
一條SQL查詢語句是如何執(zhí)行的?
MySQL是典型的C/S架構(gòu)(客戶端/服務(wù)器架構(gòu)),客戶端進(jìn)程向服務(wù)端進(jìn)程發(fā)送一段文本(MySQL指令),服務(wù)器進(jìn)程進(jìn)行語句處理然后返回執(zhí)行結(jié)果。
問題來了。服務(wù)器進(jìn)程對客戶端發(fā)送的請求究竟做了什么處理呢?本文以查詢請求為例,講解MySQL服務(wù)器進(jìn)程的處理流程。
如下圖所示,服務(wù)器進(jìn)程在處理客戶端請求的時候,大致需要進(jìn)行3個步驟:
- 處理連接
- 解析與優(yōu)化
- 存儲引擎
接下來我們來詳細(xì)了解一下這3步具體都做了什么。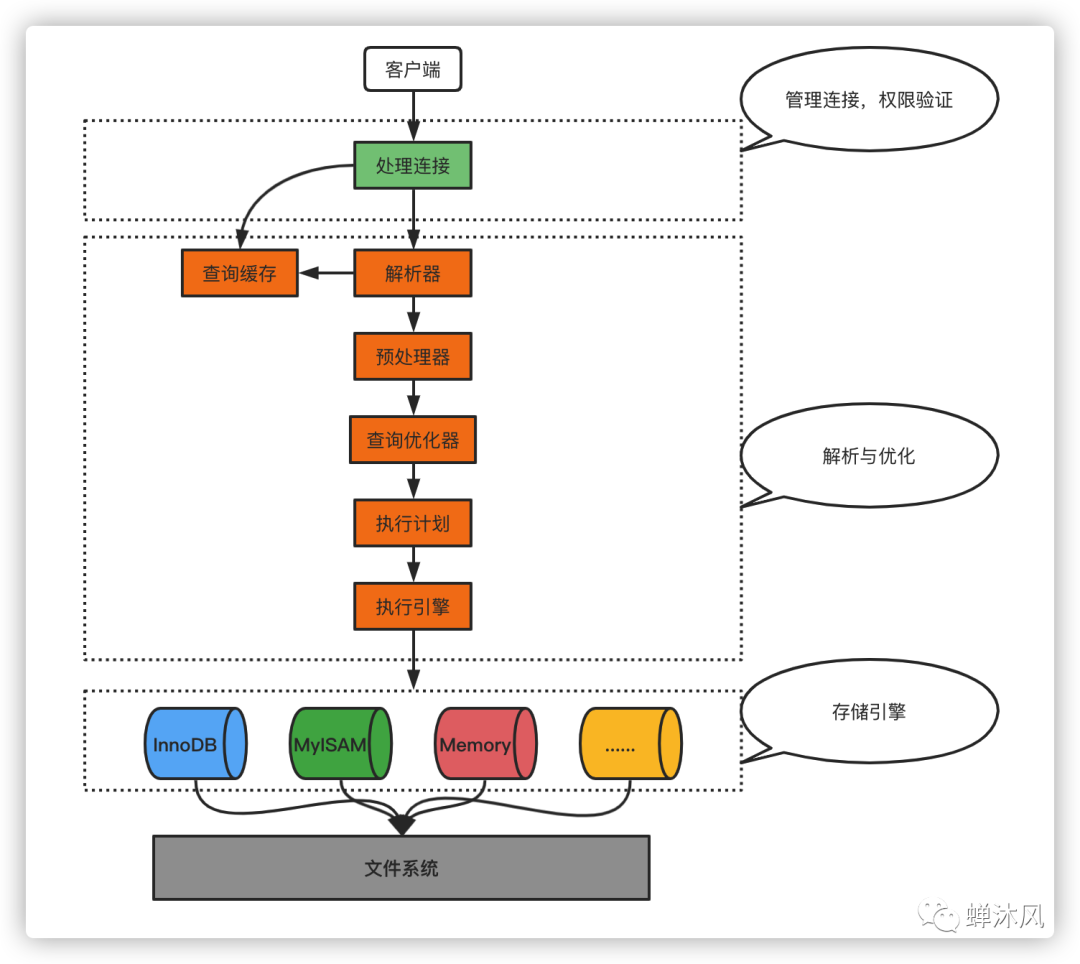
1. 處理連接
客戶端向服務(wù)器發(fā)送請求并最終收到響應(yīng),本質(zhì)上是一個進(jìn)程間通信的過程。
MySQL有專門用于處理連接的模塊——連接器。
1.1 客戶端和服務(wù)端的通信方式
1.1.1 TCP/IP協(xié)議
TCP/IP協(xié)議是MySQL客戶端和服務(wù)器最常用的通信方式。
我們平時所說的MySQL服務(wù)器默認(rèn)監(jiān)聽的端口是3306,這句話的前提是客戶端進(jìn)程和服務(wù)器進(jìn)程使用的是TCP/IP協(xié)議進(jìn)行通信。
我們在使用mysql命令啟動客戶端程序時,只要在-h參數(shù)后跟隨IP地址作為服務(wù)器進(jìn)程所在的主機(jī)地址,那么通訊方式便是TCP/IP協(xié)議。
如果客戶端進(jìn)程和服務(wù)器進(jìn)程位于同一臺主機(jī),且要使用
TCP/IP協(xié)議進(jìn)行通信,則IP地址需要指定為127.0.0.1,而不能使用localhost
1.1.2 UNIX域套接字
如果客戶端進(jìn)程和服務(wù)器進(jìn)程都位于類UNIX操作系統(tǒng)(MacOS、Centos、Ubuntu等)的主機(jī)之上,并且在啟動客戶端程序時沒有指定主機(jī)名,或者指定的主機(jī)名為localhost,又或者指定了--protocol=socket的啟動參數(shù),那么客戶端進(jìn)程和服務(wù)器進(jìn)程就會使用UNIX域套接字進(jìn)行進(jìn)程間通信。
