
注意力機制原理及其模型發(fā)展和應用
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達
Attention機制在近幾年來在圖像,自然語言處理等領域中都取得了重要的突破,被證明有益于提高模型的性能。Attention機制本身也是符合人腦和人眼的感知機制,這次我們主要以計算機視覺領域為例,講述Attention機制的原理,應用以及模型的發(fā)展。
1.1 何為Attention機制
所謂Attention機制,便是聚焦于局部信息的機制,比如圖像中的某一個圖像區(qū)域。隨著任務的變化,注意力區(qū)域往往會發(fā)生變化。

面對上面這樣的一張圖,如果你只是從整體來看,只看到了很多人頭,但是你拉近一個一個仔細看就了不得了,都是天才科學家。
圖中除了人臉之外的信息其實都是無用的,也做不了什么任務,Attention機制便是要找到這些最有用的信息,可以想見最簡單的場景就是從照片中檢測人臉了。
1.2 基于Attention的顯著目標檢測
和注意力機制相伴而生的一個任務便是顯著目標檢測,即salient object detection。它的輸入是一張圖,輸出是一張概率圖,概率越大的地方,代表是圖像中重要目標的概率越大,即人眼關注的重點,一個典型的顯著圖如下:

右圖就是左圖的顯著圖,在頭部位置概率最大,另外腿部,尾巴也有較大概率,這就是圖中真正有用的信息。
顯著目標檢測需要一個數據集,而這樣的數據集的收集便是通過追蹤多個實驗者的眼球在一定時間內的注意力方向進行平均得到,典型的步驟如下:
(1) 讓被測試者觀察圖。
(2) 用eye tracker記錄眼睛的注意力位置。
(3) 對所有測試者的注意力位置使用高斯濾波進行綜合。
(4) 結果以0~1的概率進行記錄。
