
肝了3天,深入總結(jié)了LinkedHashMap的面試必備知識(shí)點(diǎn)
概論
LinkedHashMap 通過特有底層雙向鏈表的支持,使得LinkedHashMap可以保存元素之間的順序,例如插入順序或者訪問順序,而HashMap因?yàn)闆]有雙向鏈表的支持,所以就不能保持這種順序,所以它的訪問就是隨機(jī)的了
和HashMap一樣,還是通過數(shù)組存儲(chǔ)元素的
這里的順序指的是遍歷的順序,定義了頭結(jié)點(diǎn)head,當(dāng)我們調(diào)用迭代器進(jìn)行遍歷時(shí),通過head開始遍歷,通過after屬性可以不斷找到下一個(gè),直到tail尾結(jié)點(diǎn),從而實(shí)現(xiàn)順序性。在同一個(gè)hash(其實(shí)更準(zhǔn)確的說是同一個(gè)下標(biāo),數(shù)組index ,在上圖中表現(xiàn)了同一列)鏈表內(nèi)部next和HashMap.Node.next 的效果是一樣的。不同點(diǎn)在于before和after可以連接不同hash之間的鏈表,也就是說雙向鏈表是可以跨任何index 連接的,也就是說將LinkedHashMap里面的所有元素按照特定的順序連接起來的
LinkedHashMap 的最終形態(tài)
圖中的黑色箭頭表示
next指針,這跟HashMap是一樣的;圖中的紅色箭頭表示
before和after指針,分別指向這個(gè)節(jié)點(diǎn)的前面和后面一個(gè)節(jié)點(diǎn),這就可以實(shí)現(xiàn)有序訪問;
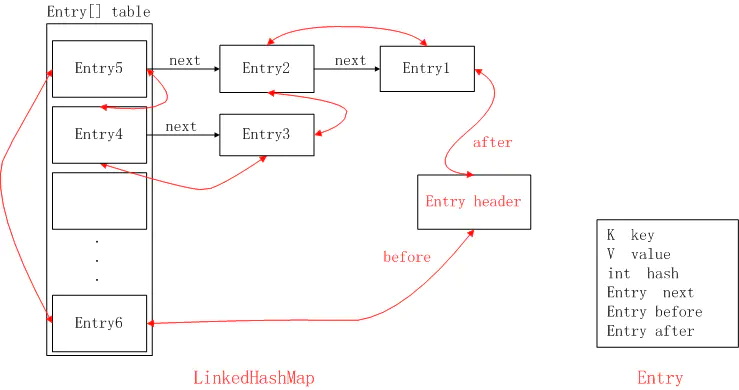
初識(shí)LinkedHashMap
我們想在頁面展示一周內(nèi)的消費(fèi)變化情況,用echarts面積圖進(jìn)行展示。如下:

我們?cè)诤笈_(tái)將數(shù)據(jù)構(gòu)造完成
?HashMap?map?=?new?HashMap<>();
?map.put("星期一",?40);
?map.put("星期二",?43);
?map.put("星期三",?35);
?map.put("星期四",?55);
?map.put("星期五",?45);
?map.put("星期六",?35);
?map.put("星期日",?30);
?for?(Map.Entry?entry?:?map.entrySet()){
?????System.out.println("key:?"?+?entry.getKey()?+?",?value:?"?+?entry.getValue());
?}
?/**
??*?結(jié)果如下:
??*?key:?星期二,?value:?40
??*?key:?星期六,?value:?35
??*?key:?星期三,?value:?50
??*?key:?星期四,?value:?55
??*?key:?星期五,?value:?45
??*?key:?星期日,?value:?65
??*?key:?星期一,?value:?30
??*/
然而頁面上一展示,發(fā)現(xiàn)并非如此,我們打印出來看,發(fā)現(xiàn)順序并非我們所想,先put進(jìn)去的先get出來
那么如何保證預(yù)期展示結(jié)果如我們所想呢,這個(gè)時(shí)候就需要用到LinkedHashMap實(shí)體,首先我們把上述代碼用LinkedHashMap進(jìn)行重構(gòu)
LinkedHashMap?map?=?new?LinkedHashMap<>();
map.put("星期一",?40);
map.put("星期二",?43);
map.put("星期三",?35);
map.put("星期四",?55);
map.put("星期五",?45);
map.put("星期六",?35);
map.put("星期日",?30);
for?(Map.Entry?entry?:?map.entrySet()){
????System.out.println("key:?"?+?entry.getKey()?+?",?value:?"?+?entry.getValue());
}
這個(gè)時(shí)候,結(jié)果正如我們所預(yù)期
key:?星期一,?value:?40
key:?星期二,?value:?43
key:?星期三,?value:?35
key:?星期四,?value:?55
key:?星期五,?value:?45
key:?星期六,?value:?35
key:?星期日,?value:?30
LinkedHashMap 的繼承關(guān)系
繼承關(guān)系圖
LinkedHashMap繼承了HashMap類,是HashMap的子類,LinkedHashMap的大多數(shù)方法的實(shí)現(xiàn)直接使用了父類HashMap的方法,LinkedHashMap可以說是HashMap和LinkedList的集合體,既使用了HashMap的數(shù)據(jù)結(jié)構(gòu),又借用了LinkedList雙向鏈表的結(jié)構(gòu)保存了記錄的插入順序,在用Iterator遍歷LinkedHashMap時(shí),先得到的記錄肯定是先插入的,也可以在構(gòu)造時(shí)帶參數(shù),按照訪問次序排序。

