
一條SQL查詢語句是如何執(zhí)行的?
預(yù)熱
比較喜歡的一段話:不經(jīng)一番寒徹骨,怎得梅花撲鼻香,學(xué)習(xí)是枯燥的請大家堅持!這篇文章的是向丁奇老師學(xué)習(xí)的。不懂的自己搜一下哈! 閱讀這篇文章大概需要20分鐘!
大家好,我是一位農(nóng)民工(碼農(nóng)),也是一位打算沖擊一線互聯(lián)網(wǎng)大廠的碼農(nóng)。目前從事的是Java后端開發(fā),寫作分享經(jīng)驗是我的興趣,我想幫助更多未來可期但是現(xiàn)在迷茫的人!
歡迎大家來到走向一線大廠的大門!開局前,先上幾句SQL大家先熱熱身!
explain SELECT ID FROM t_apimonitoring
explain SELECT * FROM t_apimonitoring
explain SELECT ID FROM t_apimonitoring where ID=20
explain SELECT * FROM t_apimonitoring where ID>7000
大概就是這四句啦,都是比較基礎(chǔ)的。分別是查詢性能監(jiān)控表的所有數(shù)據(jù),查詢所有ID數(shù)據(jù),查詢ID為20的數(shù)據(jù),查詢ID大于7000的所有數(shù)據(jù)。最后再一一論證是如何查詢的!
工作大概半年了,我見過很多同事打開SQL面板,很大的概率是非常熟練的先輸入了一遍select * from 表名然后一堆數(shù)據(jù)就出來了。以及去年大廠熱點話題 <誰在寫select * 給我滾蛋>。大家有沒有想過為什么會這樣呢?
開始
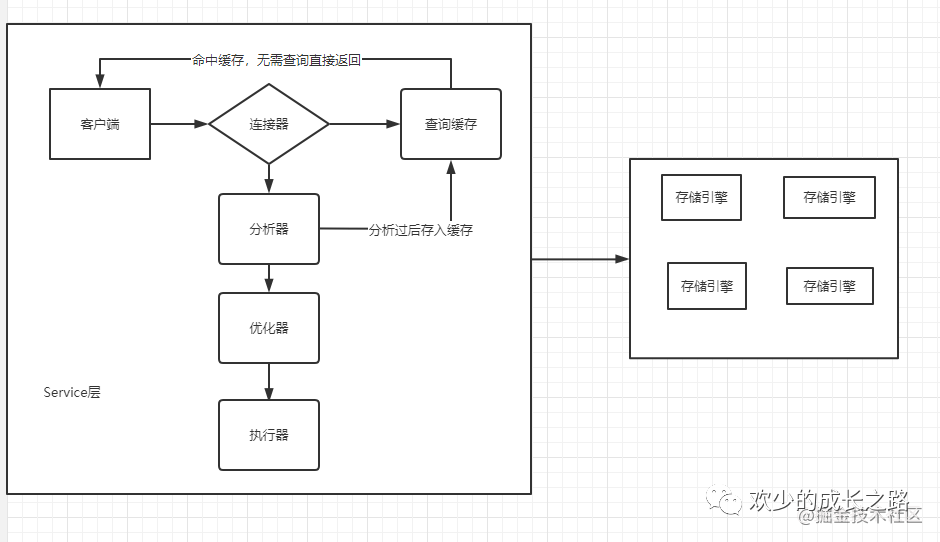
首先MySQL大體可以分為,Service層,存儲引擎層兩個部分。
連接器: 校驗用戶身份信息,校驗當(dāng)前用戶的SQL語句權(quán)限,管理SQL連接的通道
分析器: 詞法分析,語法分析。用于處理客戶端的SQL語句,分析處理完之后寫入緩存,如果下次命中的話直接返回提高查詢效率。
優(yōu)化器: 生成執(zhí)行計劃,索引選擇(這里可以完美解釋我上面拋出的SQL執(zhí)行問題)
執(zhí)行器: 調(diào)用操作存儲引擎,撈取數(shù)據(jù)。
存儲引擎: 后面會詳細(xì)講一些擴展引擎,第三方引擎,大數(shù)據(jù)量引擎等。這里會簡單介紹一下Innodb與myisam
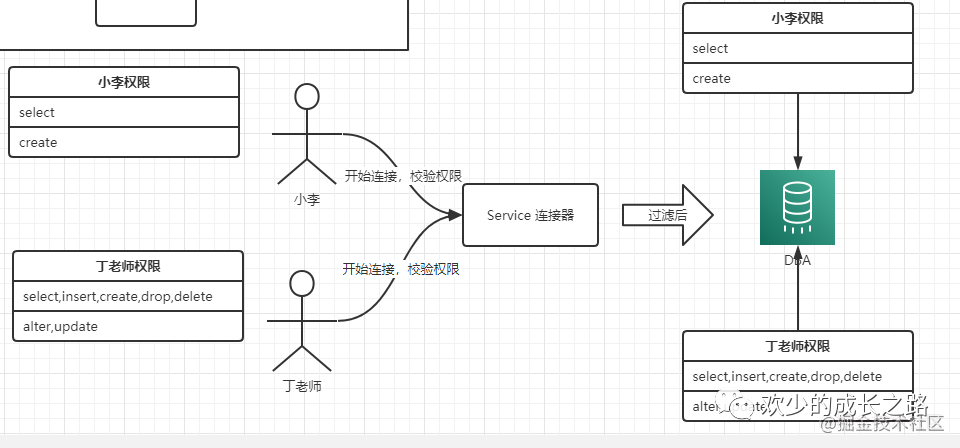
連接器
通過這個指令建立連接
mysql -h 127.0.0.1 -P 3306 -u root -p 123456通過分配后的權(quán)限,每個用戶可以操作相應(yīng)的事情
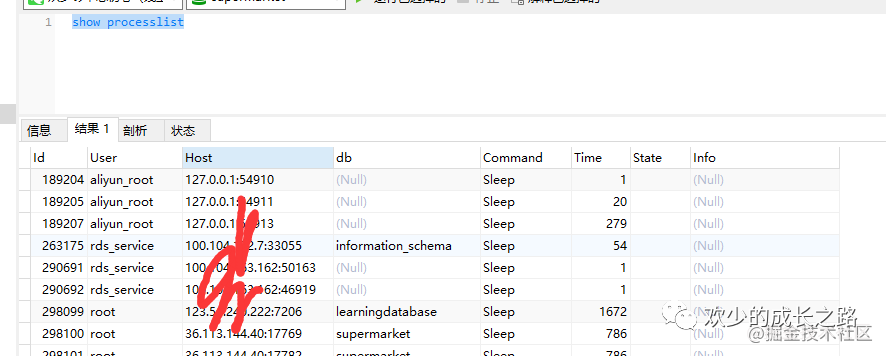
建立連接之后可以通過
