
實(shí)例分割最新最全面綜述:從Mask R-CNN到BlendMask
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

本文轉(zhuǎn)自|AI算法與圖像處理
前面的話
實(shí)例分割(Instance Segmentation)是視覺(jué)經(jīng)典四個(gè)任務(wù)中相對(duì)最難的一個(gè),它既具備語(yǔ)義分割(Semantic Segmentation)的特點(diǎn),需要做到像素層面上的分類,也具備目標(biāo)檢測(cè)(Object Detection)的一部分特點(diǎn),即需要定位出不同實(shí)例,即使它們是同一種類。因此,實(shí)例分割的研究長(zhǎng)期以來(lái)都有著兩條線,分別是自下而上的基于語(yǔ)義分割的方法和自上而下的基于檢測(cè)的方法,這兩種方法都屬于兩階段的方法,下面將分別簡(jiǎn)單介紹。
自上而下的實(shí)例分割方法
思路是:首先通過(guò)目標(biāo)檢測(cè)的方法找出實(shí)例所在的區(qū)域(bounding box),再在檢測(cè)框內(nèi)進(jìn)行語(yǔ)義分割,每個(gè)分割結(jié)果都作為一個(gè)不同的實(shí)例輸出。
自上而下的密集實(shí)例分割的開山鼻祖是DeepMask,它通過(guò)滑動(dòng)窗口的方法,在每個(gè)空間區(qū)域上都預(yù)測(cè)一個(gè)mask proposal。這個(gè)方法存在以下三個(gè)缺點(diǎn):
mask與特征的聯(lián)系(局部一致性)丟失了,如DeepMask中使用全連接網(wǎng)絡(luò)去提取mask
特征的提取表示是冗余的, 如DeepMask對(duì)每個(gè)前景特征都會(huì)去提取一次mask
下采樣(使用步長(zhǎng)大于1的卷積)導(dǎo)致的位置信息丟失
自下而上的實(shí)例分割方法
思路是:首先進(jìn)行像素級(jí)別的語(yǔ)義分割,再通過(guò)聚類、度量學(xué)習(xí)等手段區(qū)分不同的實(shí)例。這種方法雖然保持了更好的低層特征(細(xì)節(jié)信息和位置信息),但也存在以下缺點(diǎn):
對(duì)密集分割的質(zhì)量要求很高,會(huì)導(dǎo)致非最優(yōu)的分割
泛化能力較差,無(wú)法應(yīng)對(duì)類別多的復(fù)雜場(chǎng)景
后處理方法繁瑣
單階段實(shí)例分割(Single Shot Instance Segmentation),這方面工作其實(shí)也是受到了單階段目標(biāo)檢測(cè)研究的影響,因此也有兩種思路,一種是受one-stage, anchor-based 檢測(cè)模型如YOLO,RetinaNet啟發(fā),代表作有YOLACT和SOLO;一種是受anchor-free檢測(cè)模型如 FCOS 啟發(fā),代表作有PolarMask和AdaptIS。
下面是對(duì)其中一些方法在COCO數(shù)據(jù)集上的指標(biāo)對(duì)比:
Method | AP | AP50 | AP75 | APs | APm | APL |
FCIS | 29.2 | 49.5 | 7.1 | 31.3 | 50.0 | |
Mask R-CNN | 37.1 | 60.0 | 39.4 | 16.9 | 39.9 | 53.5 |
YOLACT-700 | 31.2 | 50.6 | 32.8 | 12.1 | 33.3 | 47.1 |
PolarMask | 32.9 | 55.4 | 33.8 | 15.5 | 35.1 | 46.3 |
SOLO | 40.4 | 62.7 | 43.3 | 17.6 | 43.3 | 58.9 |
PointRend | 40.9 | |||||
