
綜述 | 注意力機(jī)制
點(diǎn)擊上方“程序員大白”,選擇“星標(biāo)”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)


來(lái)源:人工智能前沿講習(xí)
地址:https://zhuanlan.zhihu.com/p/364819787、https://zhuanlan.zhihu.com/p/365550383
01

3. 注意力機(jī)制如何實(shí)現(xiàn),以及注意力機(jī)制的分類
簡(jiǎn)單來(lái)說(shuō)就是對(duì)于模型的每一個(gè)輸入項(xiàng),可能是圖片中的不同部分,或者是語(yǔ)句中的某個(gè)單詞分配一個(gè)權(quán)重,這個(gè)權(quán)重的大小就代表了我們希望模型對(duì)該部分一個(gè)關(guān)注程度。這樣一來(lái),通過(guò)權(quán)重大小來(lái)模擬人在處理信息的注意力的側(cè)重,有效的提高了模型的性能,并且一定程度上降低了計(jì)算量。
References:
02
1. 自注意力機(jī)制概述
2. 文字處理中單詞向量編碼的方式
3. 自注意力機(jī)制如何實(shí)現(xiàn)

對(duì)于每一個(gè)輸入向量a,在本例中也就是每一個(gè)詞向量,經(jīng)過(guò)self-attention之后都輸出一個(gè)向量b,這個(gè)向量b是考慮了所有的輸入向量才得到的,這里有四個(gè)詞向量a對(duì)應(yīng)就會(huì)輸出四個(gè)向量b
 ,
,  ,
, 得到q,k,v三個(gè)值:
得到q,k,v三個(gè)值: 寫成向量形式:
寫成向量形式: 
 寫成向量形式:
寫成向量形式: 
 寫成向量形式:
寫成向量形式: 

 寫成向量形式:
寫成向量形式: 

 ,寫成向量形式
,寫成向量形式 

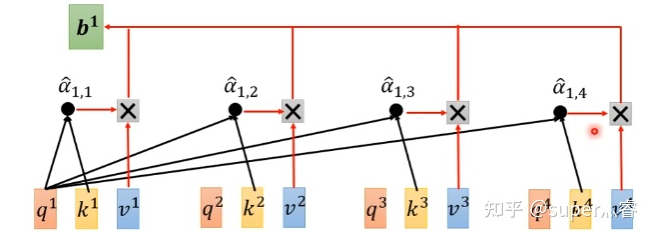
先通過(guò)三個(gè)W矩陣生成q,k,v;然后利用q,k計(jì)算attention的值α,再把所有的α經(jīng)過(guò)softmax得到α';最后對(duì)所有的v進(jìn)行加權(quán)求和,權(quán)重是α',得到a1對(duì)應(yīng)的self-attention輸出的b1
4. 自注意力機(jī)制的問(wèn)題
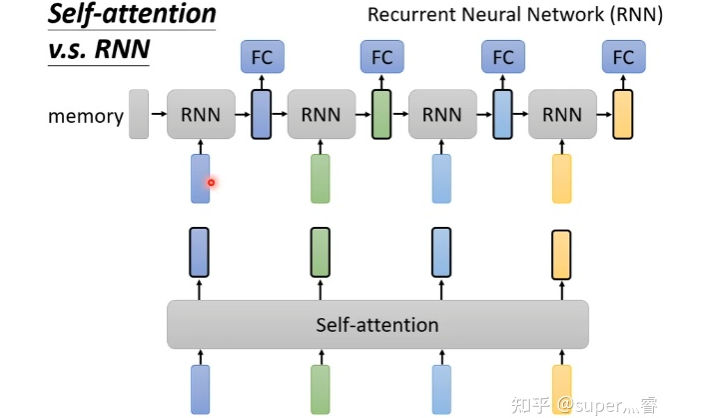
5. 自注意力機(jī)制&CNN、RNN
評(píng)論
圖片
表情