
一條SQL更新語句是如何執(zhí)行的?
預(yù)熱
比較喜歡的一段話:不經(jīng)一番寒徹骨,怎得梅花撲鼻香,學(xué)習(xí)是枯燥的請大家堅(jiān)持!這篇文章的是向丁奇老師學(xué)習(xí)的。不懂的自己搜一下哈! 閱讀這篇文章大概需要15分鐘!
大家好前面我們大概了解了一個(gè)查詢語句的執(zhí)行流程,并介紹了執(zhí)行過程中涉及的處理模塊。相信你還記得,一條查詢語句的執(zhí)行過程一般是經(jīng)過連接器、分析器、優(yōu)化器、執(zhí)行器等功能模塊,最后到達(dá)存儲引擎。那么,一條更新語句的執(zhí)行流程又是怎樣的呢?
更新語句的執(zhí)行流程與查詢語句的流程都是一樣的,大同小異。唯一的不同的就是更新語句還涉及到兩個(gè)重要的日志模塊,這也就是我們因?yàn)榈闹黝}。redo log(重要日志)和 binlog日志(歸檔日志)
開始
redo log
講述之前我們先舉一個(gè)生活中的例子吧。農(nóng)村的超市,平時(shí)有些人沒帶錢,賒賬的時(shí)候我們都是拿一個(gè)專門的賬本記錄一下,以后再一一對應(yīng)提醒還款。如果當(dāng)時(shí)那段時(shí)間特別忙的話,不足以去翻本子一一書寫。我們常見的思路就是,隨便找一個(gè)紙條記錄一下大概的人名,大概的賒賬金額等。等不忙的時(shí)候拿著這個(gè)小紙條再去把信息轉(zhuǎn)移到專門的賬本中。這樣就可以完美的解決記賬這一塊的業(yè)務(wù)。
數(shù)據(jù)庫中也是一樣。SQL再執(zhí)行更新不可能立刻就去修改磁盤中的數(shù)據(jù),如果是立刻修改的話,那開銷也太大了,我估計(jì)磁盤IO都扛不住。所以數(shù)據(jù)庫的解決方案就是利用日志模塊解決這一難題,也就是經(jīng)常說到的WAL技術(shù),WAL的技術(shù)全稱是Write-Ahead Logging,它的關(guān)鍵點(diǎn)就是在于通過先寫入日志,等不忙的時(shí)候再寫入磁盤。
具體來說當(dāng)SQL需要執(zhí)行更新的時(shí)候,Innodb引擎會先把記錄寫到redo log也就是上文的小紙條,并更新內(nèi)存。這個(gè)時(shí)候更新就完全了,大家可以看到并沒有立刻修改磁盤里的數(shù)據(jù)。修改磁盤數(shù)據(jù)的操作是等Innodb 空閑的時(shí)候,再開始工作的。操作完全之后生活中就可以把小紙條丟棄了。數(shù)據(jù)庫中也是一樣,會清掉日志。為新記賬騰出空間。
innodb的redo log是有固定大小的,ACB三個(gè)區(qū)域就類似于他的大小,兩個(gè)箭頭中間的位置就類似于上文說的紙條,寫日志的時(shí)候是從B端開始向A端寫的,如果A端大于B端,數(shù)據(jù)庫就會停下來把沒有處理的日志清掉再繼續(xù)進(jìn)行日志操作。
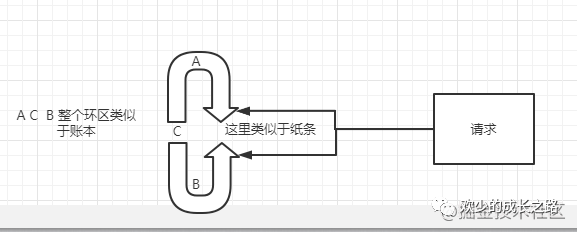
有了 redo log,InnoDB 就可以保證即使數(shù)據(jù)庫發(fā)生異常重啟,之前提交的記錄都不會丟失,這個(gè)能力稱為 crash-safe。談到這個(gè)crash-safe我們再擴(kuò)展一下吧,數(shù)據(jù)庫的crash-safe能力主要依靠三大核核心日志,除了以上的兩個(gè),還有一個(gè)比較重要的就是 回滾日志 undo log 這里不展開了,接下來我會安排在事務(wù)那邊介紹一下。
要理解 crash-safe 這個(gè)概念,可以想想我們前面賒賬記錄的例子。只要賒賬記錄記在了粉板上或?qū)懺诹速~本上,之后即使掌柜忘記了,比如突然停業(yè)幾天,恢復(fù)生意后依然可以通過賬本和粉板上的數(shù)據(jù)明確賒賬賬目。
bin log
這個(gè)binlog 我想大家都比較熟悉了,這個(gè)就是我們平時(shí)常用的一個(gè)日志。通過show binlog events 可以查看本地的日志。根據(jù)以下內(nèi)容可以大概猜測一下,binlog來自于MySQL整體架構(gòu)的Server層。那么redo log就來自于 Innodb層。這個(gè)時(shí)候我不知道你們跟我當(dāng)時(shí)想的是不是一樣。我當(dāng)時(shí)在想為什么要分Server層 binlog,innodb的redo log呢?
