
Kafka面試題系列(進(jìn)階篇2)
點(diǎn)擊上方藍(lán)色字體,選擇“設(shè)為星標(biāo)”
回復(fù)”資源“獲取更多資源



Kafka中的事務(wù)是怎么實(shí)現(xiàn)的?
Kafka中的事務(wù)可以使應(yīng)用程序?qū)⑾M(fèi)消息、生產(chǎn)消息、提交消費(fèi)位移當(dāng)作原子操作來(lái)處理,同時(shí)成功或失敗,即使該生產(chǎn)或消費(fèi)會(huì)跨多個(gè)分區(qū)。
生產(chǎn)者必須提供唯一的transactionalId,啟動(dòng)后請(qǐng)求事務(wù)協(xié)調(diào)器獲取一個(gè)PID,transactionalId與PID一一對(duì)應(yīng)。
每次發(fā)送數(shù)據(jù)給
在處理完 AddOffsetsToTxnRequest 之后,生產(chǎn)者還會(huì)發(fā)送 TxnOffsetCommitRequest 請(qǐng)求給 GroupCoordinator,從而將本次事務(wù)中包含的消費(fèi)位移信息 offsets 存儲(chǔ)到主題 __consumer_offsets 中
一旦上述數(shù)據(jù)寫(xiě)入操作完成,應(yīng)用程序必須調(diào)用KafkaProducer的commitTransaction方法或者abortTransaction方法以結(jié)束當(dāng)前事務(wù)。無(wú)論調(diào)用 commitTransaction() 方法還是 abortTransaction() 方法,生產(chǎn)者都會(huì)向 TransactionCoordinator 發(fā)送 EndTxnRequest 請(qǐng)求。
TransactionCoordinator 在收到 EndTxnRequest 請(qǐng)求后會(huì)執(zhí)行如下操作:
將 PREPARE_COMMIT 或 PREPARE_ABORT 消息寫(xiě)入主題 __transaction_state
通過(guò) WriteTxnMarkersRequest 請(qǐng)求將 COMMIT 或 ABORT 信息寫(xiě)入用戶所使用的普通主題和 __consumer_offsets
將 COMPLETE_COMMIT 或 COMPLETE_ABORT 信息寫(xiě)入內(nèi)部主題 __transaction_state表明該事務(wù)結(jié)束
在消費(fèi)端有一個(gè)參數(shù)isolation.level,設(shè)置為“read_committed”,表示消費(fèi)端應(yīng)用不可以看到尚未提交的事務(wù)內(nèi)的消息。如果生產(chǎn)者開(kāi)啟事務(wù)并向某個(gè)分區(qū)值發(fā)送3條消息 msg1、msg2 和 msg3,在執(zhí)行 commitTransaction() 或 abortTransaction() 方法前,設(shè)置為“read_committed”的消費(fèi)端應(yīng)用是消費(fèi)不到這些消息的,不過(guò)在 KafkaConsumer 內(nèi)部會(huì)緩存這些消息,直到生產(chǎn)者執(zhí)行 commitTransaction() 方法之后它才能將這些消息推送給消費(fèi)端應(yīng)用。反之,如果生產(chǎn)者執(zhí)行了 abortTransaction() 方法,那么 KafkaConsumer 會(huì)將這些緩存的消息丟棄而不推送給消費(fèi)端應(yīng)用。
失效副本是指什么?有哪些應(yīng)對(duì)措施?
正常情況下,分區(qū)的所有副本都處于 ISR 集合中,但是難免會(huì)有異常情況發(fā)生,從而某些副本被剝離出 ISR 集合中。在 ISR 集合之外,也就是處于同步失效或功能失效(比如副本處于非存活狀態(tài))的副本統(tǒng)稱為失效副本,失效副本對(duì)應(yīng)的分區(qū)也就稱為同步失效分區(qū),即 under-replicated 分區(qū)。
