
(附論文&代碼)一文看盡 27 篇 CVPR2021 2D 目標(biāo)檢測(cè)論文
點(diǎn)擊左上方藍(lán)字關(guān)注我們

6月25日,CVPR 2021 大會(huì)圓滿(mǎn)結(jié)束,隨著 CVPR 2021 最佳論文的出爐,本次大會(huì)所接收的論文也全部放出。CVPR2021 共接收了 7039 篇有效投稿,其中進(jìn)入 Decision Making 階段的共有約 5900 篇,最終有 1366 篇被接收為 poster,295 篇被接收為 oral,其中錄用率大致為 23.6%,略高于去年的 22.1%。
CVPR 2021 全部接收論文列表:
https://openaccess.thecvf.com/CVPR2021?day=all
從 CVPR2021 公布結(jié)果開(kāi)始,極市就一直對(duì)最新的 CVPR2021 進(jìn)行分類(lèi)匯總,共分為33個(gè)大類(lèi),包含檢測(cè)、分割、估計(jì)、跟蹤、醫(yī)學(xué)影像、文本、人臉、圖像視頻檢索、三維視覺(jué)、圖像處理等多個(gè)方向。所有關(guān)于CVPR的論文整理都匯總在了我們的Github項(xiàng)目中,該項(xiàng)目目前已收獲7200 Star。
Github項(xiàng)目地址:
https://github.com/extreme-assistant/CVPR2021-Paper-Code-Interpretation
在本文中,我們首先會(huì)對(duì)我們匯總的 CVPR 2021 檢測(cè)大類(lèi)中的2D目標(biāo)檢測(cè)領(lǐng)域的論文進(jìn)行盤(pán)點(diǎn),將依次闡述每篇論文的方法思路和亮點(diǎn)。接下來(lái)還會(huì)繼續(xù)進(jìn)行其他領(lǐng)域的 CVPR2021 論文盤(pán)點(diǎn)。如有遺漏或錯(cuò)誤,歡迎大家在評(píng)論區(qū)補(bǔ)充指正。

論文一
UP-DETR: Unsupervised Pre-training for Object Detection with Transformers(Oral)
標(biāo)題:針對(duì)目標(biāo)檢測(cè)的無(wú)監(jiān)督預(yù)訓(xùn)練Transformer
論文:https://arxiv.org/pdf/2011.09094.pdf
代碼:https://github.com/dddzg/up-detr
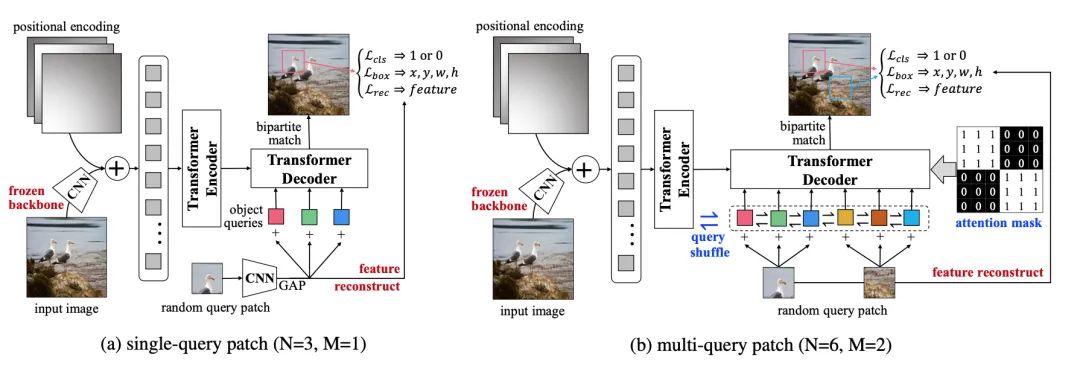
利用Transformer做目標(biāo)檢測(cè),DETR通過(guò)直截了當(dāng)?shù)木幗獯a器架構(gòu),取得了引人注目的性能。受自然語(yǔ)言處理中預(yù)訓(xùn)練transformer語(yǔ)言模型的影響,本文提出了一個(gè)適用于目標(biāo)檢測(cè)的無(wú)監(jiān)督預(yù)訓(xùn)練任務(wù)。具體而言,給定圖片,我們隨機(jī)的從其中裁剪下多個(gè)小補(bǔ)丁塊輸入解碼器,將原來(lái)輸入編碼器,預(yù)訓(xùn)練任務(wù)要求模型從原圖中找到隨機(jī)裁剪的補(bǔ)丁塊。在這個(gè)過(guò)程中,我們發(fā)現(xiàn)并解決了兩個(gè)關(guān)鍵的問(wèn)題:多任務(wù)學(xué)習(xí)和多個(gè)補(bǔ)丁塊的定位。
(1)為了權(quán)衡預(yù)訓(xùn)練過(guò)程中,檢測(cè)器對(duì)于分類(lèi)和定位特征的偏好,我們固定了預(yù)訓(xùn)練的CNN特征并添加了一個(gè)特征重構(gòu)的分支。
(2)為了同時(shí)支持多補(bǔ)丁定位,我們提出了注意力掩碼和洗牌的機(jī)制。實(shí)驗(yàn)中,無(wú)監(jiān)督預(yù)訓(xùn)練可以顯著提升DETR在下游VOC和COCO上目標(biāo)檢測(cè)的性能。
在今年4月,我們也邀請(qǐng)到了UP-DETR的論文一作戴志港來(lái)參加極市舉辦的主題為CVPR2021論文研討會(huì)的線(xiàn)下沙龍,詳細(xì)報(bào)告以及視頻回放可以戳:極市沙龍回顧|CVPR2021-戴志港:UP-DETR,針對(duì)目標(biāo)檢測(cè)的無(wú)監(jiān)督預(yù)訓(xùn)練Transformer。
論文二
Towards Open World Object Detection(Oral)
標(biāo)題:開(kāi)放世界中的目標(biāo)檢測(cè)
論文:https://arxiv.org/abs/2103.02603
代碼:https://github.com/JosephKJ/OWOD
詳細(xì)解讀:目標(biāo)檢測(cè)一卷到底之后,終于有人為它挖了個(gè)新坑|CVPR2021 Oral
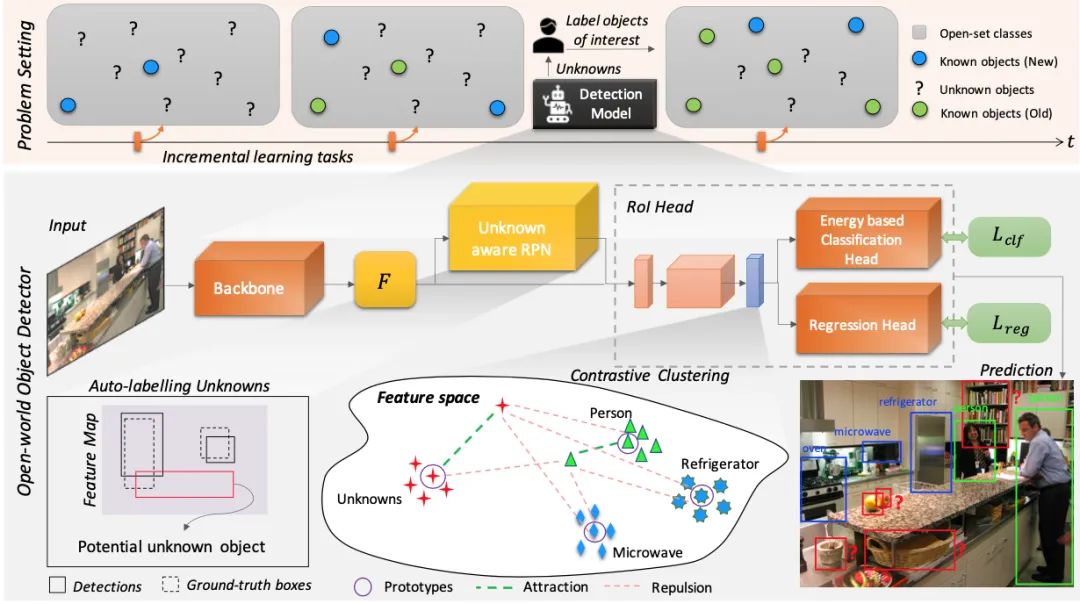
雖然目標(biāo)檢測(cè)技術(shù)目前已經(jīng)發(fā)展得較為成熟,但如果要真正能實(shí)現(xiàn)讓計(jì)算機(jī)像人眼一樣進(jìn)行識(shí)別,有項(xiàng)功能一直尚未達(dá)成——那就是像人一樣能識(shí)別現(xiàn)實(shí)世界中的所有物體,并且能夠逐漸學(xué)習(xí)認(rèn)知新的未知物體。來(lái)本文發(fā)現(xiàn)并解決了這個(gè)問(wèn)題。提出了一種新穎的方案:Open World Object Detector,簡(jiǎn)稱(chēng)ORE,即開(kāi)放世界的目標(biāo)檢測(cè)。
ORE主要包含兩個(gè)任務(wù):
Open Set Learning,即在沒(méi)有明確監(jiān)督的情況下,將尚未引入的目標(biāo)識(shí)別為“未知”; Incremental Learning,即讓網(wǎng)絡(luò)進(jìn)行N+1式增量學(xué)習(xí),接收相應(yīng)標(biāo)簽以學(xué)習(xí)其識(shí)別到的未知類(lèi)別,同時(shí)不會(huì)忘記之前已經(jīng)學(xué)到的類(lèi)別。
論文三
You Only Look One-level Feature
