
【干貨】機(jī)器學(xué)習(xí)模型訓(xùn)練全流程!
點(diǎn)擊上方“AI算法與圖像處理”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
Datawhale干貨??
譯者:張峰,安徽工業(yè)大學(xué),Datawhale成員
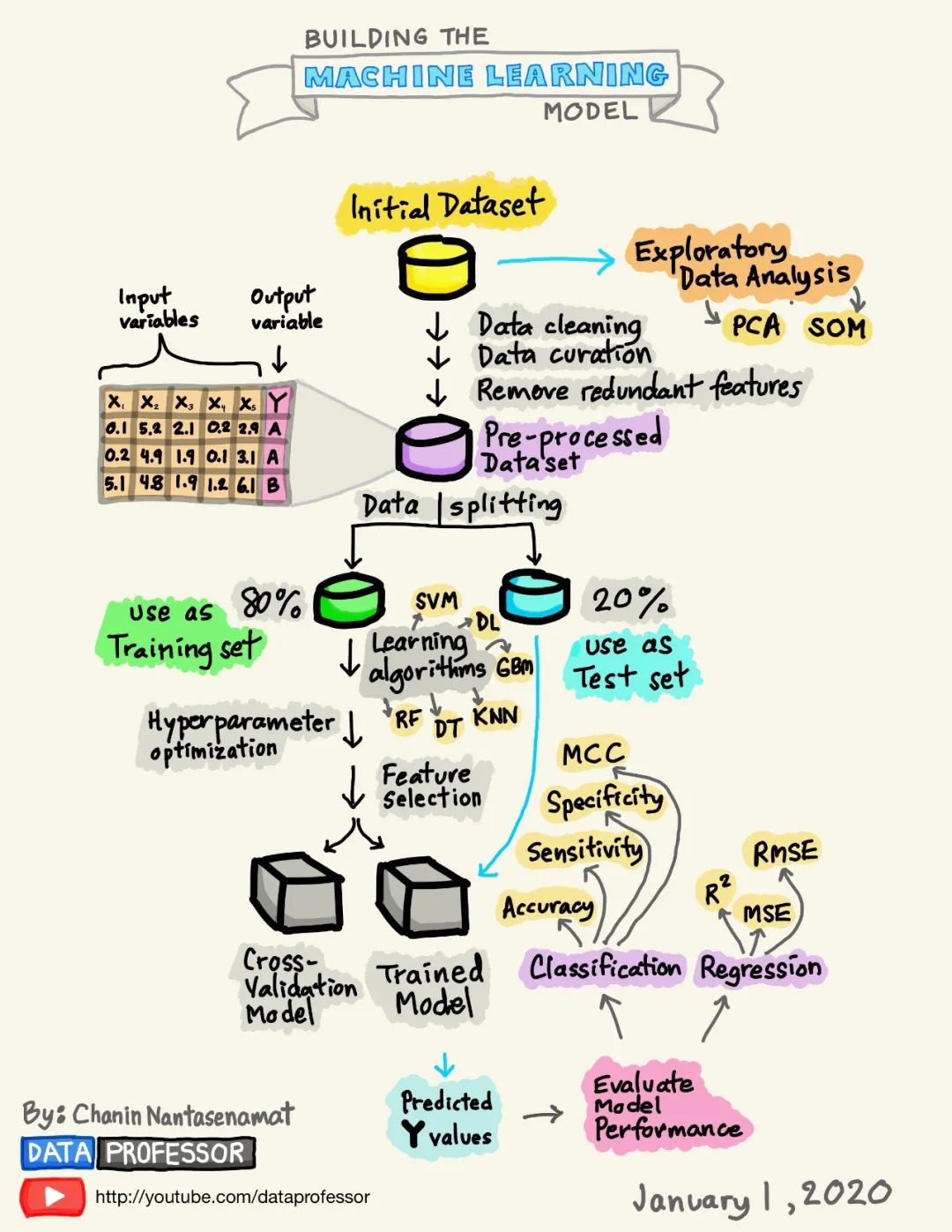
?
