
深度學(xué)習(xí)三大謎團:集成、知識蒸餾和自蒸餾

來源 |?智源社區(qū)
集成(Ensemble,又稱模型平均)是一種「古老」而強大的方法。只需要對同一個訓(xùn)練數(shù)據(jù)集上,幾個獨立訓(xùn)練的神經(jīng)網(wǎng)絡(luò)的輸出,簡單地求平均,便可以獲得比原有模型更高的性能。甚至只要這些模型初始化條件不同,即使擁有相同的架構(gòu),集成方法依然能夠?qū)⑿阅茱@著提升。
但是,為什么只是簡單的「集成」,便能提升性能呢?
目前已有的理論解釋大多只能適用于以下幾種情況:
(1)boosting:模型之間的組合系數(shù)是訓(xùn)練出來的,而不能簡單地取平均;
(2)Bootstrap aggregation:每個模型的訓(xùn)練數(shù)據(jù)集都不相同;
(3)每個模型的類型和體系架構(gòu)都不相同;
(4)隨機特征或決策樹的集合。
但正如上面提到,在(1)模型系數(shù)只是簡單的求平均;(2)訓(xùn)練數(shù)據(jù)集完全相同;(3)每個模型架構(gòu)完全相同 下,集成的方法都能夠做到性能提升。

論文鏈接:https://arxiv.org/pdf/2012.09816.pdf
來自微軟研究院機器學(xué)習(xí)與優(yōu)化組的高級研究員朱澤園博士,以及卡內(nèi)基梅隆大學(xué)機器學(xué)習(xí)系助理教授李遠志針對這一現(xiàn)象,在最新發(fā)表的論文《在深度學(xué)習(xí)中理解集成,知識蒸餾和自蒸餾》(Towards Understanding Ensemble, Knowledge Distillation, and Self-Distillation in Deep Learning)中,提出了一個理論問題:

當(dāng)我們簡單地對幾個獨立訓(xùn)練的神經(jīng)網(wǎng)絡(luò)求平均值時,「集成」是如何改善深度學(xué)習(xí)的測試性能的?尤其是當(dāng)所有神經(jīng)網(wǎng)絡(luò)具有相同的體系結(jié)構(gòu),使用相同的標準訓(xùn)練算法(即具有相同學(xué)習(xí)率和樣本正則化的隨機梯度下降),在相同數(shù)據(jù)集上進行訓(xùn)練時,即使所有單個模型都已經(jīng)進行了100%訓(xùn)練準確性?隨后,將集合的這種優(yōu)越性能「蒸餾」到相同架構(gòu)的單個神經(jīng)網(wǎng)絡(luò),為何能夠保持性能基本不變?
兩位作者分別從理論和實驗的角度給出了分析結(jié)果:
原因在于數(shù)據(jù)集中「多視圖」(Multi-view)數(shù)據(jù)的存在。

朱澤園(Zeyuan Allen-Zhu)
朱澤園博士目前就職于微軟總部 AI 研究院。南京外國語畢業(yè),高一保送清華;2005、2006兩年蟬聯(lián)IOI金牌,2009年ACM總決賽亞軍;清華畢業(yè)后在MIT讀完碩博,后在普林斯頓進修博士后。

李遠志(Yuanzhi Li)
另一位作者李遠志,現(xiàn)任美國卡內(nèi)基·梅隆大學(xué)(CMU)機器學(xué)習(xí)系助理教授,也是微軟研究院的訪問研究員。他于2010年到2014年在清華姚班進行本科學(xué)習(xí),于2018年在普林斯頓大學(xué)獲得博士學(xué)位,在斯坦福大學(xué)做了一年博士后之后,加入CMU擔(dān)任助理教授。其研究方向主要為深度學(xué)習(xí)的基礎(chǔ)理論與實踐,凸優(yōu)化算法與非凸優(yōu)化算法設(shè)計,數(shù)據(jù)處理算法分析等。
?
?1?