BlendMask | 41.3 | 63.1 | 44.6 | 22.7 | 44.1 | 54.5 |
下面詳細(xì)介紹一下幾個(gè)代表性方法:
1.雙階段的 Mask R-CNN (2017.3)
Mask-RCNN通過(guò)增加不同的分支可以完成目標(biāo)分類,目標(biāo)檢測(cè),語(yǔ)義分割,實(shí)例分割,人體姿態(tài)估計(jì)等多種任務(wù)。對(duì)于實(shí)例分割來(lái)講,就是在Faster-RCNN的基礎(chǔ)上(分類+回歸分支)增加了一個(gè)分支用于語(yǔ)義分割,其抽象結(jié)構(gòu)如下圖所示:
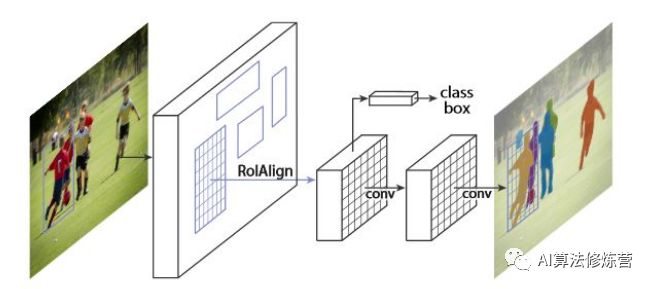
可以看到其結(jié)構(gòu)與Faster RCNN非常類似,但有3點(diǎn)主要區(qū)別:
在基礎(chǔ)網(wǎng)絡(luò)中采用了較為優(yōu)秀的ResNet-FPN結(jié)構(gòu),多層特征圖有利于多尺度物體及小物體的檢測(cè)。原始的FPN會(huì)輸出P2、P3、P4與P54個(gè)階段的特征圖,但在Mask RCNN中又增加了一個(gè)P6。將P5進(jìn)行最大值池化即可得到P6,目的是獲得更大感受野的特征,該階段僅僅用在RPN網(wǎng)絡(luò)中。
提出了RoI Align方法來(lái)替代RoI Pooling,原因是RoI Pooling的取整做法損失了一些精度,而這對(duì)于分割任務(wù)來(lái)說(shuō)較為致命。Maks RCNN提出的RoI Align取消了取整操作,而是保留所有的浮點(diǎn),然后通過(guò)雙線性插值的方法獲得多個(gè)采樣點(diǎn)的值,再將多個(gè)采樣點(diǎn)進(jìn)行最大值的池化,即可得到該點(diǎn)最終的值。
得到感興趣區(qū)域的特征后,在原來(lái)分類與回歸的基礎(chǔ)上,增加了一個(gè)Mask分支來(lái)預(yù)測(cè)每一個(gè)像素的類別。具體實(shí)現(xiàn)時(shí),采用了FCN(Fully Convolutional Network)的網(wǎng)絡(luò)結(jié)構(gòu),利用卷積與反卷積構(gòu)建端到端的網(wǎng)絡(luò),最后對(duì)每一個(gè)像素分類,實(shí)現(xiàn)了較好的分割效果。
Mask R-CNN算法的主要步驟為:
首先,將輸入圖片送入到特征提取網(wǎng)絡(luò)得到特征圖。 然后對(duì)特征圖的每一個(gè)像素位置設(shè)定固定個(gè)數(shù)的ROI(也可以叫Anchor),然后將ROI區(qū)域送入RPN網(wǎng)絡(luò)進(jìn)行二分類(前景和背景)以及坐標(biāo)回歸,以獲得精煉后的ROI區(qū)域。 對(duì)上個(gè)步驟中獲得的ROI區(qū)域執(zhí)行論文提出的ROIAlign操作,即先將原圖和feature map的pixel對(duì)應(yīng)起來(lái),然后將feature map和固定的feature對(duì)應(yīng)起來(lái)。 最后對(duì)這些ROI區(qū)域進(jìn)行多類別分類,候選框回歸和引入FCN生成Mask,完成分割任務(wù)。
總的來(lái)說(shuō),在Faster R-CNN和FPN的加持下,Mask R-CNN開啟了R-CNN結(jié)構(gòu)下多任務(wù)學(xué)習(xí)的序幕。它出現(xiàn)的時(shí)間比其他的一些實(shí)例分割方法(例如FCIS)要晚,但是依然讓proposal-based instance segmentation的方式占據(jù)了主導(dǎo)地位(盡管先檢測(cè)后分割的邏輯不是那么地自然)。