因?yàn)樵缙诘臄?shù)據(jù)庫發(fā)展默認(rèn)引擎是MyISAM,MyISAM 沒有 crash-safe 的能力,binlog 日志只能用于歸檔。而 InnoDB 是另一個(gè)公司以插件形式引入 MySQL 的,既然只依靠 binlog 是沒有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系統(tǒng)——也就是 redo log 來實(shí)現(xiàn) crash-safe 能力。
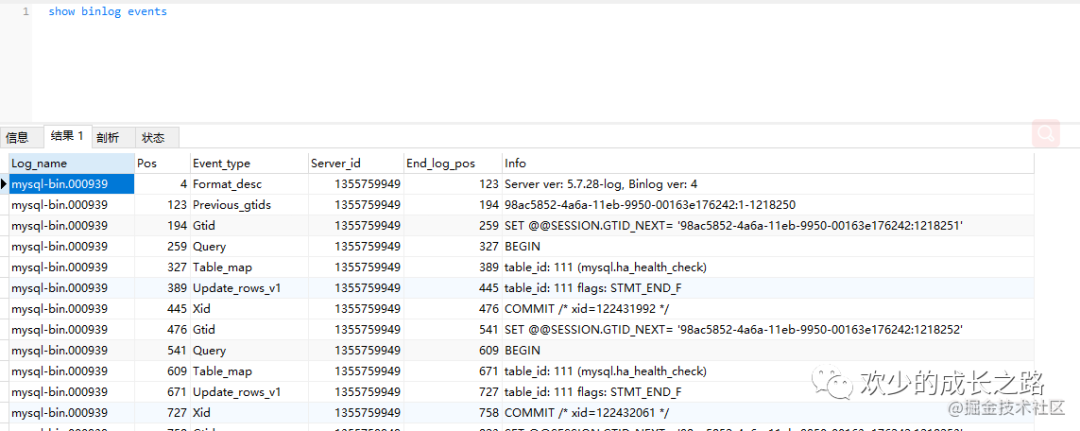
這兩種日志有以下三點(diǎn)不同。
redo log 是 InnoDB 引擎特有的;redo log 是物理日志,記錄的是“在某個(gè)數(shù)據(jù)頁上做了什么修改”
binlog 是 MySQL 的 Server 層實(shí)現(xiàn)的,所有引擎都可以使用。binlog 是邏輯日志,記錄的是這個(gè)語句的原始邏輯,
比如“給 ID=2 這一行的 c 字段加 1 ”。redo log 是循環(huán)寫的,空間固定會用完;binlog 是可以追加寫入的。“追加寫”是指 binlog 文件寫到一定大小后會切換到下一個(gè),并不會覆蓋以前的日志
更新執(zhí)行流程