MySQL服務(wù)器進(jìn)程默認(rèn)監(jiān)聽的UNIX域套接字文件為/temp/mysql.sock,客戶端進(jìn)程啟動時也默認(rèn)會連接到這個UNIX域套接字文件之上。
如果不明白
UNIX域套接字到底是什么也沒關(guān)系,只要知道這是進(jìn)程之間的一種通訊方式就可以了,這里提及的主要目的是希望讀者知曉MySQL客戶端和進(jìn)程通訊方式不止于TCP/IP協(xié)議
1.1.3 命名管道和共享內(nèi)存
如果你的MySQL是安裝在Windows主機(jī)之上,客戶端和服務(wù)器進(jìn)程可以使用命名管道和共享內(nèi)存的方式進(jìn)行通信。
不過使用這些通信方式需要在服務(wù)端和客戶端啟動時添加一些啟動參數(shù)。
使用命名管道進(jìn)行通信。需要在啟動服務(wù)器時添加
--enable-named-pipe參數(shù),同時在啟動客戶端進(jìn)程時添加--pipe或者--protocol=pipe參數(shù)使用共享內(nèi)存進(jìn)行通信。需要在啟動服務(wù)器時添加
--shared-memory參數(shù),啟動成功后,共享內(nèi)存便成為本地客戶端程序的默認(rèn)連接方式;也可以在啟動客戶端進(jìn)程的命令中加上--protocol=memory參數(shù)明確指定使用共享內(nèi)存進(jìn)行通信
如果不明白命名管道和共享內(nèi)存到底是什么沒關(guān)系,只要知道這是進(jìn)程之間的一種通訊方式就可以了,這里提及的主要目的是希望讀者知曉MySQL客戶端和進(jìn)程通訊方式不止于
TCP/IP協(xié)議
1.2 權(quán)限驗(yàn)證
確認(rèn)通信方式并且成功建立連接之后,連接器就要開始驗(yàn)證你的身份了,使用的信息就是你的用戶名和密碼。
- 如果用戶名或者密碼錯誤,客戶端連接會立即斷開
- 如果用戶名密碼認(rèn)證通過,連接器會到權(quán)限表里面查出當(dāng)前登陸用戶擁有的權(quán)限。之后這個連接里面的權(quán)限判斷邏輯,都將依賴于此時讀到的權(quán)限。
1.3 查看MySQL連接
每當(dāng)一個客戶端連接到服務(wù)端時,服務(wù)端進(jìn)程都會創(chuàng)建一個單獨(dú)的線程來處理當(dāng)前客戶端的交互操作。
那么如何查看MySQL當(dāng)前所有的連接?