地址:https://github.com/dataprofessor/infographic
全文如下:
1. 數(shù)據(jù)集
列可以分解為X和Y,首先,X是幾個(gè)類似術(shù)語(yǔ)的同義詞,如特征、獨(dú)立變量和輸入變量。其次,Y也是幾個(gè)術(shù)語(yǔ)的同義詞,即類別標(biāo)簽、因變量和輸出變量。

圖1. 數(shù)據(jù)集的卡通插圖
?
應(yīng)該注意的是,一個(gè)可以用于監(jiān)督學(xué)習(xí)的數(shù)據(jù)集(可以執(zhí)行回歸或分類)將同時(shí)包含X和Y,而一個(gè)可以用于無監(jiān)督學(xué)習(xí)的數(shù)據(jù)集將只有X。
此外,如果Y包含定量值,那么數(shù)據(jù)集(由X和Y組成)可以用于回歸任務(wù),而如果Y包含定性值,那么數(shù)據(jù)集(由X和Y組成)可以用于分類任務(wù)。
?
2. 探索性數(shù)據(jù)分析(EDA)
進(jìn)行探索性數(shù)據(jù)分析(EDA)是為了獲得對(duì)數(shù)據(jù)的初步了解。在一個(gè)典型的數(shù)據(jù)科學(xué)項(xiàng)目中,我會(huì)做的第一件事就是通過執(zhí)行EDA來 "盯住數(shù)據(jù)",以便更好地了解數(shù)據(jù)。
我通常使用的三大EDA方法包括:
描述性統(tǒng)計(jì):平均數(shù)、中位數(shù)、模式、標(biāo)準(zhǔn)差。
數(shù)據(jù)可視化:熱力圖(辨別特征內(nèi)部相關(guān)性)、箱形圖(可視化群體差異)、散點(diǎn)圖(可視化特征之間的相關(guān)性)、主成分分析(可視化數(shù)據(jù)集中呈現(xiàn)的聚類分布)等。
數(shù)據(jù)整形:對(duì)數(shù)據(jù)進(jìn)行透視、分組、過濾等。
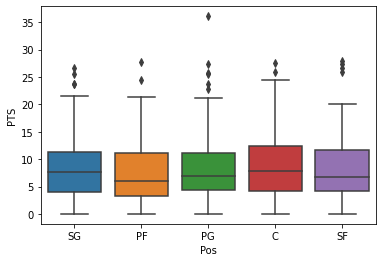
圖2. NBA球員統(tǒng)計(jì)數(shù)據(jù)的箱形圖示例
?
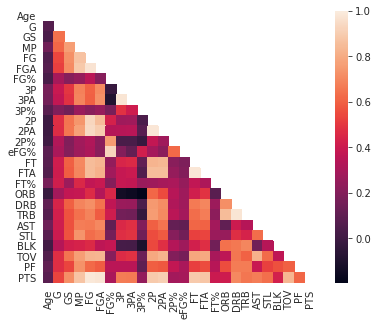
圖3. NBA球員統(tǒng)計(jì)數(shù)據(jù)的相關(guān)熱力圖示例
?

圖4. NBA球員統(tǒng)計(jì)數(shù)據(jù)的直方圖示例
?

圖5. NBA球員統(tǒng)計(jì)數(shù)據(jù)的散布圖示例
?
3. 數(shù)據(jù)預(yù)處理
數(shù)據(jù)預(yù)處理(又稱數(shù)據(jù)清理、數(shù)據(jù)整理或數(shù)據(jù)處理)是指對(duì)數(shù)據(jù)進(jìn)行各種檢查和審查的過程,以糾正缺失值、拼寫錯(cuò)誤、使數(shù)值正常化/標(biāo)準(zhǔn)化以使其具有可比性、轉(zhuǎn)換數(shù)據(jù)(如對(duì)數(shù)轉(zhuǎn)換)等問題。
正如上面的引言所說,數(shù)據(jù)的質(zhì)量將對(duì)生成模型的質(zhì)量產(chǎn)生很大的影響。因此,為了達(dá)到最高的模型質(zhì)量,應(yīng)該在數(shù)據(jù)預(yù)處理階段花費(fèi)大量精力。一般來說,數(shù)據(jù)預(yù)處理可以輕松地占到數(shù)據(jù)科學(xué)項(xiàng)目所花費(fèi)時(shí)間的80%,而實(shí)際的模型建立階段和后續(xù)的模型分析僅占到剩余的20%。
?
