
85.4% mIOU!NVIDIA:使用多尺度注意力進(jìn)行語義分割,代碼已開源!
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達(dá)

下載論文PDF和源代碼:
鏈接:https://pan.baidu.com/s/17oy5JBnmDDOtKasfPrWNiQ 提取碼:lk5z
來自NVIDIA的SOTA語義分割文章,代碼開源。

論文:https://arxiv.org/abs/2005.10821
代碼鏈接:
https://github.com/NVIDIA/semanic-segmentation
有一項重要的技術(shù),通常用于自動駕駛、醫(yī)學(xué)成像,甚至縮放虛擬背景:“語義分割。這是將圖像中的像素標(biāo)記為屬于N類中的一個(N是任意數(shù)量的類)的過程,這些類可以是像汽車、道路、人或樹這樣的東西。就醫(yī)學(xué)圖像而言,類別對應(yīng)于不同的器官或解剖結(jié)構(gòu)。
NVIDIA Research正在研究語義分割,因為它是一項廣泛適用的技術(shù)。我們還相信,改進(jìn)語義分割的技術(shù)也可能有助于改進(jìn)許多其他密集預(yù)測任務(wù),如光流預(yù)測(預(yù)測物體的運(yùn)動),圖像超分辨率,等等。
我們開發(fā)出一種新方法的語義分割方法,在兩個共同的基準(zhǔn):Cityscapes和Mapillary Vistas上達(dá)到了SOTA的結(jié)果。IOU是交并比,是描述語義分割預(yù)測精度的度量。
在Cityscapes中,這種方法在測試集上達(dá)到了85.4 IOU,考慮到這些分?jǐn)?shù)之間的接近程度,這相對于其他方法來說是一個相當(dāng)大的進(jìn)步。
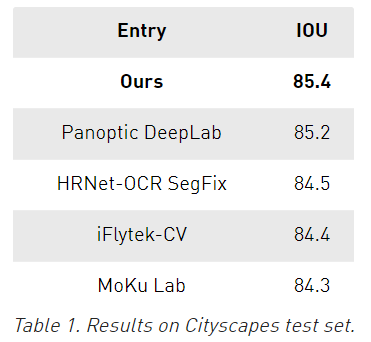
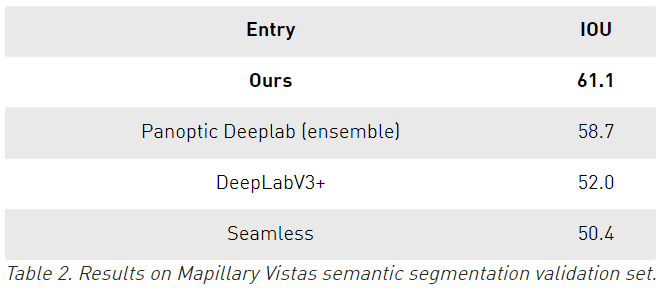
在Mapillary上,使用單個模型在驗證集上達(dá)到了61.1 IOU,相比于其他的使用了模型集成最優(yōu)結(jié)果是58.7。

為了開發(fā)這種新方法,我們考慮了圖像的哪些特定區(qū)域需要改進(jìn)。圖2顯示了當(dāng)前語義分割模型的兩種最大的失敗模式:細(xì)節(jié)錯誤和類混淆。