show processlist查詢連接狀態(tài)。其中的 Command 列顯示為“Sleep”的這一行,就表示現(xiàn)在系統(tǒng)里面有一個空閑連接。客戶端如果太長時間沒動靜,連接器就會自動將它斷開。這個時間是由參數(shù) wait_timeout 控制的,默認(rèn)值是 8 小時。
4.數(shù)據(jù)庫連接又分為兩種連接方式,一種是長連接,一種是短連接。長連接的意思就是建立連接之后,如果客戶端的有請求操作則一種使用同一個連接進行交互處理。短連接的意思就是建立連接之后,并且客戶端執(zhí)行完自己的需求之后,就關(guān)閉了連接。
結(jié)論: 數(shù)據(jù)庫建立連接這個過程是比較復(fù)雜的,所以建立盡量減少使用短連接的方式,也就是盡量使用長連接
弊端: 全部使用長連接后,你可能會發(fā)現(xiàn),有些時候 MySQL 占用內(nèi)存漲得特別快,這是因為 MySQL 在執(zhí)行過程中臨時使用的內(nèi)存是管理在連接對象里面的。這些資源會在連接斷開的時候才釋放。所以如果長連接累積下來,可能導(dǎo)致內(nèi)存占用太大,被系統(tǒng)強行殺掉(OOM),從現(xiàn)象看就是 MySQL 異常重啟了。怎么解決這個問題呢?你可以考慮以下兩種方案。定期斷開長連接。使用一段時間,或者程序里面判斷執(zhí)行過一個占用內(nèi)存的大查詢后,斷開連接,之后要查詢再重連。如果你用的是 MySQL 5.7 或更新版本,可以在每次執(zhí)行一個比較大的操作后,通過執(zhí)行 mysql_reset_connection 來重新初始化連接資源。這個過程不需要重連和重新做權(quán)限驗證,但是會將連接恢復(fù)到剛剛創(chuàng)建完時的狀態(tài)。
查詢緩存
建立連接之后,就可以開始我們的操作了,比如寫一些SQL語句了。MySQL拿到一個SQL請求后,會先檢查緩存中是否已經(jīng)執(zhí)行過這條語句了,如果當(dāng)前存在就直接返回這是最有的查詢方式,效率也是非常高的,但是在實踐中往往不建議使用緩存,因為緩存內(nèi)有一個機制,當(dāng)這個表發(fā)生更新的時候就會清空緩存,在真正的操作中一般都會多次更新操作的。所以就算存了緩存也用不上,除非有一些系統(tǒng)設(shè)置表,用戶表等一些冷門的表才建議使用緩存。
使用手法:將參數(shù)query_cache_type設(shè)置成DEMAND,這樣對于默認(rèn)的SQL都不使用查詢緩存,而真正對于一些系統(tǒng)設(shè)置類的靜態(tài)表可以在SQL上添加以下指令實現(xiàn)緩存效率。
mysql> select SQL_CACHE * from T where ID=10;
分析器
分析器要做的事情主要是‘詞法分析’和‘語法分析’
如果沒有命中緩存就說明走到這一步了.我們看到的一串字符串,真正在執(zhí)行的時候不會執(zhí)行一段字符串的,所以分析器的作用就是提取字符串的指令,比如開頭的SQL指令。字符串select會轉(zhuǎn)換成一個查詢語句,字符串t_apimonitoring會轉(zhuǎn)換成表t_apimonitoring,字符串ID會轉(zhuǎn)換成列ID。