構(gòu)造方法
//?構(gòu)造方法1,構(gòu)造一個(gè)指定初始容量和負(fù)載因子的、按照插入順序的LinkedList
public?LinkedHashMap(int?initialCapacity,?float?loadFactor)?{
????super(initialCapacity,?loadFactor);
????accessOrder?=?false;
}
//?構(gòu)造方法2,構(gòu)造一個(gè)指定初始容量的LinkedHashMap,取得鍵值對(duì)的順序是插入順序
public?LinkedHashMap(int?initialCapacity)?{
????super(initialCapacity);
????accessOrder?=?false;
}
//?構(gòu)造方法3,用默認(rèn)的初始化容量和負(fù)載因子創(chuàng)建一個(gè)LinkedHashMap,取得鍵值對(duì)的順序是插入順序
public?LinkedHashMap()?{
????super();
????accessOrder?=?false;
}
//?構(gòu)造方法4,通過傳入的map創(chuàng)建一個(gè)LinkedHashMap,容量為默認(rèn)容量(16)和(map.zise()/DEFAULT_LOAD_FACTORY)+1的較大者,裝載因子為默認(rèn)值
public?LinkedHashMap(Map?m)?{
????super(m);
????accessOrder?=?false;
}
//?構(gòu)造方法5,根據(jù)指定容量、裝載因子和鍵值對(duì)保持順序創(chuàng)建一個(gè)LinkedHashMap
public?LinkedHashMap(int?initialCapacity,?float?loadFactor,?boolean?accessOrder)?{
????super(initialCapacity,?loadFactor);
????this.accessOrder?=?accessOrder;
}
我們發(fā)現(xiàn)除了多了一個(gè)變量accessOrder之外,并無不同,此變量到底起了什么作用?
/**
?*?The?iteration?ordering?method?for?this?linked?hash?map:?true
?*?for?access-order,?false?for?insertion-order.
?*
?*?@serial
?*/
final?boolean?accessOrder;
通過注釋發(fā)現(xiàn)該變量為true時(shí)access-order,即按訪問順序遍歷,如果為false,則表示按插入順序遍歷。默認(rèn)為false
LinkedHashMap 的關(guān)鍵內(nèi)部構(gòu)成
Entry
這個(gè)元素實(shí)際上是繼承自HashMap.Node 靜態(tài)內(nèi)部類 ,我們知道HashMap.Node 實(shí)際上是一個(gè)單鏈表,因?yàn)樗挥衝ext 節(jié)點(diǎn),但是這里L(fēng)inkedHashMap.Entry保留了HashMap的數(shù)據(jù)結(jié)構(gòu),同時(shí)有before, after 兩個(gè)節(jié)點(diǎn),一個(gè)前驅(qū)節(jié)點(diǎn)一個(gè)后繼節(jié)點(diǎn),從而實(shí)現(xiàn)了雙向鏈表

static?class?EntryV >?extends?HashMap.NodeV>?{
????Entry?before,?after;
????Entry(int?hash,?K?key,?V?value,?Node?next)?{
????????super(hash,?key,?value,?next);
????}
}
accessOrder
通過注釋發(fā)現(xiàn)該變量為true時(shí)access-order,即按訪問順序遍歷,此時(shí)你任何一次的操作,包括put、get操作,都會(huì)改變map中已有的存儲(chǔ)順序
如果為false,則表示按插入順序遍歷。默認(rèn)為false 也就是按照插入順序
/**
?*?The?iteration?ordering?method?for?this?linked?hash?map:?true
?*?for?access-order,?false?for?insertion-order.
?*
?*?@serial
?*/
final?boolean?accessOrder;
head ?tail
為了方便操作,加上有是雙向鏈表所有這里定義了兩個(gè)特殊的節(jié)點(diǎn),頭結(jié)點(diǎn)和尾部節(jié)點(diǎn)
???/**
?????*?The?head?(eldest)?of?the?doubly?linked?list.