4. 數(shù)據(jù)分割
4.1 訓(xùn)練--測(cè)試集分割
接下來,利用訓(xùn)練集建立預(yù)測(cè)模型,然后將這種訓(xùn)練好的模型應(yīng)用于測(cè)試集(即作為新的、未見過的數(shù)據(jù))上進(jìn)行預(yù)測(cè)。根據(jù)模型在測(cè)試集上的表現(xiàn)來選擇最佳模型,為了獲得最佳模型,還可以進(jìn)行超參數(shù)優(yōu)化。
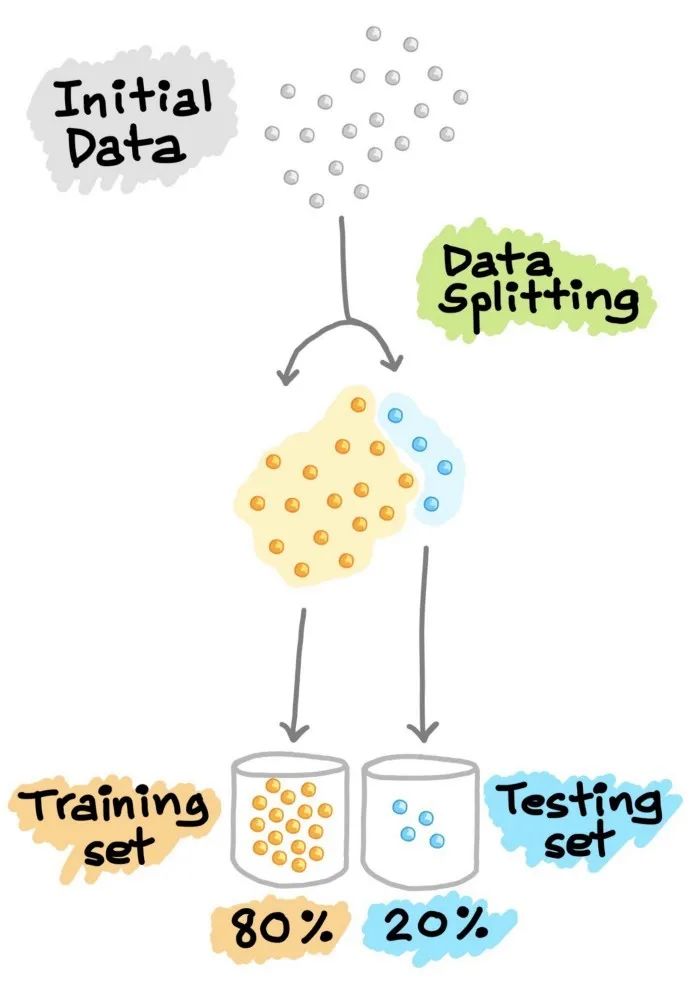
圖6. 訓(xùn)練—測(cè)試集分割示意圖
4.2 訓(xùn)練--驗(yàn)證--測(cè)試集分割
另一種常見的數(shù)據(jù)分割方法是將數(shù)據(jù)分割成3部分。(1) 訓(xùn)練集,(2) 驗(yàn)證集和(3) 測(cè)試集。與上面解釋的類似,訓(xùn)練集用于建立預(yù)測(cè)模型,同時(shí)對(duì)驗(yàn)證集進(jìn)行評(píng)估,據(jù)此進(jìn)行預(yù)測(cè),可以進(jìn)行模型調(diào)優(yōu)(如超參數(shù)優(yōu)化),并根據(jù)驗(yàn)證集的結(jié)果選擇性能最好的模型。正如我們所看到的,類似于上面對(duì)測(cè)試集進(jìn)行的操作,這里我們?cè)隍?yàn)證集上做同樣的操作。