mysql>?show?global?status?like?'Thread%';
+-------------------+-------+
|?Variable_name?????|?Value?|
+-------------------+-------+
|?Threads_cached????|?0?????|
|?Threads_connected?|?1?????|
|?Threads_created???|?1?????|
|?Threads_running???|?1?????|
+-------------------+-------+
各字段含義如下表
| 字段 | 含義 |
|---|---|
| Threads_cached | 緩存中的線程連接數(shù) |
| Threads_connected | 當(dāng)前打開的連接數(shù) |
| Threads_created | 為處理連接創(chuàng)建的線程數(shù) |
| Threads_running | 非睡眠狀態(tài)的連接數(shù),通常指并發(fā)連接數(shù) |
建立連接之后,除非客戶端主動斷開連接,否則服務(wù)器會等待客戶端發(fā)送請求。但是線程的創(chuàng)建和保持是需要消耗服務(wù)器資源的,因此服務(wù)器會把長時間不活動的客戶端連接斷開。
有2個參數(shù)控制這個自動斷開連接的行為,每個參數(shù)都默認(rèn)為28800秒,8小時。
--?非交互式超時時間,如JDBC連接
mysql>?show?global?variables?like?'wait_timeout';
+---------------+-------+
|?Variable_name?|?Value?|
+---------------+-------+
|?wait_timeout??|?28800?|
+---------------+-------+
--?交互式超時時間,如數(shù)據(jù)庫查看工具Navicat等
mysql>?show?global?variables?like?'interactive_timeout';
+---------------------+-------+
|?Variable_name???????|?Value?|
+---------------------+-------+
|?interactive_timeout?|?28800?|
+---------------------+-------+
既然連接消耗資源,那是不是MySQL的最大連接數(shù)也有默認(rèn)限制呢?沒錯!默認(rèn)最大連接數(shù)為151。
mysql>?show?variables?like?'max_connections';
+-----------------+-------+
|?Variable_name???|?Value?|
+-----------------+-------+
|?max_connections?|?151???|
+-----------------+-------+
題外話:細(xì)心的讀者可能會發(fā)現(xiàn)MySQL某些查詢語句帶有
global關(guān)鍵字,這個關(guān)鍵字有什么含義呢?
MySQL的系統(tǒng)變量有兩個作用范圍(不區(qū)分大小寫),分別是
GLOBAL(全局范圍):變量的設(shè)置影響服務(wù)器和所有客戶端SESSION(會話范圍):變量的設(shè)置僅影響當(dāng)前連接(會話)
但是并非每個參數(shù)都具有兩個作用范圍,比如允許同時連接到服務(wù)器的客戶端的數(shù)量max_connections就只有全局級別。
當(dāng)沒有帶作用范圍關(guān)鍵字時,默認(rèn)是SESSION級別,包括查詢和修改操作。
比如修改一個參數(shù)之后,在當(dāng)前窗口生效了,但是在其他窗口卻沒有生效
show?VARIABLES?like?'autocommit';
set?autocommit?=?on;
因此,如果只是臨時修改,請使用SESSION級別,如果需要當(dāng)前設(shè)置在其他會話中生效,需要使用GLOBAL關(guān)鍵字。
到此為止,服務(wù)器進(jìn)程已經(jīng)和客戶端進(jìn)程建立了連接,下一步將處理客戶端傳來的請求了。
2. 解析與優(yōu)化
服務(wù)器收到客戶端傳來的請求之后,還需要經(jīng)過查詢緩存、詞法語法解析和預(yù)處理、查詢優(yōu)化的處理。
2.1 查詢緩存
如果我們兩次都執(zhí)行同一條查詢指令,第二次的響應(yīng)時間會不會比第一次的響應(yīng)時間短一些?
之前使用過Redis緩存工具的讀者應(yīng)該會有這個很自然的想法,MySQL收到查詢請求之后應(yīng)該先到緩存中查看一下,看一下之前是不是執(zhí)行過這條指令。如果緩存命中,則直接返回結(jié)果;否則重新進(jìn)行查詢,然后加入緩存。
MySQL確實(shí)內(nèi)部自帶了一個緩存模塊。
現(xiàn)在有一張500W行且沒有添加索引的數(shù)據(jù)表,我執(zhí)行以下命令兩次,第二次會不會變得很快?
SELECT?*?FROM?t_user?WHERE?user_name?=?'蟬沐風(fēng)'
并不會!說明緩存沒有生效,為什么?MySQL默認(rèn)是關(guān)閉自身的緩存功能的,查看一下query_cache_type變量設(shè)置。
mysql>?show?variables?like?'query_cache_type';
+------------------------------+---------+
|?Variable_name????????????????|?Value???|
+------------------------------+---------+
|?query_cache_type?????????????|?OFF?????|
+------------------------------+---------+
默認(rèn)關(guān)閉就意味著不推薦,MySQL為什么不推薦用戶使用自己的緩存功能呢?
