet 主干中使用了 atrous 卷積,這種卷積最初是在 DeepLab 語(yǔ)義分割網(wǎng)絡(luò)中提出的。
2017: Soft-NMS
用一行代碼改進(jìn)目標(biāo)檢測(cè)
非極大值抑制(NMS)被廣泛應(yīng)用于基于anchor的目標(biāo)檢測(cè)網(wǎng)絡(luò)中,以減少附近的重復(fù)正proposals。更具體的說(shuō),候選框在和一個(gè)有更有置信度的候選框 IOU高于閾值時(shí),NMS 會(huì)迭代消除這個(gè)框。當(dāng)具有相同類的兩個(gè)目標(biāo)確實(shí)彼此非常接近時(shí),這可能會(huì)導(dǎo)致一些意外的行為。Soft-NMS 對(duì)重疊候選框的置信度通過(guò)一個(gè)參數(shù)進(jìn)行了小幅度的調(diào)整。這個(gè)縮放參數(shù)在調(diào)整定位性能時(shí)提供了更多的控制,并且在需要高召回率時(shí)有更高的精度。
2017: Cascade R-CNN
Cascade R-CNN: 探索高質(zhì)量的目標(biāo)檢測(cè)
當(dāng) FPN 探索如何設(shè)計(jì)一個(gè)更好的 R-CNN 頸部來(lái)使用主干特征時(shí),Cascade R-CNN 研究并重新設(shè)計(jì)了 R-CNN 分類和回歸頭。底層的假設(shè)是簡(jiǎn)單而深刻的: 我們?cè)跍?zhǔn)備正的目標(biāo)時(shí)使用的IOU值越高,網(wǎng)絡(luò)學(xué)會(huì)做出的false positive的預(yù)測(cè)就越少。然而,我們不能簡(jiǎn)單地將IOU閾值從常用的0.5提高到更具侵略性的0.7,因?yàn)檫@也可能導(dǎo)致過(guò)多的負(fù)樣本出現(xiàn)在訓(xùn)練中。Cascade R-CNN的解決方案是將多個(gè)檢測(cè)頭鏈接在一起,每個(gè)檢測(cè)頭都將依賴于前一個(gè)檢測(cè)頭的邊界框proposals。只有第一個(gè)檢測(cè)頭使用原來(lái)的 RPN proposals。這樣后面的頭便有效的模擬了 IOU 閾值的增加。
2017: Mask R-CNN
Mask R-CNN
Mask R-CNN并不是一個(gè)典型的目標(biāo)檢測(cè)網(wǎng)絡(luò)。它被設(shè)計(jì)來(lái)解決一個(gè)具有挑戰(zhàn)性的實(shí)例分割任務(wù),即為場(chǎng)景中的每個(gè)對(duì)象創(chuàng)建一個(gè)掩碼。然而,Mask R-CNN 展示了對(duì) Faster R-CNN 框架的一個(gè)很好的擴(kuò)展,反過(guò)來(lái)也激發(fā)了目標(biāo)檢測(cè)的研究。其主要思想是在已有的邊界框和分類分支的基礎(chǔ)上,在 ROI pooling之后增加一個(gè)二進(jìn)制掩碼預(yù)測(cè)分支。此外,為了解決原始的 ROI Pooling 層的圖像量化誤差問題,Mask R-CNN 還提出了一個(gè)新的 ROI Align 層,該層實(shí)際上使用了雙線性圖像重采樣。如你所料,多任務(wù)訓(xùn)練(分割 + 檢測(cè))和新的 ROI Align 層都有助于改進(jìn)邊界框benchmark。
2018: PANet
用于實(shí)例分割的路徑聚合網(wǎng)絡(luò)
實(shí)例分割與目標(biāo)檢測(cè)有著密切的關(guān)系,因此一個(gè)新的實(shí)例分割網(wǎng)絡(luò)通常也可以間接地為目標(biāo)檢測(cè)分析研究帶來(lái)好處。PANet 旨在通過(guò)在原有的自上而下路徑之后增加一個(gè)自下而上的路徑,來(lái)促進(jìn) Mask R-CNN 的 FPN 頸部的信息流。可視化這種變化就是,在多層池化特征之前,我們?cè)谠瓉?lái)的 FPN 的脖子上有一個(gè)↑↑結(jié)構(gòu),而 PANet 使它更像一個(gè)↑↓↑ 結(jié)構(gòu)。同時(shí),在 Mask R-CNN 的 ROIAlign 融合 (逐元素最大值的和)多尺度特性之后,PANet 增加了一個(gè)“自適應(yīng)特性池化”層,而不是每個(gè)特性層都有單獨(dú)的池化。
2019: NAS-FPN
NAS-FPN: 學(xué)習(xí)可擴(kuò)展特征金字塔結(jié)構(gòu)的目標(biāo)檢測(cè)
PANet的成功引起了一組 NAS 研究人員的注意。他們使用了來(lái)自圖像分類網(wǎng)絡(luò) NASNet 的類似的強(qiáng)化學(xué)習(xí)方法,重點(diǎn)搜索融合單元的最佳組合。這里,融合單元是指 FPN 的基礎(chǔ)構(gòu)建塊,它將任意兩個(gè)輸入特征層融合到一個(gè)輸出特征層中。最終的結(jié)果證明了 FPN 可以進(jìn)一步優(yōu)化的想法,但是復(fù)雜的計(jì)算機(jī)搜索結(jié)構(gòu)使人類難以理解。
總結(jié)
目標(biāo)檢測(cè)仍然是一個(gè)活躍的研究領(lǐng)域。雖然這個(gè)領(lǐng)域總體是由 R-CNN 這樣的兩級(jí)檢測(cè)器和 YOLO 這樣的單級(jí)檢測(cè)器構(gòu)成的,但是我們最好的檢測(cè)器仍然遠(yuǎn)遠(yuǎn)沒有在基準(zhǔn)度量上飽和,而且在復(fù)雜的背景中漏掉了許多目標(biāo)。與此同時(shí),像 CenterNet 這樣的anchor-free檢測(cè)器向我們展示了一個(gè)光明的未來(lái),在那里目標(biāo)檢測(cè)網(wǎng)絡(luò)可以變得像圖像分類網(wǎng)絡(luò)一樣簡(jiǎn)單。目標(biāo)檢測(cè)的其他發(fā)展方向,如 few-shot 識(shí)和 NAS,仍處于初級(jí)階段,我們將在未來(lái)幾年內(nèi)看到它的發(fā)展。
References
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~