Kafka 從 0.9.x 版本開(kāi)始就通過(guò)唯一的 broker 端參數(shù) replica.lag.time.max.ms 來(lái)抉擇,當(dāng) ISR 集合中的一個(gè) follower 副本滯后 leader 副本的時(shí)間超過(guò)此參數(shù)指定的值時(shí)則判定為同步失敗,需要將此 follower 副本剔除出 ISR 集合。replica.lag.time.max.ms 參數(shù)的默認(rèn)值為10000。
在 0.9.x 版本之前,Kafka 中還有另一個(gè)參數(shù) replica.lag.max.messages(默認(rèn)值為4000),它也是用來(lái)判定失效副本的,當(dāng)一個(gè) follower 副本滯后 leader 副本的消息數(shù)超過(guò) replica.lag.max.messages 的大小時(shí),則判定它處于同步失效的狀態(tài)。它與 replica.lag.time.max.ms 參數(shù)判定出的失效副本取并集組成一個(gè)失效副本的集合,從而進(jìn)一步剝離出分區(qū)的 ISR 集合。
Kafka 源碼注釋中說(shuō)明了一般有這幾種情況會(huì)導(dǎo)致副本失效:
follower 副本進(jìn)程卡住,在一段時(shí)間內(nèi)根本沒(méi)有向 leader 副本發(fā)起同步請(qǐng)求,比如頻繁的 Full GC。
follower 副本進(jìn)程同步過(guò)慢,在一段時(shí)間內(nèi)都無(wú)法追趕上 leader 副本,比如 I/O 開(kāi)銷過(guò)大。
如果通過(guò)工具增加了副本因子,那么新增加的副本在趕上 leader 副本之前也都是處于失效狀態(tài)的。
如果一個(gè) follower 副本由于某些原因(比如宕機(jī))而下線,之后又上線,在追趕上 leader 副本之前也處于失效狀態(tài)。
應(yīng)對(duì)措施
我們用UnderReplicatedPartitions代表leader副本在當(dāng)前Broker上且具有失效副本的分區(qū)的個(gè)數(shù)。
如果集群中有多個(gè)Broker的UnderReplicatedPartitions保持一個(gè)大于0的穩(wěn)定值時(shí),一般暗示著集群中有Broker已經(jīng)處于下線狀態(tài)。這種情況下,這個(gè)Broker中的分區(qū)個(gè)數(shù)與集群中的所有UnderReplicatedPartitions(處于下線的Broker是不會(huì)上報(bào)任何指標(biāo)值的)之和是相等的。通常這類問(wèn)題是由于機(jī)器硬件原因引起的,但也有可能是由于操作系統(tǒng)或者JVM引起的 。
如果集群中存在Broker的UnderReplicatedPartitions頻繁變動(dòng),或者處于一個(gè)穩(wěn)定的大于0的值(這里特指沒(méi)有Broker下線的情況)時(shí),一般暗示著集群出現(xiàn)了性能問(wèn)題,通常這類問(wèn)題很難診斷,不過(guò)我們可以一步一步的將問(wèn)題的范圍縮小,比如先嘗試確定這個(gè)性能問(wèn)題是否只存在于集群的某個(gè)Broker中,還是整個(gè)集群之上。如果確定集群中所有的under-replicated分區(qū)都是在單個(gè)Broker上,那么可以看出這個(gè)Broker出現(xiàn)了問(wèn)題,進(jìn)而可以針對(duì)這單一的Broker做專項(xiàng)調(diào)查,比如:操作系統(tǒng)、GC、網(wǎng)絡(luò)狀態(tài)或者磁盤狀態(tài)(比如:iowait、ioutil等指標(biāo))。
多副本下,各個(gè)副本中的HW和LEO的演變過(guò)程
某個(gè)分區(qū)有3個(gè)副本分別位于 broker0、broker1 和 broker2 節(jié)點(diǎn)中,假設(shè) broker0 上的副本1為當(dāng)前分區(qū)的 leader 副本,那么副本2和副本3就是 follower 副本,整個(gè)消息追加的過(guò)程可以概括如下:
生產(chǎn)者客戶端發(fā)送消息至 leader 副本(副本1)中。
消息被追加到 leader 副本的本地日志,并且會(huì)更新日志的偏移量。
follower 副本(副本2和副本3)向 leader 副本請(qǐng)求同步數(shù)據(jù)。
leader 副本所在的服務(wù)器讀取本地日志,并更新對(duì)應(yīng)拉取的 follower 副本的信息。
leader 副本所在的服務(wù)器將拉取結(jié)果返回給 follower 副本。
follower 副本收到 leader 副本返回的拉取結(jié)果,將消息追加到本地日志中,并更新日志的偏移量信息。
某一時(shí)刻,leader 副本的 LEO 增加至5,并且所有副本的 HW 還都為0。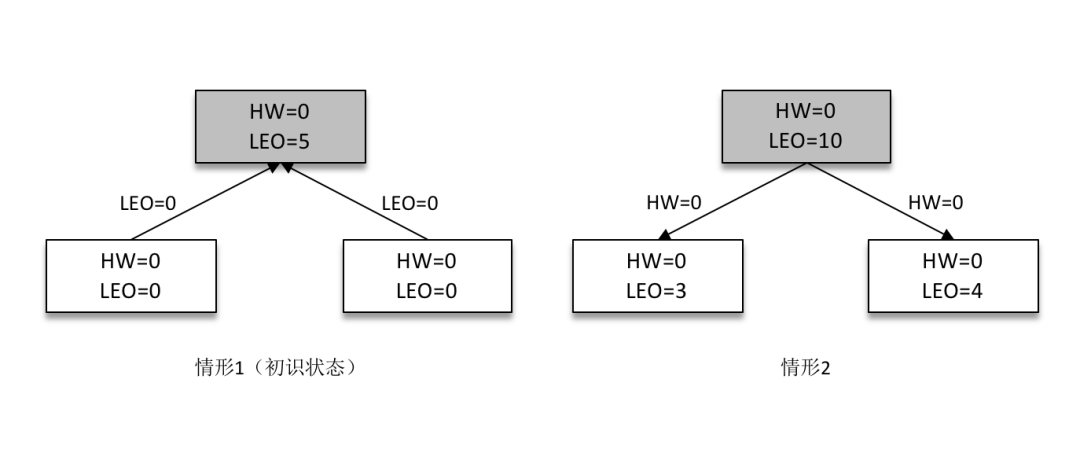
之后 follower 副本(不帶陰影的方框)向 leader 副本拉取消息,在拉取的請(qǐng)求中會(huì)帶有自身的 LEO 信息,這個(gè) LEO 信息對(duì)應(yīng)的是 FetchRequest 請(qǐng)求中的 fetch_offset。leader 副本返回給 follower 副本相應(yīng)的消息,并且還帶有自身的 HW 信息,如上圖(右)所示,這個(gè) HW 信息對(duì)應(yīng)的是 FetchResponse 中的 high_watermark。
此時(shí)兩個(gè) follower 副本各自拉取到了消息,并更新各自的 LEO 為3和4。與此同時(shí),follower 副本還會(huì)更新自己的 HW,更新 HW 的算法是比較當(dāng)前 LEO 和 leader 副本中傳送過(guò)來(lái)的HW的值,取較小值作為自己的 HW 值。當(dāng)前兩個(gè) follower 副本的 HW 都等于0(min(0,0) = 0)。
接下來(lái) follower 副本再次請(qǐng)求拉取 leader 副本中的消息,如下圖(左)所示。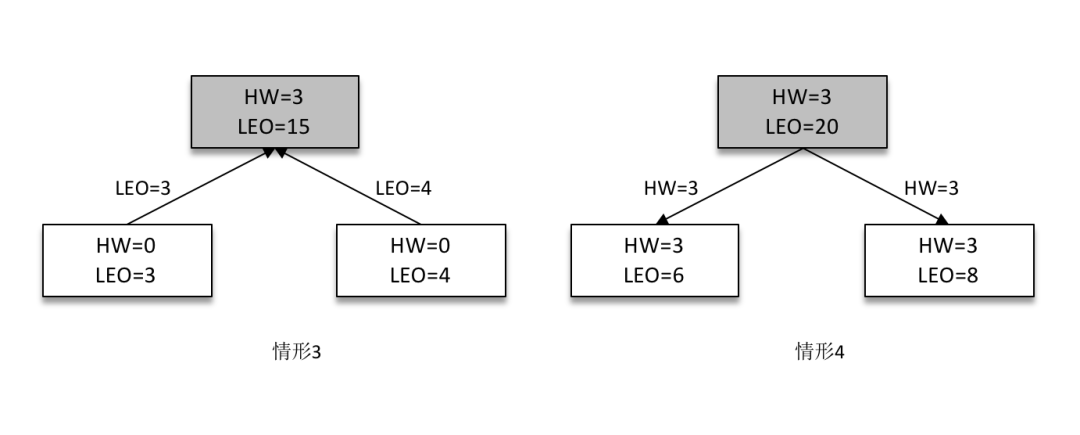
此時(shí) leader 副本收到來(lái)自 follower 副本的 FetchRequest 請(qǐng)求,其中帶有 LEO 的相關(guān)信息,選取其中的最小值作為新的 HW,即 min(15,3,4)=3。然后連同消息和 HW 一起返回 FetchResponse 給 follower 副本,如上圖(右)所示。注意 leader 副本的 HW 是一個(gè)很重要的東西,因?yàn)樗苯佑绊懥朔謪^(qū)數(shù)據(jù)對(duì)消費(fèi)者的可見(jiàn)性。
兩個(gè) follower 副本在收到新的消息之后更新 LEO 并且更新自己的 HW 為3(min(LEO,3)=3)。
Kafka在可靠性方面做了哪些改進(jìn)?(HW, LeaderEpoch)
HW
HW 是 High Watermark 的縮寫(xiě),俗稱高水位,它標(biāo)識(shí)了一個(gè)特定的消息偏移量(offset),消費(fèi)者只能拉取到這個(gè) offset 之前的消息。
分區(qū) ISR 集合中的每個(gè)副本都會(huì)維護(hù)自身的 LEO,而 ISR 集合中最小的 LEO 即為分區(qū)的 HW,對(duì)消費(fèi)者而言只能消費(fèi) HW 之前的消息。
leader epoch
leader epoch 代表 leader 的紀(jì)元信息(epoch),初始值為0。每當(dāng) leader 變更一次,leader epoch 的值就會(huì)加1,相當(dāng)于為 leader 增設(shè)了一個(gè)版本號(hào)。
每個(gè)副本中還會(huì)增設(shè)一個(gè)矢量
假設(shè)有兩個(gè)節(jié)點(diǎn)A和B,B是leader節(jié)點(diǎn),里面的數(shù)據(jù)如圖: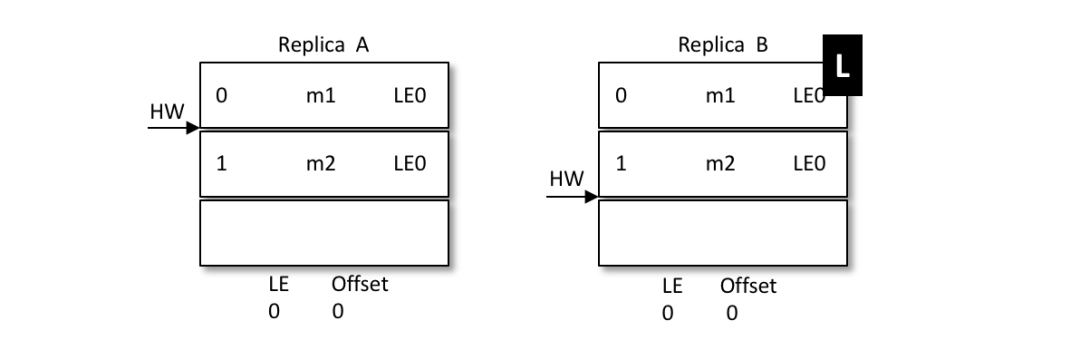
