
手把手教你用Pandas庫對淘寶原始數(shù)據(jù)進(jìn)行數(shù)據(jù)處理和分詞處理
二、原始數(shù)據(jù)預(yù)處理
1、原始數(shù)據(jù)
在未經(jīng)過處理之前的數(shù)據(jù),長這樣,大家可以看看,全部存儲(chǔ)在一個(gè)單元格里邊了,看得十分的讓人難受。如下圖所示。
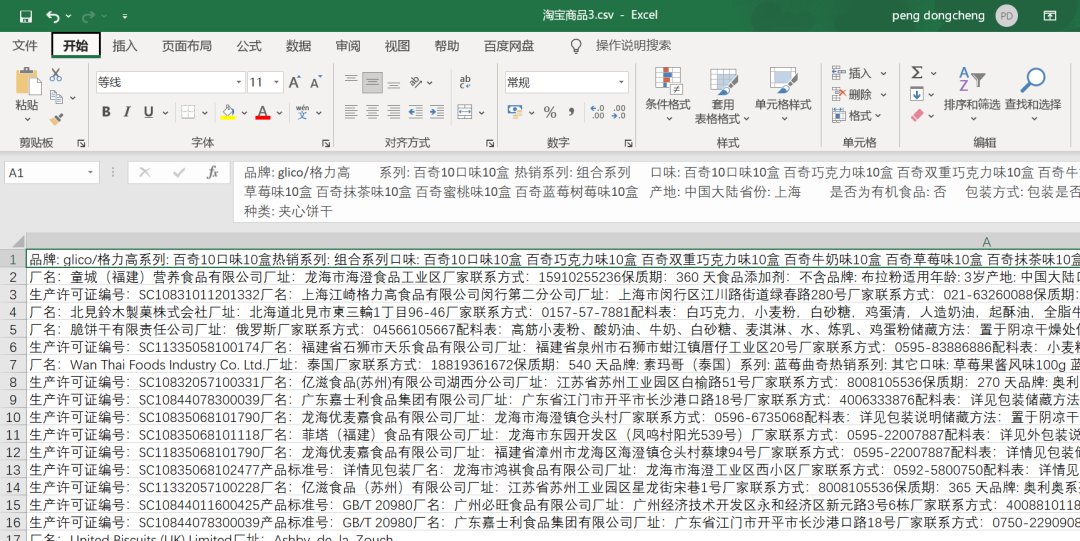
按照常規(guī)來說,針對上面的數(shù)據(jù),我們肯定會(huì)選擇Excel里邊的數(shù)據(jù)分列進(jìn)行處理,然后依次的去根據(jù)空格、冒號(hào)去分割,這樣可以得到一份較為清晰的數(shù)據(jù)表,誠然,這種方法確實(shí)可行,但是小小明大佬另辟蹊徑,給大家用Python中的正則表達(dá)式來處理這個(gè)數(shù)據(jù),處理方法如下。
2、原始數(shù)據(jù)預(yù)處理
小小明大佬直接使用正則表達(dá)式re模塊和pandas模塊進(jìn)行處理,方法可謂巧妙,一擊即中,數(shù)據(jù)處理代碼如下。
import reimport pandas as pdresult = []with open(r"淘寶數(shù)據(jù).csv") as f:for line in f:row = dict(re.findall("([^:\t]+):([^:\t]+)", line))if row:result.append(row)df = pd.DataFrame(result)df.to_excel('new_data.xlsx', encoding='utf-8')print(df)
之后我們可以看到效果圖,如下圖所示,這下是不是感覺到清爽了很多呢?