- MySQL自帶的緩存系統(tǒng)應(yīng)用場景非常有限,它要求SQL語句必須一模一樣,多一個空格,變一個大小寫都被認(rèn)為是兩條不同的SQL語句
- 緩存失效非常頻繁。只要一個表的數(shù)據(jù)有任何修改,針對該表的所有緩存都會失效。對于更新頻繁的數(shù)據(jù)表而言,緩存命中率非常低!
所以緩存的功能還是交給專業(yè)的ORM框架(比如MyBatis默認(rèn)開啟一級緩存)或者獨(dú)立的緩存服務(wù)Redis更加適合。
MySQL8.0已經(jīng)徹底移除了緩存功能
2.2 解析器 & 預(yù)處理器(Parser & Preprocessor)
現(xiàn)在跳過緩存這一步了,接下來需要做什么了?
如果我隨便在客戶端終端里輸入一個字符串chanmufeng,服務(wù)器返回了一個1064的錯誤
mysql>?chanmufeng;
ERROR?1064?(42000):?You?have?an?error?in?your?SQL?syntax;?check?the?manual?that?corresponds?to?your?MySQL?server?version?for?the?right?syntax?to?use?near?'chanmufeng'?at?line?1
服務(wù)器是怎么判斷出我的輸入是錯誤的呢?這就是MySQL的Parser解析器的作用了,它主要包含兩步,分別是詞法解析和語法分析。
2.2.1 詞法解析
以下面的SQL語句為例
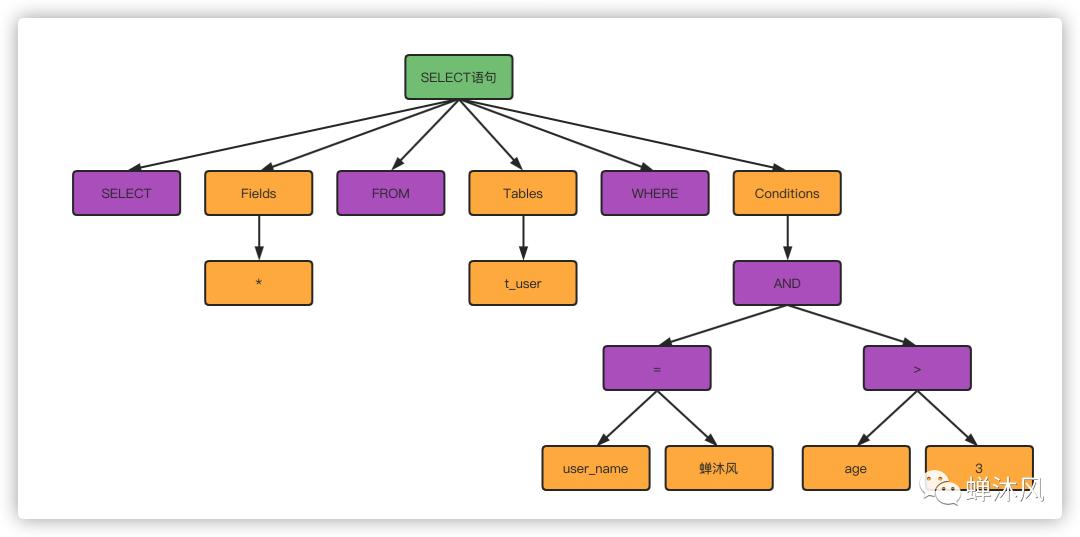
SELECT?*?FROM?t_user?WHERE?user_name?=?'蟬沐風(fēng)'?AND?age?>?3;
分析器先會做“詞法分析”,就是把一條完整的SQL語句打碎成一個個單詞,比如一條簡單的SQL語句,會打碎成8個符號,每個符號是什么類型,從哪里開始到哪里結(jié)束。
MySQL 從你輸入的SELECT這個關(guān)鍵字識別出來,這是一個查詢語句。它也要把字符串t_user識
別成“表名 t_user”,把字符串user_name識別成“列 user_name"。
2.2.2 語法分析
做完詞法解析,接下來需要做語法分析了。
根據(jù)詞法分析的結(jié)果,語法分析器會根據(jù)語法規(guī)則,判斷你輸入的這個 SQL 語句是否滿足 MySQL 語法,比如單引號是否閉合,關(guān)鍵詞拼寫是否正確等。
解析器會根據(jù)SQL語句生成一個數(shù)據(jù)結(jié)構(gòu),這個數(shù)據(jù)結(jié)構(gòu)我們成為解析樹。
 我故意拼錯了
我故意拼錯了SELECT關(guān)鍵字,MySQL報了語法錯誤,就是在語法分析這一步。
mysql>?ELECT?*?FROM?t_user?WHERE?user_name?=?'蟬沐風(fēng)'?AND?age?>?3;
ERROR?1064?(42000):?You?have?an?error?in?your?SQL?syntax;?check?the?manual?that?corresponds?to?your?MySQL?server?version?for?the?right?syntax?to?use?near?'ELECT?*?FROM?t_user?WHERE?user_name?=?'蟬沐風(fēng)''?at?line?1
詞法語法分析是一個非常基礎(chǔ)的功能,Java 的編譯器、百度搜索引擎如果要識別語句,必須也要有詞法語法分析功能。
任何數(shù)據(jù)庫的中間件,要解析 SQL完成路由功能,也必須要有詞法和語法分析功能,比如 Mycat,Sharding-JDBC(用到了Druid Parser)等都是如此。在市面上也有很多的開源的詞法解析的工具,比如 LEX,Yacc等。
2.2.3 預(yù)處理器
如果我們寫了一條語法和詞法都沒有問題的SQL,但是字段名和表名卻不存在,這個錯誤是在哪一個階段爆出的呢?