A發(fā)生重啟,之后A不是先忙著截?cái)嗳罩径窍劝l(fā)送OffsetsForLeaderEpochRequest請(qǐng)求給B,B作為目前的leader在收到請(qǐng)求之后會(huì)返回當(dāng)前的LEO(LogEndOffset,注意圖中LE0和LEO的不同),與請(qǐng)求對(duì)應(yīng)的響應(yīng)為OffsetsForLeaderEpochResponse。如果 A 中的 LeaderEpoch(假設(shè)為 LE_A)和 B 中的不相同,那么 B 此時(shí)會(huì)查找 LeaderEpoch 為 LE_A+1 對(duì)應(yīng)的 StartOffset 并返回給 A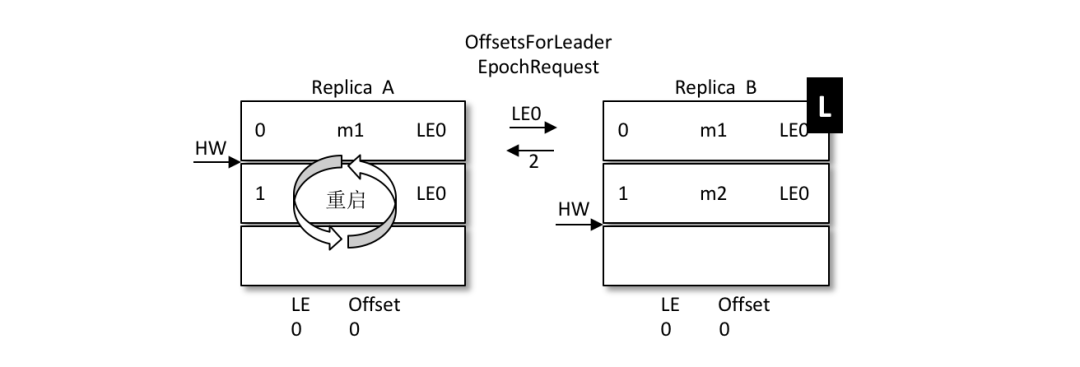
如上圖所示,A 在收到2之后發(fā)現(xiàn)和目前的 LEO 相同,也就不需要截?cái)嗳罩玖耍源藖?lái)保護(hù)數(shù)據(jù)的完整性。
再如,之后 B 發(fā)生了宕機(jī),A 成為新的 leader,那么對(duì)應(yīng)的 LE=0 也變成了 LE=1,對(duì)應(yīng)的消息 m2 此時(shí)就得到了保留。后續(xù)的消息都可以以 LE1 為 LeaderEpoch 陸續(xù)追加到 A 中。這個(gè)時(shí)候A就會(huì)有兩個(gè)LE,第二LE所記錄的Offset從2開(kāi)始。如果B恢復(fù)了,那么就會(huì)從A中獲取到LE+1的Offset為2的值返回給B。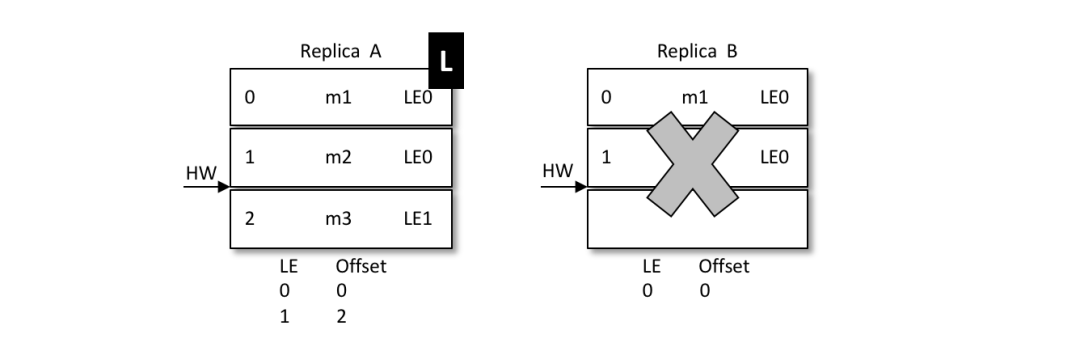
再來(lái)看看LE如何解決數(shù)據(jù)不一致的問(wèn)題:
當(dāng)前 A 為 leader,B 為 follower,A 中有2條消息 m1 和 m2,而 B 中有1條消息 m1。假設(shè) A 和 B 同時(shí)“掛掉”,然后 B 第一個(gè)恢復(fù)過(guò)來(lái)并成為新的 leader。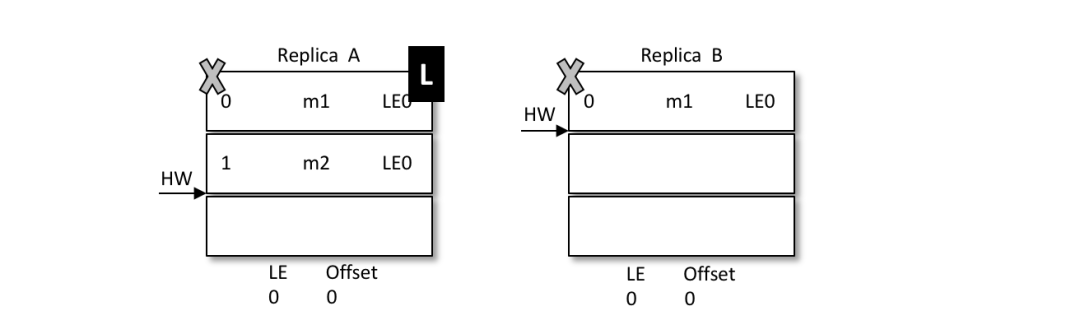
之后 B 寫(xiě)入消息 m3,并將 LEO 和 HW 更新至2,如下圖所示。注意此時(shí)的 LeaderEpoch 已經(jīng)從 LE0 增至 LE1 了。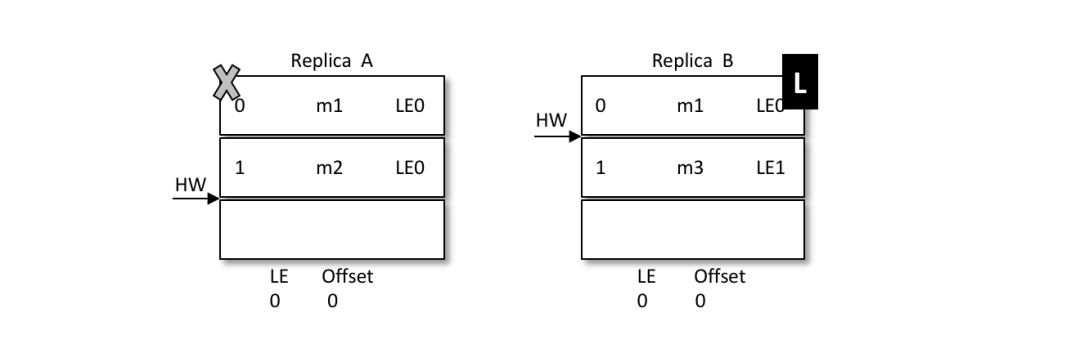
緊接著 A 也恢復(fù)過(guò)來(lái)成為 follower 并向 B 發(fā)送 OffsetsForLeaderEpochRequest 請(qǐng)求,此時(shí) A 的 LeaderEpoch 為 LE0。B 根據(jù) LE0 查詢到對(duì)應(yīng)的 offset 為1并返回給 A,A 就截?cái)嗳罩静h除了消息 m2,如下圖所示。之后 A 發(fā)送 FetchRequest 至 B 請(qǐng)求來(lái)同步數(shù)據(jù),最終A和B中都有兩條消息 m1 和 m3,HW 和 LEO都為2,并且 LeaderEpoch 都為 LE1,如此便解決了數(shù)據(jù)不一致的問(wèn)題。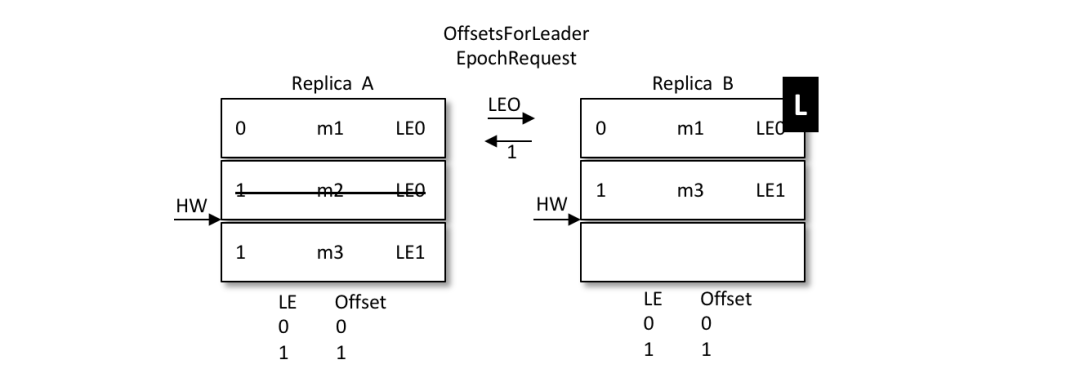
為什么Kafka不支持讀寫(xiě)分離?
因?yàn)檫@樣有兩個(gè)明顯的缺點(diǎn):
數(shù)據(jù)一致性問(wèn)題。數(shù)據(jù)從主節(jié)點(diǎn)轉(zhuǎn)到從節(jié)點(diǎn)必然會(huì)有一個(gè)延時(shí)的時(shí)間窗口,這個(gè)時(shí)間窗口會(huì)導(dǎo)致主從節(jié)點(diǎn)之間的數(shù)據(jù)不一致。
延時(shí)問(wèn)題。數(shù)據(jù)從寫(xiě)入主節(jié)點(diǎn)到同步至從節(jié)點(diǎn)中的過(guò)程需要經(jīng)歷網(wǎng)絡(luò)→主節(jié)點(diǎn)內(nèi)存→主節(jié)點(diǎn)磁盤→網(wǎng)絡(luò)→從節(jié)點(diǎn)內(nèi)存→從節(jié)點(diǎn)磁盤這幾個(gè)階段。對(duì)延時(shí)敏感的應(yīng)用而言,主寫(xiě)從讀的功能并不太適用。
