
漫畫全面解釋Spark企業(yè)調(diào)優(yōu)點


一:資源配置

一般企業(yè)中,物理機器的cpu:內(nèi)存基本上都是1:4+,比如機器24core,一般有128GB及以上內(nèi)存;48core,一般有256GB及以上內(nèi)存。
減去系統(tǒng)及hdfs所需core,2個吧;減去系統(tǒng)的2-4GB,減去存儲hdfs的相關(guān)的假設(shè)20GB吧(hbase需要的更多點,但是一般hbase會有獨立集群)。
24core,128GB的機器應該還剩還有20core,100GB。
這種情況下,很明顯,你1core對應5GB內(nèi)存才能最大化利用機器,否則往往cpu沒了,內(nèi)存還有大把,應用還容易出現(xiàn)gc問題。
所以,假設(shè)你的業(yè)務cpu確實消耗比較少,可以在配置yarn的時候虛擬cpu可以設(shè)置為物理cpu的n倍。這樣才可以滿足小白,1:1的分配cpu內(nèi)存的需求。
yarn.nodemanager.resource.cpu-vcores 二:數(shù)據(jù)傾斜



1.對于離線,任務生成文件的時候,可以采用支持分割的壓縮算法。常見的壓縮算法如下:
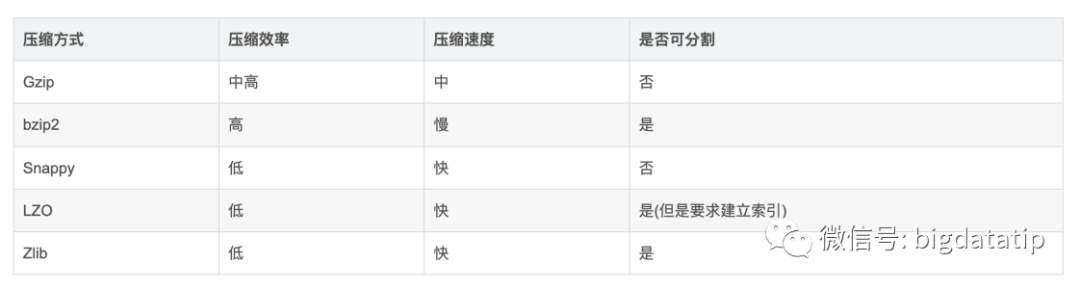
對于離線,任務生成文件的時候,也可以合理控制生成文件的大小,落地之前進行均衡。
2.對于實時,生產(chǎn)者生產(chǎn)數(shù)據(jù)到kafka的時候,進行均衡,一般可以采取隨機或者輪訓的生產(chǎn)。假設(shè)要保證相同用戶的數(shù)據(jù)到相同的分區(qū),也可以對實用hash的方式。

1.遇到shuffle過程中數(shù)據(jù)傾斜的時候,往往需要做的第一件事情就是增大shuffle并行度,只要不是key過于集中與某一個或者幾個key都會有效。
2.假設(shè)key過于集中,有以下幾個策略可以用來改善:
2.1 先跑采樣wordcount,看看key的集中情況。
2.2 個別key特別大,可以拿出來單獨處理。
2.2 一堆key特別大,可以如下操作:
key加隨機后綴,分兩次進行聚合,比如隨機后綴的范圍是0-100,相當于并行度擴大了100倍,最后再聚合一次即可。
2.3 join的時候key傾斜。
大表 join 小表,廣播小表。
大表 join 大表,預先治理,采用相同分桶策略,使得同一個task完成join,減少數(shù)據(jù)shuffle傳輸。后面案例詳解。

1.用戶自己管理的大狀態(tài)。
1.1 超時,可以使用具有超時功能的超時的map,如caffeine。
1.2 確認狀態(tài)是不是可以進行分區(qū)緩存。
1.3 換外部內(nèi)存存儲,如redis,alluxio。
2.updateStateBykey等算子。
2.1 設(shè)置超時時間,spark新版本都支持了,之前版本需要自己維護超時時間。
2.2 換外部內(nèi)存存儲,如redis,alluxio。
四:大對象

如下面一段代碼:
distData.foreach(each=>{val map = new mutable.HashMap[String,Int]();map.put("key",2)// 邏輯處理map.clear(); // 不要忘了哦})
