
實(shí)時(shí)數(shù)倉(cāng)建設(shè)思考與方案記錄
前言
隨著我司業(yè)務(wù)飛速增長(zhǎng),實(shí)時(shí)數(shù)倉(cāng)的建設(shè)已經(jīng)提上了日程。雖然還沒有正式開始實(shí)施,但是汲取前人的經(jīng)驗(yàn),做好萬全的準(zhǔn)備總是必要的。本文簡(jiǎn)單松散地記錄一下想法,不涉及維度建模方法論的事情(這個(gè)就老老實(shí)實(shí)去問Kimball他老人家吧)。
動(dòng)機(jī)
隨著業(yè)務(wù)快速增長(zhǎng),傳統(tǒng)離線數(shù)倉(cāng)的不足暴露出來:
運(yùn)維層面——所有調(diào)度任務(wù)只能在業(yè)務(wù)閑時(shí)(凌晨)集中啟動(dòng),集群壓力大,耗時(shí)越來越長(zhǎng);
業(yè)務(wù)層面——數(shù)據(jù)按T+1更新,延遲高,數(shù)據(jù)時(shí)效價(jià)值打折扣,無法精細(xì)化運(yùn)營(yíng)與及時(shí)感知異常。
實(shí)時(shí)數(shù)倉(cāng)即離線數(shù)倉(cāng)的時(shí)效性改進(jìn)方案,從原本的小時(shí)/天級(jí)別做到秒/分鐘級(jí)別。
底層設(shè)計(jì)變動(dòng)的同時(shí),需要盡力保證平滑遷移,不影響用戶(分析人員)之前的使用習(xí)慣。
指導(dǎo)思想:Kappa架構(gòu)
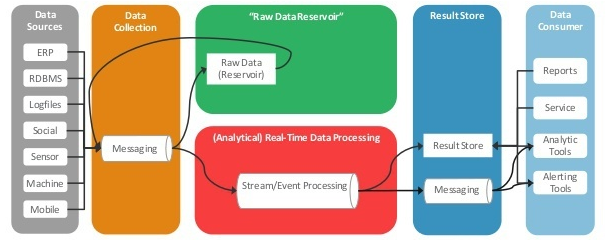
計(jì)算引擎
硬性要求
批流一體化——能同時(shí)進(jìn)行實(shí)時(shí)和離線的操作;提供統(tǒng)一易用的SQL interface——方便開發(fā)人員和分析人員。
可選項(xiàng):Spark、Flink,較優(yōu)解:Flink
優(yōu)點(diǎn):
嚴(yán)格按照Google Dataflow模型實(shí)現(xiàn);在事件時(shí)間、窗口、狀態(tài)、exactly-once等方面更有優(yōu)勢(shì);非微批次處理,真正的實(shí)時(shí)流處理;多層API,對(duì)table/SQL支持良好,支持UDF、流式j(luò)oin等高級(jí)用法。
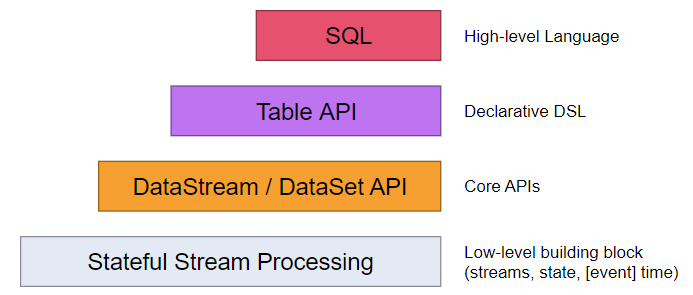
缺點(diǎn)
生態(tài)系統(tǒng)沒有Spark強(qiáng)大(不太重要);
1.10版本相比1.9版本的改動(dòng)較多,需要仔細(xì)研究。
底層(事實(shí)數(shù)據(jù))存儲(chǔ)引擎
硬性要求
數(shù)據(jù)in-flight——不能中途落地,處理完之后直接給到下游,最小化延遲;可靠存儲(chǔ)——有一定持久化能力,高可用,支持?jǐn)?shù)據(jù)重放。可選項(xiàng):各種消息隊(duì)列組件(Kafka、RabbitMQ、RocketMQ、Pulsar、...)