在這個例子中,存在兩個問題:細(xì)節(jié)和類混淆。
第一張圖片中郵箱的細(xì)節(jié)在2倍尺度的預(yù)測中得到了最好的分辨,但在0.5倍尺度下的分辨很差。 與中值分割相比,在0.5x尺度下對道路的粗預(yù)測要比在2x尺度下更好,在2x尺度下存在類混淆。
我們的解決方案在這兩個問題上的性能都能好得多,類混淆幾乎沒有發(fā)生,對細(xì)節(jié)的預(yù)測也更加平滑和一致。
在確定了這些錯誤模式之后,團(tuán)隊試驗了許多不同的策略,包括不同的網(wǎng)絡(luò)主干(例如,WiderResnet-38、EfficientNet-B4、xcepase -71),以及不同的分割解碼器(例如,DeeperLab)。我們決定采用HRNet作為網(wǎng)絡(luò)主干,RMI作為主要的損失函數(shù)。
HRNet已經(jīng)被證明非常適合計算機(jī)視覺任務(wù),因為它保持了比以前的網(wǎng)絡(luò)WiderResnet38高2倍分辨率的表示。RMI損失提供了一種無需訴諸于條件隨機(jī)場之類的東西就能獲得結(jié)構(gòu)性損失的方法。HRNet和RMI損失都有助于解決細(xì)節(jié)和類混淆。
為了進(jìn)一步解決主要的錯誤模式,我們創(chuàng)新了兩種方法:多尺度注意力和自動標(biāo)記。
在計算機(jī)視覺模型中,通常采用多尺度推理的方法來獲得最佳的結(jié)果。多尺度圖像在網(wǎng)絡(luò)中運(yùn)行,并將結(jié)果使用平均池化組合起來。
使用平均池化作為一個組合策略,將所有尺度視為同等重要。然而,精細(xì)的細(xì)節(jié)通常在較高的尺度上被最好地預(yù)測,大的物體在較低的尺度上被更好地預(yù)測,在較低的尺度上,網(wǎng)絡(luò)的感受野能夠更好地理解場景。
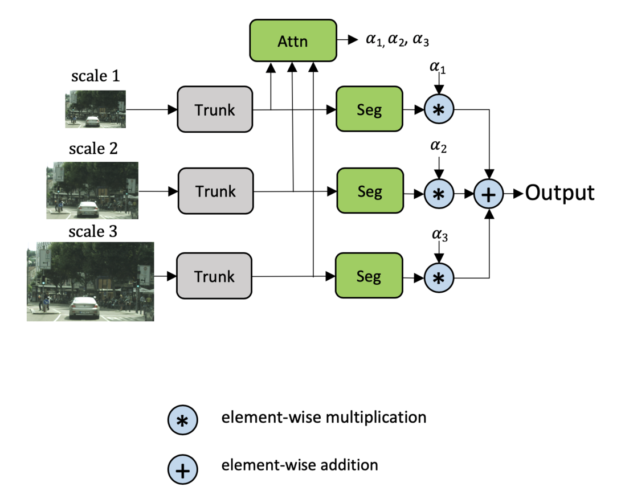
學(xué)習(xí)如何在像素級結(jié)合多尺度預(yù)測可以幫助解決這個問題。之前就有關(guān)于這一策略的研究,Chen等人的Attention to Scale是最接近的。在這個方法中,同時學(xué)習(xí)所有尺度的注意力。我們將其稱為顯式方法,如下圖所示。
受Chen方法的啟發(fā),我們提出了一個多尺度的注意力模型,該模型也學(xué)會了預(yù)測一個密集的mask,從而將多尺度的預(yù)測結(jié)合在一起。但是在這個方法中,我們學(xué)習(xí)了一個相對的注意力mask,用于在一個尺度和下一個更高的尺度之間進(jìn)行注意力,如圖4所示。我們將其稱為層次方法。
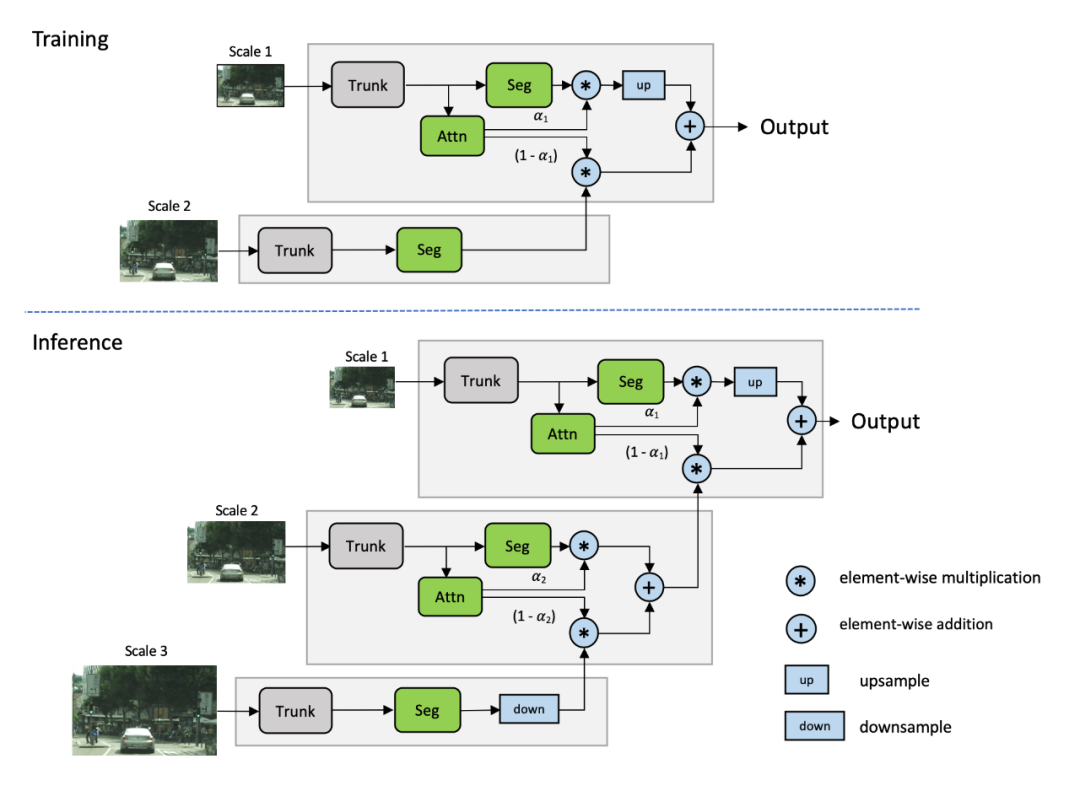
這種方法的主要好處如下:
理論訓(xùn)練成本比Chen方法降低了約4x。 訓(xùn)練只在成對的尺度上進(jìn)行,推理是靈活的,可以在任意數(shù)量的尺度上進(jìn)行。
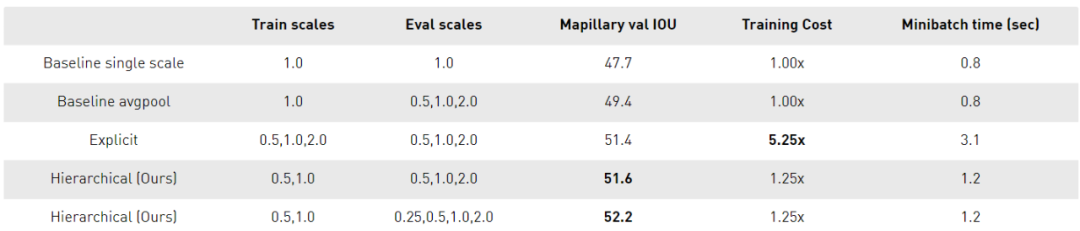
圖5顯示了我們的方法的一些例子,以及已學(xué)習(xí)的注意力mask。對于左邊圖片中郵箱的細(xì)節(jié),我們很少關(guān)注0.5x的預(yù)測,但是對2.0x尺度的預(yù)測非常關(guān)注。相反,對于右側(cè)圖像中非常大的道路/隔離帶區(qū)域,注意力機(jī)制學(xué)會最大程度地利用較低的尺度(0.5x),以及更少地利用錯誤的2.0x預(yù)測。

