
使用多尺度空間注意力的語義分割方法
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

作者:Abhinav Sagar
編譯:ronghuaiyang
用于自動駕駛的新的state of the art的網(wǎng)絡(luò)。

本文提出了一種新的神經(jīng)網(wǎng)絡(luò),利用不同尺度的多尺度特征融合來實現(xiàn)精確高效的語義分割。
我們在下采樣部分使用了膨脹卷積層,在上采樣部分使用了轉(zhuǎn)置卷積層,并在concat層中對它們進行拼接。 alternate blocks之間有跳躍連接,這有助于減少過擬合。 我們對我們的網(wǎng)絡(luò)訓練和優(yōu)化細節(jié)進行了深入的理論分析。 我們在Camvid數(shù)據(jù)集上使用每個類的平均精度和IOU作為評價指標來評估我們的網(wǎng)絡(luò)。 我們的模型在語義分割上優(yōu)于之前的state of the art網(wǎng)絡(luò),在超過100幀每秒的速度下,平均IOU值為74.12。
語義分割需要對輸入圖像的每個像素預測一個類,而不是對整個輸入圖像進行分類。為了預測圖像中每個像素的內(nèi)容,分割不僅需要找到輸入圖像中的內(nèi)容,還需要找到它的位置。語義分割在自動駕駛、視頻監(jiān)控、醫(yī)學影像等方面都有應(yīng)用。這是一個具有挑戰(zhàn)性的問題,因為要在準確性和速度之間進行權(quán)衡。由于模型最終需要在現(xiàn)實環(huán)境中部署,因此精度和速度都應(yīng)該很高。
在訓練和評估中使用了CamVid數(shù)據(jù)集。數(shù)據(jù)集提供了ground truth標簽,將每個像素與32個類中的一個相關(guān)聯(lián)。圖像大小為360×480。數(shù)據(jù)集的ground truth樣本圖像如圖1所示:
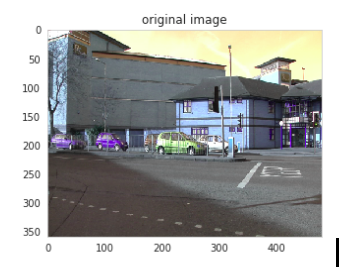
將原始圖像作為ground truth。對于任何算法,總是在與ground truth數(shù)據(jù)的比較中進行指標的評估。在數(shù)據(jù)集和測試集中提供ground truth信息用于訓練和測試。對于語義分割問題,ground truth包括圖像、圖像中目標的類別以及針對特定圖像中每個目標的分割掩模。對于圖2中的12個類別,這些圖像分別以二進制格式顯示:

這些類別為:Sky, Building, Pole, Road, Pavement, Tree, SignSymbol, Fence, Car, Pedestrian 和 Bicyclist.
對網(wǎng)絡(luò)結(jié)構(gòu)的解釋如下:
我們將原來360×480像素的圖像調(diào)整為224×224像素。 我們將數(shù)據(jù)集分成兩個部分,訓練集中有85%的圖像,測試集中有15%的圖像。 使用的損失函數(shù)是分類交叉熵。 我們用擴張卷積來代替下采樣層中的普通卷積層這是用來減少特征圖的,用轉(zhuǎn)置卷積來代替上采樣層中的普通卷積層來恢復特征。 我們在圖層之間使用concat操作來合并不同尺度的特征。 對于convolutional layer我們沒有使用任何padding,使用3 * 3 filter,并且使用relu作為激活函數(shù)。對于最大池化層,我們使用2×2的過濾器和2×2的步長。 我們使用VGG16作為訓練模型的預訓練主干。 在最后一層使用Softmax作為激活函數(shù),輸出一個物體是否存在于一個特定像素位置的離散概率。 我們使用adam作為優(yōu)化器。 為了避免過擬合,我們使用了我們認為最優(yōu)的batch size值4。
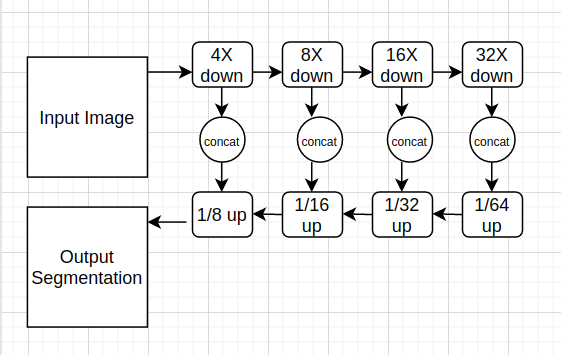
本工作中使用的網(wǎng)絡(luò)結(jié)構(gòu)圖3所示:
假設(shè)給定一個局部特征C,我們將其輸入一個卷積層,分別生成兩個新的特征圖B和C。對A與B的轉(zhuǎn)置進行矩陣乘法,應(yīng)用softmax層計算空間注意力圖,定義如下式:
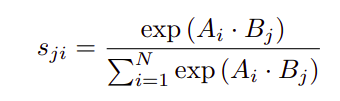
我們在X和A的轉(zhuǎn)置之間進行矩陣乘法并reshape它們的結(jié)果。然后將結(jié)果乘以一個尺度參數(shù)β,并與A進行元素和運算,得到最終的輸出結(jié)果如下式所示:

由上式可知,得到的各通道特征是各通道特征的加權(quán)和,并模擬了各尺度特征圖之間的語義依賴關(guān)系。主干網(wǎng)絡(luò)以及子階段聚合方法可表示為:
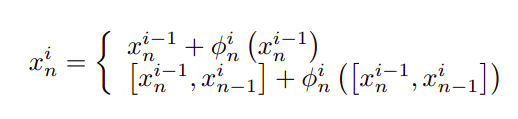
這里i指的是stage的索引。
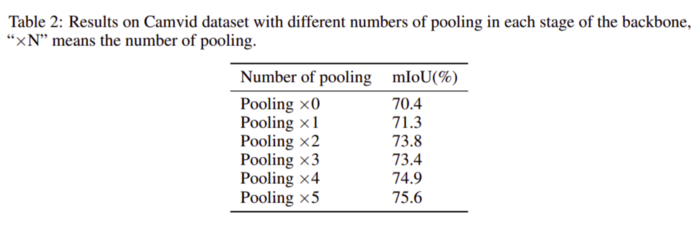
池化層的數(shù)量對IOU的影響如表2所示。
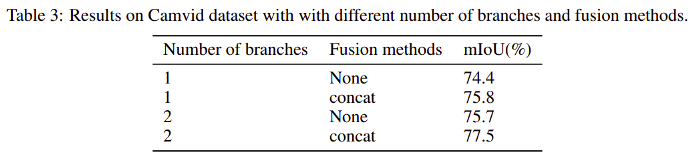
模型架構(gòu)中使用的分支數(shù)和融合方法對IOU的影響如表3所示。
模型訓練了40個epoch,訓練的平均像素精度為93%,驗證的平均像素精度為88%。損失和像素級精度(訓練和測試)被繪制成epoch的函數(shù),如圖4所示:
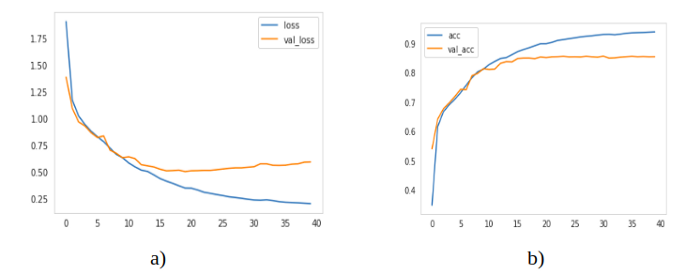
圖4:a) Loss vs epochs b) Accuracy vs epochs
對于評價,使用了以下兩個指標:
1、每個類的平均精度:這個度量輸出每個像素的類預測精度。
2、平均IOU:它是一個分割性能參數(shù),通過計算與ground truth掩模之間的交集和并集的比來度量兩個目標之間的重疊率。
按類別計算IOU值的方法如下所示。