詞法解析和語法分析是無法知道數(shù)據(jù)庫里有什么表,有哪些字段的。要知道這些信息還需要解析階段的另一個工具——預(yù)處理器。
它會檢查生成的解析樹,解決解析器無法解析的語義。比如,它會檢查表和列名是否存在,檢查名字和別名,保證沒有歧義。預(yù)處理之后得到一個新的解析樹。
本質(zhì)上,解析和預(yù)處理是一個編譯過程,涉及到詞法解析、語法和語義分析,更多細(xì)節(jié)我們不會探究,感興趣的讀者可以看一下編譯原理方面的書籍。
2.3 查詢優(yōu)化器(Optimizer)與查詢執(zhí)行計劃
到了這一步,MySQL終于知道我們想查詢的表和列以及相應(yīng)的搜索條件了,是不是可以直接進(jìn)行查詢了?
還不行。MySQL作者擔(dān)心我們寫的SQL太垃圾,所以有設(shè)計出一個叫做查詢優(yōu)化器的東東,輔助我們提高查詢效率。
2.3.1 什么是查詢優(yōu)化器?
一條 SQL語句是不是只有一種執(zhí)行方式?或者說數(shù)據(jù)庫最終執(zhí)行的 SQL是不是就是我們發(fā)送的 SQL?
不是。一條 SQL 語句是可以有很多種執(zhí)行方式的,最終返回相同的結(jié)果,他們是等價的。
舉一個非常簡單的例子,比如你執(zhí)行下面這樣的語句:
SELECT?*?FROM?t1,?t2?WHERE?t1.id?=?10?AND?t2.id?=?20
- 既可以先從表 t1 里面取出 id=10 的記錄,再根據(jù) id 值關(guān)聯(lián)到表 t2,再判斷 t2 里面 id 的值是否等于 20。
- 也可以先從表 t2 里面取出 id=20 的記錄,再根據(jù) id 值關(guān)聯(lián)到表 t1,再判斷 t1 里面 id 的值是否等于 10。
這兩種執(zhí)行方法的邏輯結(jié)果是一樣的,但是執(zhí)行的效率會有不同,如果有這么多種執(zhí)行方式,這些執(zhí)行方式怎么得到的?最終選擇哪一種去執(zhí)行?根據(jù)什么判斷標(biāo)準(zhǔn)去選擇?
這個就是 MySQL的查詢優(yōu)化器的模塊(Optimizer)的工作。
查詢優(yōu)化器的目的就是根據(jù)解析樹生成不同的執(zhí)行計劃(Execution Plan),然后選擇一種最優(yōu)的執(zhí)行計劃,MySQL 里面使用的是基于開銷(cost)的優(yōu)化器,哪種執(zhí)行計劃開銷最小,就用哪種。
2.3.2 優(yōu)化器究竟做了什么?
