點(diǎn)擊左上方藍(lán)字關(guān)注我們
一個(gè)專注于目標(biāo)檢測(cè)與深度學(xué)習(xí)知識(shí)分享的公眾號(hào) 注意力模型(AM)最初被用于機(jī)器翻譯,現(xiàn)在已成為神經(jīng)網(wǎng)絡(luò)領(lǐng)域的一個(gè)重要概念。在人工智能(Artificial Intelligence,AI)領(lǐng)域,注意力已成為神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的重要組成部分,并在自然語言處理、統(tǒng)計(jì)學(xué)習(xí)、語音和計(jì)算機(jī)等領(lǐng)域有著大量的應(yīng)用。 01
注意力機(jī)制(Attention Mechanism)淺談 早期在解決機(jī)器翻譯這一類序列到序列(Sequence to Sequence)的問題時(shí),通常采用的做法是利用一個(gè)編碼器(Encoder)和一個(gè)解碼器(Decoder)構(gòu)建端到端的神經(jīng)網(wǎng)絡(luò)模型,但是基于編碼解碼的神經(jīng)網(wǎng)絡(luò)存在兩個(gè)問題,拿機(jī)器翻譯舉例: 問題1:如果翻譯的句子很長(zhǎng)很復(fù)雜,比如直接一篇文章輸進(jìn)去,模型的計(jì)算量很大,并且模型的準(zhǔn)確率下降嚴(yán)重。 問題2:在翻譯時(shí),可能在不同的語境下,同一個(gè)詞具有不同的含義,但是網(wǎng)絡(luò)對(duì)這些詞向量并沒有區(qū)分度,沒有考慮詞與詞之間的相關(guān)性,導(dǎo)致翻譯效果比較差。 同樣在計(jì)算機(jī)視覺領(lǐng)域,如果輸入的圖像尺寸很大,做圖像分類或者識(shí)別時(shí),模型的性能就會(huì)下降。 針對(duì)這樣的問題,注意力機(jī)制被提出。 注意力機(jī)制早在上世紀(jì)九十年代就有研究,到2014年Volodymyr的《Recurrent Models of Visual Attention》一文中將其應(yīng)用在視覺領(lǐng)域,后來伴隨著2017年Ashish Vaswani的《Attention is all you need》中Transformer結(jié)構(gòu)的提出,注意力機(jī)制在NLP,CV相關(guān)問題的網(wǎng)絡(luò)設(shè)計(jì)上被廣泛應(yīng)用。 “注意力機(jī)制”實(shí)際上就是想將人的感知方式、注意力的行為應(yīng)用在機(jī)器上,讓機(jī)器學(xué)會(huì)去感知數(shù)據(jù)中的重要和不重要的部分。 打個(gè)比方:當(dāng)我們觀察下面這張圖片時(shí),大部分人第一眼應(yīng)該注意到的是小貓的面部以及吐出的舌頭,然后我們才會(huì)把我們的注意力轉(zhuǎn)移到圖片的其他部分。 所謂的"注意力機(jī)制"也就是當(dāng)機(jī)器在做一些任務(wù),比如要識(shí)別下面這張圖片是一個(gè)什么動(dòng)物時(shí),我們讓機(jī)器也存在這樣的一個(gè)注意力側(cè)重,最重要該關(guān)注的地方就是圖片中動(dòng)物的面部特征,包括耳朵,眼睛,鼻子,嘴巴,而不用太關(guān)注背景的一些信息,核心的目的就在于希望機(jī)器能在很多的信息中注意到對(duì)當(dāng)前任務(wù)更關(guān)鍵的信息,而對(duì)于其他的非關(guān)鍵信息就不需要太多的注意力側(cè)重。 同樣的如果我們?cè)跈C(jī)器翻譯中,我們要讓機(jī)器注意到每個(gè)詞向量之間的相關(guān)性,有側(cè)重地進(jìn)行翻譯,模擬人類理解的過程。