Mask R-CNN利用R-CNN得到的物體框來(lái)區(qū)分各個(gè)實(shí)例,然后針對(duì)各個(gè)物體框?qū)ζ渲械膶?shí)例進(jìn)行分割。顯而易見的問(wèn)題便是,如果框不準(zhǔn),分割結(jié)果也會(huì)不準(zhǔn)。因此對(duì)于一些邊緣精度要求高的任務(wù)而言,這不是一個(gè)較好的方案。同時(shí)由于依賴框的準(zhǔn)確性,這也容易導(dǎo)致一些非方正的物體效果比較差。
2. 單階段實(shí)例分割方法
2.1 Instance-sensitive FCN(2016.3)
該方法的思想是相對(duì)FCN在每個(gè)像素上輸出語(yǔ)義的label,其需要輸出是否在某個(gè)實(shí)例的相對(duì)位置上(以3x3的網(wǎng)格為例,即要確定像素點(diǎn)是在網(wǎng)格的哪個(gè)位置(9個(gè)位置對(duì)應(yīng)9個(gè)通道))。雖然理解上不是特別直觀,但其主要思想還是編碼了位置信息(類似方向信息)以便區(qū)分同一語(yǔ)義下的實(shí)例。
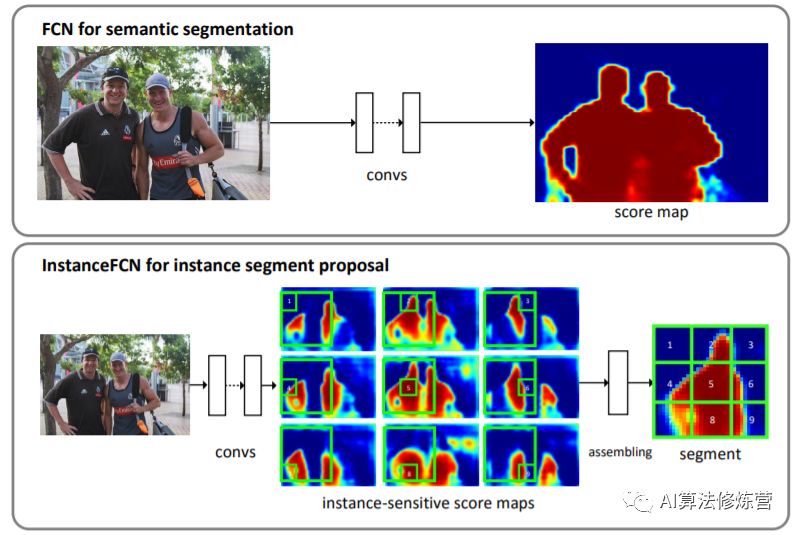
當(dāng)然在構(gòu)造groundtruth時(shí),也需要sliding window的方式把實(shí)例上各個(gè)像素分配到各個(gè)位置上去。
在推理階段,僅僅依靠sliding window去生成結(jié)果是不夠的。在相近位置上會(huì)得到相似的結(jié)果,這就需要對(duì)物體本身進(jìn)行整體的判別,以確定物體(中心)的準(zhǔn)確位置。如下instance sensitive FCN增加了物體檢測(cè)分支,通過(guò)物體的外接框以及得分,利用NMS得到最終無(wú)重復(fù)的實(shí)例分割結(jié)果。

雖然該方法效果在當(dāng)時(shí)并不突出,但請(qǐng)先記住這樣的思想,后續(xù)SOLO會(huì)進(jìn)一步升華。下面要講到的R-FCN同樣利用了單個(gè)像素編碼(附帶)相對(duì)位置信息的思路,除了類別信息外,該像素還需要判斷自己在物體區(qū)域的相對(duì)位置,相對(duì)位置通過(guò)固定的通道得以表征。
2.2 FCIS(2017.4)
FCN 最終輸出的是類別的概率圖,只有類別輸出,沒(méi)有單個(gè)對(duì)象輸出,InstanceFCN輸出3*3的位置信息圖, 只有單個(gè)對(duì)象輸出,沒(méi)有類別信息,需要單獨(dú)的downstream網(wǎng)絡(luò)完成類別信息。FCIS通過(guò)計(jì)算position-sensitive inside/outside score maps,同時(shí)輸出 instance mask 和類別信息。
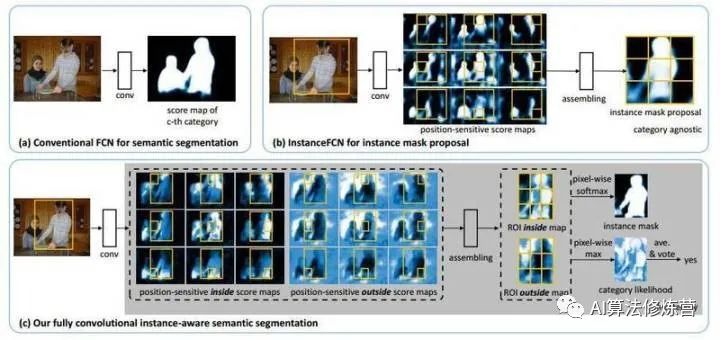
InstanceFCN提出了positive-sensitive score map,每個(gè)score表示一個(gè)像素在某個(gè)相對(duì)位置上屬于某個(gè)物體實(shí)例的似然得分。所以FCIS也采用position-sensitive score maps,只不過(guò)在物體實(shí)例中區(qū)分inside/outside,目的是想引入一點(diǎn)context信息。
作者認(rèn)為以往的SDS、Hypercolumn、CFM等算法,具有相似的結(jié)構(gòu):兩個(gè)子網(wǎng)絡(luò)分別用于對(duì)象分割和檢測(cè)子任務(wù),且兩個(gè)網(wǎng)絡(luò)的結(jié)構(gòu)、參數(shù)、執(zhí)行順序隨機(jī)。作者認(rèn)為分離的網(wǎng)絡(luò)沒(méi)有真正挖掘到兩個(gè)認(rèn)為的聯(lián)系,提出共同的 “position-sensitive score map” ,同時(shí)用于object segmentation and detection子任務(wù)。