標(biāo)題:你只需要看一層特征
論文:https://arxiv.org/abs/2103.09460
代碼:https://github.com/megvii-model/YOLOF
詳細(xì)解讀:我扔掉FPN來(lái)做目標(biāo)檢測(cè),效果竟然這么強(qiáng)!YOLOF開(kāi)源:你只需要看一層特征
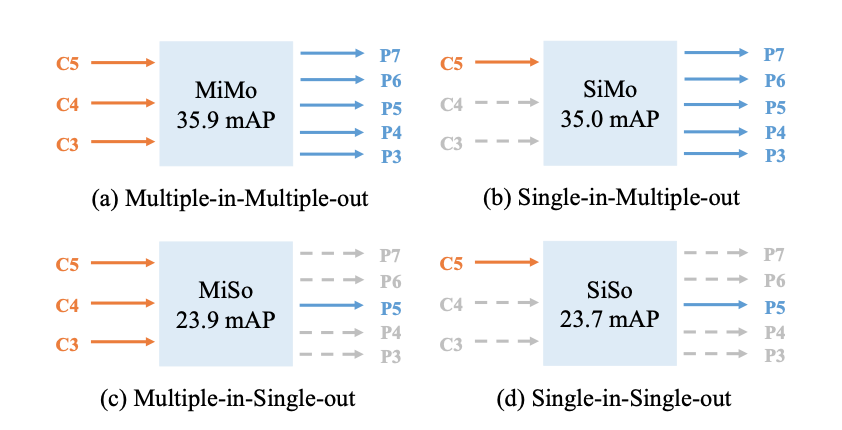
本文對(duì)單階段目標(biāo)檢測(cè)中的FPN進(jìn)行了重思考并指出FPN的成功之處在于它對(duì)目標(biāo)檢測(cè)優(yōu)化問(wèn)題的分而治之解決思路而非多尺度特征融合。從優(yōu)化的角度出發(fā),作者引入了另一種方式替換復(fù)雜的特征金字塔來(lái)解決該優(yōu)化問(wèn)題:從而可以?xún)H僅采用一級(jí)特征進(jìn)行檢測(cè)。基于所提簡(jiǎn)單而有效的解決方案,作者提出了YOLOF(You Only Look One-level Feature)。
YOLOF有兩個(gè)關(guān)鍵性模塊:Dilated Encoder與Uniform Matching,它們對(duì)最終的檢測(cè)帶來(lái)了顯著的性能提升。COCO基準(zhǔn)數(shù)據(jù)集的實(shí)驗(yàn)表明了所提YOLOF的有效性,YOLOF取得與RetinaNet-FPN同等的性能,同時(shí)快2.5倍;無(wú)需transformer層,YOLOF僅需一級(jí)特征即可取得與DETR相當(dāng)?shù)男阅埽瑫r(shí)訓(xùn)練時(shí)間少7倍。以大小的圖像作為輸入,YOLOF取得了44.3mAP的指標(biāo)且推理速度為60fps@2080Ti,它比YOLOv4快13%。
本文的貢獻(xiàn)主要包含以下幾點(diǎn):
FPN的關(guān)鍵在于針對(duì)稠密目標(biāo)檢測(cè)優(yōu)化問(wèn)題的“分而治之”解決思路,而非多尺度特征融合; 提出了一種簡(jiǎn)單而有效的無(wú)FPN的基線(xiàn)模型YOLOF,它包含兩個(gè)關(guān)鍵成分(Dilated Encoder與Uniform Matching)以減輕與FPN的性能差異; COCO數(shù)據(jù)集上的實(shí)驗(yàn)證明了所提方法每個(gè)成分的重要性,相比RetinaNet,DETR以及YOLOv4,所提方法取得相當(dāng)?shù)男阅芡瑫r(shí)具有更快的推理速度。
論文四
End-to-End Object Detection with Fully Convolutional Network
標(biāo)題:使用全卷積網(wǎng)絡(luò)進(jìn)行端到端目標(biāo)檢測(cè)
論文:https://arxiv.org/abs/2012.03544
代碼:https://github.com/Megvii-BaseDetection/DeFCN
詳細(xì)解讀:丟棄Transformer,F(xiàn)CN也可以實(shí)現(xiàn)E2E檢測(cè)
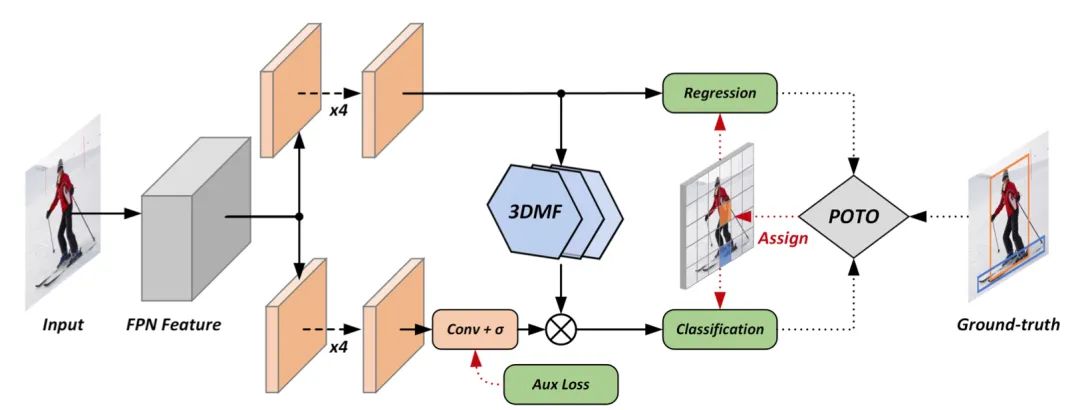
本文基于FCOS,首次在密集預(yù)測(cè)上利用全卷積結(jié)構(gòu)做到E2E,即無(wú)NMS后處理。論文首先分析了常見(jiàn)的密集預(yù)測(cè)方法(如RetinaNet、FCOS、ATSS等),并且認(rèn)為one-to-many的label assignment是依賴(lài)NMS的關(guān)鍵。受到DETR的啟發(fā),作者設(shè)計(jì)了一種prediction-aware one-to-one assignment方法。此外,還提出了3D Max Filtering以增強(qiáng)feature在local區(qū)域的表征能力,并提出用one-to-many auxiliary loss加速收斂。
本文方法基本不修改模型結(jié)構(gòu),不需要更長(zhǎng)的訓(xùn)練時(shí)間,可以基于現(xiàn)有密集預(yù)測(cè)方法平滑過(guò)渡。在無(wú)NMS的情況下,在COCO數(shù)據(jù)集上達(dá)到了與有NMS的FCOS相當(dāng)?shù)男阅埽辉诖砹嗣芗瘓?chǎng)景的CrowdHuman數(shù)據(jù)集上,論文方法的recall超越了依賴(lài)NMS方法的理論上限。
論文五
Generalized Focal Loss V2: Learning Reliable Localization Quality Estimation for Dense Object Detection
標(biāo)題:學(xué)習(xí)可靠的定位質(zhì)量估計(jì)用于密集目標(biāo)檢測(cè)
論文:https://arxiv.org/abs/2011.12885
代碼:https://github.com/implus/GFocalV2
詳細(xì)解讀:大白話(huà) Generalized Focal Loss V2,https://zhuanlan.zhihu.com/p/313684358
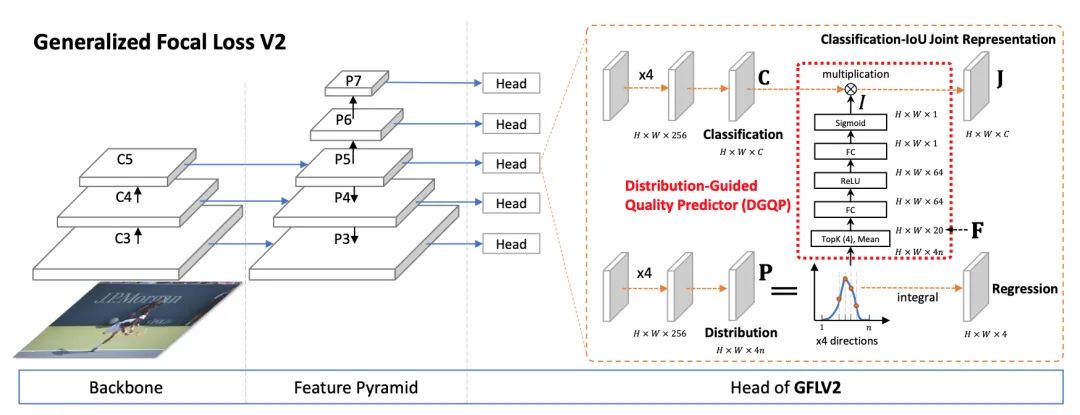
本文應(yīng)該是檢測(cè)領(lǐng)域首次引入用邊界框的不確定性的統(tǒng)計(jì)量來(lái)高效地指導(dǎo)定位質(zhì)量估計(jì),從而基本無(wú)cost(包括在訓(xùn)練和測(cè)試階段)地提升one-stage的檢測(cè)器性能,漲幅在1~2個(gè)點(diǎn)AP。
論文六
Positive-Unlabeled Data Purification in the Wild for Object Detection
標(biāo)題:野外目標(biāo)檢測(cè)的正無(wú)標(biāo)注數(shù)據(jù)清洗
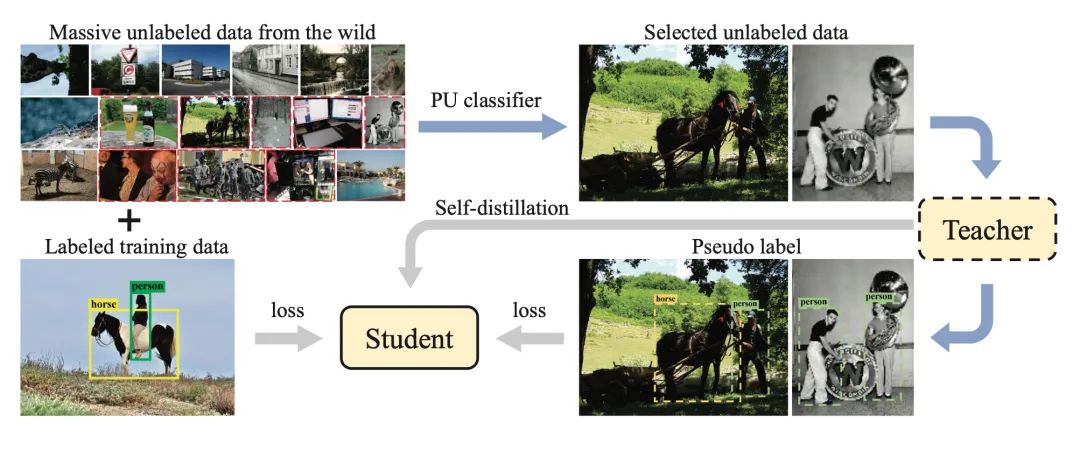
得益于大量標(biāo)注圖像,基于深度學(xué)習(xí)的目標(biāo)檢測(cè)方法取得了很大進(jìn)展。然而,圖像標(biāo)注仍然是一個(gè)費(fèi)力、耗時(shí)且容易出錯(cuò)的過(guò)程。為了進(jìn)一步提高檢測(cè)器的性能,本文尋求利用所有可用的標(biāo)注數(shù)據(jù)并從野外的大量未標(biāo)注圖像中挖掘有用的樣本,這在以前很少討論。