舉兩個簡單的例子∶
- 當(dāng)我們對多張表進(jìn)行關(guān)聯(lián)查詢的時候,以哪個表的數(shù)據(jù)作為基準(zhǔn)表。
- 有多個索引可以使用的時候,選擇哪個索引。
實(shí)際上,對于每一種數(shù)據(jù)庫來說,優(yōu)化器的模塊都是必不可少的,他們通過復(fù)雜的算法實(shí)現(xiàn)盡可能優(yōu)化查詢效率。
往細(xì)節(jié)上說,查詢優(yōu)化器主要做了下面幾方面的優(yōu)化:
- 子查詢優(yōu)化
- 等價謂詞重寫
- 條件化簡
- 外連接消除
- 嵌套連接消除
- 連接消除
- 語義優(yōu)化
本文不會對優(yōu)化的細(xì)節(jié)展開講解,大家先對MySQL的整體架構(gòu)有所了解就可以了,具體細(xì)節(jié)之后單獨(dú)開篇介紹
但是優(yōu)化器也不是萬能的,如果SQL語句寫得實(shí)在太垃圾,再牛的優(yōu)化器也救不了你了。因此大家在編寫SQL語句的時候還是要有意識地進(jìn)行優(yōu)化。
2.3.3 執(zhí)行計劃
優(yōu)化完之后,得到一個什么東西呢?優(yōu)化器最終會把解析樹變成一個查詢執(zhí)行計劃。
查詢執(zhí)行計劃展示了接下來執(zhí)行查詢的具體方式,比如多張表關(guān)聯(lián)查詢,先查詢哪張表,在執(zhí)行查詢的時候有多個索引可以使用,實(shí)際上該使用哪些索引。
MySQL提供了一個查看執(zhí)行計劃的工具。我們在 SQL語句前面加上 EXPLAIN就可以看到執(zhí)行計劃的信息。
mysql>?EXPLAIN?SELECT?*?FROM?t_user?WHERE?user_name?=?'';
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
|?id?|?select_type?|?table??|?partitions?|?type?|?possible_keys?|?key??|?key_len?|?ref??|?rows?|?filtered?|?Extra???????|
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
|??1?|?SIMPLE??????|?t_user?|?NULL???????|?ALL??|?NULL??????????|?NULL?|?NULL????|?NULL?|????1?|???100.00?|?Using?where?|
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
如果要得到更加詳細(xì)的信息,還可以用FORMAT=JSON,或者開啟optimizer trace。
mysql>?EXPLAIN?FORMAT=JSON?SELECT?*?FROM?t_user?WHERE?user_name?=?'';
文本不會帶大家詳細(xì)了解執(zhí)行計劃的每一個參數(shù),內(nèi)容很龐雜,大家先對MySQL的整體架構(gòu)有所了解就可以了,具體細(xì)節(jié)之后單獨(dú)開篇介紹
3. 存儲引擎
經(jīng)歷千辛萬苦,MySQL終于算出了最終的執(zhí)行計劃,然后就可以直接執(zhí)行了嗎?
好吧。。。依然還不可以。
我們知道,表是由一行一行的記錄組成的,但這只是邏輯上的概念,或者說只是看上去是這樣而已。
3.1 什么是存儲引擎
到底該把數(shù)據(jù)存儲在什么位置,是內(nèi)存還是磁盤?怎么從表里讀取數(shù)據(jù),以及怎么把數(shù)據(jù)寫入具體的表中,這都是存儲引擎?負(fù)責(zé)的事情。
好吧,看到這里或許你還不知道存儲引擎到底是什么。畢竟存儲引擎這個名字聽起來太玄乎了,它的前身叫做表處理器,是不是就接地氣了許多呢?
3.2 為什么需要存儲引擎
因?yàn)榇鎯Φ男枨蟛煌?/p>
試想一下:
如果一張表,需要很高的訪問速度,而不需要考慮持久化的問題,是不是最好把數(shù)據(jù)放在內(nèi)存呢?
如果一張表,是用來做歷史數(shù)據(jù)存檔的,不需要修改,也不需要索引,那是不是要支持?jǐn)?shù)據(jù)的壓縮?
如果一張表用在讀寫并發(fā)很多的業(yè)務(wù)中,是不是要支持讀寫互不干擾,而且要保證比較高的數(shù)據(jù)一致性呢?