于是就能得到下面這樣的圖,第二行是眼球追蹤結果,第三行就是顯著目標概率圖。

上面講述的都是空間上的注意力機制,即關注的是不同空間位置,而在CNN結構中,還有不同的特征通道,因此不同特征通道也有類似的原理,下面一起講述。
注意力機制的本質就是定位到感興趣的信息,抑制無用信息,結果通常都是以概率圖或者概率特征向量的形式展示,從原理上來說,主要分為空間注意力模型,通道注意力模型,空間和通道混合注意力模型三種,這里不區(qū)分soft和hard attention。
2.1?空間注意力模型(spatial attention)
不是圖像中所有的區(qū)域對任務的貢獻都是同樣重要的,只有任務相關的區(qū)域才是需要關心的,比如分類任務的主體,空間注意力模型就是尋找網絡中最重要的部位進行處理。
我們在這里給大家介紹兩個具有代表性的模型,第一個就是Google DeepMind提出的STN網絡(Spatial Transformer Network[1])。它通過學習輸入的形變,從而完成適合任務的預處理操作,是一種基于空間的Attention模型,網絡結構如下:
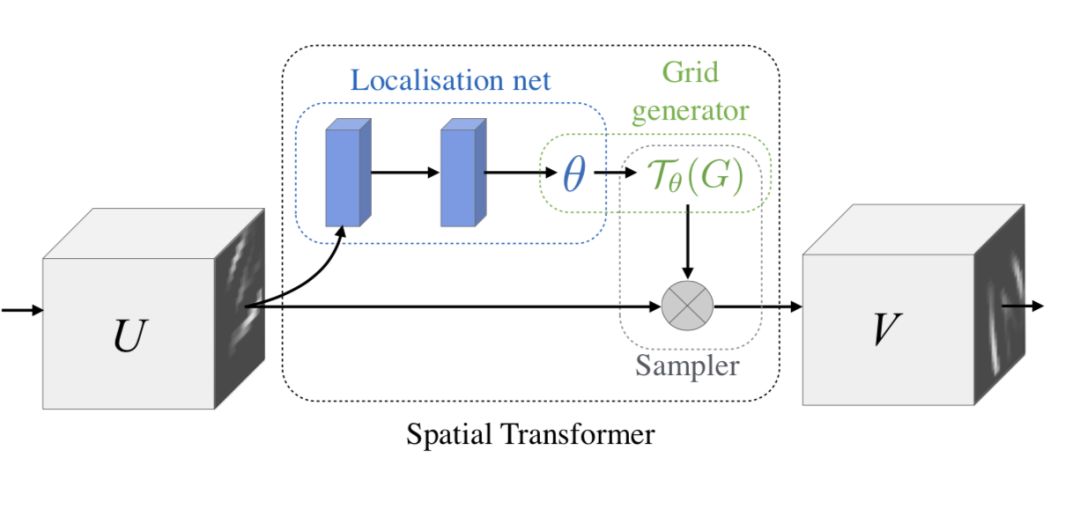
這里的Localization Net用于生成仿射變換系數,輸入是C×H×W維的圖像,輸出是一個空間變換系數,它的大小根據要學習的變換類型而定,如果是仿射變換,則是一個6維向量。
這樣的一個網絡要完成的效果如下圖:
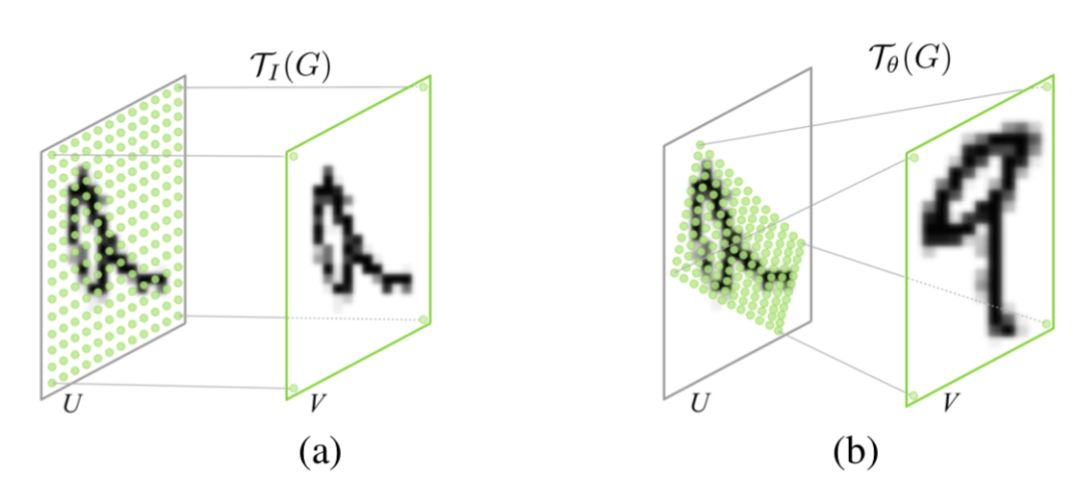
即定位到目標的位置,然后進行旋轉等操作,使得輸入樣本更加容易學習。這是一種一步調整的解決方案,當然還有很多迭代調整的方案,感興趣可以去有三知識星球星球中閱讀。