除了加入背景部分的通道外,F(xiàn)CIS還基于ROI作了類別檢測(cè),而不是再引入另外一個(gè)分支作這項(xiàng)任務(wù)。
2.3 YOLCAT(2019.4)
YOLACT將掩模分支添加到現(xiàn)有的一階段(one-stage)目標(biāo)檢測(cè)模型,其方式與Mask R-CNN對(duì) Faster-CNN 操作相同,但沒(méi)有明確的定位步驟。
YOLACT將實(shí)例分割任務(wù)拆分成兩個(gè)并行的子任務(wù):(1)通過(guò)一個(gè)Protonet網(wǎng)絡(luò), 為每張圖片生成 k 個(gè) 原型mask;(2)對(duì)每個(gè)實(shí)例,預(yù)測(cè)k個(gè)的線性組合系數(shù)(Mask Coefficients)。最后通過(guò)線性組合,生成實(shí)例mask,在此過(guò)程中,網(wǎng)絡(luò)學(xué)會(huì)了如何定位不同位置、顏色和語(yǔ)義實(shí)例的mask。
YOLACT將問(wèn)題分解為兩個(gè)并行的部分,利用 fc層(擅長(zhǎng)產(chǎn)生語(yǔ)義向量)和 conv層(擅長(zhǎng)產(chǎn)生空間相干掩模)來(lái)分別產(chǎn)生“掩模系數(shù)”和“原型掩模” 。然后,因?yàn)樵秃脱谀O禂?shù)可以獨(dú)立地計(jì)算,所以 backbone 檢測(cè)器的計(jì)算開銷主要來(lái)自合成(assembly)步驟,其可以實(shí)現(xiàn)為單個(gè)矩陣乘法。通過(guò)這種方式,我們可以在特征空間中保持空間一致性,同時(shí)仍然是一階段和快速的。
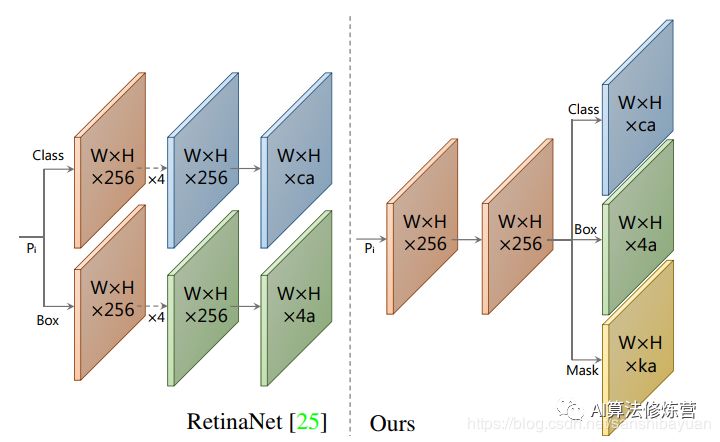
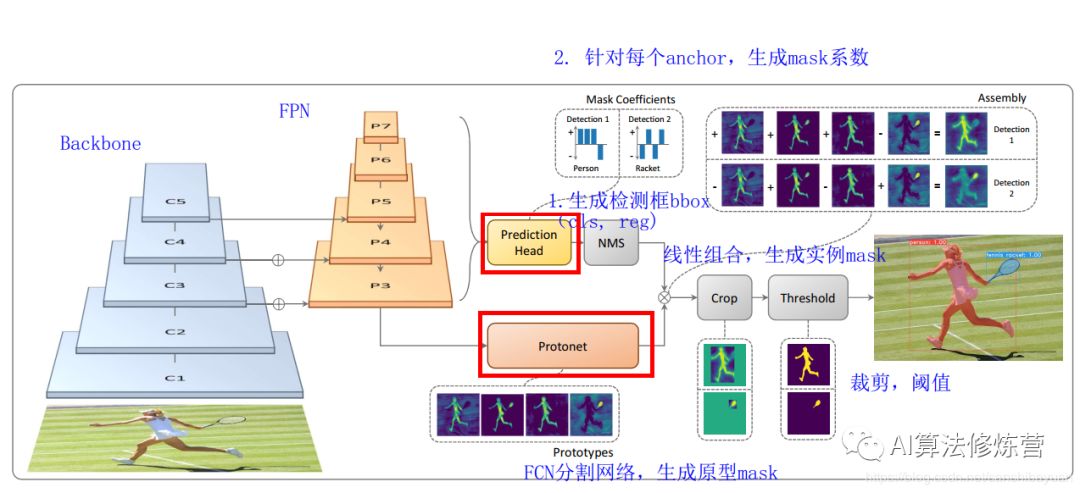
Backbone:Resnet 101+FPN,與RetinaNet相同;Protonet:接在FPN輸出的后面,是一個(gè)FCN網(wǎng)絡(luò),預(yù)測(cè)得到針對(duì)原圖的原型mask;Prediction Head:相比RetinaNet的Head,多了一個(gè)Mask Cofficient分支,預(yù)測(cè)Mask系數(shù),因此輸出是4*c+k。
可以看到head上增加了一支mask系數(shù)分支用于將prototypes進(jìn)行組合得到mask的結(jié)果。當(dāng)然按NMS的位置看,其同樣需要有bbox的準(zhǔn)確預(yù)測(cè)才行,并且該流程里不太適合用soft NMS進(jìn)行替代。需要注意的是,在訓(xùn)練過(guò)程中,其用groundtruth bbox對(duì)組合后的全圖分割結(jié)果進(jìn)行截取,再與groundtruth mask計(jì)算損失。這同樣需要bbox結(jié)果在前作為前提,以緩解前后景的像素不均衡情況。
至于后續(xù)的YOLCAT++,則主要是加入了mask rescoring的概念和DCN結(jié)構(gòu),進(jìn)一步提升精度。(1)參考Mask Scoring RCNN,添加fast mask re-scoring分支,更好地評(píng)價(jià)實(shí)例mask的好壞;(2)Backbone網(wǎng)絡(luò)中引入可變形卷積DCN;(3)優(yōu)化了Prediction Head中的anchor設(shè)計(jì)。
2.4 PolarMask(2019.10)
相比RetinaNet,FCOS將基于anchor的回歸變成了中心點(diǎn)估計(jì)與上下左右四個(gè)邊界距離的回歸,而PolarMask則是進(jìn)一步細(xì)化了邊界的描述,使得其能夠適應(yīng)mask的問(wèn)題。PolarMask最重要的特點(diǎn)是:(1) anchor free and bbox free,不需要出檢測(cè)框;(2) fully convolutional network, 相比FCOS把4根射線散發(fā)到36根射線,將instance segmentation和object detection用同一種建模方式來(lái)表達(dá)。