請(qǐng)注意,測(cè)試集不參與任何模型的建立和準(zhǔn)備。因此,測(cè)試集可以真正充當(dāng)新的、未知的數(shù)據(jù)。Google的《機(jī)器學(xué)習(xí)速成班》對(duì)這個(gè)話題進(jìn)行了更深入的處理。
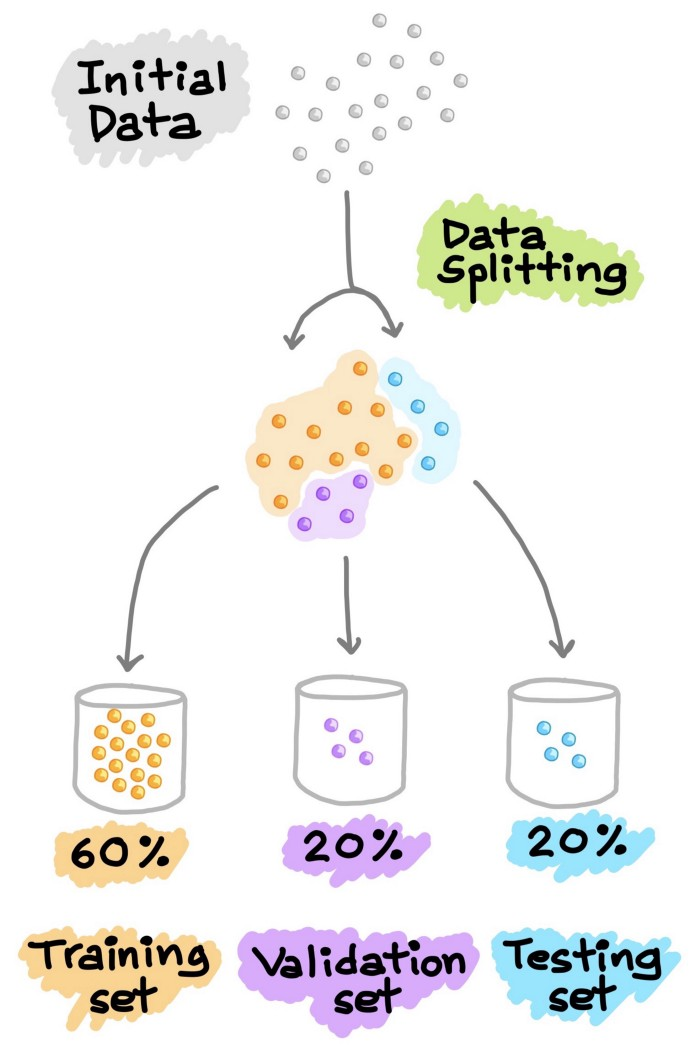
圖7. 訓(xùn)練—驗(yàn)證—測(cè)試集分割示意圖
4.3 交叉驗(yàn)證
例如,在5倍CV中,有1個(gè)折被省略,作為測(cè)試數(shù)據(jù),而剩下的4個(gè)被集中起來,作為建立模型的訓(xùn)練數(shù)據(jù)。然后,將訓(xùn)練好的模型應(yīng)用于上述遺漏的折(即測(cè)試數(shù)據(jù))。這個(gè)過程反復(fù)進(jìn)行,直到所有的折都有機(jī)會(huì)被留出作為測(cè)試數(shù)據(jù)。因此,我們將建立5個(gè)模型(即5個(gè)折中的每個(gè)折都被留出作為測(cè)試集),其中5個(gè)模型中的每個(gè)模型都包含相關(guān)的性能指標(biāo)(我們將在接下來的部分討論)。最后,度量(指標(biāo))值是基于5個(gè)模型計(jì)算出的平均性能。

圖8. 交叉驗(yàn)證示意圖
?