大家應(yīng)該明白了,為什么要支持這么多的存儲引擎,因?yàn)橐环N存儲引擎不能提供所有的特性。
存儲引擎是計算機(jī)抽象的典型代表,它的功能就是接受上層指令,然后對表中數(shù)據(jù)進(jìn)行讀取和寫入,而這些操作對上層完全是屏蔽的。你甚至可以查閱MySQL文檔定義自己的存儲引擎,只要對外實(shí)現(xiàn)同樣的接口就可以了。
存儲引擎就是MySQL對數(shù)據(jù)進(jìn)行讀寫的插件而已,可以根據(jù)不同目的隨意更換(插拔)
3.3 存儲引擎怎么用
3.3.1 創(chuàng)建表的時候指定存儲引擎
在創(chuàng)建表的時候可以指定當(dāng)前表的存儲引擎,如果沒有指定,默認(rèn)的存儲引擎為InnoDB,如果想顯式指定存儲引擎,可以這樣
CREATE?TABLE?`t_user_innodb`?(
??`id`?int(11)?NOT?NULL?AUTO_INCREMENT,
??PRIMARY?KEY?(`id`)
)?ENGINE=innodb?DEFAULT?CHARSET=utf8mb4;
3.3.2 修改表的存儲引擎
ALTER?TABLE?表名?ENGINE?=?存儲引擎名稱;
3.4 存儲引擎底層區(qū)別
下面我們分別創(chuàng)建3張設(shè)置了不同存儲引擎的表,t_user_innodb、t_user_myisam、t_user_memory 我們看一下不同存儲引擎在底層存儲方面的差異,首先找到MySQL的數(shù)據(jù)存儲目錄
我們看一下不同存儲引擎在底層存儲方面的差異,首先找到MySQL的數(shù)據(jù)存儲目錄
mysql>?show?variables?like?'datadir';
+---------------+-----------------+
|?Variable_name?|?Value???????????|
+---------------+-----------------+
|?datadir???????|?/var/lib/mysql/?|
+---------------+-----------------+
進(jìn)入到目標(biāo)目錄之后,找到當(dāng)前數(shù)據(jù)庫對應(yīng)的目錄(MySQL會為一個數(shù)據(jù)庫創(chuàng)建一個同名的目錄),數(shù)據(jù)庫中表的存儲結(jié)構(gòu)如下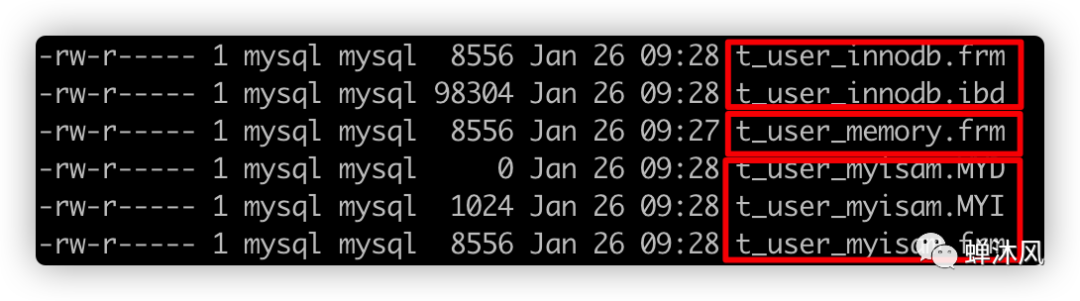 不同的存儲引擎存放數(shù)據(jù)的方式不一樣,產(chǎn)生的文件數(shù)量和格式也不一樣,InnoDB文件包含2個,MEMORY文件包含1個,MYISAM文件包含3個。
不同的存儲引擎存放數(shù)據(jù)的方式不一樣,產(chǎn)生的文件數(shù)量和格式也不一樣,InnoDB文件包含2個,MEMORY文件包含1個,MYISAM文件包含3個。
3.5 常見存儲引擎比較
首先我們查看一下當(dāng)前MySQL服務(wù)器支持的存儲引擎都有哪一些。
mysql>?SHOW?ENGINES;
+--------------------+---------+--------------+------+------------+
|?Engine?????????????|?Support?|?Transactions?|?XA???|?Savepoints?|
+--------------------+---------+--------------+------+------------+
|?InnoDB?????????????|?DEFAULT?|?YES??????????|?YES??|?YES????????|
|?MRG_MYISAM?????????|?YES?????|?NO???????????|?NO???|?NO?????????|
|?MEMORY?????????????|?YES?????|?NO???????????|?NO???|?NO?????????|
|?BLACKHOLE??????????|?YES?????|?NO???????????|?NO???|?NO?????????|
|?MyISAM?????????????|?YES?????|?NO???????????|?NO???|?NO?????????|
|?CSV????????????????|?YES?????|?NO???????????|?NO???|?NO?????????|
|?ARCHIVE????????????|?YES?????|?NO???????????|?NO???|?NO?????????|
|?PERFORMANCE_SCHEMA?|?YES?????|?NO???????????|?NO???|?NO?????????|
|?FEDERATED??????????|?NO??????|?NULL?????????|?NULL?|?NULL???????|
+--------------------+---------+--------------+------+------------+
其中,
- Support表示該存儲引擎是否可用;
- DEFAULT表示當(dāng)前MySQL服務(wù)器默認(rèn)的存儲引擎;
- Transactions表示該存儲引擎是否支持事務(wù);
- XA表示該存儲引擎是否支持分布式事務(wù);
- Savepoints表示該存儲引擎是否支持事務(wù)的部分回滾。
3.5.1 MylSAM
應(yīng)用范圍比較小,表級鎖定限制了讀/寫的性能,因此在Web和數(shù)據(jù)倉庫配置中,通常用于只讀或以讀為主的工作。
特點(diǎn):
- 支持表級別的鎖(插入和更新會鎖表),不支持事務(wù);
- 擁有較高的插入(insert)和查詢(select)速度;
- 存儲了表的行數(shù)(count速度更快)。
怎么快速向數(shù)據(jù)庫插入100萬條數(shù)據(jù)?