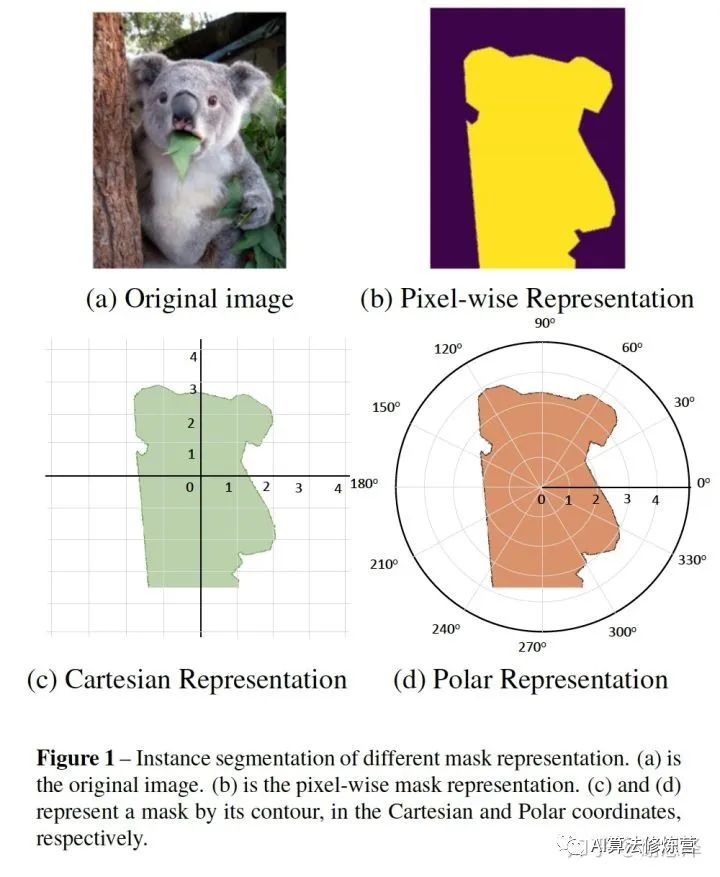
兩種實(shí)例分割的建模方式:
1 像素級(jí)建模 類似于圖b,在檢測(cè)框中對(duì)每個(gè)pixel分類
2 輪廓建模 類似于圖c和圖d,其中,圖c是基于直角坐標(biāo)系建模輪廓,圖d是基于極坐標(biāo)系建模輪廓
PolarMask 基于極坐標(biāo)系建模輪廓,把實(shí)例分割問(wèn)題轉(zhuǎn)化為實(shí)例中心點(diǎn)分類(instance center classification)問(wèn)題和密集距離回歸(dense distance regression)問(wèn)題。同時(shí),我們還提出了兩個(gè)有效的方法,用來(lái)優(yōu)化high-quality正樣本采樣和dense distance regression的損失函數(shù)優(yōu)化,分別是Polar CenterNess和 Polar IoU Loss。沒(méi)有使用任何trick(多尺度訓(xùn)練,延長(zhǎng)訓(xùn)練時(shí)間等),PolarMask 在ResNext 101的配置下 在coco test-dev上取得了32.9的mAP。 這是首次,證明了更復(fù)雜的實(shí)例分割問(wèn)題,可以在網(wǎng)絡(luò)設(shè)計(jì)和計(jì)算復(fù)雜度上,和anchor free物體檢測(cè)一樣簡(jiǎn)單。
網(wǎng)絡(luò)結(jié)構(gòu)
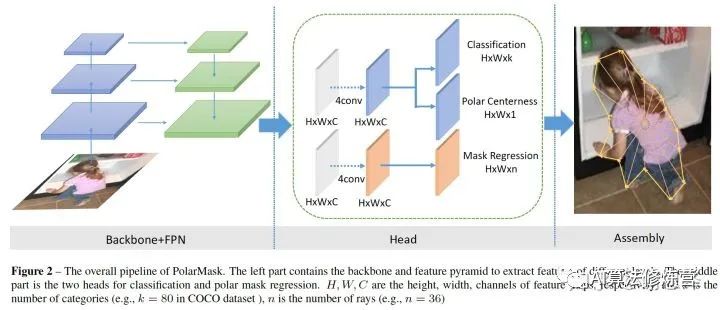
整個(gè)網(wǎng)絡(luò)和FCOS一樣簡(jiǎn)單,首先是標(biāo)準(zhǔn)的backbone + fpn模型,其次是head部分,我們把fcos的bbox分支替換為mask分支,僅僅是把channel=4替換為channel=n, 這里n=36,相當(dāng)于36根射線的長(zhǎng)度。同時(shí)我們提出了一種新的Polar Centerness 用來(lái)替換FCOS的bbox centerness。可以看到,在網(wǎng)絡(luò)復(fù)雜度上,PolarMask和FCOS并無(wú)明顯差別。
建模方式
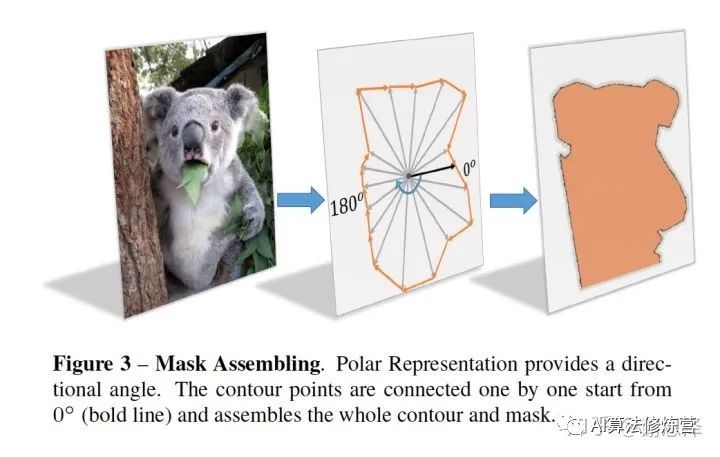
首先,輸入一張?jiān)瓐D,經(jīng)過(guò)網(wǎng)絡(luò)可以得到中心點(diǎn)的位置和n(n=36 is best in our setting)根射線的距離,其次,根據(jù)角度和長(zhǎng)度計(jì)算出輪廓上的這些點(diǎn)的坐標(biāo),從0°開始連接這些點(diǎn),最后把聯(lián)通區(qū)域內(nèi)的區(qū)域當(dāng)做實(shí)例分割的結(jié)果。
實(shí)驗(yàn)結(jié)果
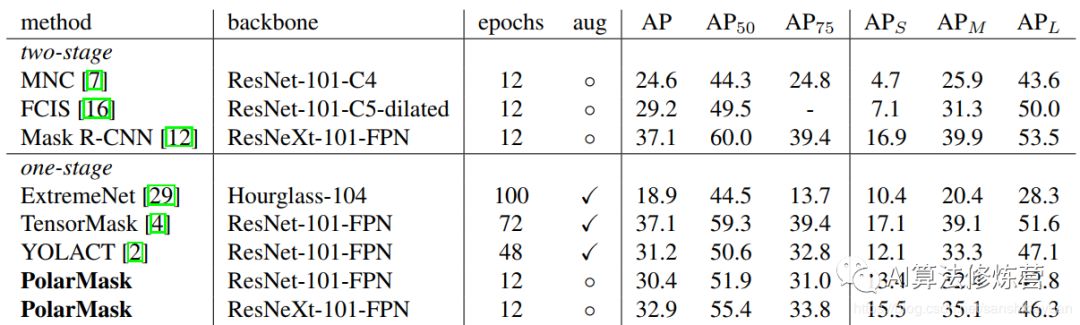
從實(shí)驗(yàn)結(jié)果可以看到,PolarMask的精度并不是很高,而且速度上也沒(méi)有優(yōu)勢(shì),但是它的思路是非常巧妙的,對(duì)后面的研究有著很大的啟發(fā)意義。具體細(xì)節(jié)可參考論文原文。
2.5 SOLO(2019.12)
和FCIS的類似,單個(gè)像素不是單純輸出類別,而是帶有位置信息的類別,同時(shí)考慮到尺度的問(wèn)題,借助網(wǎng)絡(luò)結(jié)構(gòu)來(lái)解決。