本文提出了一種基于正未標(biāo)注學(xué)習(xí)的方案,通過(guò)從大量未標(biāo)注的圖像中提純有價(jià)值的圖像來(lái)擴(kuò)展訓(xùn)練數(shù)據(jù),其中原始訓(xùn)練數(shù)據(jù)被視為正數(shù)據(jù),而野外未標(biāo)記的圖像是未標(biāo)記數(shù)據(jù)。為了有效地提純這些數(shù)據(jù),提出了一種基于提示學(xué)習(xí)和真實(shí)值有界知識(shí)蒸餾的自蒸餾算法。實(shí)驗(yàn)結(jié)果驗(yàn)證了所提出的正未標(biāo)注數(shù)據(jù)提純可以通過(guò)挖掘海量未標(biāo)注數(shù)據(jù)來(lái)增強(qiáng)原始檢測(cè)器。本文方法在 COCO 基準(zhǔn)上將FPN 的 mAP 提高了 2.0%。
論文七
Multiple Instance Active Learning for Object Detection
標(biāo)題:用于目標(biāo)檢測(cè)的多實(shí)例主動(dòng)學(xué)習(xí)
代碼:https://github.com/yuantn/MI-AOD
詳細(xì)解讀:MI-AOD: 少量樣本實(shí)現(xiàn)高檢測(cè)性能,https://zhuanlan.zhihu.com/p/362764637
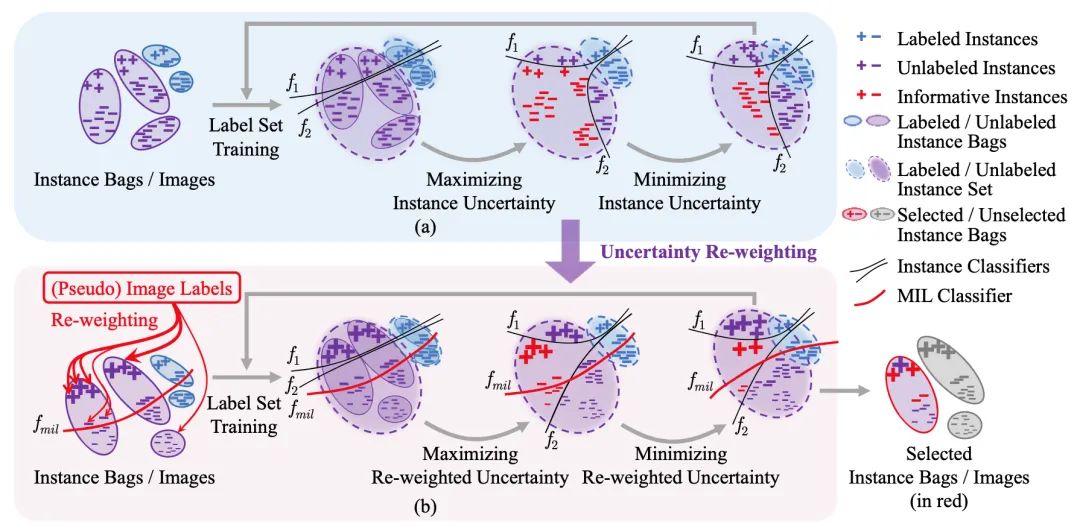
盡管主動(dòng)學(xué)習(xí)在圖像識(shí)別方面取得了長(zhǎng)足的進(jìn)步,但仍然缺乏一種專(zhuān)門(mén)適用于目標(biāo)檢測(cè)的示例級(jí)的主動(dòng)學(xué)習(xí)方法。本文提出了多示例主動(dòng)目標(biāo)檢測(cè)(MI-AOD),通過(guò)觀察示例級(jí)的不確定性來(lái)選擇信息量最大的圖像用于檢測(cè)器的訓(xùn)練。MI-AOD定義了示例不確定性學(xué)習(xí)模塊,該模塊利用在已標(biāo)注集上訓(xùn)練的兩個(gè)對(duì)抗性示例分類(lèi)器的差異來(lái)預(yù)測(cè)未標(biāo)注集的示例不確定性。MI-AOD將未標(biāo)注的圖像視為示例包,并將圖像中的特征錨視為示例,并通過(guò)以多示例學(xué)習(xí)(MIL)方式對(duì)示例重加權(quán)的方法來(lái)估計(jì)圖像的不確定性。反復(fù)進(jìn)行示例不確定性的學(xué)習(xí)和重加權(quán)有助于抑制噪聲高的示例,來(lái)縮小示例不確定性和圖像級(jí)不確定性之間的差距。實(shí)驗(yàn)證明,MI-AOD為示例級(jí)的主動(dòng)學(xué)習(xí)設(shè)置了堅(jiān)實(shí)的基線(xiàn)。在常用的目標(biāo)檢測(cè)數(shù)據(jù)集上,MI-AOD和最新方法相比具有明顯的優(yōu)勢(shì),尤其是在已標(biāo)注集很小的情況下。
論文八
Instance Localization for Self-supervised Detection Pretraining
標(biāo)題:自監(jiān)督檢測(cè)預(yù)訓(xùn)練的實(shí)例定位
論文:https://arxiv.org/abs/2102.08318
代碼:https://github.com/limbo0000/InstanceLoc
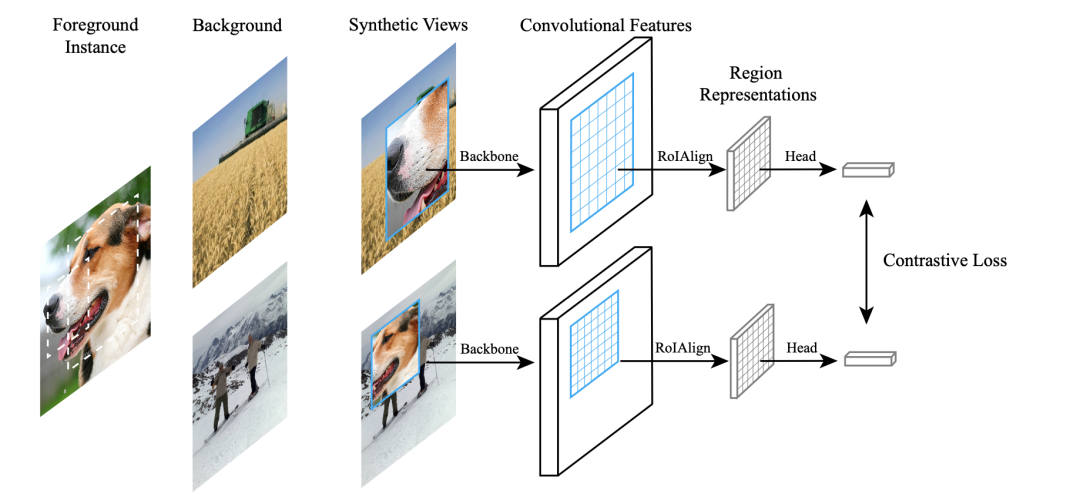
先前對(duì)自監(jiān)督學(xué)習(xí)的研究已經(jīng)在圖像分類(lèi)方面取得了相當(dāng)大的進(jìn)步,但通常在目標(biāo)檢測(cè)方面的遷移性能下降。本文的目的是推進(jìn)專(zhuān)門(mén)用于目標(biāo)檢測(cè)的自監(jiān)督預(yù)訓(xùn)練模型。基于分類(lèi)和檢測(cè)之間的固有差異,我們提出了一種新的自監(jiān)督前置任務(wù),稱(chēng)為實(shí)例定位。圖像實(shí)例粘貼在不同的位置并縮放到背景圖像上。前置任務(wù)是在給定合成圖像以及前景邊界框的情況下預(yù)測(cè)實(shí)例類(lèi)別。我們表明,將邊界框集成到預(yù)訓(xùn)練中可以促進(jìn)遷移學(xué)習(xí)的更好的任務(wù)對(duì)齊和架構(gòu)對(duì)齊。此外,我們?cè)谶吔缈蛏咸岢隽艘环N增強(qiáng)方法,以進(jìn)一步增強(qiáng)特征對(duì)齊。因此,我們的模型在 ImageNet 語(yǔ)義分類(lèi)方面變得更弱,但在圖像定位方面變得更強(qiáng),具有用于目標(biāo)檢測(cè)的整體更強(qiáng)的預(yù)訓(xùn)練模型。實(shí)驗(yàn)結(jié)果表明,我們的方法為 PASCAL VOC 和 MSCOCO 上的對(duì)象檢測(cè)產(chǎn)生了最先進(jìn)的遷移學(xué)習(xí)結(jié)果。
論文九
Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection
標(biāo)題:小樣本目標(biāo)檢測(cè)的語(yǔ)義關(guān)系推理
論文:https://arxiv.org/abs/2103.01903
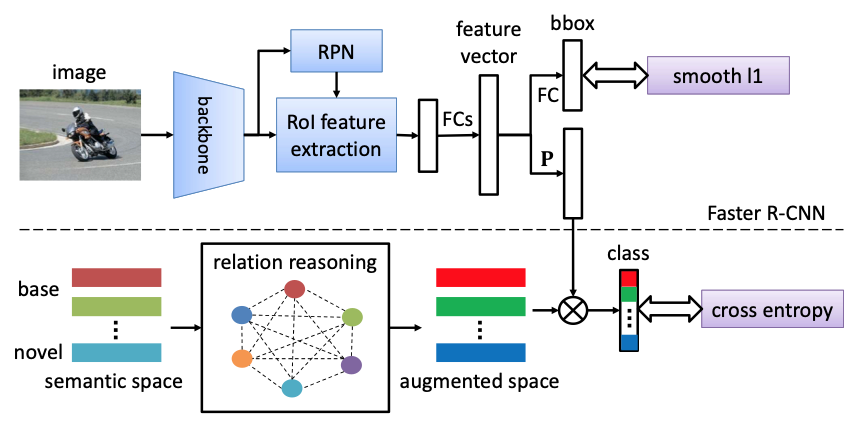
由于現(xiàn)實(shí)世界數(shù)據(jù)固有的長(zhǎng)尾分布,小樣本目標(biāo)檢測(cè)是一個(gè)必要且長(zhǎng)期存在的問(wèn)題。其性能在很大程度上受到新類(lèi)數(shù)據(jù)稀缺性的影響。但是無(wú)論數(shù)據(jù)可用性如何,新類(lèi)和基類(lèi)之間的語(yǔ)義關(guān)系都是不變的。
