PRGC:一種新的聯(lián)合關(guān)系抽取模型

點(diǎn)擊藍(lán)字關(guān)注NLP論文精選
?NLP論文解讀?原創(chuàng)?作者?| 小欣
論文標(biāo)題:PRGC: Potential Relation and Global Correspondence Based Joint
Relational Triple Extraction
論文鏈接:https://arxiv.org/pdf/2106.09895.pdf
代碼:https://github.com/hy-struggle/PRGC
 前言
前言
1. 論文的相關(guān)背景
關(guān)系抽取是信息抽取和知識圖譜構(gòu)建的關(guān)鍵任務(wù)之一,它的目標(biāo)是從非結(jié)構(gòu)化的文本中抽取形如<頭實體,關(guān)系,尾實體>的三元組數(shù)據(jù)。通常使用Pipeline方法進(jìn)行抽取:先對句子進(jìn)行實體識別,然后對識別出的實體兩兩組合進(jìn)行關(guān)系分類,最后把存在關(guān)系的實體對輸出為三元組。但這樣的做法存在以下缺點(diǎn):1. 誤差積累,實體識別模塊的錯誤會影響下面的關(guān)系分類性能。2. 實體冗余:沒有關(guān)系的實體對會帶來多余信息,提升錯誤率,同時降低整個抽取流程的效率。3. 信息利用不充分:Pipeline方法中兩個子任務(wù)相對獨(dú)立,無法有效利用兩個子任務(wù)的內(nèi)在聯(lián)系和依賴關(guān)系。為了緩解Pipeline方法存在的一些問題,聯(lián)合關(guān)系抽取模型應(yīng)運(yùn)而生。聯(lián)合關(guān)系抽取模型的設(shè)計目的是希望進(jìn)一步利用兩個任務(wù)之間的潛在信息,加強(qiáng)實體識別模型和關(guān)系分類模型之間的交互。早期的聯(lián)合關(guān)系抽取模型通過模型參數(shù)共享、多任務(wù)和關(guān)系信息融入序列標(biāo)注等方法進(jìn)行聯(lián)合抽取,但取得的效果并不盡如人意。隨著CasRel、TPLinker等一系列聯(lián)合解碼模型的提出,聯(lián)合關(guān)系抽取模型開始取得SOTA的效果。
2. 論文主要解決的問題
3. 論文的主要創(chuàng)新和貢獻(xiàn)
通過將關(guān)系抽取拆解為關(guān)系判斷、實體提取和主客實體對?三個子任務(wù),定義了一種新的關(guān)系抽取模型方法 有助于緩解CasRel、TPLinker等模型存在的關(guān)系冗余、主客實體對齊效率低等問題
 論文摘要
論文摘要
 論文模型
論文模型
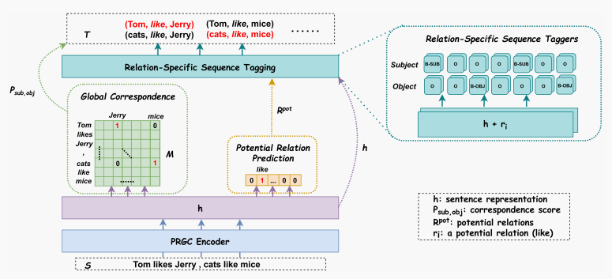
3.1 Relation Judgement
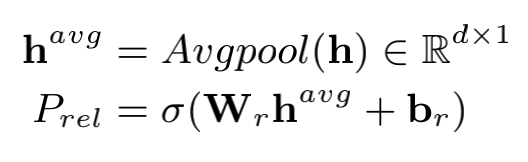
# (bs, h)
h_k_avg = self.masked_avgpool(sequence_output, attention_mask)
# (bs, rel_num)
rel_pred = self.rel_judgement(h_k_avg)
loss_func = nn.BCEWithLogitsLoss(reduction='mean')
loss_rel = loss_func(rel_pred, rel_tags.float())
在預(yù)測階段,通過sigmoid函數(shù)獲取句子對應(yīng)的所有關(guān)系標(biāo)簽的概率,并結(jié)合預(yù)先設(shè)定的概率閾值獲取句子蘊(yùn)含的關(guān)系標(biāo)簽。
# (bs, rel_num)
rel_pred_onehot = torch.where(
