
Elasticsearch 如何實(shí)現(xiàn)相似推薦功能?
1、什么是相似推薦?
拿我們身邊的算法“投喂”為主的頭條、抖音、微信視頻號(hào)等舉例,如果你喜歡乒乓球,每天推送給你的都是乒乓球比賽視頻集錦;如果你喜歡成功人士演講,每天都是馬云、馬化騰、劉強(qiáng)東等商業(yè)巨鱷的演講。
再拿電商的示例如下:比如我近期購買的吳軍老師推薦的科普經(jīng)典巨著《從一到無窮大》,京東會(huì)給我推薦樊登讀書帶火的書《微積分原理》。

Q1:ES 有相似搜索這個(gè)功能吧?我記得有個(gè) suggester吧?
Q2:ES有沒有處理相似文字的案例?把相似文章聚合起來。 來自《死磕Elasticsearch 知識(shí)星球》微信群
2、Elasticsearch 相似推薦功能實(shí)現(xiàn)
這里不得不介紹:MLT 檢索。對(duì)!你沒看錯(cuò)。不是:MIT(麻省理工學(xué)院),是 Elasticsearch 一種檢索類型 MLT(More Like This Query )。
看下圖,建立個(gè)全局認(rèn)識(shí)。MLT 屬于:Query DSL下的專業(yè)檢索(Specialized queries)的范疇。
3、More Like This 檢索介紹
More Like This 檢索定義:查找與給定文檔“相似”的文檔。
4、More Like This 底層邏輯
MLT 查詢簡單地從輸入的待查詢文本中提取文本,對(duì)其進(jìn)行分析,通常在字段中使用相同的分析器,然后選擇具有最高 tf-idf 的前 K 個(gè)詞組以形成這些詞組的組合查詢語句。
假設(shè)我們想找到與給定輸入文檔相似的所有文檔。顯然,輸入文檔本身應(yīng)該是該類型查詢的最佳匹配。為什么呢?基于 Lucene tf-idf 評(píng)分公式計(jì)算得出的呀。
如下就是 Lucene tf-idf 評(píng)分模型。

干貨 | 一步步拆解 Elasticsearch BM25 模型評(píng)分細(xì)節(jié)
實(shí)戰(zhàn) | Elasticsearch自定義評(píng)分的N種方法
MLT 查詢的本質(zhì)是:從待檢索語句中提取文本,然后用分詞器切分,選擇 tf-idf 分值高的前 K 個(gè)術(shù)語形成檢索語句。基于檢索語句返回的結(jié)果就是相似度查詢結(jié)果。
為避免歧義,對(duì)照的英文如下:
The MLT query simply extracts the text from the input document, analyzes it, usually using the same analyzer at the field, then selects the top K terms with highest tf-idf to form a disjunctive query of these terms.
如果原理還不夠清晰,我將核心 Lucene 源碼的邏輯簡要說明如下:
步驟 1:根據(jù)輸入的待查詢的文檔,抽取詞組單元(term),結(jié)合TF*IDF 評(píng)分形成優(yōu)先級(jí)隊(duì)列。
步驟 2:結(jié)合步驟 1 的優(yōu)先級(jí)隊(duì)列,生成布爾查詢語句。
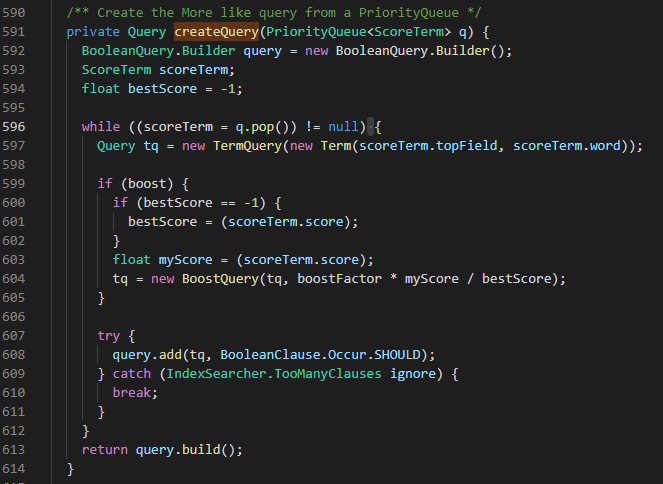
步驟 3:基于步驟2構(gòu)造的布爾查詢語句,獲取查詢結(jié)果。
5、More Like This 前置條件
執(zhí)行 MLT 的字段必須被索引并且類型為 text 或 keyword。此外,當(dāng)對(duì)文檔使用相似度檢索時(shí),必須啟用 _source 或設(shè)置為 stored 或存儲(chǔ)為 term_vector。為了加快分析速度,可以在索引時(shí)存儲(chǔ) terrm vectors。
讀者看到這里可能會(huì)疑惑:啥叫 term vectors ?