在這項(xiàng)工作中,作者研究利用這種語(yǔ)義關(guān)系和視覺(jué)信息,并將顯式關(guān)系推理引入新目標(biāo)檢測(cè)的學(xué)習(xí)中。具體來(lái)說(shuō),我們通過(guò)從大量文本語(yǔ)料庫(kù)中學(xué)習(xí)到的語(yǔ)義嵌入來(lái)表示每個(gè)類(lèi)概念。檢測(cè)器被訓(xùn)練以將對(duì)象的圖像表示投影到這個(gè)嵌入空間中。本文還確定了簡(jiǎn)單地使用帶有啟發(fā)式知識(shí)圖的原始嵌入的問(wèn)題,并建議使用動(dòng)態(tài)關(guān)系圖來(lái)增強(qiáng)嵌入。因此,SRR-FSD 的小樣本檢測(cè)器對(duì)新物體的鏡頭變化具有魯棒性和穩(wěn)定性。實(shí)驗(yàn)表明,SRR-FSD 可以在更高的鏡頭下獲得有競(jìng)爭(zhēng)力的結(jié)果,更重要的是,在較低的顯式和隱式鏡頭下,性能明顯更好。從預(yù)訓(xùn)練分類(lèi)數(shù)據(jù)集中刪除隱式鏡頭的基準(zhǔn)協(xié)議可以作為未來(lái)研究的更現(xiàn)實(shí)的設(shè)置。
論文十
OPANAS: One-Shot Path Aggregation Network Architecture Search for Object Detection
標(biāo)題:目標(biāo)檢測(cè)一鍵式路徑聚合網(wǎng)絡(luò)體系結(jié)構(gòu)搜索
論文:https://arxiv.org/abs/2103.04507
代碼:https://github.com/VDIGPKU/OPANAS
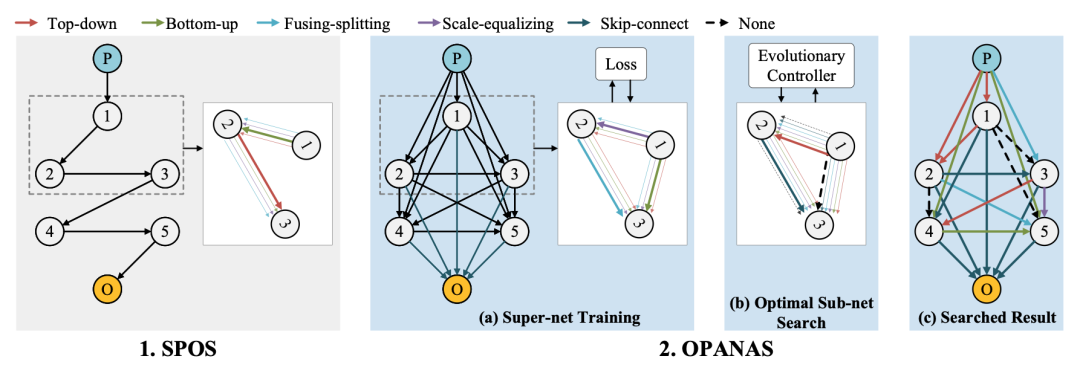
本文提出 OPANAS 算法,顯著提高了搜索效率和檢測(cè)精度,主要包含三個(gè)任務(wù):
引入六種異構(gòu)信息路徑來(lái)構(gòu)建搜索空間,即自上向下、自下向上、融合分裂、比例均衡、殘差連接和無(wú)路徑。
提出了一種新的 FPN 搜索空間,其中每個(gè) FPN 候選者都由一個(gè)密集連接的有向無(wú)環(huán)圖表示(每個(gè)節(jié)點(diǎn)是一個(gè)特征金字塔,每個(gè)邊是六個(gè)異構(gòu)信息路徑之一)。
提出一種高效的一次性搜索方法來(lái)尋找最優(yōu)路徑聚合架構(gòu),即首先訓(xùn)練一個(gè)超網(wǎng)絡(luò),然后用進(jìn)化算法找到最優(yōu)候選者。
實(shí)驗(yàn)結(jié)果證明了所提出的 OPANAS 對(duì)目標(biāo)檢測(cè)的作用:(1)OPANAS 比最先進(jìn)的方法更有效,搜索成本要小得多;(2) OPANAS 發(fā)現(xiàn)的最佳架構(gòu)顯著改進(jìn)了主流檢測(cè)器,mAP 提高了 2.3-3.2%;(3) 實(shí)現(xiàn)了最新的準(zhǔn)確度與速度的均衡(52.2% mAP,7.6 FPS),訓(xùn)練成本比同類(lèi)最先進(jìn)技術(shù)更小。
論文十一
MeGA-CDA: Memory Guided Attention for Category-Aware Unsupervised Domain Adaptive Object Detection
標(biāo)題:用于類(lèi)別感知無(wú)監(jiān)督域自適應(yīng)目標(biāo)檢測(cè)的內(nèi)存引導(dǎo)注意力
論文:https://arxiv.org/abs/2103.04224
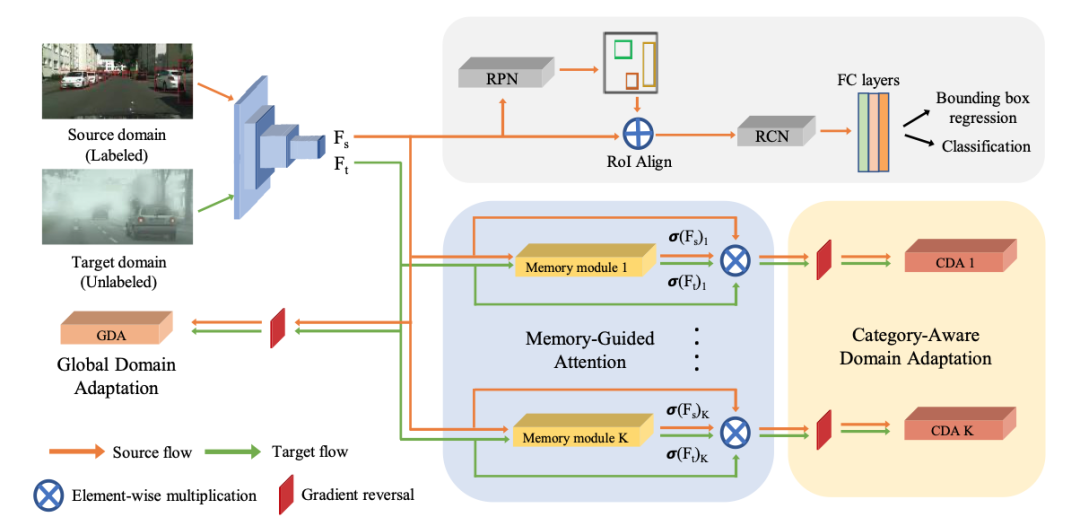
現(xiàn)有的無(wú)監(jiān)督域自適應(yīng)目標(biāo)檢測(cè)方法通過(guò)對(duì)抗性訓(xùn)練執(zhí)行特征對(duì)齊。雖然這些方法在性能上實(shí)現(xiàn)了合理的改進(jìn),但它們通常執(zhí)行與類(lèi)別無(wú)關(guān)的域?qū)R,從而導(dǎo)致特征的負(fù)遷移。
本文嘗試通過(guò)提出用于類(lèi)別感知域適應(yīng)的記憶引導(dǎo)注意(MeGA-CDA)來(lái)將類(lèi)別信息納入域適應(yīng)過(guò)程。所提出的方法包括采用類(lèi)別鑒別器來(lái)確保用于學(xué)習(xí)域不變鑒別特征的類(lèi)別感知特征對(duì)齊。然而,由于目標(biāo)樣本的類(lèi)別信息不可用,我們建議生成內(nèi)存引導(dǎo)的特定類(lèi)別注意圖,然后用于將特征適當(dāng)?shù)芈酚傻较鄳?yīng)的類(lèi)別鑒別器。所提出的方法在幾個(gè)基準(zhǔn)數(shù)據(jù)集上進(jìn)行了評(píng)估,并且表現(xiàn)出優(yōu)于現(xiàn)有方法。
論文十二
FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding
標(biāo)題:通過(guò)對(duì)比提案編碼進(jìn)行的小樣本目標(biāo)檢測(cè)
論文:https://arxiv.org/abs/2103.05950v2
代碼:https: //github.com/MegviiDetection/FSCE
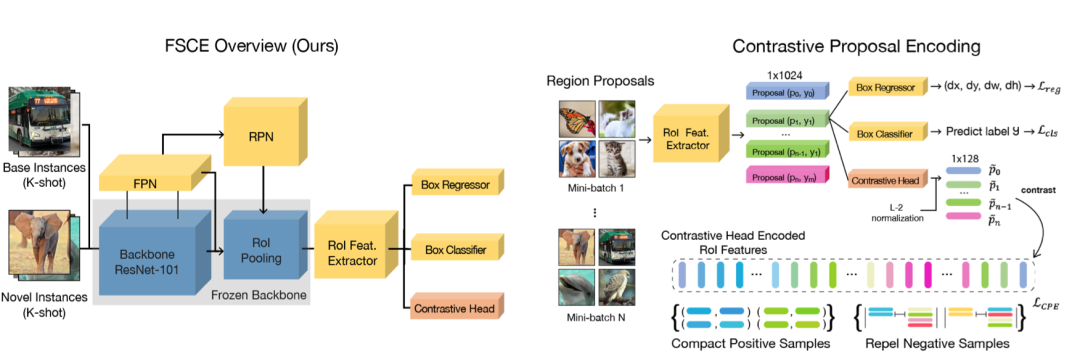
本文提出的FSCE方法旨在從優(yōu)化特征表示的角度去解決小樣本物體檢測(cè)問(wèn)題。小樣本物體檢測(cè)任務(wù)中受限于目標(biāo)樣本的數(shù)目稀少,對(duì)目標(biāo)樣本的分類(lèi)正確與否往往對(duì)最終的性能有很大的影響。FSCE借助對(duì)比學(xué)習(xí)的思想對(duì)相關(guān)候選框進(jìn)行編碼優(yōu)化其特征表示,加強(qiáng)特征的類(lèi)內(nèi)緊湊和類(lèi)間相斥,最后方法在常見(jiàn)的COCO和Pascal VOC數(shù)據(jù)集上都得到有效提升。
論文十三
Robust and Accurate Object Detection via Adversarial Learning
標(biāo)題:通過(guò)對(duì)抗學(xué)習(xí)進(jìn)行穩(wěn)健而準(zhǔn)確的目標(biāo)檢測(cè)
論文:https://arxiv.org/abs/2103.13886