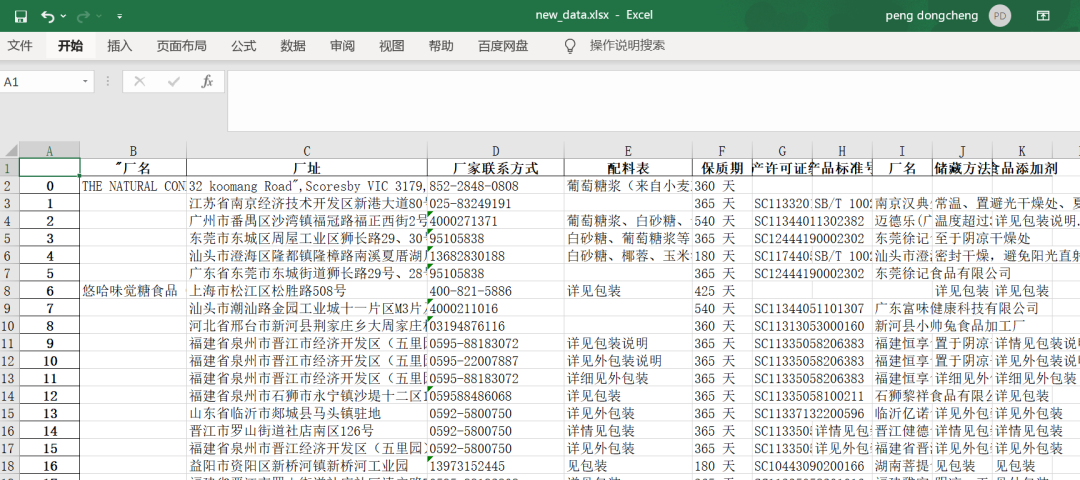
至此,我們對原始的數(shù)據(jù)進(jìn)行了預(yù)處理,但是這還不夠,我們今天主要的目標(biāo)是對上面數(shù)據(jù)中的兩列:配料表和保質(zhì)期進(jìn)行數(shù)據(jù)分析,接下來繼續(xù)我們的數(shù)據(jù)處理和分析。
三、對配料表和保質(zhì)期列進(jìn)行處理
一開始的時(shí)候,程序大佬對配料表和保質(zhì)期這兩列的數(shù)據(jù)進(jìn)行處理,但是來回得到的分詞中總有一些特殊字符,如下圖所示,我們可以看到這些字符里邊有%、頓號(hào)、空格等內(nèi)容。
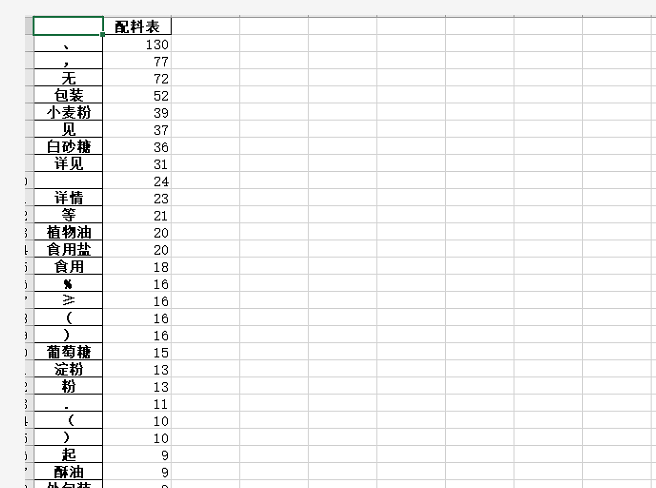
我們都知道,這些是我們不需要的字符,當(dāng)時(shí)我們在群里討論的時(shí)候,我們就想到使用停用詞去針對這些擾人的字符進(jìn)行處理,代碼如下。
# 創(chuàng)建停用詞listdef stopwordslist(filepath):stopwords = [line.strip() for line in open(filepath, 'r', encoding='gbk').readlines()]return stopwords# 對句子進(jìn)行分詞def seg_sentence(sentence):sentence_seged = jieba.cut(sentence.strip())stopwords = stopwordslist('stop_word.txt') # 這里加載停用詞的路徑outstr = ''for word in sentence_seged:if word not in stopwords:if word != '\t':outstr += wordoutstr += " "return outstr
其中stop_word.txt是小編之前在網(wǎng)上找到的一個(gè)存放一些常用特殊字符的txt文件,這個(gè)文件內(nèi)容可以看看下圖。
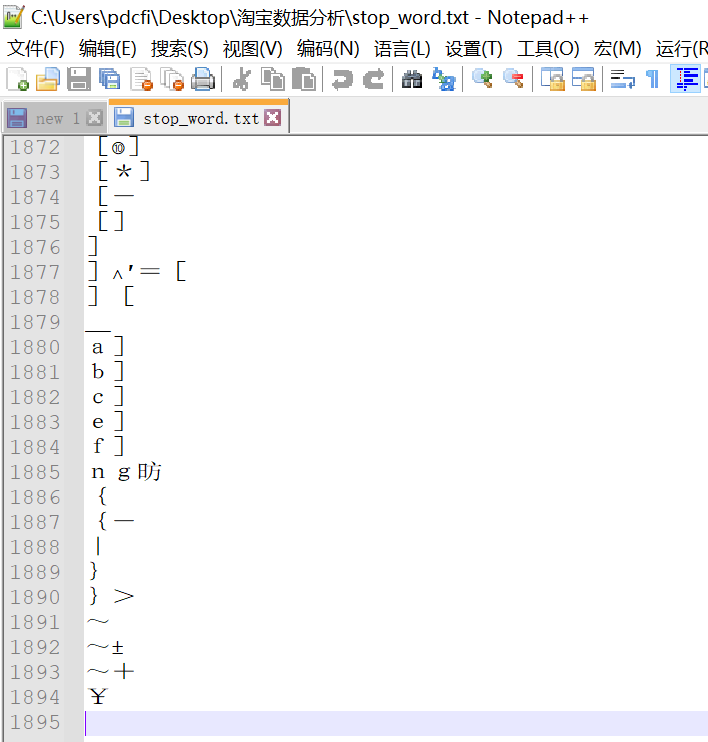
如上圖所示,大概有1894個(gè)詞左右,其實(shí)在做詞頻分析的時(shí)候,使用停用詞去除特殊字符是經(jīng)常會(huì)用到的,感興趣的小伙伴可以收藏下,也許后面你會(huì)用到呢?代碼和數(shù)據(jù)我統(tǒng)一放到文末了,記得去取就行。經(jīng)過這一輪的數(shù)據(jù)處理之后,我們得到的數(shù)據(jù)就基本上沒有太多雜亂的字符了,如下圖所示。

得到這些數(shù)據(jù)之后,接下來我們需要對這些詞語做一些詞頻統(tǒng)計(jì),并且對其進(jìn)行可視化。如果還有想法的話,也可以直接套用詞云模板,生成漂亮的詞云圖,也未嘗不可。
四、詞頻統(tǒng)計(jì)