轉(zhuǎn)換成SQL語言之后就開始進行語法分析了,分析SQL語法是否有錯誤,如果沒有錯誤的話下一步繼續(xù)執(zhí)行,如果有錯誤的話我們只需要關(guān)注use near大概就能解決一切了,所以SQL還是非常強大方便的。 > 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'from where ss per_user' at line 1
優(yōu)化器
經(jīng)過分析器已經(jīng)轉(zhuǎn)一個字符串轉(zhuǎn)換成一個SQL語句了。優(yōu)化器所要做的事情就是,尋找匹配索引達(dá)到最優(yōu)查詢效率。這里是t1表跟t2表進行關(guān)聯(lián),查詢t1表中的c字段為10的數(shù)據(jù)并且也查詢t2表中的d字段為20的共同數(shù)據(jù)。如果換一個說法這里是t2表跟t1表進行關(guān)聯(lián),查詢t2表中的d字段為20的數(shù)據(jù)并且查詢t1表中的c字段為10的數(shù)據(jù)的共同數(shù)據(jù)。這兩個說法都是對的。但是對于SQL來說,尋找不同的索引能極大的提高性能。
mysql> select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20;
執(zhí)行器
分析器處理了要做什么,優(yōu)化器處理了要怎么做,最后可以執(zhí)行SQL語句了。在執(zhí)行SQL的時候會有一步procheck驗證權(quán)限的步驟,這一步我估計會有很多人會比較懵,一開始連接不也是校驗權(quán)限嗎。其實這兩步的權(quán)限是不一樣的。一開始是校驗用戶的大權(quán)限,執(zhí)行器這里驗證的是用戶中對每個表的操作權(quán)限。如果有就開始調(diào)用引擎接口,如果沒有就返回權(quán)限錯誤。
以下列SQL為例,執(zhí)行SQL的步驟就是會先撈取表中的第一條數(shù)據(jù),并且判斷ID是不是為10,如果不是就跳過,繼續(xù)重復(fù)操作一直找到ID為10的數(shù)據(jù)為止然后返回結(jié)果集給客戶端
mysql> select * from T where ID=10;
你會在數(shù)據(jù)庫的慢查詢?nèi)罩局锌吹揭粋€ rows_examined 的字段,表示這個語句執(zhí)行過程中掃描了多少行。這個值就是在執(zhí)行器每次調(diào)用引擎獲取數(shù)據(jù)行的時候累加的。在有些場景下,執(zhí)行器調(diào)用一次,在引擎內(nèi)部則掃描了多行,因此引擎掃描行數(shù)跟 rows_examined 并不是完全相同的。我們后面會專門有一篇文章來講存儲引擎的內(nèi)部機制,里面會有詳細(xì)的說明。
結(jié)尾
感謝各位小伙伴看完這篇文章,這篇文章大概介紹了一下SQL的運行過程。是不是又自信了一點呢?
不經(jīng)一番寒徹骨,怎得梅花撲鼻香,學(xué)習(xí)是枯燥的請大家堅持!