?????*/
????transient?LinkedHashMap.Entry<K,V>?head;
????/**
?????*?The?tail?(youngest)?of?the?doubly?linked?list.
?????*/
????transient?LinkedHashMap.Entry<K,V>?tail;
newNode方法
LinkedHashMap重寫了newNode()方法,通過此方法保證了插入的順序性,在此之前我們先看一下HashMap 的newNode()方法
//?Create?a?regular?(non-tree)?node
Node?newNode(int?hash,?K?key,?V?value,?Node?next )? {
????return?new?Node<>(hash,?key,?value,?next);
}
然后我們?cè)倏匆幌翷inkedHashMap的newNode()方法
Node?newNode(int?hash,?K?key,?V?value,?Node?e )? {
????LinkedHashMap.Entry?p?=
????????new?LinkedHashMap.Entry(hash,?key,?value,?e);
????linkNodeLast(p);
????return?p;
}
這里調(diào)用了一個(gè)方法 linkNodeLast(),我們看一下這個(gè)方法,但是這和方法不止完成了串聯(lián)后置,也完成了串聯(lián)前置,所以插入的順序性是通過這個(gè)方法保證的。
//?link?at?the?end?of?list?將鏈表的尾節(jié)點(diǎn)和當(dāng)前節(jié)點(diǎn)串起來
private?void?linkNodeLast(LinkedHashMap.Entry?p )?{
????????//?將tail?的原始值記做last,因?yàn)橄旅嬉獙?duì)?tail?賦值
????LinkedHashMap.Entry?last?=?tail;
????//將新創(chuàng)建的節(jié)點(diǎn)p作為尾結(jié)點(diǎn)tail
????tail?=?p;
????//?如果last是null?也就是當(dāng)前節(jié)點(diǎn)是第一個(gè)節(jié)點(diǎn),否則last?不可能是null
????if?(last?==?null)
????????????//?因?yàn)槭堑谝粋€(gè)節(jié)點(diǎn),所以該節(jié)點(diǎn)也是head,所以該節(jié)點(diǎn)既是head?又是tail?
????????head?=?p;
????else?{
????????????//?此時(shí)p是tail節(jié)點(diǎn),那么原來的tail節(jié)點(diǎn)將成為?p節(jié)點(diǎn)前置節(jié)點(diǎn),p?節(jié)點(diǎn)也就是新的節(jié)點(diǎn)將成為原來節(jié)點(diǎn)的后置節(jié)點(diǎn)
????????p.before?=?last;
????????last.after?=?p;
????}
}
afterNodeAccess 方法
這里將HashMap 中的實(shí)現(xiàn)也帖了出來
//?Callbacks?to?allow?LinkedHashMap?post-actions
void?afterNodeAccess(Node?p) ?{?}
void?afterNodeInsertion(boolean?evict)?{?}
void?afterNodeRemoval(Node?p) ?{?}
關(guān)于afterNodeAccess()方法,在HashMap中沒給具體實(shí)現(xiàn),而在LinkedHashMap重寫了,目的是保證操作過的Node節(jié)點(diǎn)永遠(yuǎn)在最后,從而保證讀取的順序性,在調(diào)用put方法和get方法時(shí)都會(huì)用到
//?move?node?to?last?將節(jié)點(diǎn)移動(dòng)到最后(其實(shí)從這個(gè)注釋我們就可以知道,這個(gè)方法是干什么的了)
void?afterNodeAccess(Node?e )?{?
????LinkedHashMap.Entry?last;
????//?accessOrder?確定是按照訪問順序的,如果當(dāng)前節(jié)點(diǎn)不是最后節(jié)點(diǎn),因?yàn)槭堑脑捑筒挥靡屏?/span>
????if?(accessOrder?&&?(last?=?tail)?!=?e)?{
????????????//p:當(dāng)前節(jié)點(diǎn) b:當(dāng)前節(jié)點(diǎn)的前一個(gè)節(jié)點(diǎn) a:當(dāng)前節(jié)點(diǎn)的后一個(gè)節(jié)點(diǎn);
????????LinkedHashMap.Entry?p?=
????????????(LinkedHashMap.Entry)e,?b?=?p.before,?a?=?p.after;
????????//將p.after設(shè)置為null,斷開了與后一個(gè)節(jié)點(diǎn)的關(guān)系,但還未確定其位置????
????????p.after?=?null;
????????//?如果?p?的前置是null?也就是b?是null?那么此時(shí)?就是第一個(gè)節(jié)點(diǎn)也就是head?,因?yàn)閜?要后移,那么此時(shí)p?的后置應(yīng)該是head?了
????????if?(b?==?null)
????????????head?=?a;
????????//?如果不是的話,那么p?的后置也就是a?應(yīng)該代替p?的位置,成為b?的后置??b->p->a??=>??b->a???