在N等于數(shù)據(jù)樣本數(shù)的情況下,我們稱這種留一的交叉驗(yàn)證。在這種類型的CV中,每個(gè)數(shù)據(jù)樣本代表一個(gè)折。例如,如果N等于30,那么就有30個(gè)折(每個(gè)折有1個(gè)樣本)。在任何其他N折CV中,1個(gè)折點(diǎn)被留出作為測(cè)試集,而剩下的29個(gè)折點(diǎn)被用來建立模型。接下來,將建立的模型應(yīng)用于對(duì)留出的折進(jìn)行預(yù)測(cè)。與之前一樣,這個(gè)過程反復(fù)進(jìn)行,共30次;計(jì)算30個(gè)模型的平均性能,并將其作為CV性能指標(biāo)。
5. 模型建立
現(xiàn)在,有趣的部分來了,我們終于可以使用精心準(zhǔn)備的數(shù)據(jù)來建立模型了。根據(jù)目標(biāo)變量(通常稱為Y變量)的數(shù)據(jù)類型(定性或定量),我們要建立一個(gè)分類(如果Y是定性的)或回歸(如果Y是定量的)模型。
5.1 學(xué)習(xí)算法
機(jī)器學(xué)習(xí)算法可以大致分為以下三種類型之一:
監(jiān)督學(xué)習(xí):是一種機(jī)器學(xué)習(xí)任務(wù),建立輸入X和輸出Y變量之間的數(shù)學(xué)(映射)關(guān)系。這樣的X、Y對(duì)構(gòu)成了用于建立模型的標(biāo)簽數(shù)據(jù),以便學(xué)習(xí)如何從輸入中預(yù)測(cè)輸出。
無監(jiān)督學(xué)習(xí):是一種只利用輸入X變量的機(jī)器學(xué)習(xí)任務(wù)。這種 X 變量是未標(biāo)記的數(shù)據(jù),學(xué)習(xí)算法在建模時(shí)使用的是數(shù)據(jù)的固有結(jié)構(gòu)。
強(qiáng)化學(xué)習(xí):是一種決定下一步行動(dòng)方案的機(jī)器學(xué)習(xí)任務(wù),它通過試錯(cuò)學(xué)習(xí)來實(shí)現(xiàn)這一目標(biāo),努力使回報(bào)最大化。
5.2 參數(shù)調(diào)優(yōu)
超參數(shù)本質(zhì)上是機(jī)器學(xué)習(xí)算法的參數(shù),直接影響學(xué)習(xí)過程和預(yù)測(cè)性能。由于沒有 "一刀切 "的超參數(shù)設(shè)置,可以普遍適用于所有數(shù)據(jù)集,因此需要進(jìn)行超參數(shù)優(yōu)化(也稱為超參數(shù)調(diào)整或模型調(diào)整)。
地址:https://pubs.acs.org/doi/10.1021/ci500344v
5.3 特征選擇
顧名思義,特征選擇從字面上看就是從最初的大量特征中選擇一個(gè)特征子集的過程。除了實(shí)現(xiàn)高精度的模型外,機(jī)器學(xué)習(xí)模型構(gòu)建最重要的一個(gè)方面是獲得可操作的見解,為了實(shí)現(xiàn)這一目標(biāo),能夠從大量的特征中選擇出重要的特征子集非常重要。
我們自己的研究小組也在對(duì)醛糖還原酶抑制劑的定量結(jié)構(gòu)—活性關(guān)系建模的研究中,探索了利用蒙特卡洛模擬進(jìn)行特征選擇的方法(Nantasenamat等,2014)。
在《遺傳算法搜索空間拼接粒子群優(yōu)化作為通用優(yōu)化器》的工作中,我們還設(shè)計(jì)了一種基于結(jié)合兩種流行的進(jìn)化算法即遺傳算法和粒子群算法的新型特征選擇方法(Li等,2013)。
地址:https://doi.org/10.1016/j.chemolab.2013.08.009
?