深度學(xué)習(xí)的三大謎團
謎團 1:集成
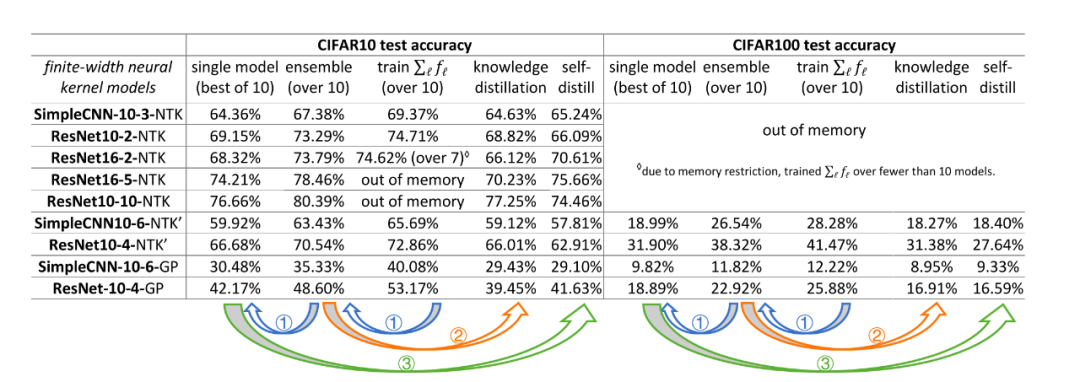
觀察結(jié)果顯示,使用不同隨機種子的學(xué)習(xí)網(wǎng)絡(luò)??1,…??10(盡管具有非常相似的測試性能)相關(guān)聯(lián)的函數(shù)非常不同。在這種情況下,使用“集成”的技術(shù),僅需要獲取這些經(jīng)過獨立訓(xùn)練的網(wǎng)絡(luò)輸出的未加權(quán)平均值,就可以在許多深度學(xué)習(xí)應(yīng)用中極大地提高測試時間的性能。(參見圖1)這意味著各個函數(shù)??1,…??10一定是不同的。但是,為什么集成可以大幅提升性能呢?
如果直接訓(xùn)練(??1+?+??10)/ 10,為什么性能提升就消失了?
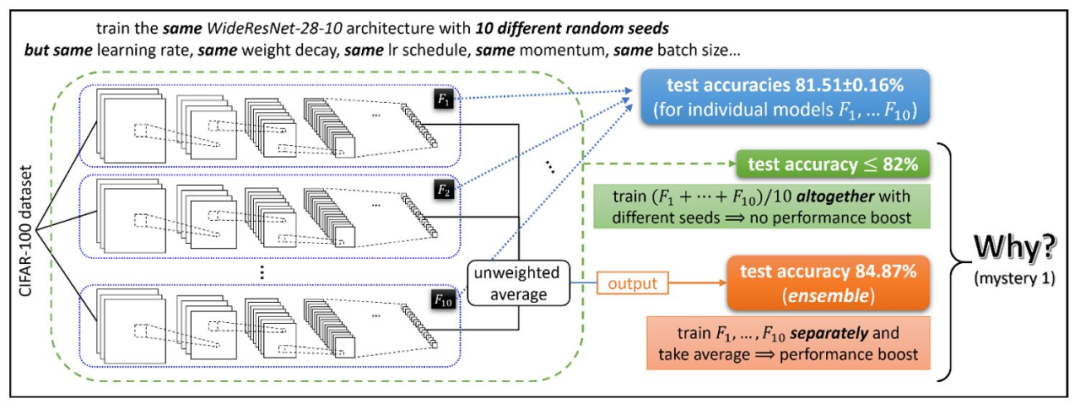
圖1:集成(Ensemble)提升了深度學(xué)習(xí)應(yīng)用中的測試準確性,但是這種準確性的提高則無法通過直接訓(xùn)練模型的平均值來實現(xiàn)。
謎團2:知識蒸餾
雖然集成可以極大地提升測試時間性能,但在推理時間(即測試時間)方面它變慢了10倍:我們需要計算10個神經(jīng)網(wǎng)絡(luò)的輸出,而不是1個。當(dāng)我們在低能耗的移動環(huán)境中部署此類模型時,這是一個嚴重的問題。
為了解決這個問題,研究者提出了一種叫做知識蒸餾的開創(chuàng)性技術(shù)。知識蒸餾指的是訓(xùn)練另一個單獨的模型來匹配集成的輸出。在這里,一張貓的圖像上的集成(也稱為隱藏知識)輸出可能看起來像“ 80%貓+ 10%狗+ 10%汽車”,而真正的訓(xùn)練標簽是“ 100%貓”。(請參見下面的圖2)
事實證明,經(jīng)過這樣訓(xùn)練的單個模型可以在很大程度上匹配10倍以上集成模型的測試時間性能。但是,這導(dǎo)致了更多的問題。
與匹配真實標簽相比,為什么匹配集成模型的輸出可以為我們提供更好的測試準確性?此外,我們在知識蒸餾后對模型進行集成學(xué)習(xí)可以進一步提高測試準確性嗎?