3. 注意力機(jī)制如何實(shí)現(xiàn),以及注意力機(jī)制的分類 簡(jiǎn)單來說就是對(duì)于模型的每一個(gè)輸入項(xiàng),可能是圖片中的不同部分,或者是語句中的某個(gè)單詞分配一個(gè)權(quán)重,這個(gè)權(quán)重的大小就代表了我們希望模型對(duì)該部分一個(gè)關(guān)注程度。這樣一來,通過權(quán)重大小來模擬人在處理信息的注意力的側(cè)重,有效的提高了模型的性能,并且一定程度上降低了計(jì)算量。
深度學(xué)習(xí)中的注意力機(jī)制通常可分為三類:軟注意(全局注意)、硬注意(局部注意)和自注意(內(nèi)注意) 1. Soft/Global Attention(軟注意機(jī)制): 對(duì)每個(gè)輸入項(xiàng)的分配的權(quán)重為0-1之間,也就是某些部分關(guān)注的多一點(diǎn),某些部分關(guān)注的少一點(diǎn),因?yàn)閷?duì)大部分信息都有考慮,但考慮程度不一樣,所以相對(duì)來說計(jì)算量比較大。 2. Hard/Local Attention(硬注意機(jī)制): 對(duì)每個(gè)輸入項(xiàng)分配的權(quán)重非0即1,和軟注意不同,硬注意機(jī)制只考慮那部分需要關(guān)注,哪部分不關(guān)注,也就是直接舍棄掉一些不相關(guān)項(xiàng)。優(yōu)勢(shì)在于可以減少一定的時(shí)間和計(jì)算成本,但有可能丟失掉一些本應(yīng)該注意的信息。 3. Self/Intra Attention(自注意力機(jī)制): 對(duì)每個(gè)輸入項(xiàng)分配的權(quán)重取決于輸入項(xiàng)之間的相互作用,即通過輸入項(xiàng)內(nèi)部的"表決"來決定應(yīng)該關(guān)注哪些輸入項(xiàng)。和前兩種相比,在處理很長(zhǎng)的輸入時(shí),具有并行計(jì)算的優(yōu)勢(shì)。
References:
https://arxiv.org/abs/2103.16775 https://arxiv.org/abs/1406.6247 https://arxiv.org/abs/1706.03762
02
自注意力機(jī)制(Self-Attention)
1. 自注意力機(jī)制概述
自注意力機(jī)制實(shí)際上是注意力機(jī)制中的一種,也是一種網(wǎng)絡(luò)的構(gòu)型,它想要解決的問題是網(wǎng)絡(luò)接收的輸入是很多向量,并且向量的大小也是不確定的情況,比如機(jī)器翻譯(序列到序列的問題,機(jī)器自己決定多少個(gè)標(biāo)簽),詞性標(biāo)注(Pos tagging一個(gè)向量對(duì)應(yīng)一個(gè)標(biāo)簽),語義分析(多個(gè)向量對(duì)應(yīng)一個(gè)標(biāo)簽)等文字處理問題。