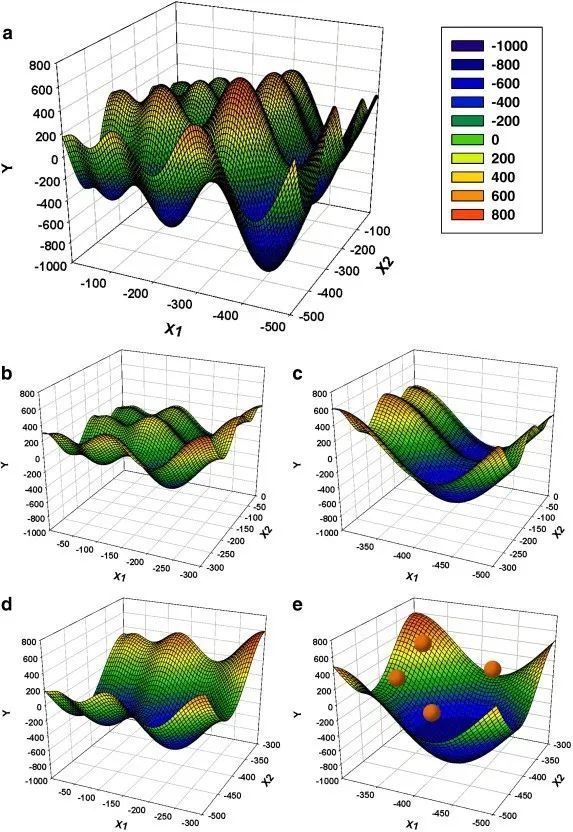
"原搜索空間(a)x∈[-500,0]在每個(gè)維度上以2的固定間隔拼接成子空間(圖中一個(gè)維度等于一個(gè)橫軸)。這樣就得到了4個(gè)子空間(b-e),其中x在每個(gè)維度上的范圍是原始空間的一半。GA的每一個(gè)字符串都會(huì)編碼一個(gè)子空間的索引。然后,GA啟發(fā)式地選擇一個(gè)子空間(e),并在那里啟動(dòng)PSO(粒子顯示為紅點(diǎn))。PSO搜索子空間的全局最小值,最好的粒子適應(yīng)性作為編碼該子空間索引的GA字符串的適應(yīng)性。最后,GA進(jìn)行進(jìn)化,選擇一個(gè)新的子空間進(jìn)行探索。整個(gè)過程重復(fù)進(jìn)行,直到達(dá)到滿意的誤差水平。"
6. 機(jī)器學(xué)習(xí)任務(wù)
在監(jiān)督學(xué)習(xí)中,兩個(gè)常見的機(jī)器學(xué)習(xí)任務(wù)包括分類和回歸。
6.1 分類
?一個(gè)訓(xùn)練有素的分類模型將一組變量(定量或定性)作為輸入,并預(yù)測(cè)輸出的類標(biāo)簽(定性)。下圖是由不同顏色和標(biāo)簽表示的三個(gè)類。每一個(gè)小的彩色球體代表一個(gè)數(shù)據(jù)樣本。

三類數(shù)據(jù)樣本在二維中的顯示。上圖顯示的是數(shù)據(jù)樣本的假設(shè)分布。這種可視化圖可以通過執(zhí)行PCA分析并顯示前兩個(gè)主成分(PC)來創(chuàng)建;或者也可以選擇兩個(gè)變量的簡(jiǎn)單散點(diǎn)圖可視化。
6.1.1 樣例數(shù)據(jù)集
以企鵝數(shù)據(jù)集(Penguins Dataset)為例(最近提出作為大量使用的Iris數(shù)據(jù)集的替代數(shù)據(jù)集),我們將定量(喙長(zhǎng)、喙深、鰭長(zhǎng)和身體質(zhì)量)和定性(性別和島嶼)特征作為輸入,這些特征唯一地描述了企鵝的特征,并將其歸入三個(gè)物種類別標(biāo)簽(Adelie、Chinstrap或Gentoo)之一。該數(shù)據(jù)集由344行和8列組成。之前的分析顯示,該數(shù)據(jù)集包含333個(gè)完整的案例,其中11個(gè)不完整的案例中出現(xiàn)了19個(gè)缺失值。

圖11. 三個(gè)企鵝物種的類別標(biāo)簽(Chinstrap、Gentoo和Adelie)
6.1.2 性能指標(biāo)
如何知道我們的模型表現(xiàn)好或壞?答案是使用性能指標(biāo),一些常見的評(píng)估分類性能的指標(biāo)包括準(zhǔn)確率(Ac)、靈敏度(Sn)、特異性(Sp)和馬太相關(guān)系數(shù)(MCC)。




?其中TP、TN、FP和FN分別表示真陽(yáng)性、真陰性、假陽(yáng)性和假陰性的實(shí)例。應(yīng)該注意的是,MCC的范圍從-1到1,其中MCC為-1表示最壞的可能預(yù)測(cè),而值為1表示最好的可能預(yù)測(cè)方案。此外,MCC為0表示隨機(jī)預(yù)測(cè)。
6.2 回歸