相比于Spatial Transformer Networks 一步完成目標的定位和仿射變換調整,Dynamic Capacity Networks[2]則采用了兩個子網絡,分別是低性能的子網絡(coarse model)和高性能的子網絡(fine model)。低性能的子網絡(coarse model)用于對全圖進行處理,定位感興趣區(qū)域,如下圖中的操作fc。高性能的子網絡(fine model)則對感興趣區(qū)域進行精細化處理,如下圖的操作ff。兩者共同使用,可以獲得更低的計算代價和更高的精度。
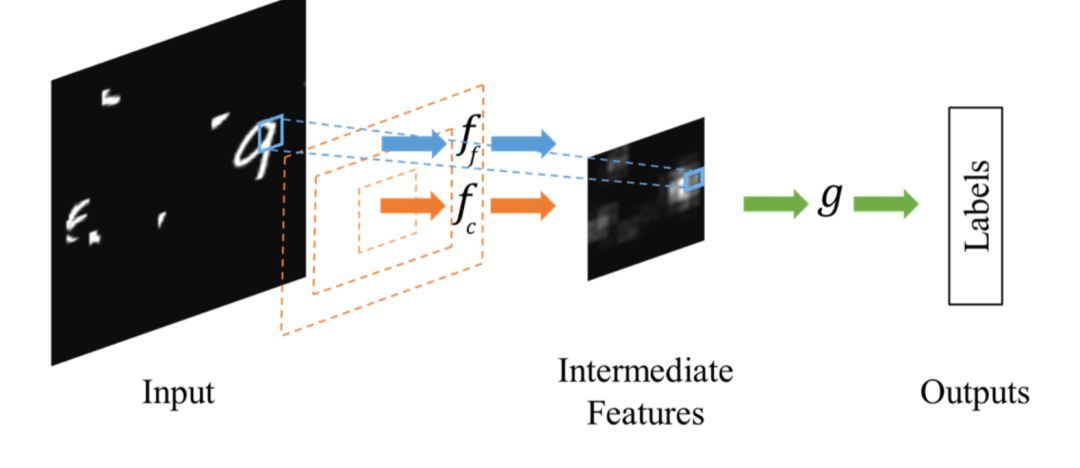
由于在大部分情況下我們感興趣的區(qū)域只是圖像中的一小部分,因此空間注意力的本質就是定位目標并進行一些變換或者獲取權重。
2.2 通道注意力機制
對于輸入2維圖像的CNN來說,一個維度是圖像的尺度空間,即長寬,另一個維度就是通道,因此基于通道的Attention也是很常用的機制。
SENet(Sequeeze and Excitation Net)[3]是2017屆ImageNet分類比賽的冠軍網絡,本質上是一個基于通道的Attention模型,它通過建模各個特征通道的重要程度,然后針對不同的任務增強或者抑制不同的通道,原理圖如下。
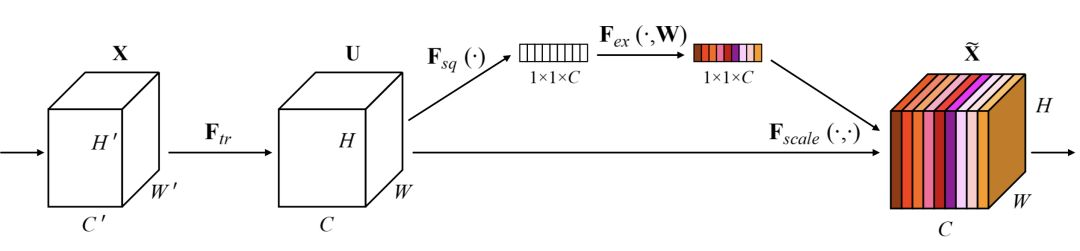
在正常的卷積操作后分出了一個旁路分支,首先進行Squeeze操作(即圖中Fsq(·)),它將空間維度進行特征壓縮,即每個二維的特征圖變成一個實數,相當于具有全局感受野的池化操作,特征通道數不變。
然后是Excitation操作(即圖中的Fex(·)),它通過參數w為每個特征通道生成權重,w被學習用來顯式地建模特征通道間的相關性。在文章中,使用了一個2層bottleneck結構(先降維再升維)的全連接層+Sigmoid函數來實現(xiàn)。