改進(jìn)城市景觀語義分割結(jié)果的一種常用方法是利用大量的粗標(biāo)記數(shù)據(jù)。這個數(shù)據(jù)大約是基線精標(biāo)注數(shù)據(jù)的7倍。過去Cityscapes上的SOTA方法會使用粗標(biāo)注標(biāo)簽,或者使用粗標(biāo)注的數(shù)據(jù)對網(wǎng)絡(luò)進(jìn)行預(yù)訓(xùn)練,或者將其與細(xì)標(biāo)注數(shù)據(jù)混合使用。
然而,粗標(biāo)注的標(biāo)簽是一個挑戰(zhàn),因為它們是有噪聲的和不精確的。ground truth粗標(biāo)簽如圖6所示為“原始粗標(biāo)簽”。

受最近工作的啟發(fā),我們將自動標(biāo)注作為一種方法,以產(chǎn)生更豐富的標(biāo)簽,以填補(bǔ)ground truth粗標(biāo)簽的標(biāo)簽空白。我們生成的自動標(biāo)簽顯示了比基線粗標(biāo)簽更好的細(xì)節(jié),如圖6所示。我們認(rèn)為,通過填補(bǔ)長尾類的數(shù)據(jù)分布空白,這有助于泛化。
使用自動標(biāo)記的樸素方法,例如使用來自教師網(wǎng)絡(luò)的多類概率來指導(dǎo)學(xué)生,將在磁盤空間上花費(fèi)非常大的代價。為20,000張橫跨19個類的、分辨率都為1920×1080的粗圖像生成標(biāo)簽大約需要2tb的存儲空間。這么大的代價最大的影響將是降低訓(xùn)練成績。
我們使用硬閾值方法而不是軟閾值方法來將生成的標(biāo)簽占用空間從2TB大大減少到600mb。在這個方法中,教師預(yù)測概率 > 0.5是有效的,較低概率的預(yù)測被視為“忽略”類。表4顯示了將粗?jǐn)?shù)據(jù)添加到細(xì)數(shù)據(jù)和使用融合后的數(shù)據(jù)集訓(xùn)練新學(xué)生的好處。


該模型使用PyTorch框架在4個DGX節(jié)點(diǎn)上對fp16張量核進(jìn)行自動混合精度訓(xùn)練。
論文:https://arxiv.org/abs/2005.10821
代碼:https://github.com/nvidia/semanic-segmentation
英文原文:https://developer.nvidia.com/blog/using-multi-scale-attention-for-semantic-segmentation/
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細(xì)分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進(jìn)入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~