圖12. 實(shí)際值與預(yù)測(cè)值的簡(jiǎn)單散點(diǎn)圖
6.2.1 樣例數(shù)據(jù)集

?在14列中,前13個(gè)變量被用作輸入變量,而房?jī)r(jià)中位數(shù)(medv)被用作輸出變量。可以看出,所有14個(gè)變量都包含了量化的數(shù)值,因此適合進(jìn)行回歸分析。我還在YouTube上做了一個(gè)逐步演示如何用Python建立線性回歸模型的視頻。
在視頻中,我首先向大家展示了如何讀取波士頓房屋數(shù)據(jù)集,將數(shù)據(jù)分離為X和Y矩陣,進(jìn)行80/20的數(shù)據(jù)拆分,利用80%的子集建立線性回歸模型,并應(yīng)用訓(xùn)練好的模型對(duì)20%的子集進(jìn)行預(yù)測(cè)。最后顯示了實(shí)際與預(yù)測(cè)medv值的性能指標(biāo)和散點(diǎn)圖。
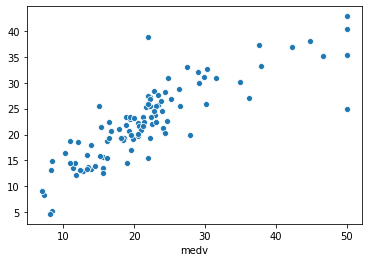
圖13. 測(cè)試集的實(shí)際medv值與預(yù)測(cè)medv值(20%子集)的散點(diǎn)圖。
6.2.2 性能指標(biāo)?
對(duì)回歸模型的性能進(jìn)行評(píng)估,以評(píng)估擬合模型可以準(zhǔn)確預(yù)測(cè)輸入數(shù)據(jù)值的程度。
評(píng)估回歸模型性能的常用指標(biāo)是確定系數(shù)(R2)。
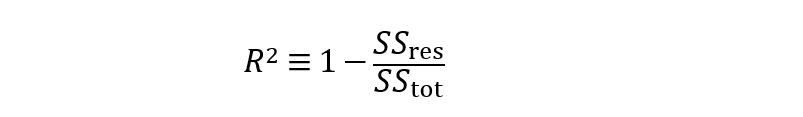
此外,均方誤差(MSE)以及均方根誤差(RMSE)也是衡量殘差或預(yù)測(cè)誤差的常用指標(biāo)。
? ? ??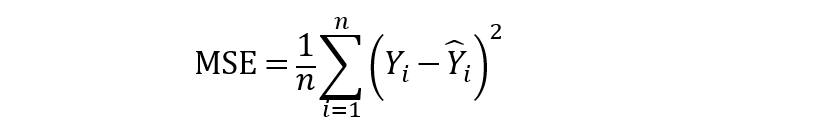
從上面的公式可以看出,MSE顧名思義是很容易計(jì)算的,取平方誤差的平均值。此外,MSE的簡(jiǎn)單平方根可以得到RMSE。
7. 分類任務(wù)的直觀說明
現(xiàn)在我們?cè)賮砜纯捶诸惸P偷恼麄€(gè)過程。以企鵝數(shù)據(jù)集為例,我們可以看到,企鵝可以通過4個(gè)定量特征和2個(gè)定性特征來描述,然后將這些特征作為訓(xùn)練分類模型的輸入。在訓(xùn)練模型的過程中,需要考慮的問題包括以下幾點(diǎn)。
使用什么機(jī)器學(xué)習(xí)算法?
應(yīng)該探索什么樣的搜索空間進(jìn)行超參數(shù)優(yōu)化?
使用哪種數(shù)據(jù)分割方案?80/20分割還是60/20/20分割?還是10倍CV?
除了只進(jìn)行分類建模,我們還可以進(jìn)行主成分分析(PCA),這將只利用X(獨(dú)立)變量來辨別數(shù)據(jù)的底層結(jié)構(gòu),并在這樣做的過程中允許將固有的數(shù)據(jù)簇可視化(如下圖所示為一個(gè)假設(shè)圖,其中簇根據(jù)3種企鵝物種進(jìn)行了顏色編碼)。
圖14. 建立一個(gè)分類模型的過程示意圖

個(gè)人微信(如果沒有備注不拉群!) 請(qǐng)注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