2. 文字處理中單詞向量編碼的方式
在文字處理中,我們對(duì)單詞進(jìn)行向量編碼通常有兩種方式: 1. 獨(dú)熱編碼(one-hot encoding): 用N位的寄存器對(duì)N個(gè)狀態(tài)編碼,通俗來講就是開一個(gè)很長(zhǎng)很長(zhǎng)的向量,向量的長(zhǎng)度和世界上存在的詞語的數(shù)量是一樣多的,每一項(xiàng)都表示一個(gè)詞語,只要把其中的某一項(xiàng)置1,其他的項(xiàng)都置0,那么就可以表示一個(gè)詞語,但這樣的編碼方式?jīng)]有考慮詞語之間的相關(guān)性,并且內(nèi)存占用也很大 2. 詞向量編碼(Word Embedding): 將詞語映射(嵌入)到另一個(gè)數(shù)值向量空間,可以通過距離來表征不同詞語之間的相關(guān)性 拿詞性標(biāo)注舉例,對(duì)一個(gè)句子來說每一個(gè)詞向量對(duì)應(yīng)一個(gè)標(biāo)簽,初始的想法是可以通過全連接神經(jīng)網(wǎng)絡(luò),但全連接神經(jīng)網(wǎng)絡(luò)沒有考慮在句子不同位置,單詞可能表示不同含義的問題,并且當(dāng)輸入的句子很長(zhǎng),比如是一篇文章的時(shí)候,模型的性能下降嚴(yán)重。
3. 自注意力機(jī)制如何實(shí)現(xiàn)
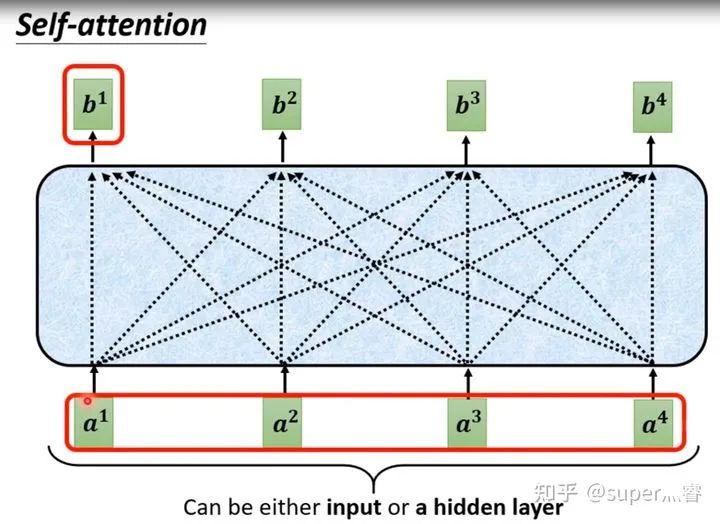
針對(duì)全連接神經(jīng)網(wǎng)絡(luò)存在的這個(gè)問題,通過自注意力機(jī)制來解決,自注意力機(jī)制實(shí)際上是想讓機(jī)器注意到整個(gè)輸入中不同部分之間的相關(guān)性,它的實(shí)現(xiàn)方法如下: 對(duì)于每一個(gè)輸入向量a,在本例中也就是每一個(gè)詞向量,經(jīng)過self-attention之后都輸出一個(gè)向量b,這個(gè)向量b是考慮了所有的輸入向量才得到的,這里有四個(gè)詞向量a對(duì)應(yīng)就會(huì)輸出四個(gè)向量b
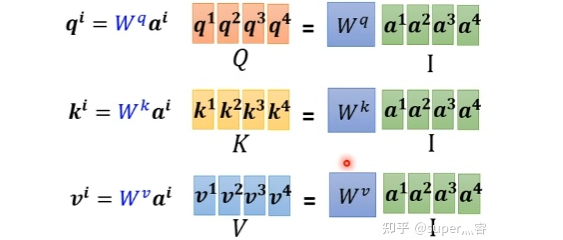
步驟1:對(duì)于每一個(gè)向量a,分別乘上三個(gè)系數(shù) , , 得到q,k,v三個(gè)值: 寫成向量形式: 寫成向量形式: 寫成向量形式: 得到的Q,K,V分別表示query,key和value
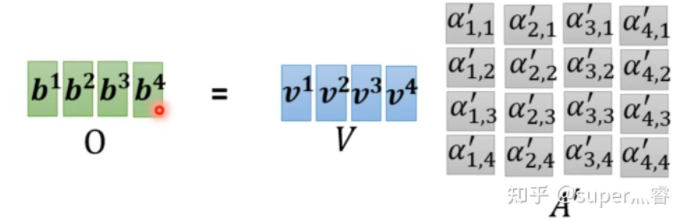
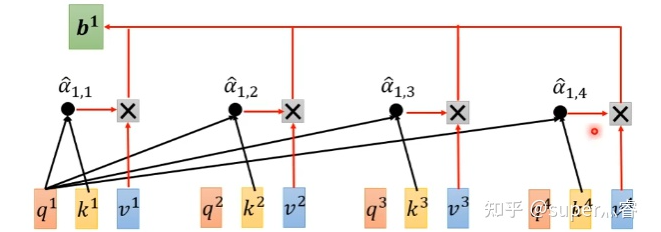
三個(gè)W就是我們需要學(xué)習(xí)的參數(shù) 步驟2:利用得到的Q和K計(jì)算每?jī)蓚€(gè)輸入向量之間的相關(guān)性,也就是計(jì)算attention的值α,α的計(jì)算方法有多種,通常采用點(diǎn)乘的方式 寫成向量形式: 矩陣A中的每一個(gè)值記錄了對(duì)應(yīng)的兩個(gè)輸入向量的Attention的大小α 步驟3:對(duì)A矩陣進(jìn)行softmax操作或者relu操作得到A' 步驟4:利用得到的A'和V計(jì)算每個(gè)輸入向量a對(duì)應(yīng)的self-attention層的輸出向量b: ,寫成向量形式 拿第一個(gè)向量a1對(duì)應(yīng)的self-attention輸出向量b1舉例,它的產(chǎn)生過程如下:
先通過三個(gè)W矩陣生成q,k,v;然后利用q,k計(jì)算attention的值α,再把所有的α經(jīng)過softmax得到α';最后對(duì)所有的v進(jìn)行加權(quán)求和,權(quán)重是α',得到a1對(duì)應(yīng)的self-attention輸出的b1
4. 自注意力機(jī)制的問題
自注意力機(jī)制雖然考慮了所有的輸入向量,但沒有考慮到向量的位置信息。在實(shí)際的文字處理問題中,可能在不同位置詞語具有不同的性質(zhì),比如動(dòng)詞往往較低頻率出現(xiàn)在句首。 有學(xué)者提出可以通過位置編碼(Positional Encoding)來解決這個(gè)問題:對(duì)每一個(gè)輸入向量加上一個(gè)位置向量e,位置向量的生成方式有多種,通過e來表示位置信息帶入self-attention層進(jìn)行計(jì)算。 https://arxiv.org/abs/2003.09229
5. 自注意力機(jī)制&CNN、RNN
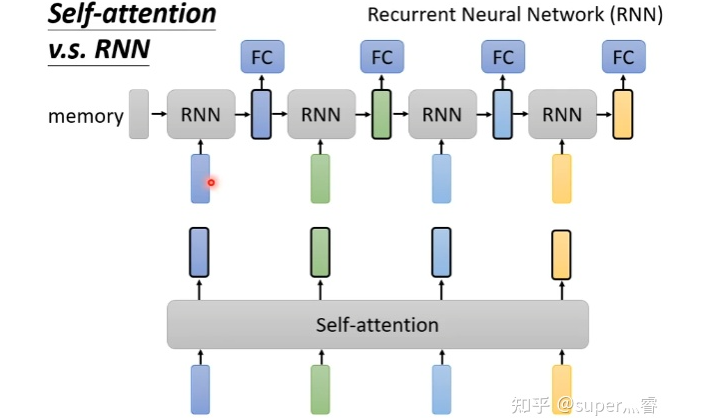
實(shí)際上,在處理圖像問題時(shí),每一個(gè)像素點(diǎn)都可以看成一個(gè)三維的向量,維度就是圖像的通道數(shù),所以圖像也可以看成是很多向量輸入到模型,自注意力機(jī)制和CNN的概念類似,都是希望網(wǎng)絡(luò)不僅僅考慮某一個(gè)向量,也就是CNN中希望模型不僅僅考慮某一個(gè)像素點(diǎn),而是讓模型考慮一個(gè)正方形或者矩形的感受野(Receptive field),對(duì)于自注意力機(jī)制來說,相當(dāng)于模型自己決定receptive field是怎樣的形狀和類型。所以其實(shí)CNN卷積神經(jīng)網(wǎng)絡(luò)是特殊情況下的一種self-attention,self-attention就是復(fù)雜版的CNN。 https://arxiv.org/abs/1911.03584 RNN和自注意力機(jī)制也類似,都是接受一批輸入向量,然后輸出一批向量,但RNN只能接受前面的輸出作為輸入,self-attention可以同時(shí)接受所有的向量作為輸入,所以一定程度上說Self-attention比RNN更具效率 https://arxiv.org/abs/2006.16236
相關(guān)鏈接:
https://zhuanlan.zhihu.com/p/364819787
https://zhuanlan.zhihu.com/p/365550383
雙一流大學(xué)研究生團(tuán)隊(duì)創(chuàng)建,專注于目標(biāo)檢測(cè)與深度學(xué)習(xí),希望可以將分享變成一種習(xí)慣! 點(diǎn)贊 三連,支持一下吧↓



 ,
,  ,
, 得到q,k,v三個(gè)值:
得到q,k,v三個(gè)值: 寫成向量形式:
寫成向量形式: 
 寫成向量形式:
寫成向量形式: 
 寫成向量形式:
寫成向量形式: 
 寫成向量形式:
寫成向量形式: 

 ,寫成向量形式
,寫成向量形式