執(zhí)行器先找引擎取 ID=2 這一行。ID 是主鍵,引擎直接用樹搜索找到這一行。如果 ID=2 這一行所在的數(shù)據(jù)頁本來就在內(nèi)存中,就直接返回給執(zhí)行器;否則,需要先從磁盤讀入內(nèi)存,然后再返回。
執(zhí)行器拿到引擎給的行數(shù)據(jù),把這個(gè)值加上 1,比如原來是 N,現(xiàn)在就是 N+1,得到新的一行數(shù)據(jù),再調(diào)用引擎接口寫入這行新數(shù)據(jù)。引擎將這行新數(shù)據(jù)更新到內(nèi)存中,同時(shí)將這個(gè)更新操作記錄到 redo log 里面,此時(shí) redo log 處于 prepare 狀態(tài)。
然后告知執(zhí)行器執(zhí)行完成了,隨時(shí)可以提交事務(wù)。執(zhí)行器生成這個(gè)操作的 binlog,并把 binlog 寫入磁盤。執(zhí)行器調(diào)用引擎的提交事務(wù)接口,引擎把剛剛寫入的 redo log 改成提交(commit)狀態(tài),更新完成。
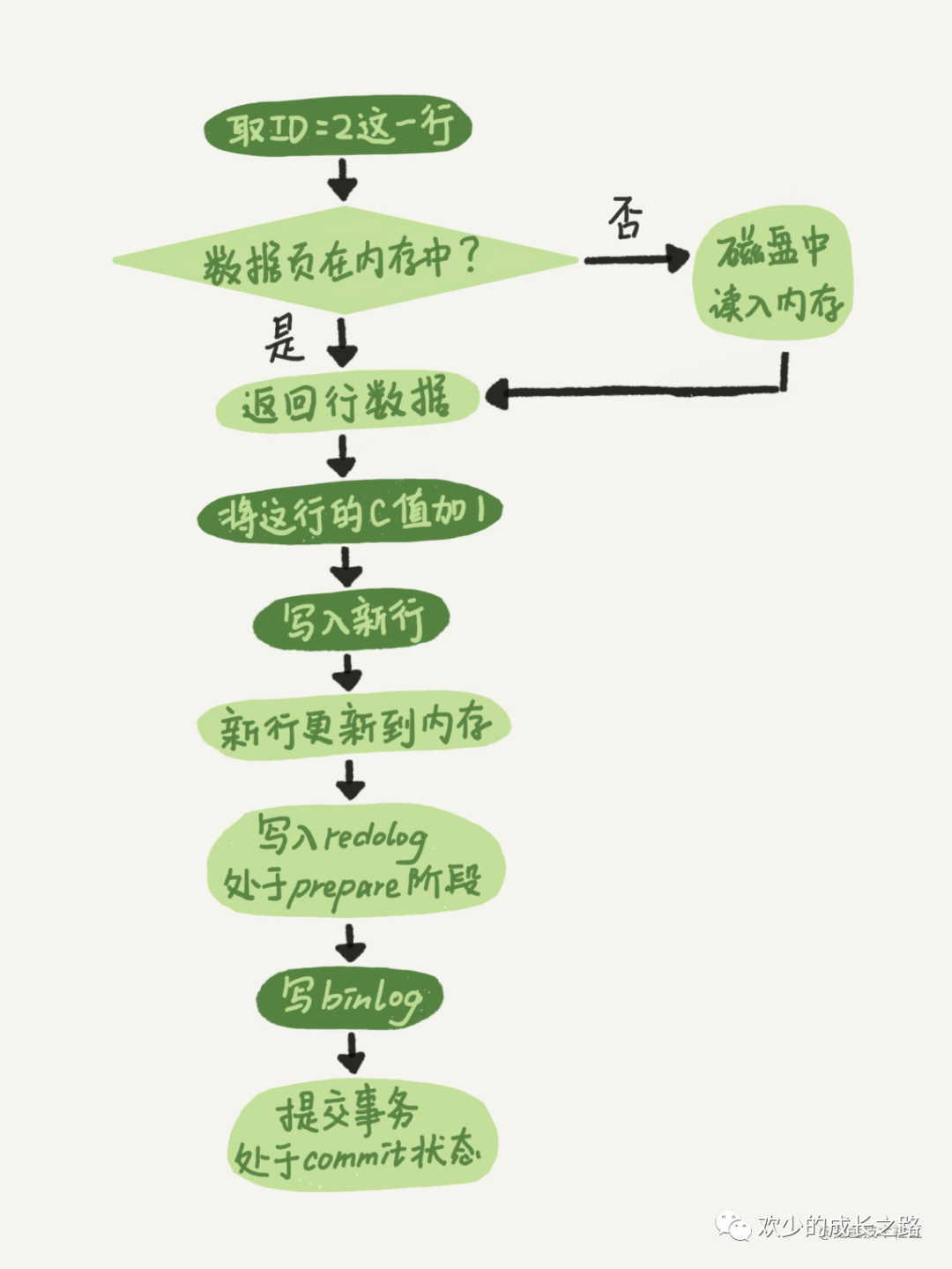
這張圖是來自丁奇老師的。我們簡單說一下最后三步吧。最不三步寫入redelog日志,commit提交,最后為啥要分兩步執(zhí)行呢?兩階段提交
首先說一下兩階段提交的目的:為了讓兩份日志的邏輯是一致的。
為什么要那么做?