模型:https://github.com/google/automl/tree/master/efficientdet/Det-AdvProp.md
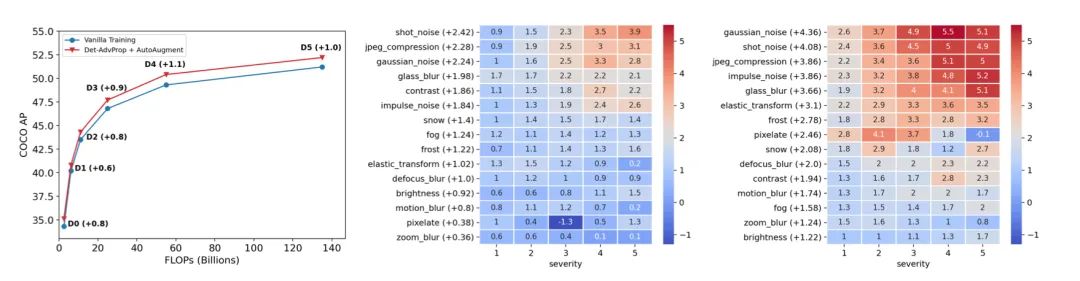
數(shù)據(jù)增強(qiáng)已經(jīng)成為訓(xùn)練高性能深度圖像分類(lèi)器的一個(gè)組成部分,但是它在目標(biāo)檢測(cè)方面的潛力尚未被充分挖掘。鑒于大多數(shù)最先進(jìn)的目標(biāo)檢測(cè)器都得益于對(duì)預(yù)先訓(xùn)練好的分類(lèi)器進(jìn)行微調(diào),本文首先研究了分類(lèi)器從各種數(shù)據(jù)增強(qiáng)中獲得的收益如何遷移至目標(biāo)檢測(cè)。但結(jié)果令人沮喪:在精度或魯棒性方面,微調(diào)后增益減小。因而,本文通過(guò)探索對(duì)抗性的例子來(lái)增強(qiáng)目標(biāo)檢測(cè)器的微調(diào)階段,可以看作是一種依賴(lài)于模型的數(shù)據(jù)增強(qiáng)。本文方法動(dòng)態(tài)地選擇來(lái)自檢測(cè)器分類(lèi)和定位分支的強(qiáng)對(duì)抗性圖像,并隨檢測(cè)器迭代,以確保增強(qiáng)策略保持最新和相關(guān)。這種依賴(lài)于模型的增廣策略比自動(dòng)增廣這樣基于一個(gè)特定檢測(cè)器的模型無(wú)關(guān)增廣策略更適用于不同的目標(biāo)檢測(cè)器。
論文十四
I^3Net: Implicit Instance-Invariant Network for Adapting One-Stage Object Detectors
標(biāo)題:用于適應(yīng)一階段目標(biāo)檢測(cè)器的隱式實(shí)例不變網(wǎng)絡(luò)
論文:https://arxiv.org/abs/2103.13757
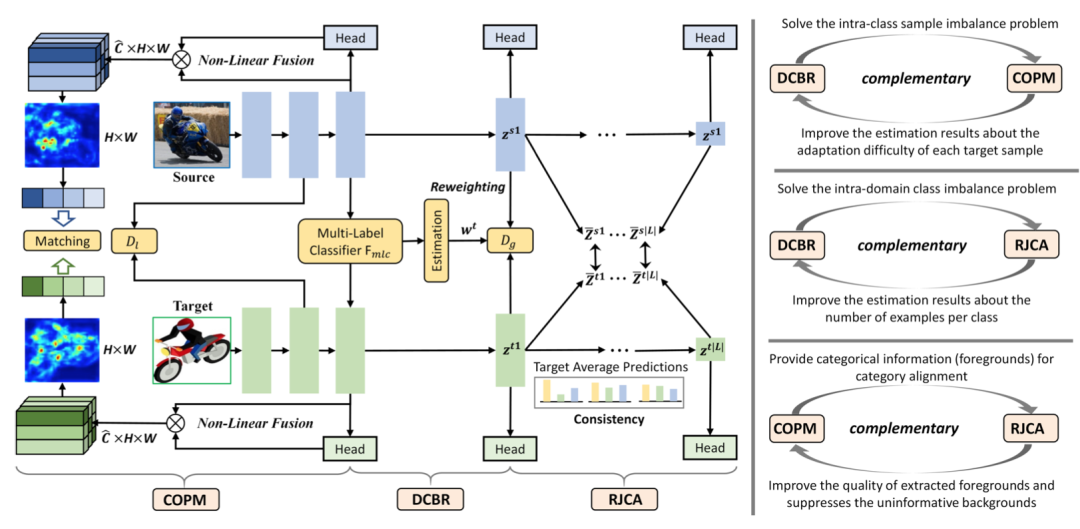
最近關(guān)于兩階段跨域檢測(cè)的工作廣泛地探索了局部特征模式,以獲得更準(zhǔn)確的自適應(yīng)結(jié)果。這些方法在很大程度上依賴(lài)于區(qū)域建議機(jī)制和基于ROI的實(shí)例級(jí)特征來(lái)設(shè)計(jì)針對(duì)前景對(duì)象的細(xì)粒度特征對(duì)齊模塊。然而,對(duì)于單級(jí)檢測(cè)器,很難甚至不可能在檢測(cè)管道中獲得顯式的實(shí)例級(jí)特征。基于此,我們提出了一種隱式實(shí)例不變網(wǎng)絡(luò)(I3Net),該網(wǎng)絡(luò)是為適應(yīng)一級(jí)檢測(cè)器而定制的,通過(guò)利用不同層次深層特征的自然特征隱式學(xué)習(xí)實(shí)例不變特征。本文從三個(gè)方面促進(jìn)了自適應(yīng):
動(dòng)態(tài)類(lèi)平衡重加權(quán)(DCBR)策略,該策略考慮了域內(nèi)和類(lèi)內(nèi)變量的共存,為樣本稀缺和易于適應(yīng)的樣本分配更大的權(quán)重; 類(lèi)別感知對(duì)象模式匹配(COPM)模塊,在類(lèi)別信息的引導(dǎo)下,增強(qiáng)跨域前景對(duì)象匹配,抑制非信息背景特征; 正則化聯(lián)合類(lèi)別對(duì)齊(RJCA)模塊,通過(guò)一致性正則化在不同的領(lǐng)域特定層上聯(lián)合執(zhí)行類(lèi)別對(duì)齊。
論文十五
Distilling Object Detectors via Decoupled Features
標(biāo)題:利用解耦特征提取目標(biāo)檢測(cè)器
論文:https://arxiv.org/abs/2103.14475
代碼:https://github.com/ggjy/DeFeat.pytorch
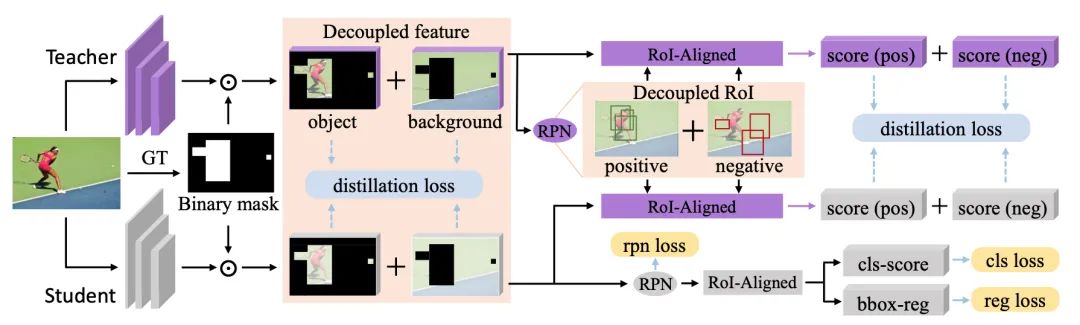
與圖像分類(lèi)不同,目標(biāo)檢測(cè)器具有復(fù)雜的多損失函數(shù),其中語(yǔ)義信息所依賴(lài)的特征非常復(fù)雜。本文指出一種在現(xiàn)有方法中經(jīng)常被忽略的路徑:從不包括物體的區(qū)域中提取的特征信息對(duì)于提取學(xué)生檢測(cè)器。同時(shí)闡明了在蒸餾過(guò)程中,不同區(qū)域的特征應(yīng)具有不同的重要性。并為此提出了一種新的基于解耦特征(DeFeat)的提取算法來(lái)學(xué)習(xí)更好的學(xué)生檢測(cè)器。具體來(lái)說(shuō),將處理兩個(gè)層次的解耦特征來(lái)將有用信息嵌入到學(xué)生中,即來(lái)自頸部的解耦特征和來(lái)自分類(lèi)頭部的解耦建議。在不同主干的探測(cè)器上進(jìn)行的大量實(shí)驗(yàn)表明,該方法能夠超越現(xiàn)有的目標(biāo)檢測(cè)蒸餾方法。
論文十六
OTA: Optimal Transport Assignment for Object Detection
標(biāo)題:目標(biāo)檢測(cè)的最優(yōu)傳輸分配
論文:https://arxiv.org/abs/2103.14259
代碼:https://github.com/Megvii-BaseDetection/OTA
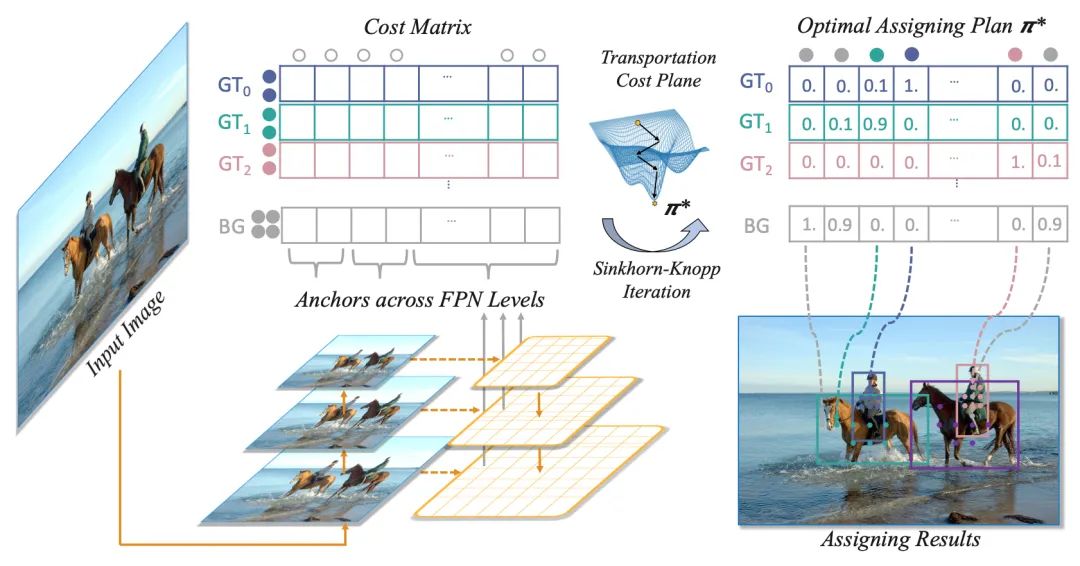
本文提出了一種基于最優(yōu)傳輸理論的目標(biāo)檢測(cè)樣本匹配策略,利用全局信息來(lái)尋找最優(yōu)樣本匹配的結(jié)果,相對(duì)于現(xiàn)有的樣本匹配技術(shù),具有如下優(yōu)勢(shì):
檢測(cè)精度高。全局最優(yōu)的匹配結(jié)果能幫助檢測(cè)器以穩(wěn)定高效的方式訓(xùn)練,最終在COCO數(shù)據(jù)集上達(dá)到最優(yōu)檢測(cè)性能。 適用場(chǎng)景廣。現(xiàn)有的目標(biāo)檢測(cè)算法在遇到諸如目標(biāo)密集或被嚴(yán)重遮擋等復(fù)雜場(chǎng)景時(shí),需要重新設(shè)計(jì)策略或者調(diào)整參數(shù),而最優(yōu)傳輸模型在全局建模的過(guò)程中包括了尋找最優(yōu)解的過(guò)程,不用做任何額外的調(diào)整,在各種目標(biāo)密集、遮擋嚴(yán)重的場(chǎng)景下也能達(dá)到最先進(jìn)的性能,具有很大的應(yīng)用潛力。