關(guān)于詞頻統(tǒng)計(jì)這塊,小編這里介紹兩種方法,兩個(gè)代碼都是可以用的,條條大路通羅馬,一起來看看吧!
方法一:常規(guī)處理
這里使用的是常規(guī)處理的方法,代碼親測可用,只需要將代碼中的1.txt進(jìn)行替換成你自己的那個(gè)需要分詞統(tǒng)計(jì)的文檔即可,然后系統(tǒng)會(huì)自動(dòng)給你生成一個(gè)Excel表格和一個(gè)TXT文件,內(nèi)容都是一樣的,只不過一個(gè)是表格,一個(gè)是文本。
#!/usr/bin/env python3# -*- coding:utf-8 -*-import sysimport jiebaimport jieba.analyseimport xlwt # 寫入Excel表的庫# reload(sys)# sys.setdefaultencoding('utf-8')if __name__ == "__main__":wbk = xlwt.Workbook(encoding='ascii')sheet = wbk.add_sheet("wordCount") # Excel單元格名字word_lst = []key_list = []for line in open('1.txt', encoding='utf-8'): # 1.txt是需要分詞統(tǒng)計(jì)的文檔item = line.strip('\n\r').split('\t') # 制表格切分# print itemtags = jieba.analyse.extract_tags(item[0]) # jieba分詞for t in tags:word_lst.append(t)word_dict = {}with open("wordCount_all_lyrics.txt", 'w') as wf2: # 打開文件for item in word_lst:if item not in word_dict: # 統(tǒng)計(jì)數(shù)量word_dict[item] = 1else:word_dict[item] += 1orderList = list(word_dict.values())orderList.sort(reverse=True)# print orderListfor i in range(len(orderList)):for key in word_dict:if word_dict[key] == orderList[i]:wf2.write(key + ' ' + str(word_dict[key]) + '\n') # 寫入txt文檔key_list.append(key)word_dict[key] = 0for i in range(len(key_list)):sheet.write(i, 1, label=orderList[i])sheet.write(i, 0, label=key_list[i])wbk.save('wordCount_all_lyrics.xls') # 保存為 wordCount.xls文件