對(duì)于Kafka來(lái)說(shuō),必要性不是很高,因?yàn)樵贙afka集群中,如果存在多個(gè)副本,經(jīng)過(guò)合理的配置,可以讓leader副本均勻的分布在各個(gè)broker上面,使每個(gè) broker 上的讀寫(xiě)負(fù)載都是一樣的。
Kafka中的延遲隊(duì)列怎么實(shí)現(xiàn)
在發(fā)送延時(shí)消息的時(shí)候并不是先投遞到要發(fā)送的真實(shí)主題(real_topic)中,而是先投遞到一些 Kafka 內(nèi)部的主題(delay_topic)中,這些內(nèi)部主題對(duì)用戶不可見(jiàn),然后通過(guò)一個(gè)自定義的服務(wù)拉取這些內(nèi)部主題中的消息,并將滿足條件的消息再投遞到要發(fā)送的真實(shí)的主題中,消費(fèi)者所訂閱的還是真實(shí)的主題。
如果采用這種方案,那么一般是按照不同的延時(shí)等級(jí)來(lái)劃分的,比如設(shè)定5s、10s、30s、1min、2min、5min、10min、20min、30min、45min、1hour、2hour這些按延時(shí)時(shí)間遞增的延時(shí)等級(jí),延時(shí)的消息按照延時(shí)時(shí)間投遞到不同等級(jí)的主題中,投遞到同一主題中的消息的延時(shí)時(shí)間會(huì)被強(qiáng)轉(zhuǎn)為與此主題延時(shí)等級(jí)一致的延時(shí)時(shí)間,這樣延時(shí)誤差控制在兩個(gè)延時(shí)等級(jí)的時(shí)間差范圍之內(nèi)(比如延時(shí)時(shí)間為17s的消息投遞到30s的延時(shí)主題中,之后按照延時(shí)時(shí)間為30s進(jìn)行計(jì)算,延時(shí)誤差為13s)。雖然有一定的延時(shí)誤差,但是誤差可控,并且這樣只需增加少許的主題就能實(shí)現(xiàn)延時(shí)隊(duì)列的功能。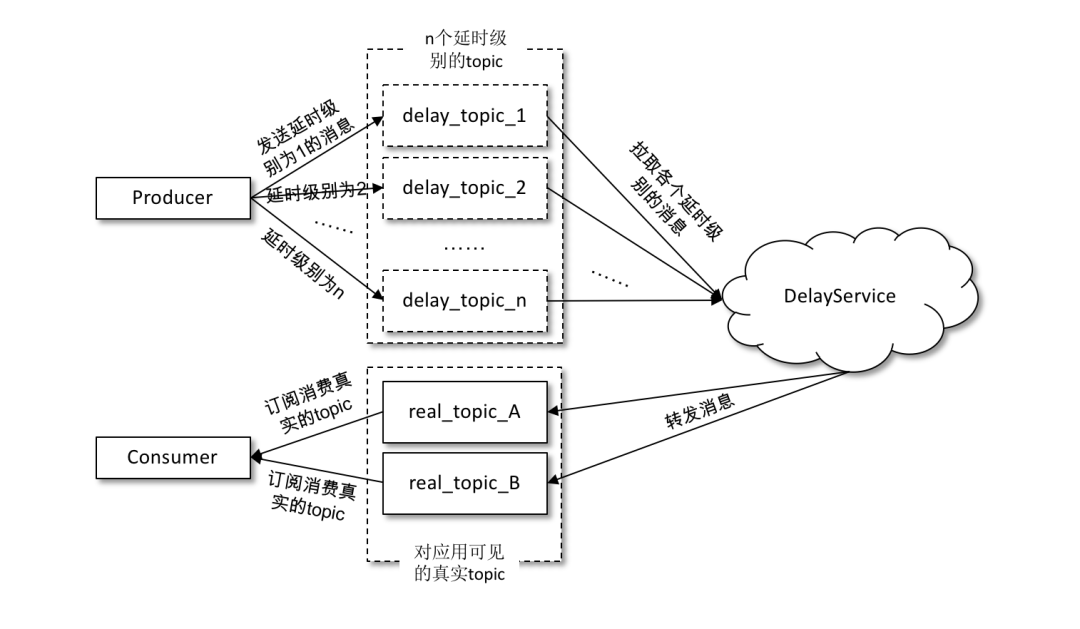
發(fā)送到內(nèi)部主題(delay_topic_*)中的消息會(huì)被一個(gè)獨(dú)立的 DelayService 進(jìn)程消費(fèi),這個(gè) DelayService 進(jìn)程和 Kafka broker 進(jìn)程以一對(duì)一的配比進(jìn)行同機(jī)部署(參考下圖),以保證服務(wù)的可用性。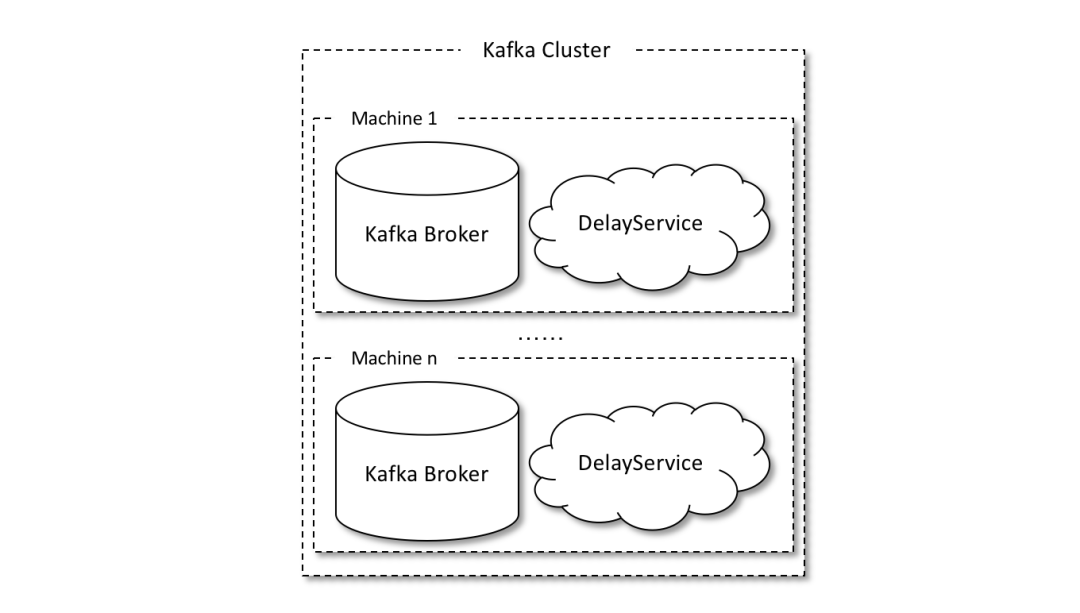
針對(duì)不同延時(shí)級(jí)別的主題,在 DelayService 的內(nèi)部都會(huì)有單獨(dú)的線程來(lái)進(jìn)行消息的拉取,以及單獨(dú)的 DelayQueue(這里用的是 JUC 中 DelayQueue)進(jìn)行消息的暫存。與此同時(shí),在 DelayService 內(nèi)部還會(huì)有專門的消息發(fā)送線程來(lái)獲取 DelayQueue 的消息并轉(zhuǎn)發(fā)到真實(shí)的主題中。從消費(fèi)、暫存再到轉(zhuǎn)發(fā),線程之間都是一一對(duì)應(yīng)的關(guān)系。如下圖所示,DelayService 的設(shè)計(jì)應(yīng)當(dāng)盡量保持簡(jiǎn)單,避免鎖機(jī)制產(chǎn)生的隱患。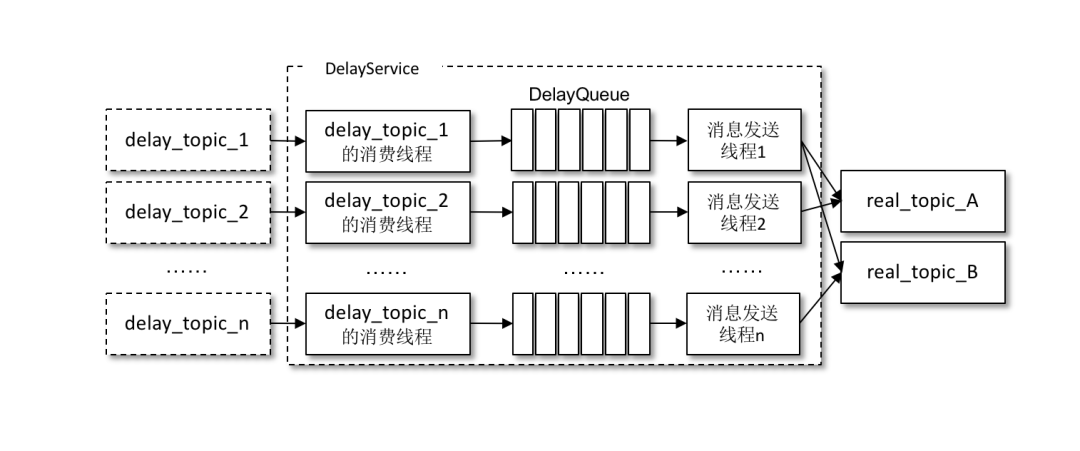
為了保障內(nèi)部 DelayQueue 不會(huì)因?yàn)槲刺幚淼南⑦^(guò)多而導(dǎo)致內(nèi)存的占用過(guò)大,DelayService 會(huì)對(duì)主題中的每個(gè)分區(qū)進(jìn)行計(jì)數(shù),當(dāng)達(dá)到一定的閾值之后,就會(huì)暫停拉取該分區(qū)中的消息。
因?yàn)橐粋€(gè)主題中一般不止一個(gè)分區(qū),分區(qū)之間的消息并不會(huì)按照投遞時(shí)間進(jìn)行排序,DelayQueue的作用是將消息按照再次投遞時(shí)間進(jìn)行有序排序,這樣下游的消息發(fā)送線程就能夠按照先后順序獲取最先滿足投遞條件的消息。
Kafka中怎么實(shí)現(xiàn)死信隊(duì)列和重試隊(duì)列?
