
神經(jīng)網(wǎng)絡(luò)調(diào)參技巧:warmup策略
01
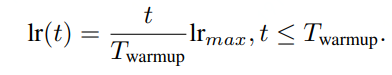


02
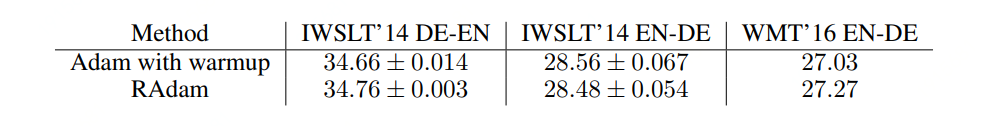
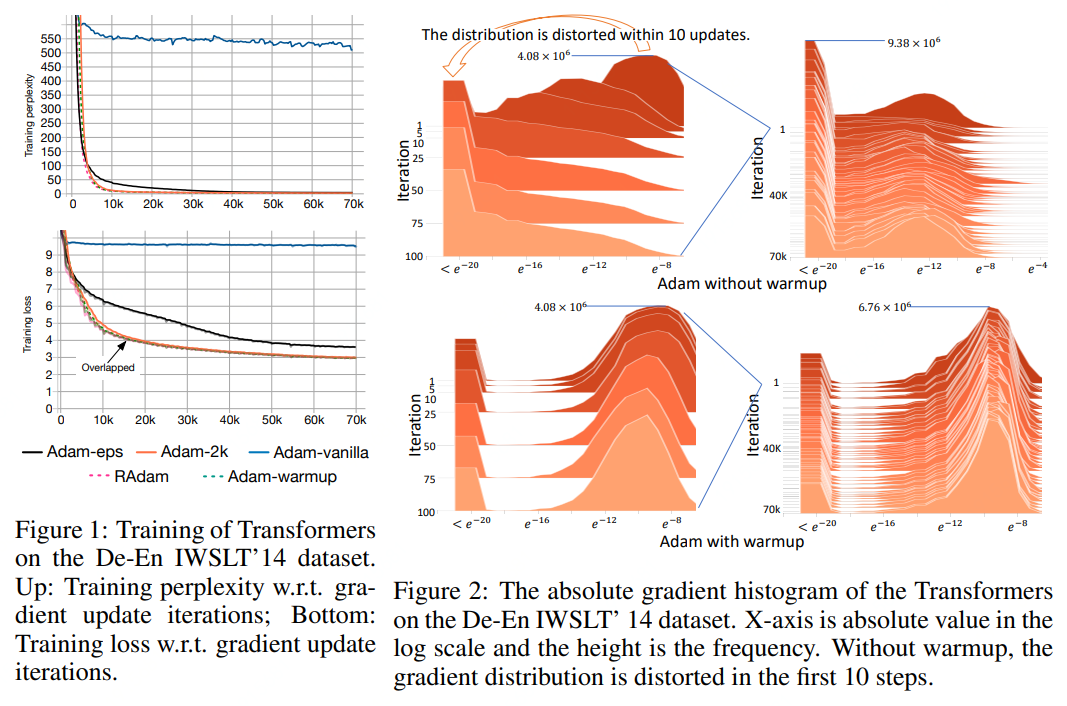
03
class AdamWarmup(Optimizer):def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0, warmup = 0):if not 0.0 <= lr:raise ValueError("Invalid learning rate: {}".format(lr))if not 0.0 <= eps:raise ValueError("Invalid epsilon value: {}".format(eps))if not 0.0 <= betas[0] < 1.0:raise ValueError("Invalid beta parameter at index 0: {}".format(betas[0]))if not 0.0 <= betas[1] < 1.0:raise ValueError("Invalid beta parameter at index 1: {}".format(betas[1]))defaults = dict(lr=lr, betas=betas, eps=eps,weight_decay=weight_decay, warmup = warmup)super(AdamW, self).__init__(params, defaults)def __setstate__(self, state):super(AdamW, self).__setstate__(state)def step(self, closure=None):loss = Noneif closure is not None:loss = closure()for group in self.param_groups:for p in group['params']:if p.grad is None:continuegrad = p.grad.data.float()if grad.is_sparse:raise RuntimeError('Adam does not support sparse gradients, please consider SparseAdam instead')p_data_fp32 = p.data.float()state = self.state[p]if len(state) == 0:state['step'] = 0state['exp_avg'] = torch.zeros_like(p_data_fp32)state['exp_avg_sq'] = torch.zeros_like(p_data_fp32)else:state['exp_avg'] = state['exp_avg'].type_as(p_data_fp32)state['exp_avg_sq'] = state['exp_avg_sq'].type_as(p_data_fp32)exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']beta1, beta2 = group['betas']state['step'] += 1exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)exp_avg.mul_(beta1).add_(1 - beta1, grad)denom = exp_avg_sq.sqrt().add_(group['eps'])bias_correction1 = 1 - beta1 ** state['step']bias_correction2 = 1 - beta2 ** state['step']if group['warmup'] > state['step']:scheduled_lr = 1e-8 + state['step'] * group['lr'] / group['warmup']else:scheduled_lr = group['lr']step_size = scheduled_lr * math.sqrt(bias_correction2) / bias_correction1if group['weight_decay'] != 0:p_data_fp32.add_(-group['weight_decay'] * scheduled_lr, p_data_fp32)p_data_fp32.addcdiv_(-step_size, exp_avg, denom)p.data.copy_(p_data_fp32)return loss
04
RAdam代碼
import mathimport torchfrom torch.optim.optimizer import Optimizer, requiredclass RAdam(Optimizer):def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0, degenerated_to_sgd=False):if not 0.0 <= lr:raise ValueError("Invalid learning rate: {}".format(lr))if not 0.0 <= eps:raise ValueError("Invalid epsilon value: {}".format(eps))if not 0.0 <= betas[0] < 1.0:raise ValueError("Invalid beta parameter at index 0: {}".format(betas[0]))if not 0.0 <= betas[1] < 1.0:raise ValueError("Invalid beta parameter at index 1: {}".format(betas[1]))self.degenerated_to_sgd = degenerated_to_sgdif isinstance(params, (list, tuple)) and len(params) > 0 and isinstance(params[0], dict):for param in params:if 'betas' in param and (param['betas'][0] != betas[0] or param['betas'][1] != betas[1]):param['buffer'] = [[None, None, None] for _ in range(10)]defaults = dict(lr=lr, betas=betas, eps=eps, weight_decay=weight_decay, buffer=[[None, None, None] for _ in range(10)])super(RAdam, self).__init__(params, defaults)def __setstate__(self, state):super(RAdam, self).__setstate__(state)def step(self, closure=None):loss = Noneif closure is not None:loss = closure()for group in self.param_groups:for p in group['params']:if p.grad is None:continuegrad = p.grad.data.float()if grad.is_sparse:raise RuntimeError('RAdam does not support sparse gradients')p_data_fp32 = p.data.float()state = self.state[p]if len(state) == 0:state['step'] = 0state['exp_avg'] = torch.zeros_like(p_data_fp32)state['exp_avg_sq'] = torch.zeros_like(p_data_fp32)else:state['exp_avg'] = state['exp_avg'].type_as(p_data_fp32)state['exp_avg_sq'] = state['exp_avg_sq'].type_as(p_data_fp32)exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']beta1, beta2 = group['betas']exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)exp_avg.mul_(beta1).add_(1 - beta1, grad)state['step'] += 1buffered = group['buffer'][int(state['step'] % 10)]if state['step'] == buffered[0]:N_sma, step_size = buffered[1], buffered[2]else:buffered[0] = state['step']beta2_t = beta2 ** state['step']N_sma_max = 2 / (1 - beta2) - 1N_sma = N_sma_max - 2 * state['step'] * beta2_t / (1 - beta2_t)buffered[1] = N_sma# more conservative since it's an approximated valueif N_sma >= 5:step_size = math.sqrt((1 - beta2_t) * (N_sma - 4) / (N_sma_max - 4) * (N_sma - 2) / N_sma * N_sma_max / (N_sma_max - 2)) / (1 - beta1 ** state['step'])elif self.degenerated_to_sgd:step_size = 1.0 / (1 - beta1 ** state['step'])else:step_size = -1buffered[2] = step_size# more conservative since it's an approximated valueif N_sma >= 5:if group['weight_decay'] != 0:p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)denom = exp_avg_sq.sqrt().add_(group['eps'])p_data_fp32.addcdiv_(-step_size * group['lr'], exp_avg, denom)p.data.copy_(p_data_fp32)elif step_size > 0:if group['weight_decay'] != 0:p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)p_data_fp32.add_(-step_size * group['lr'], exp_avg)p.data.copy_(p_data_fp32)return loss
參考資料
猜您喜歡:
 戳我,查看GAN的系列專輯~!
戳我,查看GAN的系列專輯~!附下載 |《TensorFlow 2.0 深度學習算法實戰(zhàn)》
《基于深度神經(jīng)網(wǎng)絡(luò)的少樣本學習綜述》
評論
圖片
表情