以防你們搞混,我們先把日志內(nèi)容舉個(gè)例子。redo log存的是 我對CD=2這條數(shù)據(jù)做了修改。我要改成2,binlog有兩種模式,statement 格式的話是記sql語句, row格式會記錄行的內(nèi)容,記兩條,更新前和更新后都有。
由于 redo log 和 binlog 是兩個(gè)獨(dú)立的邏輯,如果不用兩階段提交,要么就是先寫完 redo log 再寫 binlog,或者采用反過來的順序。我們看看這兩種方式會有什么問題。
仍然用前面的 update 語句來做例子。假設(shè)當(dāng)前 ID=2 的行,字段 c 的值是 0,再假設(shè)執(zhí)行 update 語句過程中在寫完第一個(gè)日志后,第二個(gè)日志還沒有寫完期間發(fā)生了 crash,會出現(xiàn)什么情況呢?
先寫 redo log 后寫 binlog。假設(shè)在 redo log 寫完,binlog 還沒有寫完的時(shí)候,MySQL 進(jìn)程異常重啟。由于我們前面說過的,redo log 寫完之后,系統(tǒng)即使崩潰,仍然能夠把數(shù)據(jù)恢復(fù)回來,所以恢復(fù)后這一行 c 的值是 1。但是由于 binlog 沒寫完就 crash 了,這時(shí)候 binlog 里面就沒有記錄這個(gè)語句。因此,之后備份日志的時(shí)候,存起來的 binlog 里面就沒有這條語句。然后你會發(fā)現(xiàn),如果需要用這個(gè) binlog 來恢復(fù)臨時(shí)庫的話,由于這個(gè)語句的 binlog 丟失,這個(gè)臨時(shí)庫就會少了這一次更新,恢復(fù)出來的這一行 c 的值就是 0,與原庫的值不同。
先寫 binlog 后寫 redo log。如果在 binlog 寫完之后 crash,由于 redo log 還沒寫,崩潰恢復(fù)以后這個(gè)事務(wù)無效,所以這一行 c 的值是 0。但是 binlog 里面已經(jīng)記錄了“把 c 從 0 改成 1”這個(gè)日志。所以,在之后用 binlog 來恢復(fù)的時(shí)候就多了一個(gè)事務(wù)出來,恢復(fù)出來的這一行 c 的值就是 1,與原庫的值不同。
可以看到,如果不使用“兩階段提交”,那么數(shù)據(jù)庫的狀態(tài)就有可能和用它的日志恢復(fù)出來的庫的狀態(tài)不一致。你可能會說,這個(gè)概率是不是很低,平時(shí)也沒有什么動不動就需要恢復(fù)臨時(shí)庫的場景呀?其實(shí)不是的,不只是誤操作后需要用這個(gè)過程來恢復(fù)數(shù)據(jù)。
當(dāng)你需要擴(kuò)容的時(shí)候,也就是需要再多搭建一些備庫來增加系統(tǒng)的讀能力的時(shí)候,現(xiàn)在常見的做法也是用全量備份加上應(yīng)用 binlog 來實(shí)現(xiàn)的,這個(gè)“不一致”就會導(dǎo)致你的線上出現(xiàn)主從數(shù)據(jù)庫不一致的情況。簡單說,redo log 和 binlog 都可以用于表示事務(wù)的提交狀態(tài),而兩階段提交就是讓這兩個(gè)狀態(tài)保持邏輯上的一致。
擴(kuò)展: innodb_flush_log_at_trx_commit 這個(gè)參數(shù)設(shè)置成 1 的時(shí)候,表示每次事務(wù)的 redo log 都直接持久化到磁盤。這個(gè)參數(shù)我建議你設(shè)置成 1,這樣可以保證 MySQL 異常重啟之后數(shù)據(jù)不丟失。sync_binlog 這個(gè)參數(shù)設(shè)置成 1 的時(shí)候,表示每次事務(wù)的 binlog 都持久化到磁盤。這個(gè)參數(shù)我也建議你設(shè)置成 1,這樣可以保證 MySQL 異常重啟之后 binlog 不丟失。