死信可以看作消費(fèi)者不能處理收到的消息,也可以看作消費(fèi)者不想處理收到的消息,還可以看作不符合處理要求的消息。比如消息內(nèi)包含的消息內(nèi)容無(wú)法被消費(fèi)者解析,為了確保消息的可靠性而不被隨意丟棄,故將其投遞到死信隊(duì)列中,這里的死信就可以看作消費(fèi)者不能處理的消息。再比如超過(guò)既定的重試次數(shù)之后將消息投入死信隊(duì)列,這里就可以將死信看作不符合處理要求的消息。
重試隊(duì)列其實(shí)可以看作一種回退隊(duì)列,具體指消費(fèi)端消費(fèi)消息失敗時(shí),為了防止消息無(wú)故丟失而重新將消息回滾到 broker 中。與回退隊(duì)列不同的是,重試隊(duì)列一般分成多個(gè)重試等級(jí),每個(gè)重試等級(jí)一般也會(huì)設(shè)置重新投遞延時(shí),重試次數(shù)越多投遞延時(shí)就越大。
理解了他們的概念之后我們就可以為每個(gè)主題設(shè)置重試隊(duì)列,消息第一次消費(fèi)失敗入重試隊(duì)列 Q1,Q1 的重新投遞延時(shí)為5s,5s過(guò)后重新投遞該消息;如果消息再次消費(fèi)失敗則入重試隊(duì)列 Q2,Q2 的重新投遞延時(shí)為10s,10s過(guò)后再次投遞該消息。
然后再設(shè)置一個(gè)主題作為死信隊(duì)列,重試越多次重新投遞的時(shí)間就越久,并且需要設(shè)置一個(gè)上限,超過(guò)投遞次數(shù)就進(jìn)入死信隊(duì)列。重試隊(duì)列與延時(shí)隊(duì)列有相同的地方,都需要設(shè)置延時(shí)級(jí)別。
Kafka中怎么做消息審計(jì)?
消息審計(jì)是指在消息生產(chǎn)、存儲(chǔ)和消費(fèi)的整個(gè)過(guò)程之間對(duì)消息個(gè)數(shù)及延遲的審計(jì),以此來(lái)檢測(cè)是否有數(shù)據(jù)丟失、是否有數(shù)據(jù)重復(fù)、端到端的延遲又是多少等內(nèi)容。
目前與消息審計(jì)有關(guān)的產(chǎn)品也有多個(gè),比如 Chaperone(Uber)、Confluent Control Center、Kafka Monitor(LinkedIn),它們主要通過(guò)在消息體(value 字段)或在消息頭(headers 字段)中內(nèi)嵌消息對(duì)應(yīng)的時(shí)間戳 timestamp 或全局的唯一標(biāo)識(shí) ID(或者是兩者兼?zhèn)洌﹣?lái)實(shí)現(xiàn)消息的審計(jì)功能。
內(nèi)嵌 timestamp 的方式主要是設(shè)置一個(gè)審計(jì)的時(shí)間間隔 time_bucket_interval(可以自定義設(shè)置幾秒或幾分鐘),根據(jù)這個(gè) time_bucket_interval 和消息所屬的 timestamp 來(lái)計(jì)算相應(yīng)的時(shí)間桶(time_bucket)。
內(nèi)嵌 ID 的方式就更加容易理解了,對(duì)于每一條消息都會(huì)被分配一個(gè)全局唯一標(biāo)識(shí) ID。如果主題和相應(yīng)的分區(qū)固定,則可以為每個(gè)分區(qū)設(shè)置一個(gè)全局的 ID。當(dāng)有消息發(fā)送時(shí),首先獲取對(duì)應(yīng)的 ID,然后內(nèi)嵌到消息中,最后才將它發(fā)送到 broker 中。消費(fèi)者進(jìn)行消費(fèi)審計(jì)時(shí),可以判斷出哪條消息丟失、哪條消息重復(fù)。
Kafka中怎么做消息軌跡?