論文十七
Data-Uncertainty Guided Multi-Phase Learning for Semi-Supervised Object Detection
標(biāo)題:基于數(shù)據(jù)不確定性的多階段學(xué)習(xí)半監(jiān)督目標(biāo)檢測(cè)
論文:https://arxiv.org/abs/2103.16368
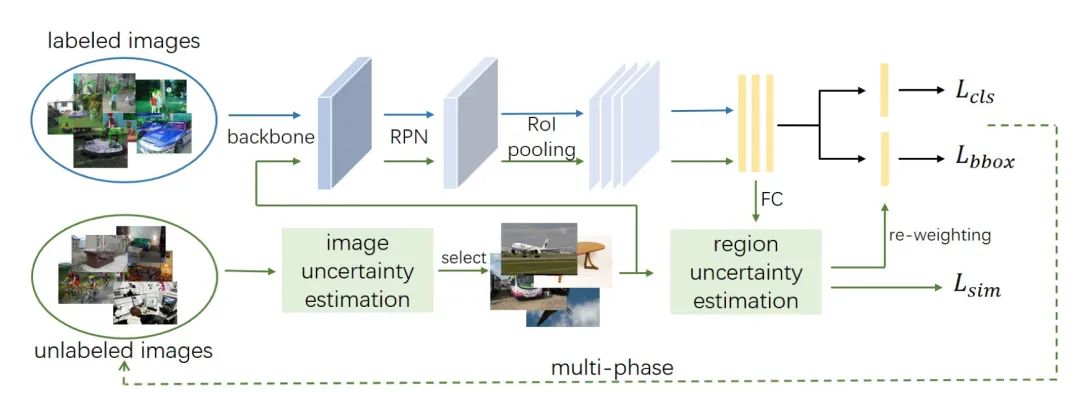
本文深入研究了半監(jiān)督對(duì)象檢測(cè),其中利用未標(biāo)注的圖像來(lái)突破全監(jiān)督對(duì)象檢測(cè)模型的上限。以往基于偽標(biāo)簽的半監(jiān)督方法受噪聲影響嚴(yán)重,容易對(duì)噪聲標(biāo)簽過(guò)擬合,無(wú)法很好地學(xué)習(xí)不同的未標(biāo)記知識(shí)。為了解決這個(gè)問(wèn)題,本文提出了一種用于半監(jiān)督目標(biāo)檢測(cè)的數(shù)據(jù)不確定性引導(dǎo)的多階段學(xué)習(xí)方法,根據(jù)它們的難度級(jí)別綜合考慮不同類(lèi)型的未標(biāo)記圖像,在不同階段使用它們,并將不同階段的集成模型一起生成最終結(jié)果。圖像不確定性引導(dǎo)的簡(jiǎn)單數(shù)據(jù)選擇和區(qū)域不確定性引導(dǎo)的 RoI 重新加權(quán)參與多階段學(xué)習(xí),使檢測(cè)器能夠?qū)W⒂诟_定的知識(shí)。
論文十八
Scale-aware Automatic Augmentation for Object Detection
標(biāo)題:用于目標(biāo)檢測(cè)的尺度感知自動(dòng)增強(qiáng)
論文:https://arxiv.org/abs/2103.17220
代碼:https://github.com/Jia-Research-Lab/SA-AutoAug
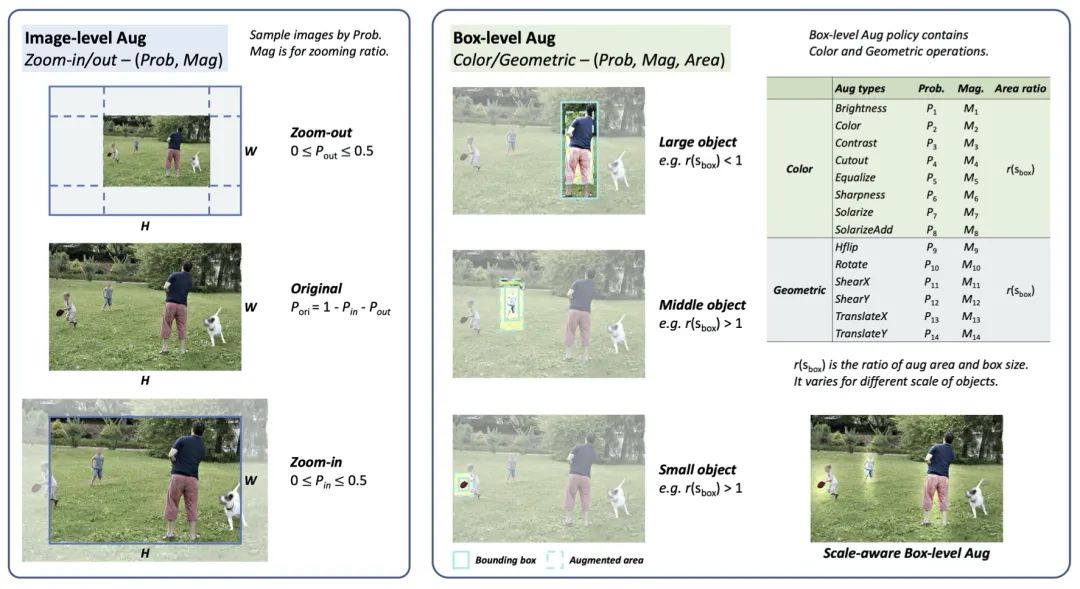
本文提出了一種用于目標(biāo)檢測(cè)的數(shù)據(jù)增強(qiáng)策略,定義了一個(gè)新的尺度感知搜索空間,其中圖像級(jí)和框級(jí)增強(qiáng)都旨在保持尺度不變性。在這個(gè)搜索空間上,本文提出了一種新的搜索指標(biāo),稱(chēng)為帕累托規(guī)模均衡(Pareto Scale Balance),以促進(jìn)高效搜索。在實(shí)驗(yàn)中,即使與強(qiáng)大的多尺度訓(xùn)練基線(xiàn)相比,尺度感知自動(dòng)增強(qiáng)對(duì)各種目標(biāo)檢測(cè)器(如 RetinaNet、Faster R-CNN、Mask R-CNN 和 FCOS)也產(chǎn)生了顯著且一致的改進(jìn)。本文搜索的增強(qiáng)策略可轉(zhuǎn)移到目標(biāo)檢測(cè)之外的其他視覺(jué)任務(wù)(如實(shí)例分割和關(guān)鍵點(diǎn)估計(jì))以提高性能,且搜索成本遠(yuǎn)低于以前用于目標(biāo)檢測(cè)的自動(dòng)增強(qiáng)方法。
論文十九
Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection
標(biāo)題:具有上下文感知聚合的密集關(guān)系蒸餾用于小樣本目標(biāo)檢測(cè)
論文:https://arxiv.org/abs/2103.17115
代碼:https://github.com/hzhupku/DCNet
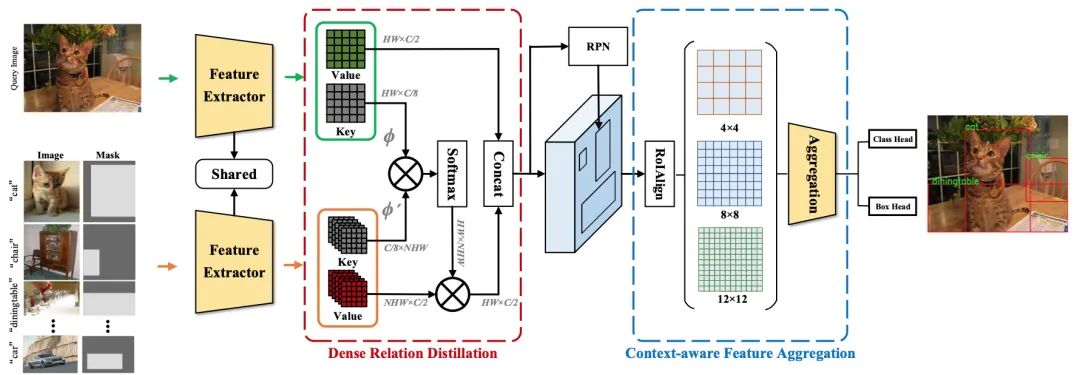
傳統(tǒng)的基于深度學(xué)習(xí)的目標(biāo)檢測(cè)方法需要大量的邊界框標(biāo)注進(jìn)行訓(xùn)練,獲得如此高質(zhì)量的標(biāo)注數(shù)據(jù)成本很高。小樣本目標(biāo)檢測(cè)能通過(guò)少量帶標(biāo)注的樣本學(xué)習(xí)新類(lèi),非常具有挑戰(zhàn)性,因?yàn)樾履繕?biāo)的細(xì)粒度特征很容易被忽略,而只有少數(shù)可用數(shù)據(jù)。
在這項(xiàng)工作中,為了充分利用帶標(biāo)注的新對(duì)象的特征并捕獲查詢(xún)對(duì)象的細(xì)粒度特征,作者提出了具有上下文感知聚合的密集關(guān)系蒸餾來(lái)解決小樣本檢測(cè)問(wèn)題。密集關(guān)系蒸餾模塊建立在基于元學(xué)習(xí)的框架之上,旨在充分利用支持特征,其中支持特征和查詢(xún)特征密集匹配,以前饋方式覆蓋所有空間位置。引導(dǎo)信息的大量使用讓模型能處理常見(jiàn)挑戰(zhàn)(例如外觀變化和遮擋)。此外,為了更好地捕獲尺度感知特征,上下文感知聚合模塊自適應(yīng)地利用來(lái)自不同尺度的特征以獲得更全面的特征表示。
論文二十
DAP: Detection-Aware Pre-training with Weak Supervision
標(biāo)題:弱監(jiān)督下的檢測(cè)感知預(yù)訓(xùn)練
論文:https://arxiv.org/abs/2103.16651
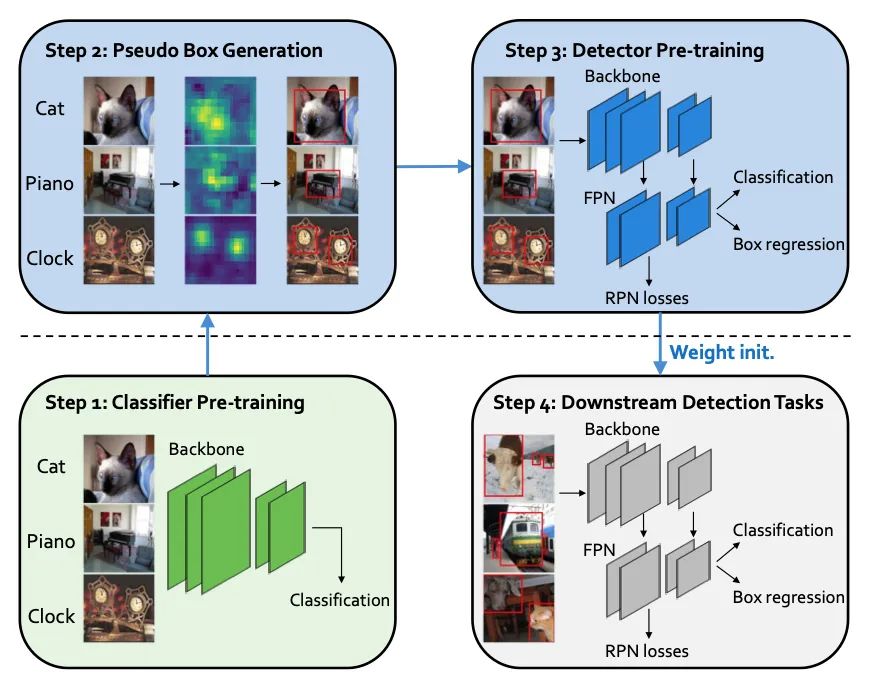
本文提出了一種檢測(cè)感知預(yù)訓(xùn)練方法,該方法僅利用弱標(biāo)記的分類(lèi)樣式數(shù)據(jù)集進(jìn)行預(yù)訓(xùn)練,但專(zhuān)門(mén)為使目標(biāo)檢測(cè)任務(wù)受益而量身定制。與廣泛使用的基于圖像分類(lèi)的預(yù)訓(xùn)練不同,它不包括任何與位置相關(guān)的訓(xùn)練任務(wù),本文通過(guò)基于類(lèi)激活圖的弱監(jiān)督對(duì)象定位方法將分類(lèi)數(shù)據(jù)集轉(zhuǎn)換為檢測(cè)數(shù)據(jù)集,直接預(yù)訓(xùn)練檢測(cè)器,使預(yù)先訓(xùn)練的模型具有位置感知能力并能夠預(yù)測(cè)邊界框。在下游檢測(cè)任務(wù)中,DAP在效率和收斂速度方面都可以?xún)?yōu)于傳統(tǒng)的分類(lèi)預(yù)訓(xùn)練。特別是當(dāng)下游任務(wù)中的樣本數(shù)量很少時(shí),DAP 可以大幅提高檢測(cè)精度。