????????else
????????????b.after?=?a;
????????//?到這里p?已經(jīng)成為一個(gè)游離的節(jié)點(diǎn)了,接下來我們只要找到一個(gè)位置將p?安置即可,目前的情況是?b->a?,如果a!=null?的話,也讓a?指向?b?=>?也就是?a?b?互指??b<->a??
????????if?(a?!=?null)
????????????a.before?=?b;
????????//?如果a==null?的話,也就是是b?將成為尾部節(jié)點(diǎn),此時(shí)第二次完成last?的賦值,此時(shí)last?指向b(這里有個(gè)問題是e不是tail?此時(shí)?a?就不可能是null)
????????else
????????????last?=?b;
????????//?這里就相當(dāng)于已經(jīng)找到了尾節(jié)點(diǎn),(?因?yàn)樯厦鎍!=null,此時(shí)last=tail也不是null,所以只會(huì)走else?)
????????if?(last?==?null)
????????????head?=?p;
????????else?{
????????????p.before?=?last;
????????????last.after?=?p;
????????}
????????//?完成新的tail?確定,也就是p?節(jié)點(diǎn),這下就知道上面為什么先讓?p.after?=?null?了吧
????????tail?=?p;
????????++modCount;
????}
}
前面說到的newNode()方法中調(diào)用的 linkNodeLast(Entry e)方法和現(xiàn)在的afterNodeAccess(Node e)都是將傳入的Node節(jié)點(diǎn)放到最后,那么它們的使用場(chǎng)景如何呢?
在上一節(jié)講HashMap的put流程,如果在對(duì)應(yīng)的hash位置上還沒有元素,那么直接new Node()放到數(shù)組table中,這個(gè)時(shí)候?qū)?yīng)到LinkedHashMap中,調(diào)用了newNode()方法,就會(huì)用到linkNodeLast(),將新node放到最后,
如果對(duì)應(yīng)的hash位置上有元素,進(jìn)行元素值的覆蓋時(shí),就會(huì)調(diào)用afterNodeAccess(),將原本可能不是最后的node節(jié)點(diǎn)移動(dòng)到了最后,下面給出了刪減之后的代碼邏輯
final?V?putVal(int?hash,?K?key,?V?value,?boolean?onlyIfAbsent,boolean?evict)?{
????if?((p?=?tab[i?=?(n?-?1)?&?hash])?==?null)
????????????//?調(diào)用linkNodeLast方法將新元素放到最后
????????tab[i]?=?newNode(hash,?key,?value,?null);
????else?{
????????if?(e?!=?null)?{
????????????//?existing?mapping?for?key
????????????V?oldValue?=?e.value;
????????????if?(!onlyIfAbsent?||?oldValue?==?null)
????????????????e.value?=?value;
????????????//?將存在的節(jié)點(diǎn)放到最后(因?yàn)榇嬖谒允茿ccess,也就是訪問存在的元素)
????????????afterNodeAccess(e);
????????????return?oldValue;
????????}
????}
????++modCount;
????if?(++size?>?threshold)
????????resize();
????//?這里就是插入到了樹的葉子節(jié)點(diǎn)或者是鏈表的末尾,也就是說本來就在末尾就不用操作了????
????afterNodeInsertion(evict);
????return?null;
}
下面給出一個(gè)例子
?@Test
?public?void?test1()?{
?????//?這里是按照訪問順序排序的
?????HashMap?m?=?new?LinkedHashMap<>(10,?0.75f,?true);
?????//?每次調(diào)用?put()?函數(shù),往?LinkedHashMap?中添加數(shù)據(jù)的時(shí)候,都會(huì)將數(shù)據(jù)添加到鏈表的尾部
?????m.put(3,?11);
?????m.put(1,?12);
?????m.put(5,?23);
?????m.put(2,?22);
?????//?再次將鍵值為 3 的數(shù)據(jù)放入到 LinkedHashMap 的時(shí)候,會(huì)先查找這個(gè)鍵值是否已經(jīng)有了,然后,再將已經(jīng)存在的?(3,11)?刪除,并且將新的?(3,26)?放到鏈表的尾部。
?????m.put(3,?26);
?????//?當(dāng)代碼訪問到 key 為 5 的數(shù)據(jù)的時(shí)候,我們將被訪問到的數(shù)據(jù)移動(dòng)到鏈表的尾部。
?????m.get(5);
?????//?那么此時(shí)的結(jié)果應(yīng)該是?1?2?3?5?因?yàn)?3?和?5?一次被移動(dòng)到了最后面去
?????for?(Map.Entry?e?:?m.entrySet())?{
?????????System.out.println(e.getKey());
?????}
?}
運(yùn)行結(jié)果如下
1
2
3
5
afterNodeInsertion 方法
關(guān)于afterNodeAccess()方法,在HashMap中依然沒給具體實(shí)現(xiàn),可以參考afterNodeAccess 中貼出的源代碼
LinkedHashMap中還重寫了afterNodeInsertion(boolean evict)方法,它的目的是移除鏈表中最老的節(jié)點(diǎn)對(duì)象,也就是當(dāng)前在頭部的節(jié)點(diǎn)對(duì)象,但實(shí)際上在JDK8中不會(huì)執(zhí)行,因?yàn)閞emoveEldestEntry方法始終返回false
?void?afterNodeInsertion(boolean?evict)?{?