消息軌跡指的是一條消息從生產(chǎn)者發(fā)出,經(jīng)由 broker 存儲(chǔ),再到消費(fèi)者消費(fèi)的整個(gè)過(guò)程中,各個(gè)相關(guān)節(jié)點(diǎn)的狀態(tài)、時(shí)間、地點(diǎn)等數(shù)據(jù)匯聚而成的完整鏈路信息。生產(chǎn)者、broker、消費(fèi)者這3個(gè)角色在處理消息的過(guò)程中都會(huì)在鏈路中增加相應(yīng)的信息,將這些信息匯聚、處理之后就可以查詢?nèi)我庀⒌臓顟B(tài),進(jìn)而為生產(chǎn)環(huán)境中的故障排除提供強(qiáng)有力的數(shù)據(jù)支持。
對(duì)消息軌跡而言,最常見(jiàn)的實(shí)現(xiàn)方式是封裝客戶端,在保證正常生產(chǎn)消費(fèi)的同時(shí)添加相應(yīng)的軌跡信息埋點(diǎn)邏輯。無(wú)論生產(chǎn),還是消費(fèi),在執(zhí)行之后都會(huì)有相應(yīng)的軌跡信息,我們需要將這些信息保存起來(lái)。
我們同樣可以將軌跡信息保存到 Kafka 的某個(gè)主題中,比如下圖中的主題 trace_topic。
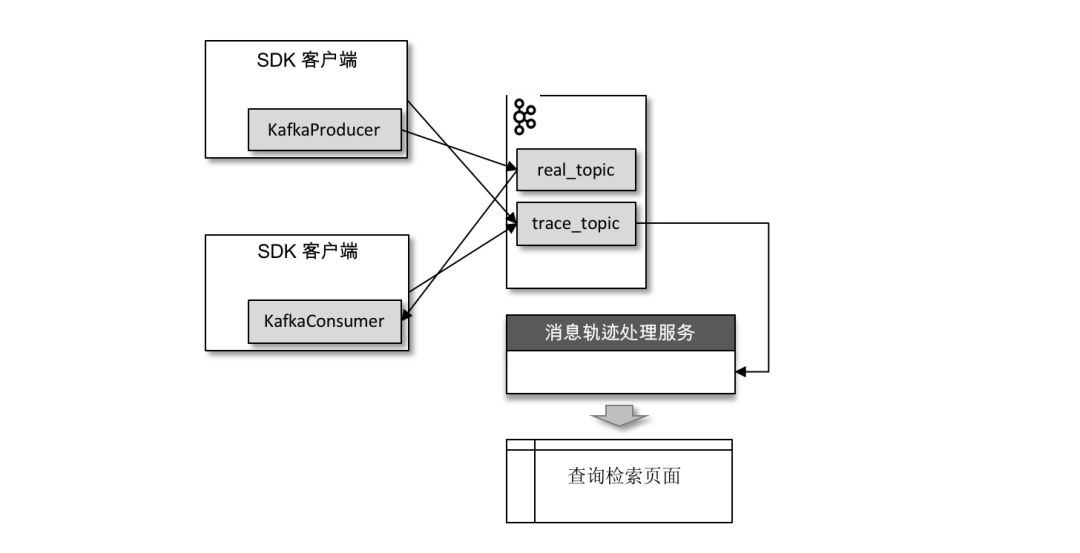
生產(chǎn)者在將消息正常發(fā)送到用戶主題 real_topic 之后(或者消費(fèi)者在拉取到消息消費(fèi)之后)會(huì)將軌跡信息發(fā)送到主題 trace_topic 中。
怎么計(jì)算Lag?(注意read_uncommitted和read_committed狀態(tài)下的不同)
如果消費(fèi)者客戶端的 isolation.level 參數(shù)配置為“read_uncommitted”(默認(rèn)),它對(duì)應(yīng)的 Lag 等于HW – ConsumerOffset 的值,其中 ConsumerOffset 表示當(dāng)前的消費(fèi)位移。
如果這個(gè)參數(shù)配置為“read_committed”,那么就要引入 LSO 來(lái)進(jìn)行計(jì)算了。LSO 是 LastStableOffset 的縮寫(xiě),它對(duì)應(yīng)的 Lag 等于 LSO – ConsumerOffset 的值。
首先通過(guò) DescribeGroupsRequest 請(qǐng)求獲取當(dāng)前消費(fèi)組的元數(shù)據(jù)信息,當(dāng)然在這之前還會(huì)通過(guò) FindCoordinatorRequest 請(qǐng)求查找消費(fèi)組對(duì)應(yīng)的 GroupCoordinator。
接著通過(guò) OffsetFetchRequest 請(qǐng)求獲取消費(fèi)位移 ConsumerOffset。
然后通過(guò) KafkaConsumer 的 endOffsets(Collection partitions)方法(對(duì)應(yīng)于 ListOffsetRequest 請(qǐng)求)獲取 HW(LSO)的值。
最后通過(guò) HW 與 ConsumerOffset 相減得到分區(qū)的 Lag,要獲得主題的總體 Lag 只需對(duì)旗下的各個(gè)分區(qū)累加即可。
Kafka有哪些指標(biāo)需要著重關(guān)注?
比較重要的 Broker 端 JMX 指標(biāo):
BytesIn/BytesOut:即 Broker 端每秒入站和出站字節(jié)數(shù)。你要確保這組值不要接近你的網(wǎng)絡(luò)帶寬,否則這通常都表示網(wǎng)卡已被“打滿”,很容易出現(xiàn)網(wǎng)絡(luò)丟包的情形。
NetworkProcessorAvgIdlePercent:即網(wǎng)絡(luò)線程池線程平均的空閑比例。通常來(lái)說(shuō),你應(yīng)該確保這個(gè) JMX 值長(zhǎng)期大于 30%。如果小于這個(gè)值,就表明你的網(wǎng)絡(luò)線程池非常繁忙,你需要通過(guò)增加網(wǎng)絡(luò)線程數(shù)或?qū)⒇?fù)載轉(zhuǎn)移給其他服務(wù)器的方式,來(lái)給該 Broker 減負(fù)。
RequestHandlerAvgIdlePercent:即 I/O 線程池線程平均的空閑比例。同樣地,如果該值長(zhǎng)期小于 30%,你需要調(diào)整 I/O 線程池的數(shù)量,或者減少 Broker 端的負(fù)載。
UnderReplicatedPartitions:即未充分備份的分區(qū)數(shù)。所謂未充分備份,是指并非所有的 Follower 副本都和 Leader 副本保持同步。一旦出現(xiàn)了這種情況,通常都表明該分區(qū)有可能會(huì)出現(xiàn)數(shù)據(jù)丟失。因此,這是一個(gè)非常重要的 JMX 指標(biāo)。
ISRShrink/ISRExpand:即 ISR 收縮和擴(kuò)容的頻次指標(biāo)。如果你的環(huán)境中出現(xiàn) ISR 中副本頻繁進(jìn)出的情形,那么這組值一定是很高的。這時(shí),你要診斷下副本頻繁進(jìn)出 ISR 的原因,并采取適當(dāng)?shù)拇胧?/p>
ActiveControllerCount:即當(dāng)前處于激活狀態(tài)的控制器的數(shù)量。正常情況下,Controller 所在 Broker 上的這個(gè) JMX 指標(biāo)值應(yīng)該是 1,其他 Broker 上的這個(gè)值是 0。如果你發(fā)現(xiàn)存在多臺(tái) Broker 上該值都是 1 的情況,一定要趕快處理,處理方式主要是查看網(wǎng)絡(luò)連通性。這種情況通常表明集群出現(xiàn)了腦裂。腦裂問(wèn)題是非常嚴(yán)重的分布式故障,Kafka 目前依托 ZooKeeper 來(lái)防止腦裂。但一旦出現(xiàn)腦裂,Kafka 是無(wú)法保證正常工作的。
Kafka的那些設(shè)計(jì)讓它有如此高的性能?