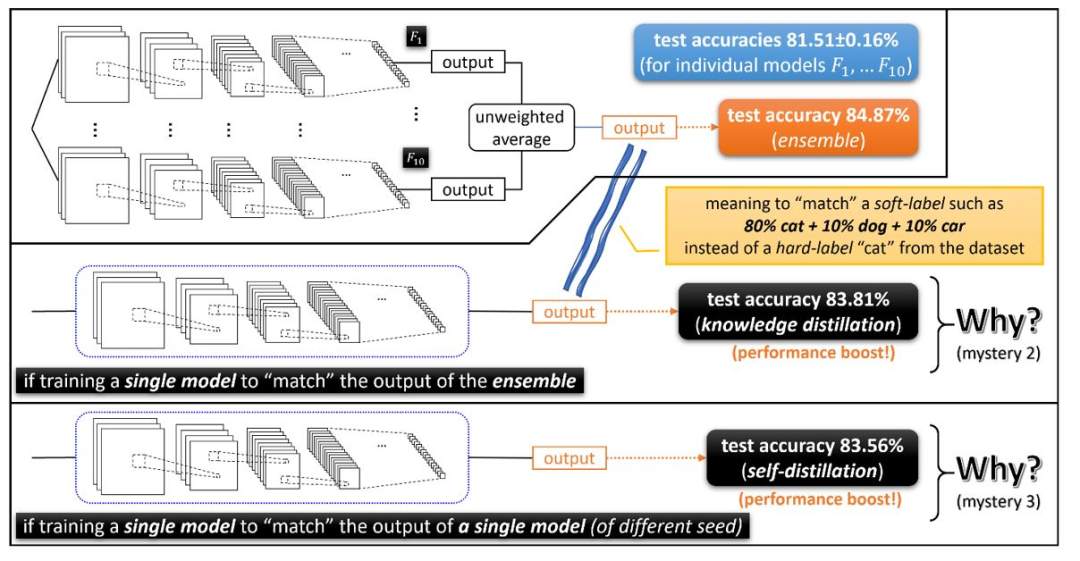
圖2:知識蒸餾和自蒸餾也能夠提升深度學(xué)習(xí)的性能。
謎團3: 自蒸餾
注意,知識蒸餾至少在直觀上是有意義的:teacher model有84.8% 的測試準確率,那么student model 可以達到83.8% 。
但接下來這個現(xiàn)象就讓人難以理解了,使用自蒸餾技術(shù),也即老師的學(xué)生就是它自己:通過對具有相同架構(gòu)的單個模型進行知識蒸餾,竟然可以提高測試準確率。
想象一下: 訓(xùn)練出一個測試準確率為81.5% 的單個模型,結(jié)果使用相同結(jié)構(gòu)的模型進行自蒸餾一下,測試準確率竟然提高到了83.5%,這不是很奇怪么?
?
?2?