要理解SOLO的思想,重點(diǎn)就是要理解SOLO提出的實(shí)例類別(Instance Category)的概念。作者指出,實(shí)例類別就是量化后的物體中心位置(location)和物體的尺寸(size)。下面就解釋一下這兩個(gè)部分。
位置(location)
SOLO將一張圖片劃分S×S的網(wǎng)格,這就有了S*S個(gè)位置。不同于TensorMask和DeepMask將mask放在了特征圖的channel維度上,SOLO參照語(yǔ)義分割,將定義的物體中心位置的類別放在了channel維度上,這樣就保留了幾何結(jié)構(gòu)上的信息。
本質(zhì)上來(lái)說(shuō),一個(gè)實(shí)例類別可以去近似一個(gè)實(shí)例的中心的位置。因此,通過(guò)將每個(gè)像素分類到對(duì)應(yīng)的實(shí)例類別,就相當(dāng)于逐像素地回歸出物體的中心、這就將一個(gè)位置預(yù)測(cè)的問(wèn)題從回歸的問(wèn)題轉(zhuǎn)化成了分類的問(wèn)題。這么做的意義是,分類問(wèn)題能夠更加直觀和簡(jiǎn)單地用固定的channel數(shù)、同時(shí)不依賴后處理方法(如分組和學(xué)習(xí)像素嵌入embedding)對(duì)數(shù)量不定的實(shí)例進(jìn)行建模。
尺寸(size)
對(duì)于尺寸的處理,SOLO使用了FPN來(lái)將不同尺寸的物體分配到不同層級(jí)的特征圖上,依次作為物體的尺寸類別。這樣,所有的實(shí)例都被分別開來(lái),就可以去使用實(shí)例類別去分類物體了。
網(wǎng)絡(luò)實(shí)現(xiàn)
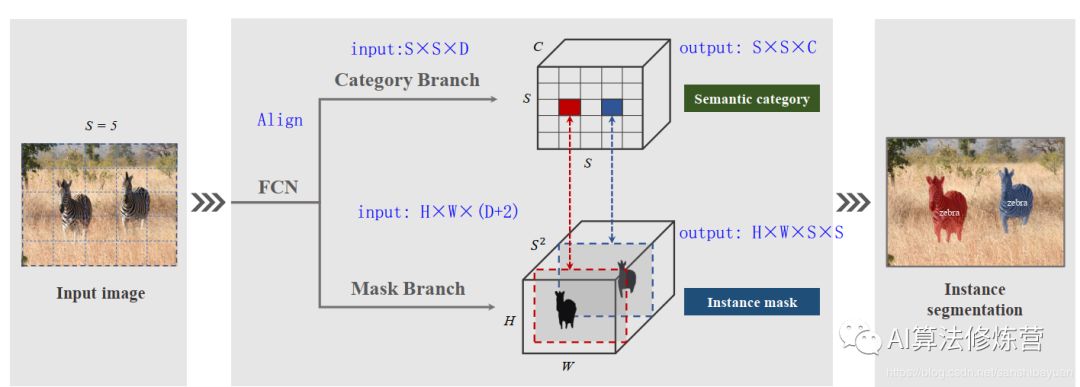
SOLO將圖片劃分成S×S的網(wǎng)格,如果物體的中心(質(zhì)心)落在了某個(gè)網(wǎng)格中,那么該網(wǎng)格就有了兩個(gè)任務(wù):(1)負(fù)責(zé)預(yù)測(cè)該物體語(yǔ)義類別(2)負(fù)責(zé)預(yù)測(cè)該物體的instance mask。這就對(duì)應(yīng)了網(wǎng)絡(luò)的兩個(gè)分支Category Branch和Mask Branch。同時(shí),SOLO在骨干網(wǎng)絡(luò)后面使用了FPN,用來(lái)應(yīng)對(duì)尺寸。FPN的每一層后都接上述兩個(gè)并行的分支,進(jìn)行類別和位置的預(yù)測(cè),每個(gè)分支的網(wǎng)格數(shù)目也相應(yīng)不同,小的實(shí)例對(duì)應(yīng)更多的的網(wǎng)格。
Category Branch:Category Branch負(fù)責(zé)預(yù)測(cè)物體的語(yǔ)義類別,每個(gè)網(wǎng)格預(yù)測(cè)類別S×S×C,這部分跟YOLO是類似的。輸入為Align后的S×S×C的網(wǎng)格圖像,輸出為S×S×C的類別。這個(gè)分支使用的損失函數(shù)是focal loss。
Mask Branch:預(yù)測(cè)instance mask的一個(gè)直觀方法是類似語(yǔ)義分割使用FCN,但FCN是具有空間不變性(spatiallly invariant)的,而我們這邊需要位置上的信息。因此,作者使用了CoordConv,將像素橫縱坐標(biāo)x,y(歸一化到[-1,1])與輸入特征做了concat再輸入網(wǎng)絡(luò)中。這樣輸入的維度就是 H*W*(D+2)了。
實(shí)驗(yàn)結(jié)果
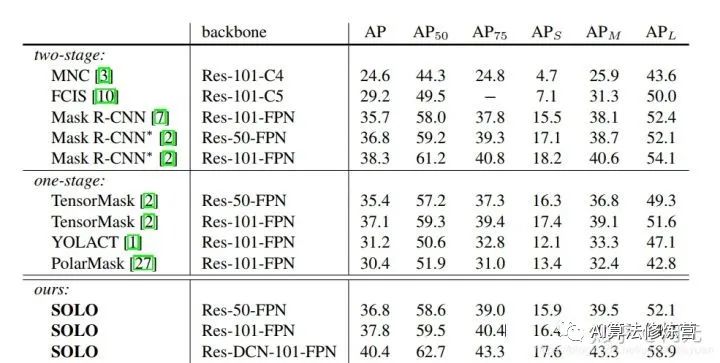
可以看到,SOLO的精度已經(jīng)超越了Mask R-CNN,相較思路類似的PolarMask也有較大的優(yōu)勢(shì)。
2.6 RDSNet & PointRend(2019.12)