有必要解釋一下:
term vectors 組成:
terms 分詞單元列表。 每個(gè)分詞單元的位置 position??和序號(hào)。 分詞后的單詞或字在原有串中的起始位置?start_offset?、結(jié)束位置 ?end_offset 和偏移值。 有效載荷。與位置相關(guān)的用戶定義的二進(jìn)制值。
給了一堆術(shù)語,還是看不懂,再來?!
給個(gè)例子,一看就明白了。
PUT?my-index-0000012
{
??"mappings":?{
????"properties":?{
??????"text":?{
????????"type":?"text",
????????"term_vector":?"with_positions_offsets"
??????}
????}
??}
}
PUT?my-index-0000012/_doc/1
{
??"text":?"Quick?brown?fox?fox"
}
GET?/my-index-0000012/_termvectors/1
position 更精確的說法是:序號(hào)。
Quick 的 position 為 0;
brown 的 position 為 1;
quick 的 start_offset 為?0;
quick?的?end_offset?為 5。

6、More?Like?This 實(shí)戰(zhàn)一把
光說不練是假把式,實(shí)戰(zhàn)一把,一探究竟。
插入一批數(shù)據(jù),數(shù)據(jù)來源:百度熱點(diǎn)新聞 。
DELETE?news
PUT?news
{
??"mappings":?{
????"properties":?{
??????"title":?{
????????"type":?"text",
????????"analyzer":?"ik_smart"
??????}
????}
??}
}
POST?news/_bulk
{?"index":??{?"_id":1?}}
{"title":"演唱會(huì)突發(fā)意外!知名男星受傷,本人最新回應(yīng)"}
{?"index":??{?"_id":2?}}
{"title":"張杰演唱會(huì)主辦方道歉:舞臺(tái)升降設(shè)備出現(xiàn)故障"}
{?"index":??{?"_id":3?}}
{"title":"謝娜發(fā)文回應(yīng)張杰受傷"}
{?"index":??{?"_id":4?}}
{"title":"張杰回應(yīng)受傷:不會(huì)有大礙,請(qǐng)歌迷和家人朋友們放寬心"}
{?"index":??{?"_id":5?}}
{"title":"張杰表演時(shí)從電梯墜落?手指血流不止"}
{?"index":??{?"_id":6?}}
{"title":"謝娜回應(yīng)張杰受傷:他問的第一句話就是怕嚇到女兒"}
{?"index":??{?"_id":7?}}
{"title":"張杰演唱會(huì)出意外后,發(fā)長文給粉絲報(bào)平安,謝娜透露張杰本人..."}
{?"index":??{?"_id":8}}
{"title":"張杰明星資料大全愛奇藝泡泡"}
PS:以上僅是百度公開的熱點(diǎn)新聞,以此舉例相似查詢,別無其他用途,特此說明。
執(zhí)行 MLT:
POST?news/_search
{
??"query":?{
????"more_like_this":?{
??????"fields":?[
????????"title"
??????],
??????"like":?[
????????"張杰開演唱會(huì)從升降機(jī)上掉落"
??????],
??????"analyzer":?"ik_smart",
??????"min_doc_freq":?2,
??????"min_term_freq":?1
????}
??}
}
返回結(jié)果如下:

以如上截圖最后一條數(shù)據(jù)為例,強(qiáng)調(diào)說明一下:注意到一個(gè)細(xì)節(jié),返回結(jié)果只是相似,并沒有真正做到語義相關(guān)。
7、More?Like?This 核心語法詳解
參數(shù)看著很好解釋,但著實(shí)非常難理解,特此解讀如下:
"min_doc_freq": 2
最小的文檔頻率,默認(rèn)為 5。
什么意思呢?