神經(jīng)網(wǎng)絡(luò)集成與特征映射集成
大多數(shù)現(xiàn)有的集成理論只適用于單個模型之間存在根本性差異的情況(例如,決策樹支持不同變量的子集),或者在不同的數(shù)據(jù)集上訓(xùn)練的情況(例如自舉)。
但這些理論顯然不能解釋前面提到的現(xiàn)象。上面提到,集成的模型,其訓(xùn)練的框架是相同的,訓(xùn)練的數(shù)據(jù)也是相同的 —— 唯一的區(qū)別只是訓(xùn)練期間的隨機性。
或許,與深度學(xué)習(xí)中的集成最為相近的理論,應(yīng)該是「隨機特征映射集成」(ensemble in random feature mappings)。這表現(xiàn)在兩個方面:一方面,將多個隨機特征的線性模型進行組合,可以提升測試時的性能,這很顯然,因為它增加了特征的數(shù)量;另一方面,在特定的參數(shù)區(qū)域中,神經(jīng)網(wǎng)絡(luò)的權(quán)值可以非常接近它們的初始化(稱為神經(jīng)正切核區(qū)域,或 NTK區(qū)域) ,結(jié)果網(wǎng)絡(luò)只在規(guī)定的特征映射上學(xué)習(xí)一個線性函數(shù),這些特征映射完全由隨機初始化決定。
將這兩者結(jié)合起來,可以推測深度學(xué)習(xí)集成與隨機特征映射集成,在原理上是一致的。
這就引出了另外一個問題:
集成和知識蒸餾在深度學(xué)習(xí)上,與在隨機特征映射(即NTK特征映射)上,是否會有相同的表現(xiàn)呢?
答案是否定的。
如下圖3所示,該圖比較了在深度學(xué)習(xí)/隨機特征映射中的集成和知識蒸餾的性能。

圖3: 集成在隨機特征映射上有效(但是出于與深度學(xué)習(xí)完全不同的原因) ,而知識蒸餾在隨機特征映射中不起作用。
可以看出,通過集成的方式,無論是在深度學(xué)習(xí)中,還是在隨機特征映射中,都能夠得到較好的性能;而在隨機特征映射中,知識蒸餾的性能顯然要比單個模型的性能還要差。
這就很明顯地說明:集成和蒸餾,原理上并不相同。
具體來說:
與在深度學(xué)習(xí)情況不同,在隨機特征映射中,集成的優(yōu)越性能不能蒸餾到單個模型上。
在圖3中,神經(jīng)正切核(NTK)模型的集成,在 CIFAR-10數(shù)據(jù)集上達到了70.54% 的準確率,但經(jīng)過知識蒸餾后,它下降到了66.01% ,甚至比單個模型的66.68% 的測試準確率還要低。
在深度學(xué)習(xí)中,直接訓(xùn)練模型的平均值(??1+?+??10)/10 與訓(xùn)練單個模型 ???? 相比沒有任何優(yōu)勢;而在隨機特征映射中,訓(xùn)練平均值的效果優(yōu)于單個模型及其集成。
在圖3中,NTK 模型的集成的準確率為 70.54% ,而直接訓(xùn)練10個模型的平均值準確率為72.86%。
為什么會這樣呢?
主要原因在于,神經(jīng)網(wǎng)絡(luò)是使用分層特征學(xué)習(xí),盡管每個模型????有不同的初始化,但在每一層它們都擁有相同的特征集合。因此,與單個模型相比,多個模型的平均模型,并沒有增加其特征集合的大小。
在隨機特征映射中,每個 ???? 都使用了一組完全不同的規(guī)定特征。因此,無論是使用集成的方式,還是直接求平均的方式,都能夠帶來一些性能優(yōu)勢,但由于特征的稀缺性,在蒸餾后,性能必然會有一定下降。
?3?
集成與減少單個模型的方差
除了隨機特征的集成外,還有人推測認為,由于神經(jīng)網(wǎng)絡(luò)的高度復(fù)雜性,每個單獨的模型 ???? 可能學(xué)習(xí)到一個函數(shù) ?????(??)=??+ξ??,ξ?? 是某種噪聲,這種噪聲取決于訓(xùn)練過程中使用的隨機性。
經(jīng)典的統(tǒng)計學(xué)認為,如果所有的ξ??是大致獨立的,那么求取他們的平均值能夠大大減少噪音量。
因此,
“集成能夠減少方差”真的是集成能提高提高性能的原因嗎?
