
卷積神經(jīng)網(wǎng)絡(luò)中用1*1 卷積有什么作用或者好處呢?
點(diǎn)擊上方“程序員大白”,選擇“星標(biāo)”公眾號
重磅干貨,第一時(shí)間送達(dá)


來自 | 知乎
https://www.zhihu.com/question/56024942
編輯 | AI有道
本文僅作學(xué)術(shù)分享,若侵權(quán),請聯(lián)系后臺刪文處理
卷積神經(jīng)網(wǎng)絡(luò)中用1*1 卷積有什么作用或者好處呢?為什么非要加個(gè)1*1 呢,那不就是簡單的線性變換嗎??
作者:東東
https://www.zhihu.com/question/56024942/answer/154291405
來源:知乎
1*1卷積過濾器 和正常的過濾器一樣,唯一不同的是它的大小是1*1,沒有考慮在前一層局部信息之間的關(guān)系。最早出現(xiàn)在 Network In Network的論文中 ,使用1*1卷積是想加深加寬網(wǎng)絡(luò)結(jié)構(gòu) ,在Inception網(wǎng)絡(luò)( Going Deeper with Convolutions )中用來降維,如下圖:
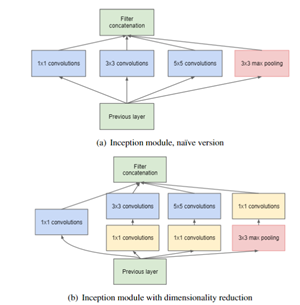
由于3*3卷積或者5*5卷積在幾百個(gè)filter的卷積層上做卷積操作時(shí)相當(dāng)耗時(shí),所以1*1卷積在3*3卷積或者5*5卷積計(jì)算之前先降低維度。
那么,1*1卷積的主要作用有以下幾點(diǎn):
1、降維( dimension reductionality )。比如,一張500 * 500且厚度depth為100 的圖片在20個(gè)filter上做1*1的卷積,那么結(jié)果的大小為500*500*20。
2、加入非線性。卷積層之后經(jīng)過激勵(lì)層,1*1的卷積在前一層的學(xué)習(xí)表示上添加了非線性激勵(lì)( non-linear activation ),提升網(wǎng)絡(luò)的表達(dá)能力;
作者:zhwhong
https://www.zhihu.com/question/56024942/answer/154846007
來源:知乎
可以實(shí)現(xiàn):
1. 實(shí)現(xiàn)跨通道的交互和信息整合
1×1的卷積層(可能)引起人們的重視是在NIN的結(jié)構(gòu)中,論文中林敏師兄的想法是利用MLP代替?zhèn)鹘y(tǒng)的線性卷積核,從而提高網(wǎng)絡(luò)的表達(dá)能力。文中同時(shí)利用了跨通道pooling的角度解釋,認(rèn)為文中提出的MLP其實(shí)等價(jià)于在傳統(tǒng)卷積核后面接cccp層,從而實(shí)現(xiàn)多個(gè)feature map的線性組合,實(shí)現(xiàn)跨通道的信息整合。而cccp層是等價(jià)于1×1卷積的,因此細(xì)看NIN的caffe實(shí)現(xiàn),就是在每個(gè)傳統(tǒng)卷積層后面接了兩個(gè)cccp層(其實(shí)就是接了兩個(gè)1×1的卷積層)。
2. 進(jìn)行卷積核通道數(shù)的降維和升維,減少網(wǎng)絡(luò)參數(shù)
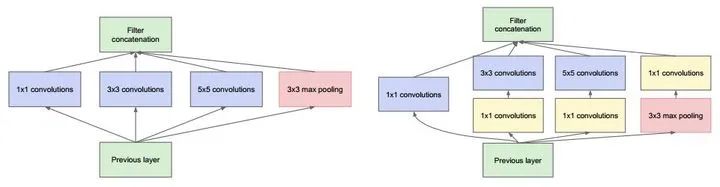
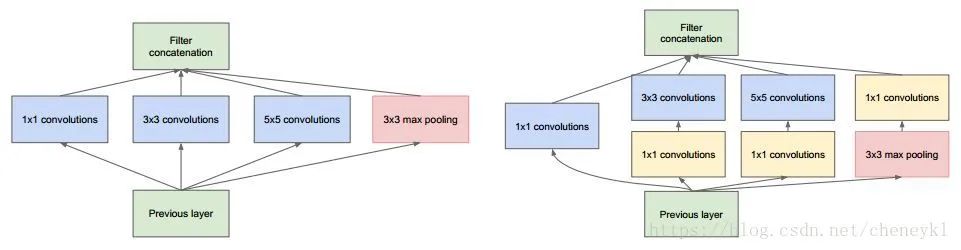