就拿上面的示例來說,至少得有兩篇文章才可以,不管這兩篇文章與輸入相關(guān)與否。
更具體點(diǎn)說,如果bulk 寫入僅一篇document,哪怕和標(biāo)題一致也無法返回結(jié)果。
"min_term_freq": 1
文檔中詞組的最低頻率,默認(rèn)是2,低于此頻率的會(huì)被忽略。
什么意思呢?
就是待檢索語句的其中一個(gè)分詞單元的詞頻的最小值。
PUT?news
{
??"mappings":?{
????"properties":?{
??????"title":?{
????????"type":?"text",
????????"analyzer":?"ik_smart"
??????}
????}
??}
}
POST?news/_bulk
{?"index":??{?"_id":1?}}
{"title":"張杰演唱會(huì)突發(fā)意外!知名男星受傷,本人最新回應(yīng)"}
{?"index":??{?"_id":2?}}
{"title":"hello?kitty"}
POST?news/_search
{
??"query":?{
????"more_like_this":?{
??????"fields":?[
????????"title"
??????],
??????"like":?[
????????"張杰回應(yīng)張杰受傷"
??????],
??????"analyzer":?"ik_smart",
??????"min_doc_freq":?1,
??????"min_term_freq":?2
????}
??}
}
上面的例子更有說服力。
更為具體的說,like部分待檢索語句的分詞詞頻要至少有一個(gè) >=2 。
更多參數(shù)建議參考官方文檔,不再贅述。
8、Elasticsearch 相似推薦其他的實(shí)現(xiàn)方案
在第 6 部分提及,more like this 并沒有實(shí)現(xiàn)完全的相關(guān)度推薦,出現(xiàn)了“噪音” 數(shù)據(jù)。
所以,實(shí)戰(zhàn)環(huán)節(jié)使用 more like this 多半基于燃眉之急。
如果想深入的實(shí)現(xiàn)相似度推薦,推薦方案:
基于類似 simhash 的方式,給每個(gè)文檔打上 hash 值,基于海明距離實(shí)現(xiàn)相似度推薦。
如果想再深入就需要借助:
基于協(xié)同過濾的推薦算法、基于關(guān)聯(lián)規(guī)則的推薦算法、基于知識(shí)的推理算法或者組合推理算法實(shí)現(xiàn)。
9、小結(jié)
本文介紹了 Elasticsearch 中實(shí)現(xiàn)相似推薦的 More Like This 檢索方法、實(shí)現(xiàn)原理、案例解讀。
目的是給大家業(yè)務(wù)系統(tǒng)實(shí)現(xiàn)相似推薦提供了理論和實(shí)踐支撐。
大家實(shí)戰(zhàn)環(huán)節(jié)如何實(shí)現(xiàn)的相似推薦呢?歡迎留言討論細(xì)節(jié)。
參考
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-mlt-query.html
https://spoon-elastic.com/all-elastic-search-post/more-like-this-query-mlt-suggest-similar-content-with-elasticsearch/
https://qbox.io/blog/mlt-similar-documents-in-elasticsearch-more-like-this-query/
https://spoon-elastic.com/all-elastic-search-post/more-like-this-query-mlt-suggest-similar-content-with-elasticsearch/
https://newbedev.com/elasticsearch-more-like-this-query
https://www.linkedin.com/pulse/finding-similar-documents-elasticsearch-morelikethis-fl%C3%A1vio-knob?articleId=6657988773374111744
《Lucene 原理與代碼分析》
推薦
更短時(shí)間更快習(xí)得更多干貨!
已帶領(lǐng)70位球友通過 Elastic 官方認(rèn)證!
中國僅通過百余人