較優(yōu)解:Kafka
優(yōu)點(diǎn):
吞吐量很大;與Flink、Canal等外部系統(tǒng)的對(duì)接方案非常成熟,容易操作;團(tuán)隊(duì)使用經(jīng)驗(yàn)豐富。
中間層(維度數(shù)據(jù))存儲(chǔ)引擎
硬性要求
支持較大規(guī)模的查詢(主要是與事實(shí)數(shù)據(jù)join的查詢);能夠快速實(shí)時(shí)更新。可選項(xiàng):RDBMS(MySQL等)、NoSQL(HBase、Redis、Cassandra等)
較優(yōu)解:HBase
優(yōu)點(diǎn)
實(shí)時(shí)寫入性能高,且支持基于時(shí)間戳的多版本機(jī)制;
接入業(yè)務(wù)庫(kù)MySQL binlog簡(jiǎn)單;
可以通過集成Phoenix獲得SQL能力。
高層(明細(xì)/匯總數(shù)據(jù))存儲(chǔ)/查詢引擎
根據(jù)不同的需求,按照業(yè)務(wù)特點(diǎn)選擇不同的方案。
當(dāng)前已大規(guī)模應(yīng)用,可隨時(shí)利用的組件:
Greenplum——業(yè)務(wù)歷史明細(xì)、BI支持、大寬表MOLAP
Redis——大列表業(yè)務(wù)結(jié)果(PV/UV、標(biāo)簽、推薦結(jié)果、Top-N等)
HBase——高并發(fā)匯總指標(biāo)(用戶畫像)
MySQL——普通匯總指標(biāo)、匯總模型等
當(dāng)前未有或未大規(guī)模應(yīng)用的組件:
ElasticSearch(ELK)——日志明細(xì),似乎也可以用作OLAP?
Druid——OLAP
InfluxDB/OpenTSDB——時(shí)序數(shù)據(jù)
數(shù)倉(cāng)分層設(shè)計(jì)
參照傳統(tǒng)數(shù)倉(cāng)分層,盡量扁平,減少數(shù)據(jù)中途的lag,草圖如下。
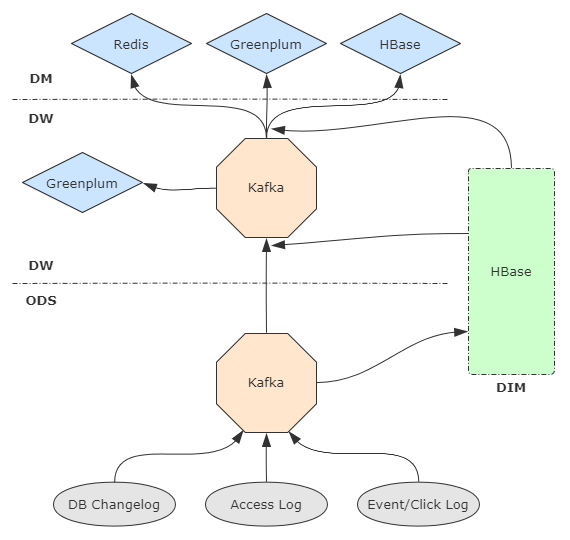
元數(shù)據(jù)管理
必要性 Kafka本身沒有Hive/GP等傳統(tǒng)數(shù)倉(cāng)組件的metastore,必須自己維護(hù)數(shù)據(jù)schema。(Flink 1.10開始正式在Table API中支持Catalog,用于外部元數(shù)據(jù)對(duì)接。)
可行方案
外部存儲(chǔ)(e.g. MySQL) + Flink ExternalCatalog
Hive metastore + Flink HiveCatalog(與上一種方案本質(zhì)相同,但是借用Hive的表描述與元數(shù)據(jù)體系)