RDSNet方法的出發(fā)點(diǎn)是檢測(cè)阻礙不應(yīng)該成為分割效果的阻礙,兩種應(yīng)該循環(huán)相互促進(jìn)。有可能存在的情況是分割本身是比較準(zhǔn)確的,但是因?yàn)槎ㄎ徊粶?zhǔn),導(dǎo)致分割結(jié)果也比較差;這時(shí)候如果能提前知道分割的結(jié)果,那么檢測(cè)的結(jié)果也會(huì)更好些。
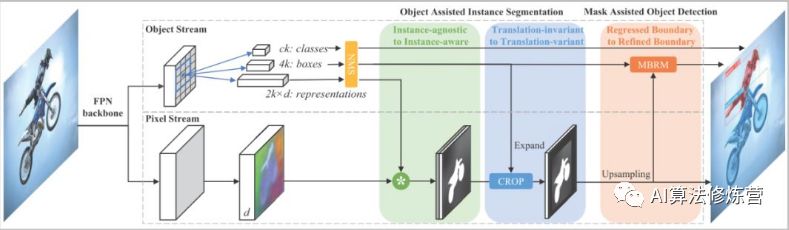
這里就有用到YOLCAT的方式,去獲得提取獲取分割結(jié)果。當(dāng)然這里從embedding的角度出發(fā),還結(jié)合了前后景的處理(實(shí)驗(yàn)中說(shuō)明前后景correlation比單前景l(fā)inear combination要好)。得到bbox預(yù)測(cè)結(jié)果后是需要進(jìn)行NMS,以及expand操作的,以確保盡可能多的有效區(qū)域被選進(jìn)來(lái)(訓(xùn)練時(shí)1.5,測(cè)試時(shí)1.2)。之后再通過(guò)Mask-based Boundary Refinement模塊對(duì)物體的邊框進(jìn)行調(diào)整。為了使該過(guò)程可導(dǎo),作者還設(shè)計(jì)了貝葉斯分布估計(jì)的方式,不太懂。
PointRend借鑒了Render的思想,在尺度方式變化時(shí)由于采樣的方式(不是連續(xù)坐標(biāo)的設(shè)定嗎),使得鋸齒現(xiàn)象不會(huì)很明顯。因此PointRend是利用一種非均勻采樣的方式來(lái)確定在分辨率提高的情況下,如何確定邊界上的點(diǎn),并對(duì)這些點(diǎn)歸屬進(jìn)行判別。本質(zhì)上其實(shí)是一個(gè)新型上采樣方法,針對(duì)物體邊緣的圖像分割進(jìn)行優(yōu)化,使其在難以分割的物體邊緣部分有更好的表現(xiàn)。
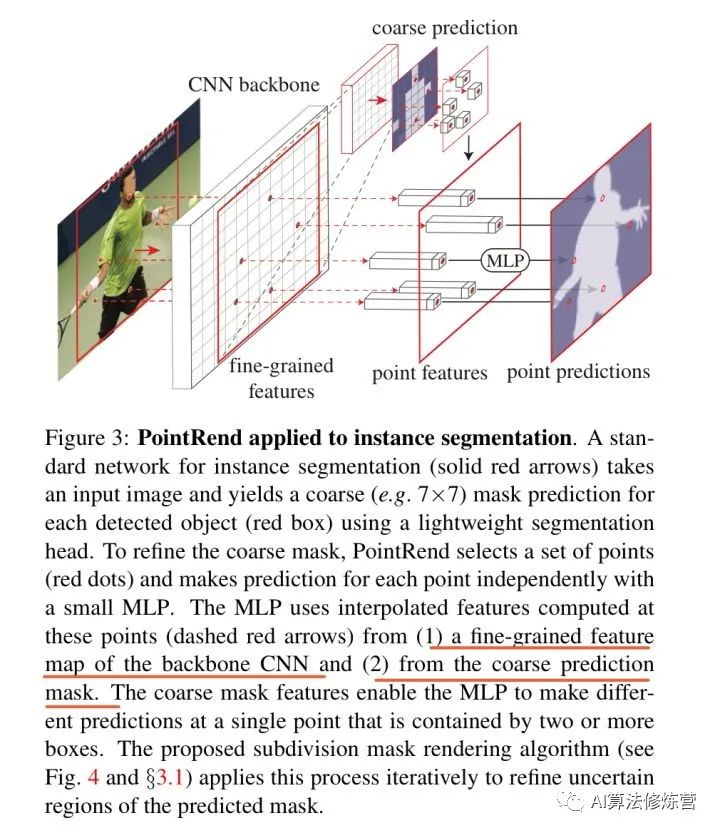
PointRend 方法要點(diǎn)總結(jié)來(lái)說(shuō)是一個(gè)迭代上采樣的過(guò)程:
while 輸出的分辨率 < 圖片分辨率:
對(duì)輸出結(jié)果進(jìn)行2倍雙線性插值上采樣得到 coarse prediction_i。
挑選出 N 個(gè)“難點(diǎn)”,即結(jié)果很有可能和周圍點(diǎn)不一樣的點(diǎn)(例如物體邊緣)。
對(duì)于每個(gè)難點(diǎn),獲取其“表征向量”,“表征向量”由兩個(gè)部分組成,其一是低層特征(fine-grained features),通過(guò)使用點(diǎn)的坐標(biāo),在低層的特征圖上進(jìn)行雙線性插值獲得(類似 RoI Align),其二是高層特征(coarse prediction),由步驟 1 獲得。
使用 MLP 對(duì)“表征向量”計(jì)算得到新的預(yù)測(cè),更新 coarse prediction_i 得到 coarse prediction_i+1。這個(gè) MLP 其實(shí)可以看做一個(gè)只對(duì)“難點(diǎn)”的“表征向量”進(jìn)行運(yùn)算的由多個(gè) conv1x1 組成的小網(wǎng)絡(luò)。
2.7 BlendMask(2020.1)
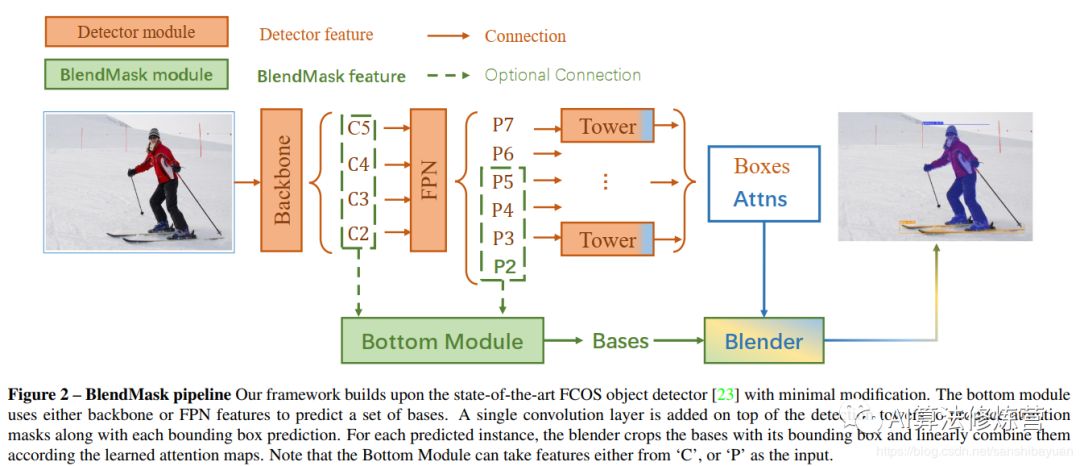
BlendMask是一階段的密集實(shí)例分割方法,結(jié)合了Top-down和Bottom-up的方法的思路。它通過(guò)在anchor-free檢測(cè)模型FCOS的基礎(chǔ)上增加了Bottom Module提取low-level的細(xì)節(jié)特征,并在instance-level上預(yù)測(cè)一個(gè)attention;借鑒FCIS和YOLACT的融合方法,提出了Blender模塊來(lái)更好地融合這兩種特征。最終,BlendMask在COCO上的精度(41.3AP)與速度(BlendMask-RT 34.2mAP, 25FPS on 1080ti)都超越了Mask R-CNN。