torch.sigmoid(rel_pred) > rel_threshold,
torch.ones(rel_pred.size(), device=rel_pred.device),
torch.zeros(rel_pred.size(), device=rel_pred.device)
)
3.2 Entity Extraction
實體抽取模塊與一般的序列標(biāo)注任務(wù)的不同在于:輸入的向量是融合了關(guān)系信息的句子向量。作者提供了兩種融合方式,一種是直接拼接兩個向量,另一種是通過向量相加進(jìn)行融合。此外,實體抽取模塊會將主體實體抽取和客體實體抽取分開進(jìn)行抽取
if ex_params['emb_fusion'] == 'concat':
decode_input = torch.cat([sequence_output, rel_emb], dim=-1)
# sequence_tagging_sub就是個普通的序列標(biāo)注模塊
output_sub = self.sequence_tagging_sub(decode_input)
output_obj = self.sequence_tagging_obj(decode_input)
elif ex_params['emb_fusion'] == 'sum':
decode_input = sequence_output + rel_emb
# sequence_tagging_sum里面主客實體抽取也是分開進(jìn)行的
output_sub, output_obj = self.sequence_tagging_sum(decode_input)
3.3 Subject-object Alignment
主客實體對齊模塊本質(zhì)上就是生成字符與字符的相關(guān)矩陣。
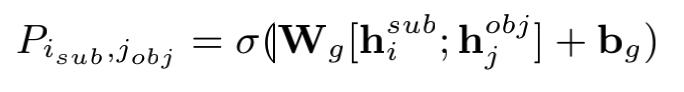
代碼實現(xiàn)
# batch x seq_len x seq_len x 2*hidden
corres_pred = torch.cat([sub_extend, obj_extend], 3)
# (bs, seq_len, seq_len)
corres_pred = self.global_corres(corres_pred).squeeze(-1)
# global_corres的類代碼
class MultiNonLinearClassifier(nn.Module):
def __init__(self, hidden_size, tag_size, dropout_rate):
super(MultiNonLinearClassifier, self).__init__()
self.tag_size = tag_size
self.linear = nn.Linear(hidden_size, int(hidden_size / 2))
self.hidden2tag = nn.Linear(int(hidden_size / 2), self.tag_size)
self.dropout = nn.Dropout(dropout_rate)
def forward(self, input_features):
features_tmp = self.linear(input_features)
features_tmp = nn.ReLU()(features_tmp)
features_tmp = self.dropout(features_tmp)
features_output = self.hidden2tag(features_tmp)
return features_output
由于采用了拼接向量后通過全連接生成對齊矩陣,故而會占用較多的顯存。筆者在這部分嘗試了使用biffine機(jī)制進(jìn)行向量的交叉融合,可以在不降低性能的情況下有效地節(jié)約顯存。