方法二:使用Pandas優(yōu)化處理
這里使用Pandas方法進(jìn)行處理,代碼如下,小編也是親測有效,小伙伴們也可以去嘗試下。
def get_data(df):# 將食品添加劑這一列空的數(shù)據(jù)設(shè)置為無# print(df)df.loc[:,'食品添加劑'] = df['食品添加劑'].fillna('無')df.loc[:,'保質(zhì)期'] = df['保質(zhì)期'].fillna('無')df.loc[:, '配料表'] = df['配料表'].fillna('無')# 分詞并擴(kuò)展提取names = df.配料表.apply(jieba.lcut).explode()# 過濾長度小于等于1的詞并去重df1 = names[names.apply(len) > 1].value_counts()with pd.ExcelWriter("taobao.xlsx") as writer:df1.to_excel(writer, sheet_name='配料')df2 = pd.read_excel('taobao.xlsx', header=None, skiprows=1, names=['column1', 'column2'])print(df2)
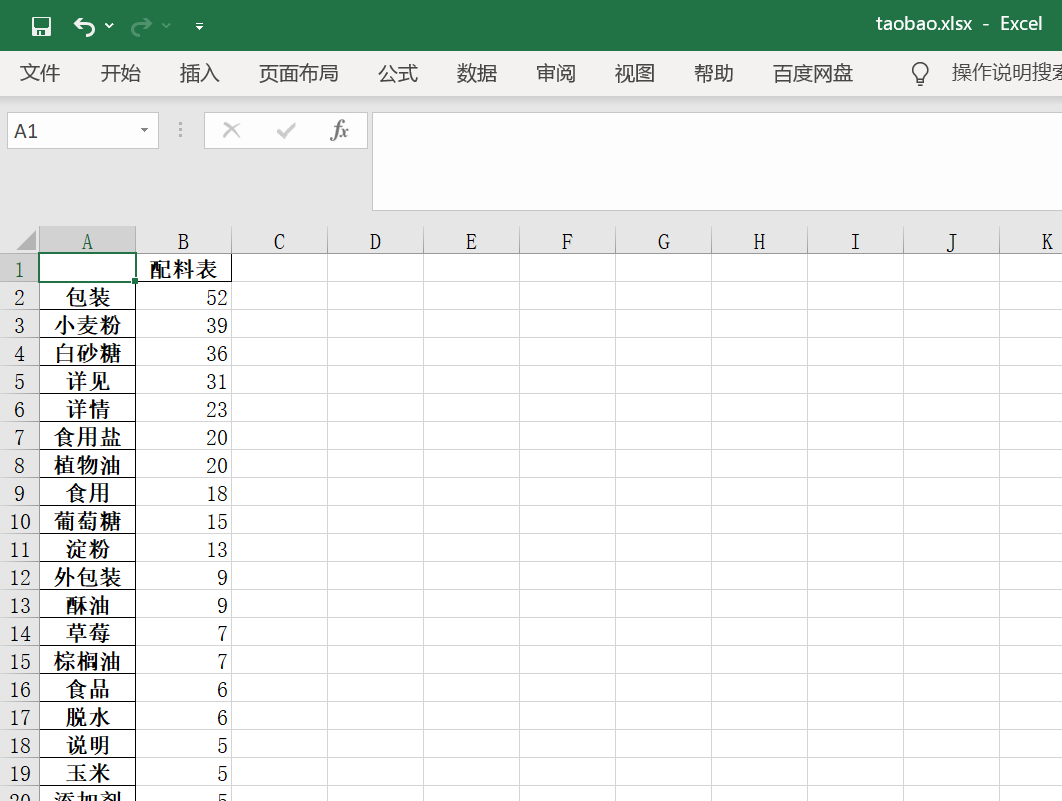

五、總結(jié)
推薦閱讀:
入門: 最全的零基礎(chǔ)學(xué)Python的問題 | 零基礎(chǔ)學(xué)了8個(gè)月的Python | 實(shí)戰(zhàn)項(xiàng)目 |學(xué)Python就是這條捷徑
干貨:爬取豆瓣短評,電影《后來的我們》 | 38年NBA最佳球員分析 | 從萬眾期待到口碑撲街!唐探3令人失望 | 笑看新倚天屠龍記 | 燈謎答題王 |用Python做個(gè)海量小姐姐素描圖 |碟中諜這么火,我用機(jī)器學(xué)習(xí)做個(gè)迷你推薦系統(tǒng)電影
趣味:彈球游戲 | 九宮格 | 漂亮的花 | 兩百行Python《天天酷跑》游戲!
AI: 會(huì)做詩的機(jī)器人 | 給圖片上色 | 預(yù)測收入 | 碟中諜這么火,我用機(jī)器學(xué)習(xí)做個(gè)迷你推薦系統(tǒng)電影
小工具: Pdf轉(zhuǎn)Word,輕松搞定表格和水印! | 一鍵把html網(wǎng)頁保存為pdf!| 再見PDF提取收費(fèi)! | 用90行代碼打造最強(qiáng)PDF轉(zhuǎn)換器,word、PPT、excel、markdown、html一鍵轉(zhuǎn)換 | 制作一款釘釘?shù)蛢r(jià)機(jī)票提示器! |60行代碼做了一個(gè)語音壁紙切換器天天看小姐姐!|