論文二十一
Adaptive Class Suppression Loss for Long-Tail Object Detection
標(biāo)題:用于長(zhǎng)尾目標(biāo)檢測(cè)的自適應(yīng)類(lèi)抑制損失
論文:https://arxiv.org/abs/2104.00885
代碼:https://github.com/CASIA-IVA-Lab/ACSL
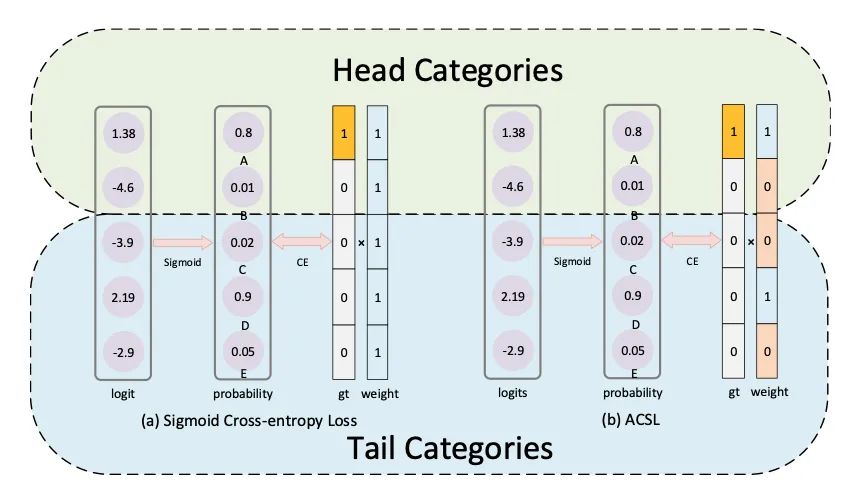
為了解決大詞匯量目標(biāo)檢測(cè)任務(wù)的長(zhǎng)尾分布問(wèn)題,現(xiàn)有的方法通常將整個(gè)類(lèi)別分為幾組,并對(duì)每組采取不同的策略。這些方法帶來(lái)以下兩個(gè)問(wèn)題一:一是大小相似的相鄰類(lèi)別之間的訓(xùn)練不一致,二是學(xué)習(xí)的模型對(duì)尾部類(lèi)別缺乏區(qū)分,這些尾部類(lèi)別在語(yǔ)義上與某些頭部類(lèi)別相似。
本文設(shè)計(jì)了一種新穎的自適應(yīng)類(lèi)別抑制損失(ACSL)來(lái)有效解決上述問(wèn)題,并提長(zhǎng)尾類(lèi)別的檢測(cè)性能。本文引入了一個(gè)無(wú)統(tǒng)計(jì)的視角來(lái)分析長(zhǎng)尾分布,打破了手動(dòng)分組的限制,因而 ACSL 能自適應(yīng)地調(diào)整每個(gè)類(lèi)別的樣本的抑制梯度,確保訓(xùn)練的一致性,并提高對(duì)稀有類(lèi)別的區(qū)分度。以ResNet50-FPN作為基準(zhǔn),ACSL 在長(zhǎng)尾數(shù)據(jù)集 LVIS 和 Open Images 上分別實(shí)現(xiàn)了 5.18% 和 5.2% 的提升。
論文二十二
IQDet: Instance-wise Quality Distribution Sampling for Object Detection
標(biāo)題:用于目標(biāo)檢測(cè)的實(shí)例質(zhì)量分布采樣 論文:https://arxiv.org/abs/2104.06936
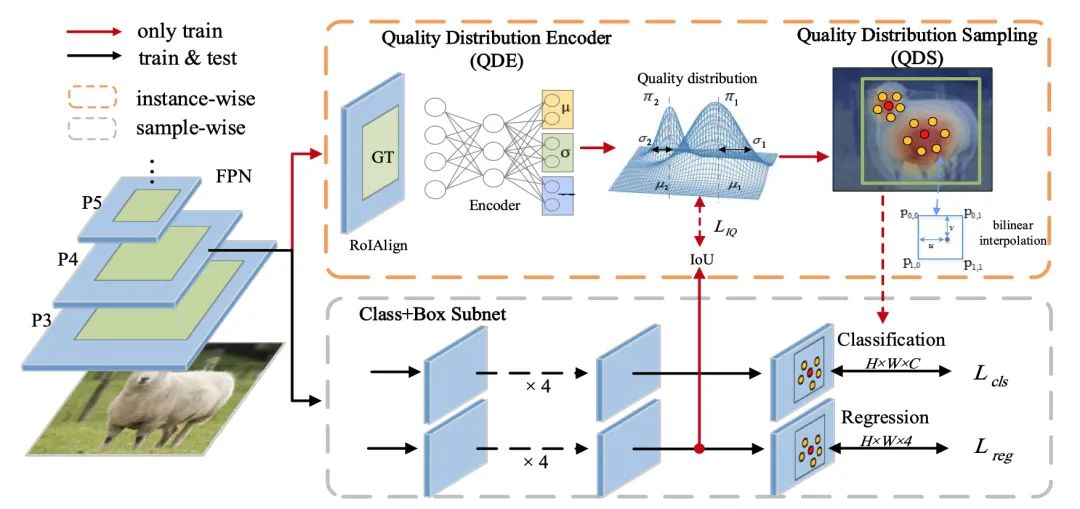
本文提出了一種具有實(shí)例采樣策略的密集對(duì)象檢測(cè)器。與使用先驗(yàn)采樣策略不同,本文首先提取了每個(gè)真值的區(qū)域特征來(lái)估計(jì)實(shí)例質(zhì)量分布。根據(jù)空間維度的混合模型,該分布具有更強(qiáng)的抗噪性并適應(yīng)每個(gè)實(shí)例的語(yǔ)義模式。基于分布,本文提出了一種質(zhì)量采樣策略,它以概率的方式自動(dòng)選擇訓(xùn)練樣本,并用更多的高質(zhì)量樣本進(jìn)行訓(xùn)練。在 MS COCO 上的大量實(shí)驗(yàn)表明,我們的方法簡(jiǎn)單穩(wěn)定地提高了近 2.4 個(gè) AP。本文最好的模型達(dá)到了 51.6 AP,優(yōu)于所有現(xiàn)有的最先進(jìn)的單階段檢測(cè)器,且在推理時(shí)間上完全無(wú)消耗。
論文二十三
Line Segment Detection Using Transformers without Edges(Oral)
標(biāo)題:使用無(wú)邊緣Transformer的線(xiàn)段檢測(cè)
論文:https://arxiv.org/abs/2101.01909
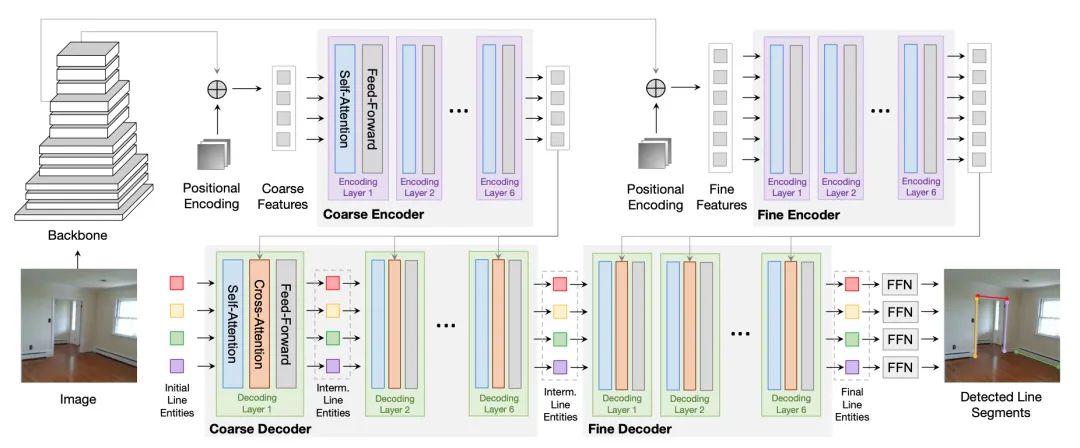
本文提出了一種使用 Transformer 的聯(lián)合端到端線(xiàn)段檢測(cè)算法(LETR),該算法無(wú)需后處理和啟發(fā)式引導(dǎo)的中間處理(邊緣/結(jié)點(diǎn)/區(qū)域檢測(cè))。LETR通過(guò)跳過(guò)邊緣元素檢測(cè)和感知分組過(guò)程的標(biāo)準(zhǔn)啟發(fā)式設(shè)計(jì),利用了 Transformer 中集成的標(biāo)記化查詢(xún)、自注意力機(jī)制和編碼解碼策略。本文為 Transformers 配備了多尺度編碼器/解碼器策略,以在直接端點(diǎn)距離損失下執(zhí)行細(xì)粒度線(xiàn)段檢測(cè)。該損失項(xiàng)特別適用于檢測(cè)幾何結(jié)構(gòu),例如標(biāo)準(zhǔn)邊界框不方便表示的線(xiàn)段。
論文二十四
Domain-Specific Suppression for Adaptive Object Detection
標(biāo)題:自適應(yīng)目標(biāo)檢測(cè)的特定領(lǐng)域抑制
論文:https://arxiv.org/abs/2105.03570
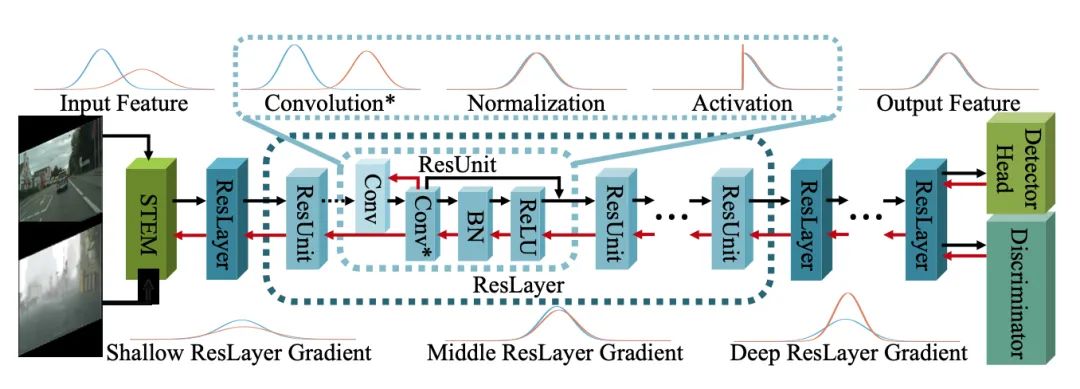
由于復(fù)雜任務(wù)對(duì)模型的可遷移性有更高要求,領(lǐng)域自適應(yīng)方法在目標(biāo)檢測(cè)中面臨性能下降的問(wèn)題。當(dāng)前的UDA目標(biāo)檢測(cè)方法在優(yōu)化時(shí)將兩個(gè)方向視為一個(gè)整體,即使輸出特征完美對(duì)齊也會(huì)導(dǎo)致域不變方向不匹配。
本文對(duì)提升 CNN 可遷移性的新視角進(jìn)行了探討,將模型的權(quán)重視為一系列運(yùn)動(dòng)模式。權(quán)重的方向和梯度可以分為領(lǐng)域特定和領(lǐng)域不變的部分,領(lǐng)域適應(yīng)的目標(biāo)是專(zhuān)注于領(lǐng)域不變的方向,同時(shí)消除領(lǐng)域特定的干擾。