????????//?possibly?remove?eldest
????LinkedHashMap.Entry?first;
????if?(evict?&&?(first?=?head)?!=?null?&&?removeEldestEntry(first))?{
????????K?key?=?first.key;
????????removeNode(hash(key),?key,?null,?false,?true);
????}
}
removeEldestEntry 方法的源代碼如下
protected?boolean?removeEldestEntry(Map.Entry?eldest) ?{
????return?false;
}
afterNodeInsertion 方法的意義是什么呢
因?yàn)閞emoveEldestEntry 固定返回false , 那這個(gè)方法的意義是什么呢 ?·
afterNodeInsertion方法的evict參數(shù)如果為false,表示哈希表處于創(chuàng)建模式。只有在使用Map集合作為構(gòu)造器參數(shù)創(chuàng)建LinkedHashMap或HashMap時(shí)才會(huì)為false,使用其他構(gòu)造器創(chuàng)建的LinkedHashMap,之后再調(diào)用put方法,該參數(shù)均為true。
下面給出了單獨(dú)put 的情況
?public?V?put(K?key,?V?value)?{
?????return?putVal(hash(key),?key,?value,?false,?true);
?}
?/**
??*?@param?evict?if?false,?the?table?is?in?creation?mode.
??*?@return?previous?value,?or?null?if?none
??*/
?final?V?putVal(int?hash,?K?key,?V?value,?boolean?onlyIfAbsent,boolean?evict)?
這里是使用Map集合作為構(gòu)造器參數(shù)創(chuàng)建的時(shí)的情況
public?HashMap(Map?m)?{
????this.loadFactor?=?DEFAULT_LOAD_FACTOR;
????putMapEntries(m,?false);
}
/**
?*?Implements?Map.putAll?and?Map?constructor.
?*
?*?@param?m?the?map
?*?@param?evict?false?when?initially?constructing?this?map,?else
?*?true?(relayed?to?method?afterNodeInsertion).
?*/
final?void?putMapEntries(Map?m,?boolean?evict)?{
????int?s?=?m.size();
????if?(s?>?0)?{
????????if?(table?==?null)?{?//?pre-size
????????????float?ft?=?((float)s?/?loadFactor)?+?1.0F;
????????????int?t?=?((ft?float)MAXIMUM_CAPACITY)??
?????????????????????(int)ft?:?MAXIMUM_CAPACITY);
????????????if?(t?>?threshold)
????????????????threshold?=?tableSizeFor(t);
????????}
????????else?if?(s?>?threshold)
????????????resize();
????????for?(Map.Entry?e?:?m.entrySet())?{
????????????K?key?=?e.getKey();
????????????V?value?=?e.getValue();
????????????putVal(hash(key),?key,?value,?false,?evict);
????????}
????}
}
哈哈,其實(shí)到這里還是沒有說這個(gè)方法的意義是什么,這里我們回過頭來想一下,看一下HashMap 中有類似的操作嗎,其實(shí)有的,就是這三個(gè)方法
//?Callbacks?to?allow?LinkedHashMap?post-actions
void?afterNodeAccess(Node?p) ?{?}
void?afterNodeInsertion(boolean?evict)?{?}
void?afterNodeRemoval(Node?p) ?{?}
很明顯這三個(gè)方法,都在LinkedHashMap 中被重寫了,所以下面的方法是因?yàn)槭怯蟹祷刂档模运辉谑强辗椒w了,而是一個(gè)直接返回false 的方法體了
protected?boolean?removeEldestEntry(Map.Entry?eldest) ?{
????return?false;
}
所以這里的意義就是讓你去實(shí)現(xiàn),為什么這么做呢?LinkedHashMap 就是用在記錄順序的場(chǎng)景下,一個(gè)典型應(yīng)用就是LRU,也就是主要用在緩存上面,因?yàn)榇藭r(shí)的設(shè)計(jì)雖然保留了LRU的基本特性,但是整個(gè)鏈表的大小是沒有限制的
大小沒有限制的緩存,哈哈 你懂了,后面肯定就是無限的GC了,因?yàn)檫@里都是強(qiáng)引用
實(shí)現(xiàn)一個(gè)大小確定的LRU(LinkedHashMap)