其中TP為真陽性,F(xiàn)P為假陽性,F(xiàn)N為假銀性,IOU表示交并比。
使用多個block、FLOPS和參數(shù)對IOU的影響如表5所示。在這里,F(xiàn)LOPS和參數(shù)是我們的模型架構(gòu)所需要的計算量的度量。
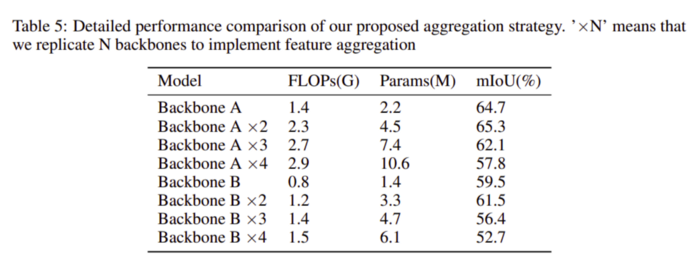
表6中顯示了之前的stage和我們的模型結(jié)構(gòu)所實現(xiàn)的FPS和IOU的比較分析。

將預測的分割結(jié)果與來自數(shù)據(jù)集的ground truth圖像進行比較,結(jié)果如圖5所示。
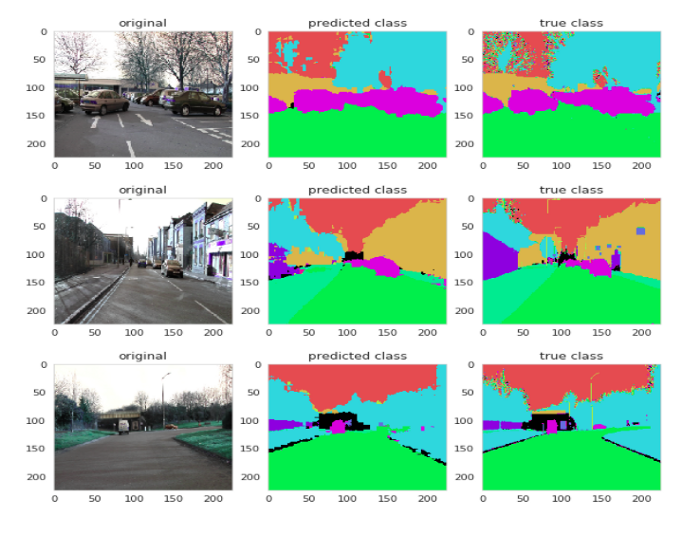
圖5:預測圖像的結(jié)果 —— 第一列來自dataset的原始圖像,第二列來自network的預測圖像,第三列來自dataset的ground truth圖像
本文提出了一種基于多尺度關(guān)注特征圖的語義分割網(wǎng)絡(luò),并對其在Camvid數(shù)據(jù)集上的性能進行了評價。我們使用了一個下采樣和上采樣結(jié)構(gòu),分別使用了擴展卷積和轉(zhuǎn)置卷積層,并結(jié)合了相應(yīng)的池化層和反池化層。我們的網(wǎng)絡(luò)在語義分割方面的表現(xiàn)超過了以往的技術(shù)水平,同時仍能以100幀每秒的速度運行,這在自動駕駛環(huán)境中非常重要。
論文地址:https://abhinavsagar.github.io/files/sem_seg.pdf
代碼:https://github.com/abhinavsagar/mssa

英文原文:https://towardsdatascience.com/semantic-segmentation-with-multi-scale-spatial-attention-5442ac808b3e
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~