可以先用MylSAM插入數(shù)據(jù),然后修改存儲引擎為InnoDB。
3.5.2 InnoDB
MySQL 5.7及更新版中的默認(rèn)存儲引擎。InnoDB是一個事務(wù)安全(與ACID兼容)的MySQL 存儲引擎,它具有提交、回滾和崩潰恢復(fù)功能來保護(hù)用戶數(shù)據(jù)。InnoDB行級鎖(不升級為更粗粒度的鎖)和Oracle風(fēng)格的一致非鎖讀提高了多用戶并發(fā)性。InnoDB將用戶數(shù)據(jù)存儲在聚集索引中,以減少基于主鍵的常見查詢的I/O。為了保持?jǐn)?shù)據(jù)完整性,InnoDB還支持外鍵引用完整性約束。
特點(diǎn):
- 支持事務(wù),支持外鍵,因此數(shù)據(jù)的完整性、一致性更高;
- 支持行級別的鎖和表級別的鎖;
- 支持讀寫并發(fā),寫不阻塞讀(MVCC);
- 特殊的索引存放方式,可以減少IO,提升査詢效率。
番外:InnoDB本來是InnobaseOy公司開發(fā)的,它和MySQL AB公司合作開源了InnoDB的代碼。但是沒想到MySQL的競爭對手Oracle把InnobaseOy收購了。后來08年Sun公司(開發(fā)Java語言的Sun)收購了MySQL AB,09年Sun公司又被Oracle收購了,所以MySQL和 InnoDB又是一家了。有人覺得MySQL越來越像Oracle,其實(shí)也是這個原因。
3.5.3 Memory
將所有數(shù)據(jù)存儲在RAM中,以便快速訪問。這個引擎以前被稱為堆引擎。
特點(diǎn):
- 把數(shù)據(jù)放在內(nèi)存里面,讀寫的速度很快,但是數(shù)據(jù)庫重啟或者崩潰,數(shù)據(jù)會全部消失;
- 只適合做臨時表。
3.5.4 CSV
它的表實(shí)際上是帶有逗號分隔值的文本文件。csv表允許以CSV格式導(dǎo)入或轉(zhuǎn)儲數(shù)據(jù), 以便與讀寫相同格式的腳本和應(yīng)用程序交換數(shù)據(jù)。因?yàn)镃SV表沒有索引,所以通常在正常操作期間將數(shù)據(jù)保存在InnoDB表中,只在導(dǎo)入或?qū)С鲭A段使用csv表。
特點(diǎn):
- 不允許空行,不支持索引;
- 格式通用,可以直接編輯,適合在不同數(shù)據(jù)庫之間導(dǎo)入導(dǎo)出。
3.5.5 Archive
專用與存檔,空間經(jīng)過壓縮,用于存儲和檢索大量很少引用的信息。
特點(diǎn):
- 不支持索引;
- 不支持update、delete。
3.6 如何選擇存儲引擎
如果對數(shù)據(jù)一致性要求比較高,需要事務(wù)支持,可以選擇InnoDB。
如果數(shù)據(jù)查詢多更新少,對查詢性能要求比較高,可以選擇MyISAM。
如果需要一個用于查詢的臨時表,可以選擇Memory。
如果所有的存儲引擎都不能滿足你的需求,并且技術(shù)能力足夠,可以根據(jù)官網(wǎng)內(nèi)部手冊用C語言開發(fā)一個存儲引擎:https://dev.mvsql.com/doc/internals/en/custom-engine.html