如果一個(gè)鏈表只能維持10個(gè)元素,那么當(dāng)插入了第11個(gè)元素時(shí),以如下方式重寫removeEldestEntry的話,那么將會(huì)刪除最老的一個(gè)元素
public?class?BuerLinkedHashMap<K,?V>?extends?LinkedHashMap<K,?V>?{
????private?int?maxCacheSiz;
????public?BuerLinkedHashMap(int?maxCacheSize)?{
????????super();
????????this.maxCacheSiz?=?maxCacheSize;
????}
????@Override
????protected?boolean?removeEldestEntry(Map.Entry?eldest) ?{
????????if?(size()?>?maxCacheSiz)?{
????????????System.out.println("即將執(zhí)行刪除");
????????????return?true;
????????}?else?{
????????????return?false;
????????}
????}
????public?static?void?main(String[]?args)?{
????????BuerLinkedHashMap?buerLinkedHashMap?=?new?BuerLinkedHashMap(10);
????????LinkedHashMap?linkedHashMap?=?new?LinkedHashMap(10);
????????for?(int?i?=?0;?i?11;?i++)?{
????????????buerLinkedHashMap.put(i,?i);
????????????linkedHashMap.put(i,?i);
????????}
????????System.out.println("不二map的大小:"+buerLinkedHashMap.size());
????????System.out.println("默認(rèn)map的大小:"+linkedHashMap.size());
????}
}
程序的運(yùn)行結(jié)果如下
即將執(zhí)行刪除
不二map的大小:10
默認(rèn)map的大小:11
afterNodeRemoval 方法
這個(gè)方法和上面的方法一樣,在HashMap 中都是沒有實(shí)現(xiàn)的,但是在LinkedHashMap的實(shí)現(xiàn)如下,其實(shí)這個(gè)方法是在刪除節(jié)點(diǎn)后調(diào)用的,可以思考一下為甚么
void?afterNodeRemoval(Node?e )?{?//?unlink
????????//?將要?jiǎng)h除的節(jié)點(diǎn)標(biāo)記為p,?b?是p?的前置,a?是p?的后置
????LinkedHashMap.Entry?p?=(LinkedHashMap.Entry)e,?b?=?p.before,?a?=?p.after;
????//?切點(diǎn)p?的前后連接
????p.before?=?p.after?=?null;
????//?p?的前置是null?的話,p?是要被刪除的,那么p?的后置將成為head
????if?(b?==?null)
????????head?=?a;
????//?p?的前置b?不是null?的話,b的前置p指向b的后置a即可,?也就是?b->p->a???=>?b->a?
????else
????????b.after?=?a;
???????//?a?是null?的話,p?則是原來的tail,那么新的tail?就是?b??????
????if?(a?==?null)
????????tail?=?b;
????//?如果a?不是null?則是一個(gè)普通的節(jié)點(diǎn),也就是說刪除的不是tail?則讓a?也指向b????
????else
????????a.before?=?b;
}
因?yàn)長inkedHashMap 的雙向鏈表連接了LinkedHashMap中的所有元素,HashMap中的刪除方法可以使沒有考慮這些的,它只考慮了如何存紅黑樹、鏈表中刪除節(jié)點(diǎn),所以它是不維護(hù)雙向鏈表的,所以這里才有了這個(gè)方法的實(shí)現(xiàn)
debug 源碼 插入元素的過程
有了HashMap 那一節(jié)和前面的鋪墊,接下來我們看一下完整的插入過程,下面將和HashMap 不一樣的地方標(biāo)注出來
其他細(xì)節(jié)請(qǐng)參考上一篇HashMap,因?yàn)?DRY(don't repeat yourself)
final?V?putVal(int?hash,?K?key,?V?value,?boolean?onlyIfAbsent,
???????????????boolean?evict)?{
????Node[]?tab;?Node?p;?int?n,?i;
????if?((tab?=?table)?==?null?||?(n?=?tab.length)?==?0)
????????n?=?(tab?=?resize()).length;
????if?((p?=?tab[i?=?(n?-?1)?&?hash])?==?null)
????????????//?首先newNode方法是重寫了的,在插入元素的同時(shí)將元素放到了鏈表的尾部,具體可以參考上面對(duì)這個(gè)方法的解析
????????tab[i]?=?newNode(hash,?key,?value,?null);
????else?{
????????Node?e;?K?k;
????????if?(p.hash?==?hash?&&
????????????((k?=?p.key)?==?key?||?(key?!=?null?&&?key.equals(k))))