Confluent Schema Registry (CSR) + Kafka Avro Serializer/Deserializer 現(xiàn)在仍然糾結(jié)中。
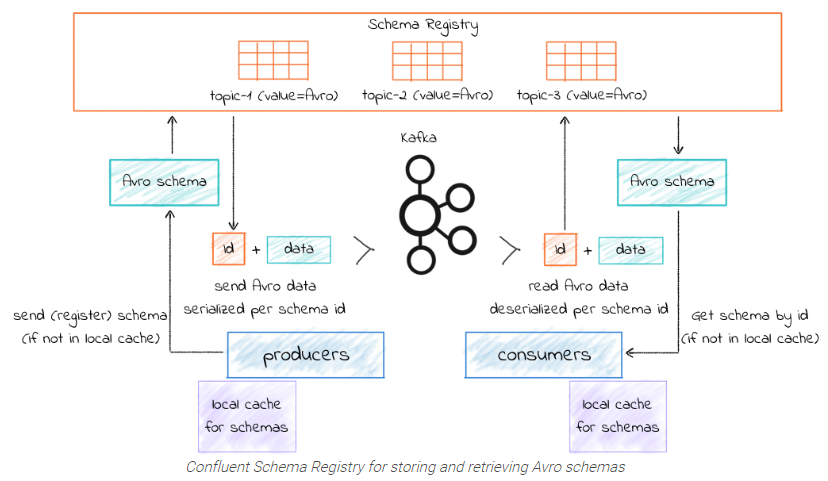
CSR是開源的元數(shù)據(jù)注冊(cè)中心,能與Kafka無縫集成,支持RESTful風(fēng)格管理。producer和consumer通過Avro序列化/反序列化來利用元數(shù)據(jù)。
SQL作業(yè)管理
必要性:實(shí)時(shí)數(shù)倉(cāng)平臺(tái)展現(xiàn)給分析人員的開發(fā)界面應(yīng)該是類似Hue的交互式查詢UI,即用戶寫標(biāo)準(zhǔn)SQL,在平臺(tái)上提交作業(yè)并返回結(jié)果,底層是透明的。但僅靠Flink SQL無法實(shí)現(xiàn),需要我們自行填補(bǔ)這個(gè)gap。
可行方案:AthenaX(由Uber開源)
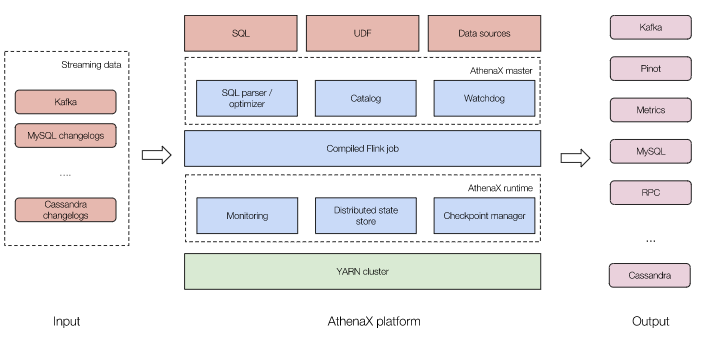
流程:用戶提交SQL → 通過Catalog獲取元數(shù)據(jù) → 解釋、校驗(yàn)、優(yōu)化SQL → 編譯為Flink Table/SQL job → 部署到Y(jié)ARN集群并運(yùn)行 → 輸出結(jié)果 重點(diǎn)仍然是元數(shù)據(jù)問題:如何將AthenaX的Catalog與Flink的Catalog打通?
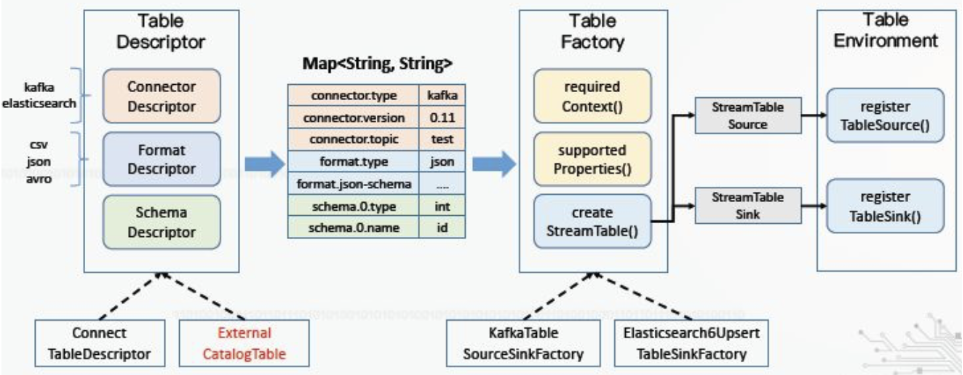
需要將外部元數(shù)據(jù)的對(duì)應(yīng)到Flink的TableDescriptor(包含connector、format、schema三類參數(shù)),進(jìn)而映射到相應(yīng)的TableFactory并注冊(cè)表。
另外還需要控制SQL作業(yè)對(duì)YARN資源的占用,考慮用YARN隊(duì)列實(shí)現(xiàn),視情況調(diào)整調(diào)度策略。
性能監(jiān)控
使用Flink Metrics,主要考慮兩點(diǎn):
算子數(shù)據(jù)吞吐量(numRecordsInPerSecond/numRecordsOutPerSecond)
Kafka鏈路延遲(records-lag-max)→ 如果搞全鏈路延遲,需要做數(shù)據(jù)血緣分析
數(shù)據(jù)質(zhì)量保證
手動(dòng)對(duì)數(shù)——旁路寫明細(xì)表,定期與數(shù)據(jù)源交叉驗(yàn)證
自動(dòng)監(jiān)控——數(shù)據(jù)指標(biāo)波動(dòng)告警 etc