得到了每一個特征通道的權重之后,就將該權重應用于原來的每個特征通道,基于特定的任務,就可以學習到不同通道的重要性。
將其機制應用于若干基準模型,在增加少量計算量的情況下,獲得了更明顯的性能提升。作為一種通用的設計思想,它可以被用于任何現(xiàn)有網絡,具有較強的實踐意義。而后SKNet[4]等方法將這樣的通道加權的思想和Inception中的多分支網絡結構進行結合,也實現(xiàn)了性能的提升。
通道注意力機制的本質,在于建模了各個特征之間的重要性,對于不同的任務可以根據輸入進行特征分配,簡單而有效。
2.3 空間和通道注意力機制的融合
前述的Dynamic Capacity Network是從空間維度進行Attention,SENet是從通道維度進行Attention,自然也可以同時使用空間Attention和通道Attention機制。
CBAM(Convolutional Block Attention Module)[5]是其中的代表性網絡,結構如下:
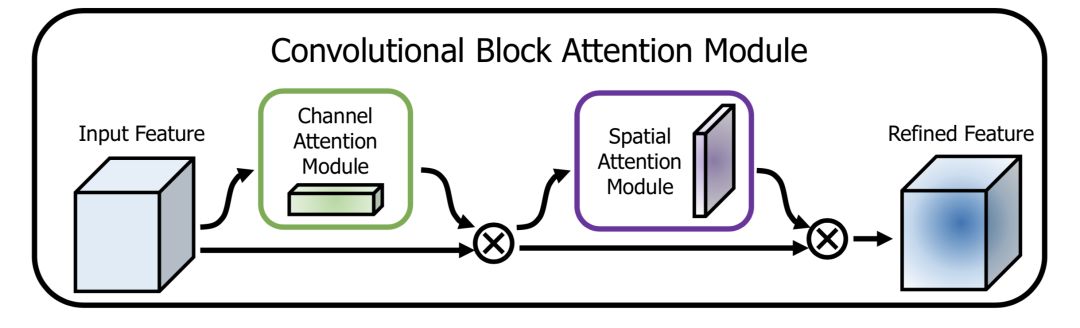
通道方向的Attention建模的是特征的重要性,結構如下:
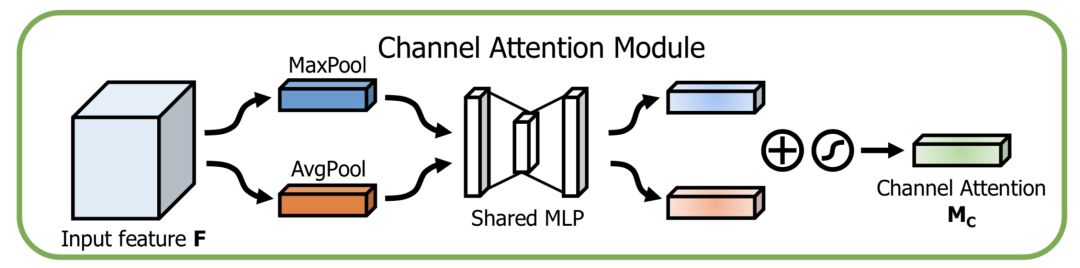
同時使用最大pooling和均值pooling算法,然后經過幾個MLP層獲得變換結果,最后分別應用于兩個通道,使用sigmoid函數得到通道的attention結果。
空間方向的Attention建模的是空間位置的重要性,結構如下:
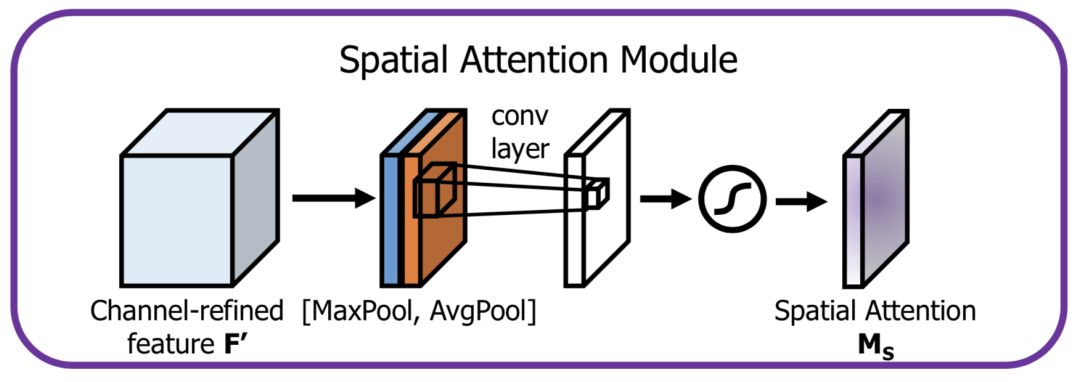
首先將通道本身進行降維,分別獲取最大池化和均值池化結果,然后拼接成一個特征圖,再使用一個卷積層進行學習。??