????????????e?=?p;
????????else?if?(p?instanceof?TreeNode)
????????????e?=?((TreeNode)p).putTreeVal(this,?tab,?hash,?key,?value);
????????else?{
????????????for?(int?binCount?=?0;?;?++binCount)?{
????????????????if?((e?=?p.next)?==?null)?{
????????????????????p.next?=?newNode(hash,?key,?value,?null);
????????????????????if?(binCount?>=?TREEIFY_THRESHOLD?-?1)?//?-1?for?1st
????????????????????????treeifyBin(tab,?hash);
????????????????????break;
????????????????}
????????????????if?(e.hash?==?hash?&&
????????????????????((k?=?e.key)?==?key?||?(key?!=?null?&&?key.equals(k))))
????????????????????break;
????????????????p?=?e;
????????????}
????????}
????????if?(e?!=?null)?{?//?existing?mapping?for?key
????????????V?oldValue?=?e.value;
????????????if?(!onlyIfAbsent?||?oldValue?==?null)
????????????????e.value?=?value;
???????????????//?這里說明這個(gè)key?已經(jīng)存在,就相當(dāng)于與是對(duì)這個(gè)key?的一次訪問,所以訪問結(jié)束之后調(diào)用了?afterNodeAccess(e),其實(shí)這里還有一點(diǎn)要說明,即使存在的key?是在鏈表的尾部或者是在樹的葉子節(jié)點(diǎn)
???????????????//?也算是訪問,所以這里并沒有要求位置,只要求存在,所以afterNodeAccess?中判斷了e?是不是?tail
????????????afterNodeAccess(e);
????????????return?oldValue;
????????}
????}
????++modCount;
????if?(++size?>?threshold)
????????resize();
????//?這個(gè)方法和??afterNodeAccess(e)??linkNodeLast(p)?都不一樣,因?yàn)樗鼪]有傳入元素,下面單獨(dú)對(duì)著一點(diǎn)進(jìn)行解釋一下
????afterNodeInsertion(evict);
????return?null;
}
獲取元素的過程
首先 LinkedHashMap 重寫了get 方法,getNode 方法依然使用的實(shí)HashMap 的,當(dāng)元素存在的時(shí)候,判斷是否要根據(jù)accessOrder 將元素移動(dòng)到雙向鏈表的尾部
public?V?get(Object?key)?{
????Node?e;
????if?((e?=?getNode(hash(key),?key))?==?null)
????????return?null;
????if?(accessOrder)
????????afterNodeAccess(e);
????return?e.value;
}

刪除元素的過程
Hashmap 一節(jié),我們也沒有講remove 方法,所以這里我們來看一下,細(xì)節(jié)的一些東西都寫在注釋里了,首先remove 方法是有返回值的,存在則返回key 對(duì)應(yīng)的value 不存在則返回null
public?V?remove(Object?key)?{
????Node?e;
????return?(e?=?removeNode(hash(key),?key,?null,?false,?true))?==?null??
????????null?:?e.value;
}
//?實(shí)際執(zhí)行刪除的方法
final?Node?removeNode(int?hash,?Object?key,?Object?value,
???????????????????????????boolean?matchValue,?boolean?movable)? {
????Node[]?tab;?Node?p;?int?n,?index;
????//?數(shù)組不為空且有元素,并且tab[index?=?(n?-?1)?&?hash]!=null?也就是這個(gè)桶上得有元素,不是空桶?否則返回null
????if?((tab?=?table)?!=?null?&&?(n?=?tab.length)?>?0?&&?(p?=?tab[index?=?(n?-?1)?&?hash])?!=?null)?{
????????//?node?要?jiǎng)h除的節(jié)點(diǎn)
????????Node?node?=?null,?e;?K?k;?V?v;
????????//p?就是當(dāng)前節(jié)點(diǎn),也就是和我們要?jiǎng)h除的key?在同一個(gè)桶上的第一個(gè)節(jié)點(diǎn),判斷p?是不是要?jiǎng)h除的節(jié)點(diǎn)?是則標(biāo)記為node?