進(jìn)行降維和升維引起人們重視的(可能)是在GoogLeNet里。對于每一個(gè)Inception模塊(如下圖),原始模塊是左圖,右圖中是加入了1×1卷積進(jìn)行降維的。雖然左圖的卷積核都比較小,但是當(dāng)輸入和輸出的通道數(shù)很大時(shí),乘起來也會使得卷積核參數(shù)變的很大,而右圖加入1×1卷積后可以降低輸入的通道數(shù),卷積核參數(shù)、運(yùn)算復(fù)雜度也就跟著降下來了。以GoogLeNet的3a模塊為例,輸入的feature map是28×28×192,3a模塊中1×1卷積通道為64,3×3卷積通道為128,5×5卷積通道為32,如果是左圖結(jié)構(gòu),那么卷積核參數(shù)為1×1×192×64+3×3×192×128+5×5×192×32,而右圖對3×3和5×5卷積層前分別加入了通道數(shù)為96和16的1×1卷積層,這樣卷積核參數(shù)就變成了1×1×192×64+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32),參數(shù)大約減少到原來的三分之一。同時(shí)在并行pooling層后面加入1×1卷積層后也可以降低輸出的feature map數(shù)量,左圖pooling后feature map是不變的,再加卷積層得到的feature map,會使輸出的feature map擴(kuò)大到416,如果每個(gè)模塊都這樣,網(wǎng)絡(luò)的輸出會越來越大。而右圖在pooling后面加了通道為32的1×1卷積,使得輸出的feature map數(shù)降到了256。GoogLeNet利用1×1的卷積降維后,得到了更為緊湊的網(wǎng)絡(luò)結(jié)構(gòu),雖然總共有22層,但是參數(shù)數(shù)量卻只是8層的AlexNet的十二分之一(當(dāng)然也有很大一部分原因是去掉了全連接層)。
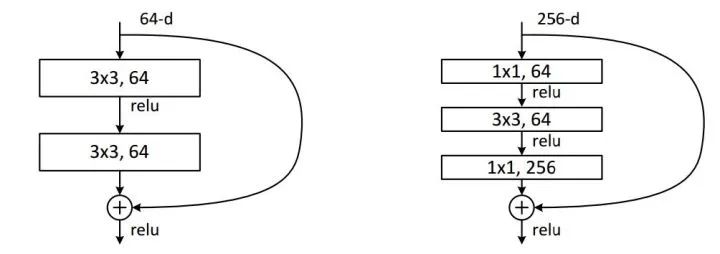
最近大熱的MSRA的ResNet同樣也利用了1×1卷積,并且是在3×3卷積層的前后都使用了,不僅進(jìn)行了降維,還進(jìn)行了升維,使得卷積層的輸入和輸出的通道數(shù)都減小,參數(shù)數(shù)量進(jìn)一步減少,如下圖的結(jié)構(gòu)。(不然真不敢想象152層的網(wǎng)絡(luò)要怎么跑起來TAT)
作者:康樂
https://www.zhihu.com/question/56024942/answer/369745892
來源:知乎
1、降維(減少參數(shù))
例子1 : GoogleNet中的3a模塊
輸入的feature map是28×28×192
1×1卷積通道為64
3×3卷積通道為128
5×5卷積通道為32
左圖卷積核參數(shù):192 × (1×1×64) +192 × (3×3×128) + 192 × (5×5×32) = 387072
右圖對3×3和5×5卷積層前分別加入了通道數(shù)為96和16的1×1卷積層,這樣卷積核參數(shù)就變成了:
192 × (1×1×64) +(192×1×1×96+ 96 × 3×3×128)+(192×1×1×16+16×5×5×32)= 157184
同時(shí)在并行pooling層后面加入1×1卷積層后也可以降低輸出的feature map數(shù)量(feature map尺寸指W、H是共享權(quán)值的sliding window,feature map 的數(shù)量就是channels)
左圖feature map數(shù)量:64 + 128 + 32 + 192(pooling后feature map不變) = 416 (如果每個(gè)模塊都這樣,網(wǎng)絡(luò)的輸出會越來越大)
右圖feature map數(shù)量:64 + 128 + 32 + 32(pooling后面加了通道為32的1×1卷積) = 256
GoogLeNet利用1×1的卷積降維后,得到了更為緊湊的網(wǎng)絡(luò)結(jié)構(gòu),雖然總共有22層,但是參數(shù)數(shù)量卻只是8層的AlexNet的十二分之一(當(dāng)然也有很大一部分原因是去掉了全連接層)
例子2:ResNet中的殘差模塊
假設(shè)上一層的feature map是w*h*256,并且最后要輸出的是256個(gè)feature map
左側(cè)操作數(shù):w*h*256*3*3*256 =589824*w*h
右側(cè)操作數(shù):w*h*256*1*1*64 + w*h*64*3*3*64 +w*h*64*1*1*256 = 69632*w*h,,左側(cè)參數(shù)大概是右側(cè)的8.5倍。(實(shí)現(xiàn)降維,減少參數(shù))