3.4 Loss Function
PRGC的損失采用了三個子任務(wù)加權(quán)的形式,本質(zhì)上都是交叉熵,只是針對不同維度進(jìn)行了處理。作者在論文中并未詳細(xì)討論不同的加權(quán)方式對模型的影響,在代碼實現(xiàn)中也是采用了常規(guī)的三個損失直接相加的結(jié)構(gòu)。筆者認(rèn)為由于三個損失的收斂情況不同,可以嘗試根據(jù)訓(xùn)練輪數(shù)動態(tài)調(diào)整三個損失之間的加權(quán)關(guān)系。
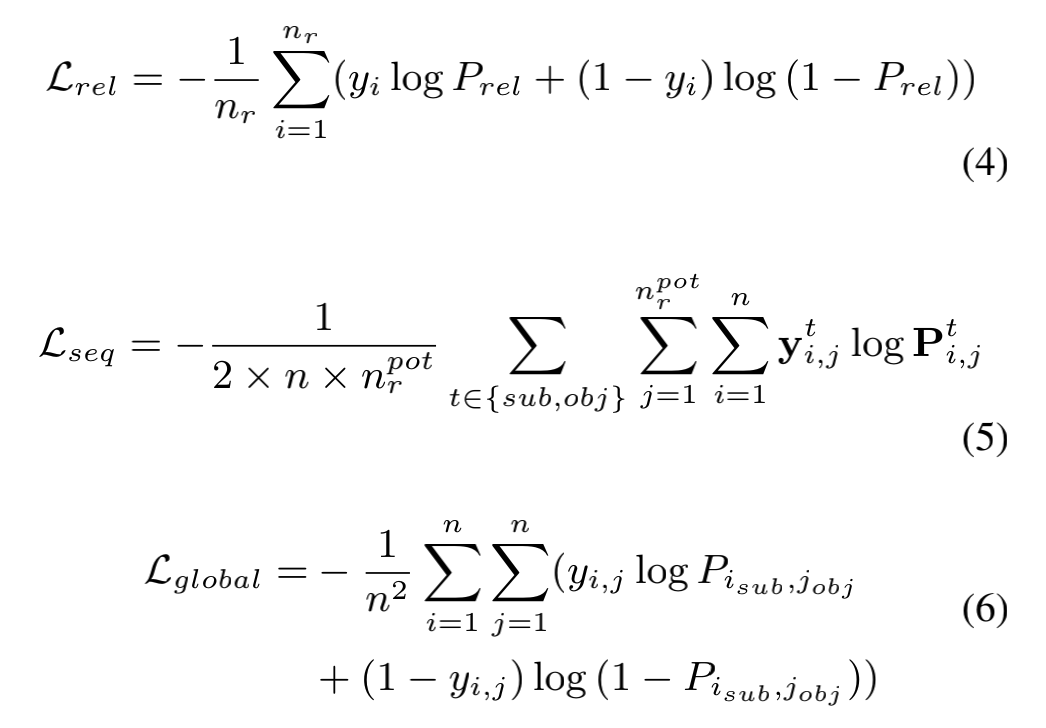
 論文實驗
論文實驗
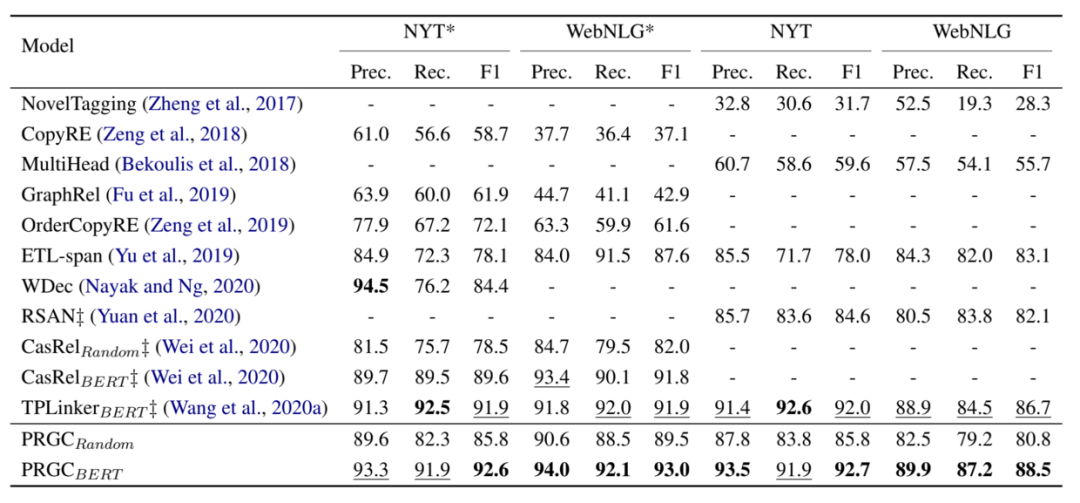
PRGC主要在NYT和WebNLG上進(jìn)行實驗,NYT和WebNLG都有兩個版本,一個版本是標(biāo)注出整個實體,另一個版本是僅標(biāo)注出實體的最后一個字符,作者將僅標(biāo)注出實體的最后一個字符的版本記為NYT*和WebNLG*。如下例中實體North Carolina在NYT中是整體標(biāo)出的,而在NYT*中則是僅標(biāo)出Carolina。
NYT的數(shù)據(jù)格式:
{
"text": "North Carolina EASTERN MUSIC FESTIVAL Greensboro , June 25-July 30 .",
"triple_list": [
[
"North Carolina",
"/location/location/contains",
"Greensboro"
]
]
}
NYT*的數(shù)據(jù)格式:
{
"text": "North Carolina EASTERN MUSIC FESTIVAL Greensboro , June 25-July 30 .",
"triple_list": [
[
"Carolina",
"/location/location/contains",
"Greensboro"
]
]
}
WebNLG的數(shù)據(jù)格式:
{
"text": "Alan Bean , who graduated in 1955 from UT Austin with a B.S . and was selected by NASA in 1963 , spent 100305.0 minutes in space .",
"triple_list": [
[
"Alan Bean",
"was selected by NASA",
"1963"
]
]
}
WebNLG*的數(shù)據(jù)格式:
{
"text": "Alan Bean , who graduated in 1955 from UT Austin with a B.S . and was selected by NASA in 1963 , spent 100305.0 minutes in space .",
"triple_list": [
[
"Bean",
"was selected by NASA",
"1963"
]
]
}
評價指標(biāo)采用了常見的精準(zhǔn)率(Prec.)、 召回率(Rec.)和F1-score。實驗結(jié)果如下圖,可以看出PRGC在四個數(shù)據(jù)上都取得了不錯的效果。
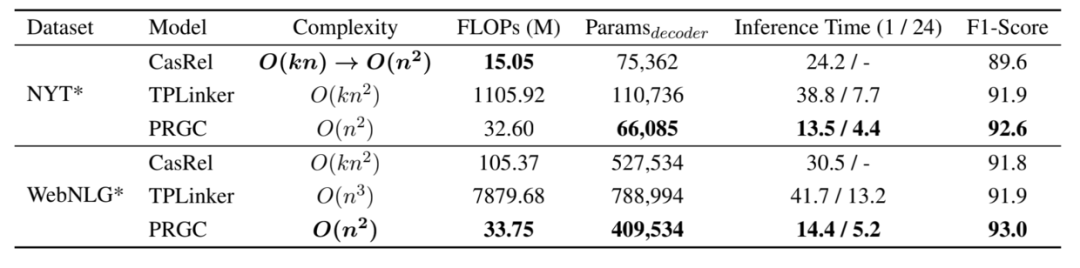
此外,作者還對PRGC的效率進(jìn)行了實驗,得益于PRGC可以通過關(guān)系判斷去除掉句子中不包含的關(guān)系標(biāo)簽和整個模型不存在過于復(fù)雜的解碼方式,PRGC在復(fù)雜度和推理速度上相比于CasRel和TPLinker都有明顯的優(yōu)勢:
記得點(diǎn)個在看喲