????????if?(p.hash?==?hash?&&?((k?=?p.key)?==?key?||?(key?!=?null?&&?key.equals(k))))
????????????node?=?p;
????????//?不是的話,開始遍歷,可能是鏈表可能是樹,前提是當(dāng)前節(jié)點(diǎn)的next?節(jié)點(diǎn)那不為空,如果為空的話,就不用遍歷了
????????//因?yàn)楫?dāng)前節(jié)點(diǎn)不是要?jiǎng)h除的節(jié)點(diǎn),并且當(dāng)前節(jié)點(diǎn)么有next,那就是不存在了
????????else?if?((e?=?p.next)?!=?null)?{
????????????????//?判斷是不是樹
????????????if?(p?instanceof?TreeNode)
????????????????node?=?((TreeNode)p).getTreeNode(hash,?key);
????????????else?{
???????????????//?不是樹的話,那就一定是鏈表了
????????????????do?{
????????????????????????//?這個(gè)判斷方式和上面的判斷方式是一樣的,找到了要?jiǎng)h除的節(jié)點(diǎn)就跳出循環(huán)
????????????????????if?(e.hash?==?hash?&&((k?=?e.key)?==?key?||??(key?!=?null?&&?key.equals(k))))?{
????????????????????????node?=?e;
????????????????????????break;
????????????????????}
????????????????????//?p?是?e?的前一個(gè)節(jié)點(diǎn),當(dāng)node?是要?jiǎng)h除的節(jié)點(diǎn)的時(shí)候,p?就是待刪除節(jié)點(diǎn)的前一個(gè)節(jié)點(diǎn)
????????????????????p?=?e;
????????????????}?while?((e?=?e.next)?!=?null);
????????????}
????????}
????????//?判斷有沒有找到要?jiǎng)h除的節(jié)點(diǎn),并且這里有其他的條件,因?yàn)樯厦媾袛嗍遣皇且獎(jiǎng)h除的節(jié)點(diǎn)僅僅判斷了key?是不是同一個(gè)key?
????????if?(node?!=?null?&&?(!matchValue?||?(v?=?node.value)?==?value?||?(value?!=?null?&&?value.equals(v))))?{
????????????????//?樹刪除
????????????if?(node?instanceof?TreeNode)
????????????????((TreeNode)node).removeTreeNode(this,?tab,?movable);
????????????//?此時(shí)只有一個(gè)節(jié)點(diǎn),也就是也就是一開始的第一個(gè)if?處的判斷條件為true,就是說要?jiǎng)h除節(jié)點(diǎn)就是鏈表的第一個(gè)節(jié)點(diǎn)
????????????else?if?(node?==?p)
????????????????tab[index]?=?node.next;
????????????//?鏈表刪除,此時(shí)p?是node?的前一個(gè)節(jié)點(diǎn)????
????????????else
????????????????p.next?=?node.next;
????????????//?標(biāo)記修改????
????????????++modCount;
????????????//?修改size?大小
????????????--size;
????????????afterNodeRemoval(node);
????????????return?node;
????????}
????}
????return?null;
}
matchValue 判斷刪除的時(shí)候,是否要求節(jié)點(diǎn)的值是相同的,True 則表示找到key相同的節(jié)點(diǎn)之后,還需要判斷值是相等的才可以使刪除。下面就是判斷條件,可以自己分析一下
(!matchValue?||?(v?=?node.value)?==?value?||?(value?!=?null?&&?value.equals(v)))
LinkedHashMap重寫了其中的afterNodeRemoval(Node e),該方法在HashMap中沒有具體實(shí)現(xiàn),通過此方法在刪除節(jié)點(diǎn)的時(shí)候調(diào)整了雙鏈表的結(jié)構(gòu)。
總結(jié)
LinkedHashMap 的有序性
LinkedHashMap 指的是遍歷的時(shí)候的有序性,而有序性是通過雙向鏈表實(shí)現(xiàn)的,真實(shí)的存儲(chǔ)之間是沒有順序的,和Hashmap 一樣
如何實(shí)現(xiàn)一個(gè)固定大小的LinkedHashMap
繼承LinkedHashMap實(shí)現(xiàn)removeEldestEntry 方法,當(dāng)插入成功后,判斷是否要?jiǎng)h除最老節(jié)點(diǎn)
四個(gè)維護(hù)雙向鏈表的方法
afterNodeAccess(Node p)
訪問元素之后維護(hù)
afterNodeInsertion(boolean evict)
插入元素之后維護(hù)
afterNodeRemoval(Node p)
刪除元素之后維護(hù)
linkNodeLast
也是插入元素之后維護(hù),但是只用于桶上的第一個(gè)節(jié)點(diǎn),后面的節(jié)點(diǎn)都是用afterNodeAccess或者afterNodeInsertion
你覺得LinkedHashMap 還有什么可以改進(jìn)的地方嗎,歡迎討論
和上一節(jié)一樣這里我依然給出這個(gè)思考題,雖然我們的說法可能不對(duì),可能我們永遠(yuǎn)也站不到源代碼作者當(dāng)年的高度,但是我們依然積極思考,大膽討論
雖然java 源代碼的山很高,如果你想跨越,至少你得有登山的勇氣,這里我給出自己的一點(diǎn)點(diǎn)愚見,希望各位不吝指教
afterNodeAccess() 方里面有幾處判斷個(gè)人覺得是不需要的,具體可以看afterNodeAccess方法里我寫的注釋,歡迎大佬討論,謝謝!