這兩種機制,分別學習了通道的重要性和空間的重要性,還可以很容易地嵌入到任何已知的框架中。
除此之外,還有很多的注意力機制相關的研究,比如殘差注意力機制,多尺度注意力機制,遞歸注意力機制等。
從原理上來說,注意力機制在所有的計算機視覺任務中都能提升模型性能,但是有兩類場景尤其受益。
3.1 細粒度分類
關于細粒度分類的基礎內容,可以回顧公眾號的往期文章。
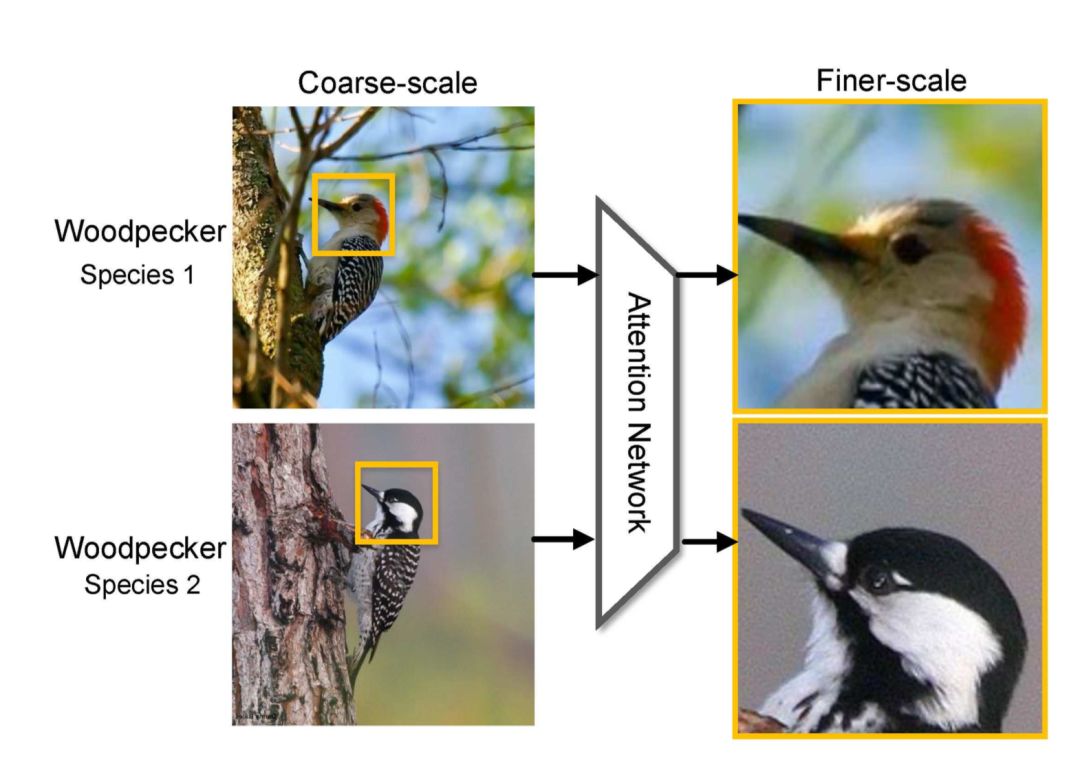
我們知道細粒度分類任務中真正的難題在于如何定位到真正對任務有用的局部區(qū)域,如上示意圖中的鳥的頭部。Attention機制恰巧原理上非常合適,文[1],[6]中都使用了注意力機制,對模型的提升效果很明顯。
3.2 顯著目標檢測/縮略圖生成/自動構圖
我們又回到了開頭,沒錯,Attention的本質就是重要/顯著區(qū)域定位,所以在目標檢測領域是非常有用的。


上圖展示了幾個顯著目標檢測的結果,可以看出對于有顯著目標的圖,概率圖非常聚焦于目標主體,在網絡中添加注意力機制模塊,可以進一步提升這一類任務的模型。
參考文獻
[1] Jaderberg M, Simonyan K, Zisserman A. Spatial transformer networks[C]//Advances in neural information processing systems. 2015: 2017-2025.
[2] Almahairi A, Ballas N, Cooijmans T, et al. Dynamic capacity networks[C]//International Conference on Machine Learning. 2016: 2549-2558.
[3] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
[4] Li X, Wang W, Hu X, et al. Selective Kernel Networks[J]. 2019.
[5] Woo S, Park J, Lee J Y, et al. Cbam: Convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 3-19.
[6] Fu J, Zheng H, Mei T. Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4438-4446.
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據研究方向邀請進入相關微信群。請勿在群內發(fā)送廣告,否則會請出群,謝謝理解~