本文提出了特定領(lǐng)域的抑制,這是一種對(duì)反向傳播中原始卷積梯度的示例性和可推廣的約束,以分離方向的兩個(gè)部分并抑制特定領(lǐng)域的方向。作者進(jìn)一步驗(yàn)證了在幾個(gè)域自適應(yīng)對(duì)象檢測(cè)任務(wù)上的理論分析和方法,包括天氣、相機(jī)配置和合成到現(xiàn)實(shí)世界的適應(yīng)。實(shí)驗(yàn)結(jié)果表明,在 UDA 對(duì)象檢測(cè)領(lǐng)域,本文方法與目前最先進(jìn)的方法相比取得了顯著進(jìn)步,在所有這些域適應(yīng)場(chǎng)景中實(shí)現(xiàn)了 10.2~12.2% mAP 的提升。
論文二十五
PSRR-MaxpoolNMS: Pyramid Shifted MaxpoolNMS with Relationship Recovery
標(biāo)題:關(guān)系修復(fù)和金字塔移位MaxpoolNMS
論文:https://arxiv.org/abs/2105.12990
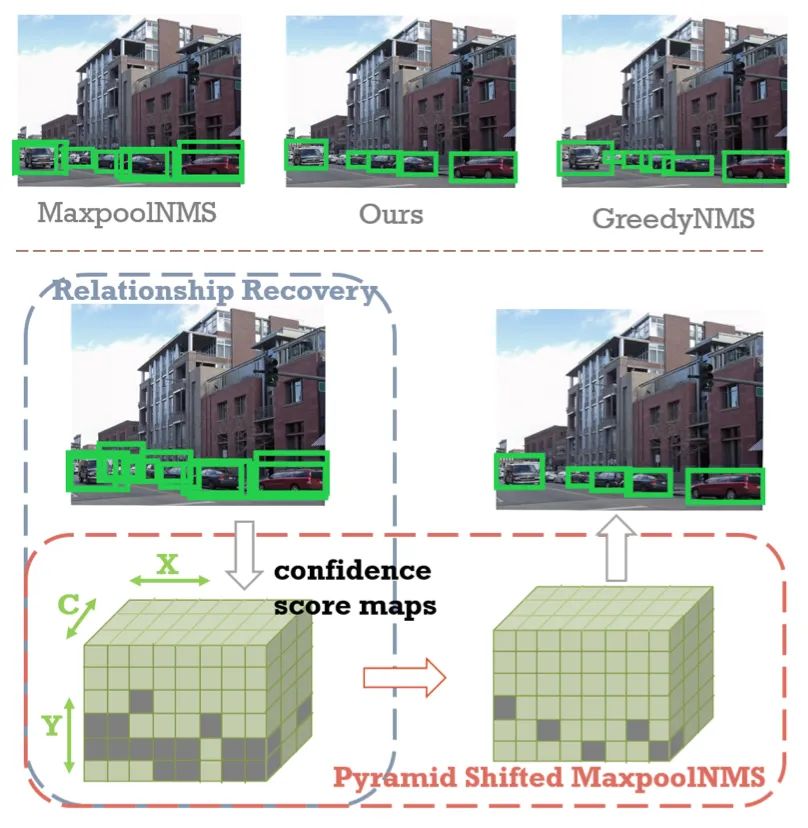
非極大值抑制 (NMS) 是現(xiàn)代卷積神經(jīng)網(wǎng)絡(luò)中用于目標(biāo)檢測(cè)的重要后處理步驟。與本質(zhì)上并行的卷積不同,NMS 的實(shí)際標(biāo)準(zhǔn) GreedyNMS 并不容易并行化,因而可能成為目標(biāo)檢測(cè)的性能瓶頸。MaxpoolNMS 被引入作為 GreedyNMS 的可并行替代方案,從而在不降低精度的條件下實(shí)現(xiàn)比 GreedyNMS 更快的速度。但是,MaxpoolNMS 只能在像 Faster-RCNN 這樣的兩階段檢測(cè)器的一階段替換 GreedyNMS。在最終檢測(cè)階段應(yīng)用 MaxpoolNMS 時(shí),準(zhǔn)確率會(huì)顯著下降,因?yàn)?MaxpoolNMS 在邊界框選擇方面無(wú)法比擬 GreedyNMS。
本文提出了一種通用的、可并行的和可配置的方法 PSRR-MaxpoolNMS,以在所有檢測(cè)器的所有階段都能完全替代 GreedyNMS。通過(guò)引入簡(jiǎn)單的關(guān)系恢復(fù)模塊和金字塔移位 MaxpoolNMS 模塊,PSRR-MaxpoolNMS 能夠比 MaxpoolNMS 更貼近 GreedyNMS。綜合實(shí)驗(yàn)表明,本文方法在很大程度上優(yōu)于 MaxpoolNMS,并且被證明比 GreedyNMS 更快且具有相當(dāng)?shù)臏?zhǔn)確性。PSRR-MaxpoolNMS 首次為定制化硬件設(shè)計(jì)提供了完全可并行化的解決方案,可重復(fù)用于加速各處的 NMS。
論文二十六
Improved Handling of Motion Blur in Online Object Detection
標(biāo)題:改進(jìn)在線(xiàn)目標(biāo)檢測(cè)中運(yùn)動(dòng)模糊的處理
論文:https://arxiv.org/abs/2011.14448
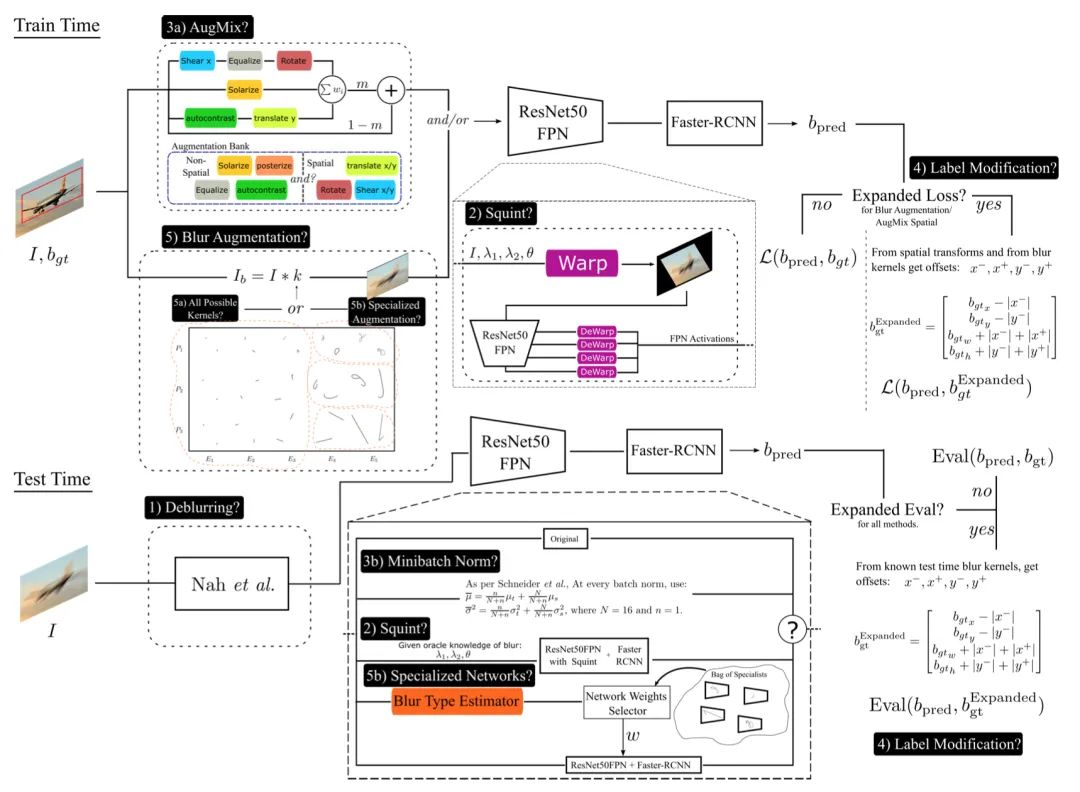
目標(biāo)檢測(cè)已經(jīng)非常具有挑戰(zhàn)性,當(dāng)圖像模糊時(shí)更難。大多數(shù)現(xiàn)有的努力要么集中在清晰的圖像上,易于標(biāo)記真值,要么將運(yùn)動(dòng)模糊視為通用損壞之一。而本文希望為將在現(xiàn)實(shí)世界中運(yùn)行的在線(xiàn)視覺(jué)系統(tǒng)檢測(cè)特定類(lèi)別的對(duì)象。
本文特別關(guān)注自運(yùn)動(dòng)引起的模糊的細(xì)節(jié)。探索了五種解決方案,每一種都針對(duì)導(dǎo)致清晰和模糊圖像之間性能差距的不同潛在原因。首先對(duì)圖像進(jìn)行去模糊處理,但目前只能部分改善目標(biāo)檢測(cè)。其他四類(lèi)措施涉及多尺度紋理、分布外測(cè)試、標(biāo)簽生成和模糊類(lèi)型調(diào)節(jié)。令人驚訝的是,作者發(fā)現(xiàn)能夠解決空間歧義的自定義標(biāo)簽生成領(lǐng)先于其他所有方法,顯著改善了目標(biāo)檢測(cè)。此外,與分類(lèi)的結(jié)果相反,通過(guò)根據(jù)定制的運(yùn)動(dòng)模糊類(lèi)別調(diào)節(jié)模型,本文方法取得了顯著的性能提升。
論文二十七
Open-Vocabulary Object Detection Using Captions(Oral)
標(biāo)題:使用字幕的開(kāi)放詞匯目標(biāo)檢測(cè)
論文:https://arxiv.org/abs/2011.10678
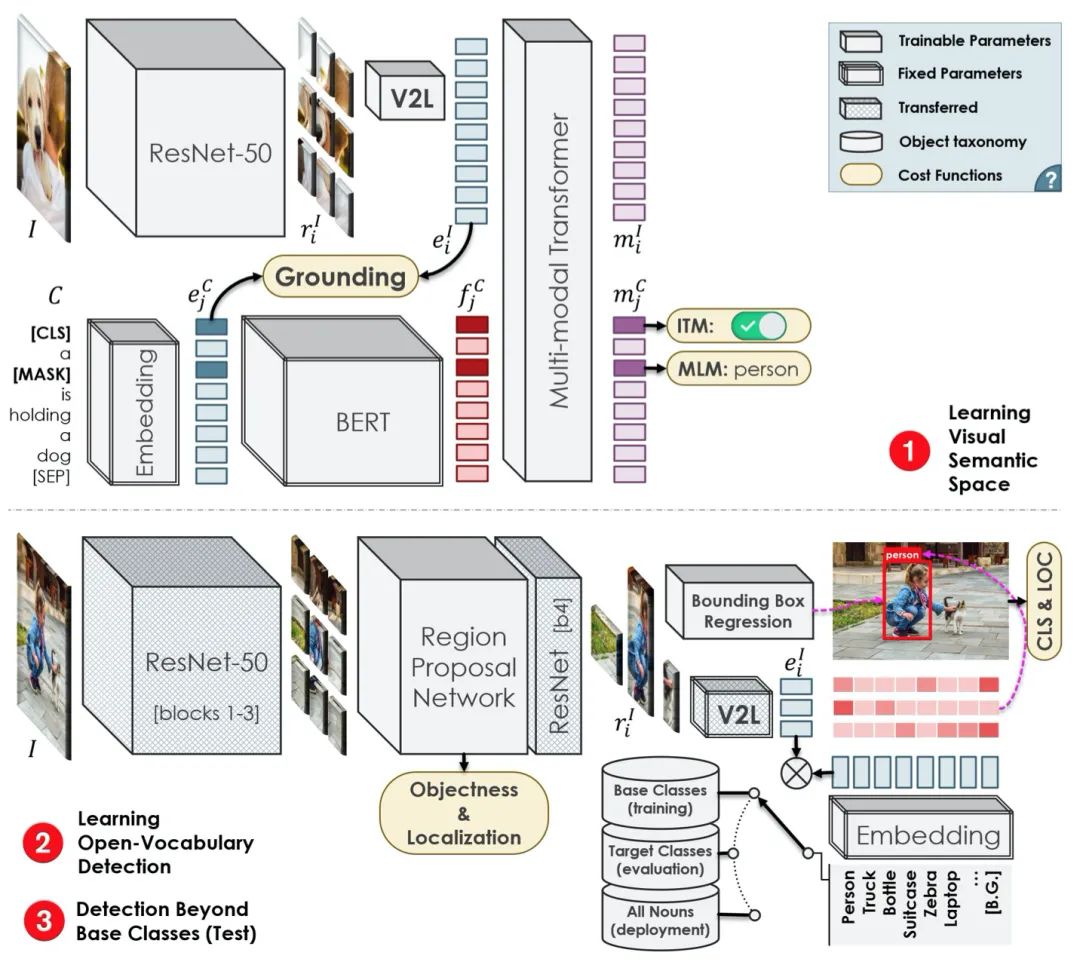
盡管深度神經(jīng)網(wǎng)絡(luò)在目標(biāo)檢測(cè)中具有非凡的準(zhǔn)確性,但由于監(jiān)督要求,它們的訓(xùn)練和擴(kuò)展成本很高。特別是,學(xué)習(xí)更多的對(duì)象類(lèi)別通常需要按比例增加更多的邊界框注釋。雖然已有工作探索了弱監(jiān)督和零樣本學(xué)習(xí)技術(shù),以在監(jiān)督較少的情況下將目標(biāo)檢測(cè)器擴(kuò)展到更多類(lèi)別,但它們并沒(méi)有像監(jiān)督模型那樣成功和廣泛采用。
本文提出了目標(biāo)檢測(cè)問(wèn)題的一種新表述,即開(kāi)放詞匯目標(biāo)檢測(cè),它比弱監(jiān)督和零樣本方法更通用、更實(shí)用、更有效。文章提出了一種新方法,為有限的一組對(duì)象類(lèi)別用邊界框注釋來(lái)訓(xùn)練目標(biāo)檢測(cè)器,同時(shí)以顯著更低的成本覆蓋更多種類(lèi)對(duì)象的圖像-字幕對(duì)。本文所提出的方法可以檢測(cè)和定位在訓(xùn)練期間未提供邊界框注釋的對(duì)象,其準(zhǔn)確度明顯高于零樣本方法。同時(shí),具有邊界框注釋的對(duì)象幾乎可以與監(jiān)督方法一樣準(zhǔn)確地被檢測(cè)到,這明顯優(yōu)于弱監(jiān)督基線(xiàn)。因此,我們?yōu)榭蓴U(kuò)展的對(duì)象檢測(cè)建立了一種新的技術(shù)狀態(tài)。
END
整理不易,點(diǎn)贊三連↓