證據(jù)表明,在深度學(xué)習(xí)的背景下,這種減少方差來提升性能的假設(shè)是值得懷疑的:
1. 集成并不能無限制地提高測試的準確性。
集成超過100個單個模型通常,與集成10個單個模型基本沒有差別。因此,100 ξ?? 的平均值與10 ξ?? 的平均值相比,方差不再減小,表明 ξ?? 可能是不獨立的,而且有可能存在偏差,因此均值不為零。在ξ?? 不獨立的情況下,很難討論求得這些 ξ?? 的平均值能夠減少多少偏差。
2. 即使理想情況下,我們認為ξ?? 是相互獨立的,那么這就表明ξ?? 是有偏或異號的。
于是我們可以將 ???? 寫成:
????(x)=??+ξ+ξ??
ξ 是一個固定誤差,ξ?? 則指每個模型的獨立誤差。于是在集成之后,期望的網(wǎng)絡(luò)輸出將接近 y + ξ,這會有一個固定的偏差 ξ。
在這種情況下,為什么知識蒸餾會有效呢?那么,為什么這個帶有偏差 ξ (也被稱為隱藏知識)的輸出會優(yōu)于原來的訓(xùn)練呢?
3. 集成學(xué)習(xí)并不總是能夠提高準確性
在圖4中,我們可以看到神經(jīng)網(wǎng)絡(luò)的集成學(xué)習(xí)并不總是能夠提高測試的準確性,至少在輸入類似高斯分布的情況下是這樣。
換句話說,在這些網(wǎng)絡(luò)中,求平均值不會帶來任何準確性的增益。
綜上來看,我們需要更深入地理解深度學(xué)習(xí)中的集成,而不只是認為“集成能夠減少方差”這么簡單。

圖4:當(dāng)輸入類似高斯分布時,實驗表明集成并不能提高測試的準確性。
?4?
多視圖數(shù)據(jù):深度學(xué)習(xí)中集成的一種新方法
圖4 表明,在非結(jié)構(gòu)化隨機輸入的情況下,集成并不湊效。
在我們最新的工作中,我們從數(shù)據(jù)中找到了集成之所以能夠在深度學(xué)習(xí)中有效的原因所在。
通常,在一個數(shù)據(jù)集中(以視覺數(shù)據(jù)集為例),一個對象通常會有多個視角(muti-view)的數(shù)據(jù)。以「car」為例,一個汽車的數(shù)據(jù)集中,通常會有從各個角度拍攝的車輛的照片,通常我們僅需要通過車頭燈、車輪或車窗等其中的一個特征,便可以對汽車進行分類了;即使在圖片中有些特征因為拍攝角度的原因而缺失了,也沒有太大的關(guān)系。例如從正前方拍攝的汽車,圖像中便沒有車輪,但這并不妨礙我們識別出「car」。
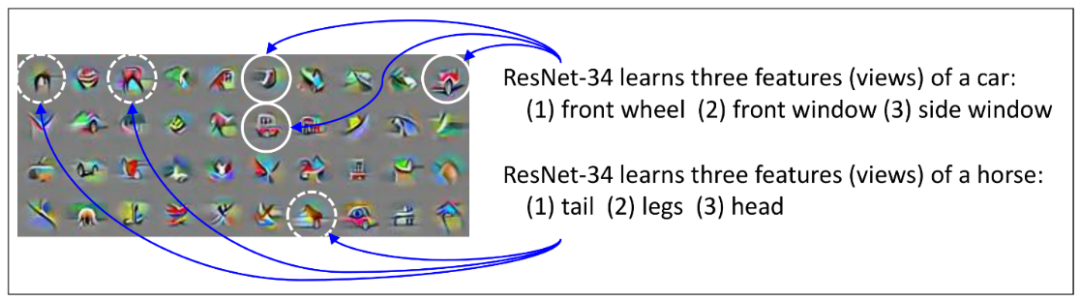
圖5:在CIFAR-10數(shù)據(jù)集上進行訓(xùn)練的 ResNet-34第23層的一些通道的可視化。
這種現(xiàn)象在多數(shù)數(shù)據(jù)中都會存在,其中每類數(shù)據(jù)都具有多個視角的特征,這種結(jié)構(gòu)被稱為“多視圖”(multi-view)。
在大多數(shù)數(shù)據(jù)中,幾乎所有的視圖特征都會顯示出來;但在某些數(shù)據(jù)中,卻可能缺少一些視圖特征。
更廣泛地說,這種“多視圖”結(jié)構(gòu)事實上,不僅在原始數(shù)據(jù)中存在,在中間層抽取的特征集合中也會存在。
在這種“多視圖”結(jié)構(gòu)下進行訓(xùn)練,網(wǎng)絡(luò)會:
1)根據(jù)學(xué)習(xí)過程中的隨機性,快速學(xué)習(xí)這些視圖特征的一個子集;
2)會使用這些視圖特征,記下剩余那些少量不能正確分類的數(shù)據(jù)。
第一點意味著,如果將不同網(wǎng)絡(luò)進行集成,將能夠把學(xué)習(xí)到的視圖特征聚合起來,從而達到更高的測試精度。
第二點意味著,單個模型不能學(xué)習(xí)所有的視圖特性,不是因為它們沒有足夠的容量,而是因為沒有足夠的訓(xùn)練數(shù)據(jù);大多數(shù)數(shù)據(jù)已經(jīng)被現(xiàn)有的視圖特征正確分類,因此在訓(xùn)練階段,它們基本上不提供梯度。
?5?