分區(qū)
kafka是個(gè)分布式集群的系統(tǒng),整個(gè)系統(tǒng)可以包含多個(gè)broker,也就是多個(gè)服務(wù)器實(shí)例。每個(gè)主題topic會(huì)有多個(gè)分區(qū),kafka將分區(qū)均勻地分配到整個(gè)集群中,當(dāng)生產(chǎn)者向?qū)?yīng)主題傳遞消息,消息通過(guò)負(fù)載均衡機(jī)制傳遞到不同的分區(qū)以減輕單個(gè)服務(wù)器實(shí)例的壓力。
一個(gè)Consumer Group中可以有多個(gè)consumer,多個(gè)consumer可以同時(shí)消費(fèi)不同分區(qū)的消息,大大的提高了消費(fèi)者的并行消費(fèi)能力。但是一個(gè)分區(qū)中的消息只能被一個(gè)Consumer Group中的一個(gè)consumer消費(fèi)。
網(wǎng)絡(luò)傳輸上減少開(kāi)銷
批量發(fā)送:
在發(fā)送消息的時(shí)候,kafka不會(huì)直接將少量數(shù)據(jù)發(fā)送出去,否則每次發(fā)送少量的數(shù)據(jù)會(huì)增加網(wǎng)絡(luò)傳輸頻率,降低網(wǎng)絡(luò)傳輸效率。kafka會(huì)先將消息緩存在內(nèi)存中,當(dāng)超過(guò)一個(gè)的大小或者超過(guò)一定的時(shí)間,那么會(huì)將這些消息進(jìn)行批量發(fā)送。
端到端壓縮:
當(dāng)然網(wǎng)絡(luò)傳輸時(shí)數(shù)據(jù)量小也可以減小網(wǎng)絡(luò)負(fù)載,kafaka會(huì)將這些批量的數(shù)據(jù)進(jìn)行壓縮,將一批消息打包后進(jìn)行壓縮,發(fā)送broker服務(wù)器后,最終這些數(shù)據(jù)還是提供給消費(fèi)者用,所以數(shù)據(jù)在服務(wù)器上還是保持壓縮狀態(tài),不會(huì)進(jìn)行解壓,而且頻繁的壓縮和解壓也會(huì)降低性能,最終還是以壓縮的方式傳遞到消費(fèi)者的手上。順序讀寫(xiě)
kafka將消息追加到日志文件中,利用了磁盤的順序讀寫(xiě),來(lái)提高讀寫(xiě)效率。零拷貝技術(shù)
零拷貝將文件內(nèi)容從磁盤通過(guò)DMA引擎復(fù)制到內(nèi)核緩沖區(qū),而且沒(méi)有把數(shù)據(jù)復(fù)制到socket緩沖區(qū),只是將數(shù)據(jù)位置和長(zhǎng)度信息的描述符復(fù)制到了socket緩存區(qū),然后直接將數(shù)據(jù)傳輸?shù)骄W(wǎng)絡(luò)接口,最后發(fā)送。這樣大大減小了拷貝的次數(shù),提高了效率。kafka正是調(diào)用linux系統(tǒng)給出的sendfile系統(tǒng)調(diào)用來(lái)使用零拷貝。Java中的系統(tǒng)調(diào)用給出的是FileChannel.transferTo接口。
5. 優(yōu)秀的文件存儲(chǔ)機(jī)制
如果分區(qū)規(guī)則設(shè)置得合理,那么所有的消息可以均勻地分布到不同的分區(qū)中,這樣就可以實(shí)現(xiàn)水平擴(kuò)展。不考慮多副本的情況,一個(gè)分區(qū)對(duì)應(yīng)一個(gè)日志(Log)。為了防止 Log 過(guò)大,Kafka 又引入了日志分段(LogSegment)的概念,將 Log 切分為多個(gè) LogSegment,相當(dāng)于一個(gè)巨型文件被平均分配為多個(gè)相對(duì)較小的文件,這樣也便于消息的維護(hù)和清理。
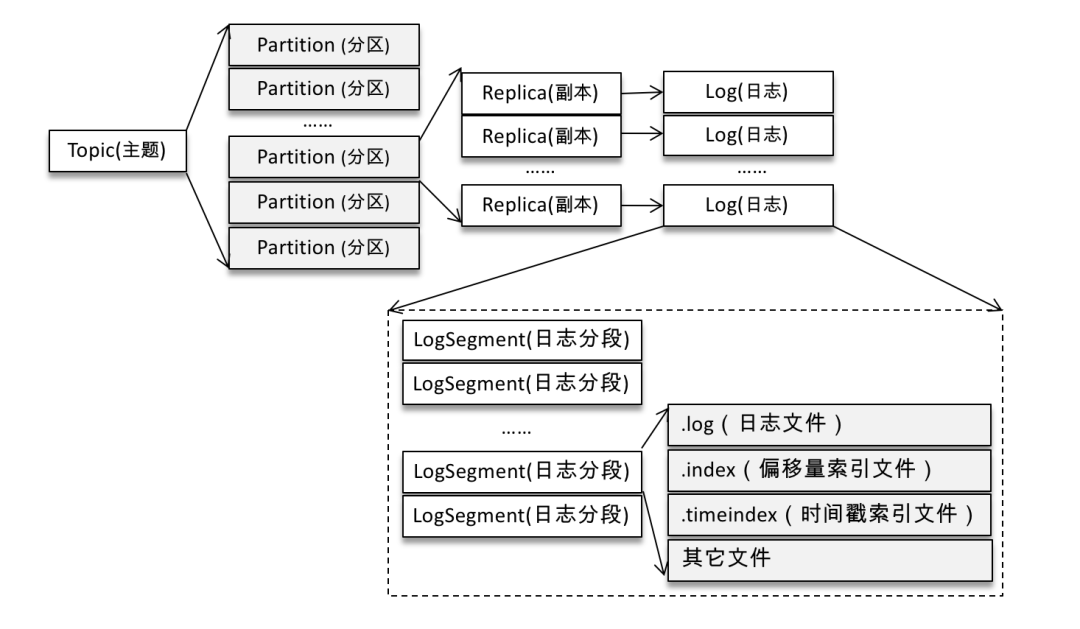
Kafka 中的索引文件以稀疏索引(sparse index)的方式構(gòu)造消息的索引,它并不保證每個(gè)消息在索引文件中都有對(duì)應(yīng)的索引項(xiàng)。每當(dāng)寫(xiě)入一定量(由 broker 端參數(shù) log.index.interval.bytes 指定,默認(rèn)值為4096,即 4KB)的消息時(shí),偏移量索引文件和時(shí)間戳索引文件分別增加一個(gè)偏移量索引項(xiàng)和時(shí)間戳索引項(xiàng),增大或減小 log.index.interval.bytes 的值,對(duì)應(yīng)地可以增加或縮小索引項(xiàng)的密度。
歡迎點(diǎn)贊+收藏+轉(zhuǎn)發(fā)朋友圈素質(zhì)三連文章不錯(cuò)?點(diǎn)個(gè)【在看】吧!??