detector module直接用的FCOS,BlendMask模塊則由三部分組成:bottom module用來(lái)對(duì)底層特征進(jìn)行處理,生成的score map稱為Base;top layer串接在檢測(cè)器的box head上,生成Base對(duì)應(yīng)的top level attention;最后是blender來(lái)對(duì)Base和attention進(jìn)行融合。
BlendMask 的優(yōu)勢(shì):
計(jì)算量小:使用一階段檢測(cè)器FCOS,相比Mask R-CNN使用的RPN,省下了對(duì)positon-sensitive feature map及mask feature的計(jì)算,
還是計(jì)算量小:提出attention guided blender模塊來(lái)計(jì)算全局特征(global map representation),相比FCN和FCIS中使用的較復(fù)雜的hard alignment在相同分辨率的條件下,減少了十倍的計(jì)算量;
mask質(zhì)量更高:BlendMask屬于密集像素預(yù)測(cè)的方法,輸出的分辨率不會(huì)受到 top-level 采樣的限制。在Mask R-CNN中,如果要得到更準(zhǔn)確的mask特征,就必須增加RoIPooler的分辨率,這樣變回成倍增加head的計(jì)算時(shí)間和head的網(wǎng)絡(luò)深度;
推理時(shí)間穩(wěn)定:Mask R-CNN的推理時(shí)間隨著檢測(cè)的bbox數(shù)量增多而增多,BlendMask的推理速度更快且增加的時(shí)間可以忽略不計(jì)
Flexible:可以加到其他檢測(cè)算法里面
總結(jié)
綜上所述,我們大致可以看出兩個(gè)趨勢(shì):一個(gè)是YOLCAT,RDSNet,BlendMask(RetinaNet, FCOS,PolarMask發(fā)展而來(lái))單階段基于硬編碼(embedding)的實(shí)例分割;另一個(gè)是SOLO(FCIS)區(qū)分位置信息的方式。
兩者沒(méi)有特別大的區(qū)別,特別當(dāng)embedding的通道數(shù)等于位置數(shù)目時(shí)。剩下的PointRend其實(shí)可以引出一個(gè)計(jì)算資源分配的問(wèn)題,如何在有限次計(jì)算的情況下提升分割邊緣的準(zhǔn)確性。以上這些還是針對(duì)檢測(cè)目的的,所以分割精度上有時(shí)在意,有時(shí)也不在意。在精確分割方面仍然有值得探索的地方,除了目前很火的attention機(jī)制,其實(shí)我覺(jué)得依然得回頭去關(guān)注下標(biāo)注不那么精細(xì)的情況下如何去提升邊緣的分割精度(當(dāng)然這又可能是個(gè)ill問(wèn)題,或者是個(gè)外插問(wèn)題,不過(guò)從guided filter的角度看至少還有些圖像結(jié)構(gòu)信息可以作為先驗(yàn)知識(shí)利用起來(lái))
參考:
2.https://blog.csdn.net/sanshibayuan/article/details/104011910
3.https://zhuanlan.zhihu.com/p/102231853
4.https://zhuanlan.zhihu.com/p/84890413
5.https://zhuanlan.zhihu.com/p/98351269
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~