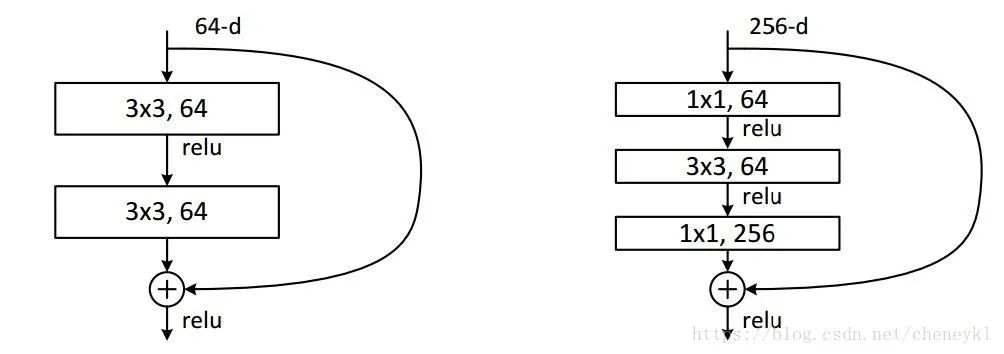
2、升維(用最少的參數(shù)拓寬網(wǎng)絡(luò)channal)
例子:上一個(gè)例子中,不僅在輸入處有一個(gè)1*1卷積核,在輸出處也有一個(gè)卷積核,3*3,64的卷積核的channel是64,只需添加一個(gè)1*1,256的卷積核,只用64*256個(gè)參數(shù)就能把網(wǎng)絡(luò)channel從64拓寬四倍到256。
3、跨通道信息交互(channal 的變換)
例子:使用1*1卷積核,實(shí)現(xiàn)降維和升維的操作其實(shí)就是channel間信息的線性組合變化,3*3,64channels的卷積核后面添加一個(gè)1*1,28channels的卷積核,就變成了3*3,28channels的卷積核,原來的64個(gè)channels就可以理解為跨通道線性組合變成了28channels,這就是通道間的信息交互。
注意:只是在channel維度上做線性組合,W和H上是共享權(quán)值的sliding window
4、增加非線性特性
1*1卷積核,可以在保持feature map尺度不變的(即不損失分辨率)的前提下大幅增加非線性特性(利用后接的非線性激活函數(shù)),把網(wǎng)絡(luò)做的很deep。
備注:一個(gè)filter對應(yīng)卷積后得到一個(gè)feature map,不同的filter(不同的weight和bias),卷積以后得到不同的feature map,提取不同的特征,得到對應(yīng)的specialized neuro。
四、從fully-connected layers的角度來理解1*1卷積核
將其看成全連接層
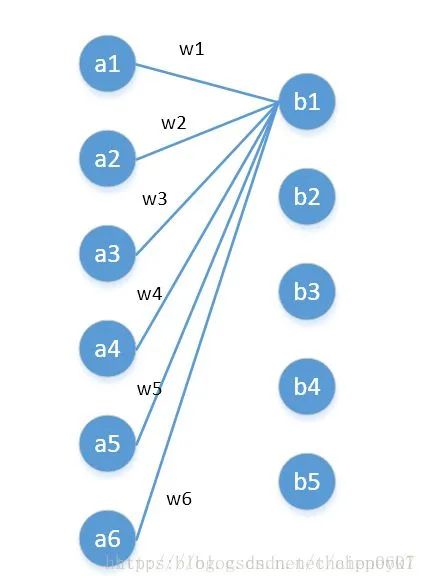
左邊6個(gè)神經(jīng)元,分別是a1—a6,通過全連接之后變成5個(gè),分別是b1—b5
左邊6個(gè)神經(jīng)元相當(dāng)于輸入特征里面的channels:6
右邊5個(gè)神經(jīng)元相當(dāng)于1*1卷積之后的新的特征channels:5
左邊 W*H*6 經(jīng)過 1*1*5的卷積核就能實(shí)現(xiàn)全連接
In Convolutional Nets, there is no such thing as “fully-connected layers”. There are only convolution layers with 1x1 convolution kernels and a full connection table– Yann LeCun
作者:陳運(yùn)錦
https://www.zhihu.com/question/56024942/answer/195274297
來源:知乎
前面的回答講了許多1*1卷積核好處之類的,但是我認(rèn)為沒有切中題主想問的。題主想問的其實(shí)是,1*1的卷積不就是多個(gè)feature channels之間的線性疊加嗎,為什要說成是什么1*1的卷積這種貌似有特殊牛逼功能的概念?
題主你想的是對的,1*1的卷積就是多個(gè)feature channels線性疊加,nothing more!只不過這個(gè)組合系數(shù)恰好可以看成是一個(gè)1*1的卷積。這種表示的好處是,完全可以回到模型中其他常見N*N的框架下,不用定義新的層。
推薦閱讀
國產(chǎn)小眾瀏覽器因屏蔽視頻廣告,被索賠100萬(后續(xù))
年輕人“不講武德”:因看黃片上癮,把網(wǎng)站和786名女主播起訴了
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學(xué),西湖大學(xué)和上海交通大學(xué)的碩士博士運(yùn)營維護(hù)的號,大家樂于分享高質(zhì)量文章,喜歡總結(jié)知識,歡迎關(guān)注[程序員大白],大家一起學(xué)習(xí)進(jìn)步!