知識蒸餾: 強制單個模型學(xué)習(xí)多個視圖
基于上述視角,我們可以再來分析知識蒸餾是如何工作的。
在現(xiàn)實生活的場景中,一些汽車圖像可能看起來“更像一只貓”:例如,一些汽車圖像的前燈可能看起來像貓眼。當(dāng)這種情況發(fā)生時,集成模型可以提供有意義的隱藏知識,例如“汽車圖像 X 有10% 像一只貓。”
這里是個關(guān)鍵點。在訓(xùn)練單個神經(jīng)網(wǎng)絡(luò)模型時,如果沒有學(xué)習(xí)“前燈”視圖,剩下的視圖或許仍然有可能根據(jù)別的視圖將圖像 x 標記為汽車,但它卻無法匹配隱藏知識“圖像 X 有10% 像貓”。
而在知識蒸餾的過程中,蒸餾模型會學(xué)習(xí)每一個可能的視圖特征,來匹配集成的性能。需要注意的是,深度學(xué)習(xí)中知識蒸餾的關(guān)鍵是,作為一個神經(jīng)網(wǎng)絡(luò),單個模型在特征學(xué)習(xí)中能夠?qū)W習(xí)到集成的所有特征。這與實驗中觀察到的情況是一致的。(見圖6)
 圖6:知識蒸餾已經(jīng)從集成中學(xué)習(xí)了大部分視圖特性,因此在知識蒸餾之后對模型進行集成學(xué)習(xí)不會帶來更多的性能提升。
圖6:知識蒸餾已經(jīng)從集成中學(xué)習(xí)了大部分視圖特性,因此在知識蒸餾之后對模型進行集成學(xué)習(xí)不會帶來更多的性能提升。
?
?6?
自蒸餾: 集成與知識蒸餾的隱性結(jié)合
這個解釋也可以用到知識自蒸餾中——訓(xùn)練一個模型來匹配另一個相同的架構(gòu)的模型(但使用不同的隨機種子)的輸出,在某種程度上也能提高性能。
簡單來理解,自蒸餾是知識蒸餾的一種特殊情況。
我們假設(shè)使用模型??2 從一個隨機的初始化開始,來匹配另外一個模型??1 的輸出。在這個過程中??2 一方面會學(xué)習(xí)??1 已經(jīng)學(xué)習(xí)到特征子集,另一方面其能夠?qū)W習(xí)到的特征子集也會受其隨機初始化的影響。
這個過程,可以看做是:首先對兩個單獨的模型 ??1,??2進行集成學(xué)習(xí),然后蒸餾成 ??2。
最終的 ??2 可能不一定涵蓋數(shù)據(jù)集中所有可學(xué)習(xí)的視圖,但它至少有學(xué)習(xí)所有視圖(通過兩個單個模型的集成學(xué)習(xí)數(shù)據(jù)庫來覆蓋)的潛力。這就是自蒸餾模型測試時性能提升的來源!
?
參考:
https://www.microsoft.com/en-us/research/blog/three-mysteries-in-deep-learning-ensemble-knowledge-distillation-and-self-distillation/

