
【深度學習】從R-CNN到Mask R-CNN的思維躍遷
01
R-CNN

在那個時間點,基于深度學習的卷積神經(jīng)網(wǎng)絡開始屠榜ImageNet,R-CNN的思路非常直接,既然在圖像分類方向上卷積神經(jīng)網(wǎng)絡效果這么好,那么如果把一張圖的所有目標摳出來,一個一個送入CNN,不就可以將CNN和目標檢測任務結合起來使用了,于是R-CNN就誕生了。
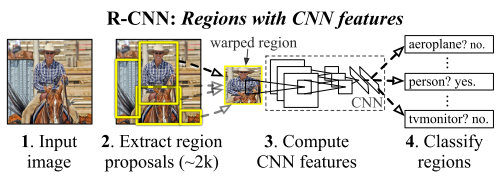
訓練流程:
1.先在ImageNet上對CNN進行supervised pre-training。
2.然后在PASCAL VOC 2012數(shù)據(jù)集上進行domain-specific fine-tuning,即把ImageNet的1000分類層替換成21分類層(20個目標類加上1個背景類,因為region proposal會多產(chǎn)生一個背景類)進行fine-tuning。
3.然后將21分類層替換成每個類別一個線性SVM分類器(即總共21個SVM),然后進行分類訓練。
4.最后加上邊界框回歸分支,進行定位訓練。
推理流程:
1.先對輸入圖片使用selective search抽取2000個region proposals。
2.然后將region proposals一個一個送入CNN進行計算。
3.最后使用SVM分類器和邊界框回歸分支得到最終的類別和定位。
(ps: 由于后續(xù)的Faster R-CNN沒有再沿用selective search和SVM,這里就不細講了)
貢獻
另外R-CNN還有一個容易被忽略的重要貢獻,R-CNN之前的方法是先unsupervised pre-training,然后fine tuning,而R-CNN是第一個提出先supervised pre-training,然后fine tuning用于下游任務(說句題外話,現(xiàn)在的self-supervised是要重新使用usupervised pre-training的方式啊)。
最終,R-CNN在PASCAL VOC 2012數(shù)據(jù)集上比起之前的方法提升了30%。R-CNN奠定了目標檢測的總體框架,開辟目標檢測領域region proposal+CNN范式的新時代。
同時R-CNN埋下了兩個伏筆
伏筆一
將R-CNN和OverFeat進行比較,提到OverFeat比R-CNN速度快9倍,主要是因為OverFeat的region proposals是作用在CNN后的feature map上的,CNN參數(shù)共享大大提高region proposals的并行性。
伏筆二
R-CNN中提到,SVM可能不是必須的,可能可以精簡訓練流程。
02
Fast R-CNN

Fast R-CNN針對R-CNN的兩個伏筆進行了改進,通過CNN并行處理所有region proposal,并且同時訓練分類和定位。
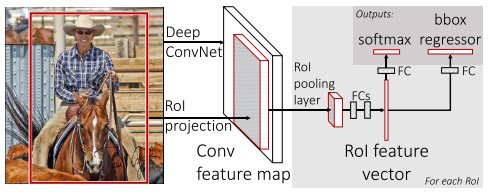
訓練流程:
1.先在ImageNet上進行pre-training。
2.然后在PASCAL VOC數(shù)據(jù)集上進行分類和定位多任務的fine-tuning。
在訓練流程上,相對于R-CNN直接將2,3,4步驟合并成一個步驟完成,大大降低了訓練的復雜程度。
推理流程:
1.先將整張圖片送入CNN得到feature map。
2.然后對feature map進行selective search,得到region of interest(RoI)。
3.然后將每個RoI送入RoI pooling轉化成相同維度的向量。
4.最后通過兩個獨立的FC,預測出類別和位置。
在推理流程上,相比于R-CNN,送入CNN的是整張圖片,selective search是在更小分辨率的feature map上進行的,大大減少了計算量。
下面詳細講一下Fast R-CNN的兩個部分:RoI pooling和Multi-task loss。
RoI pooling
將不同尺寸大小的RoI進行維度上的對齊,可以統(tǒng)一進行multi-task的訓練和推理。
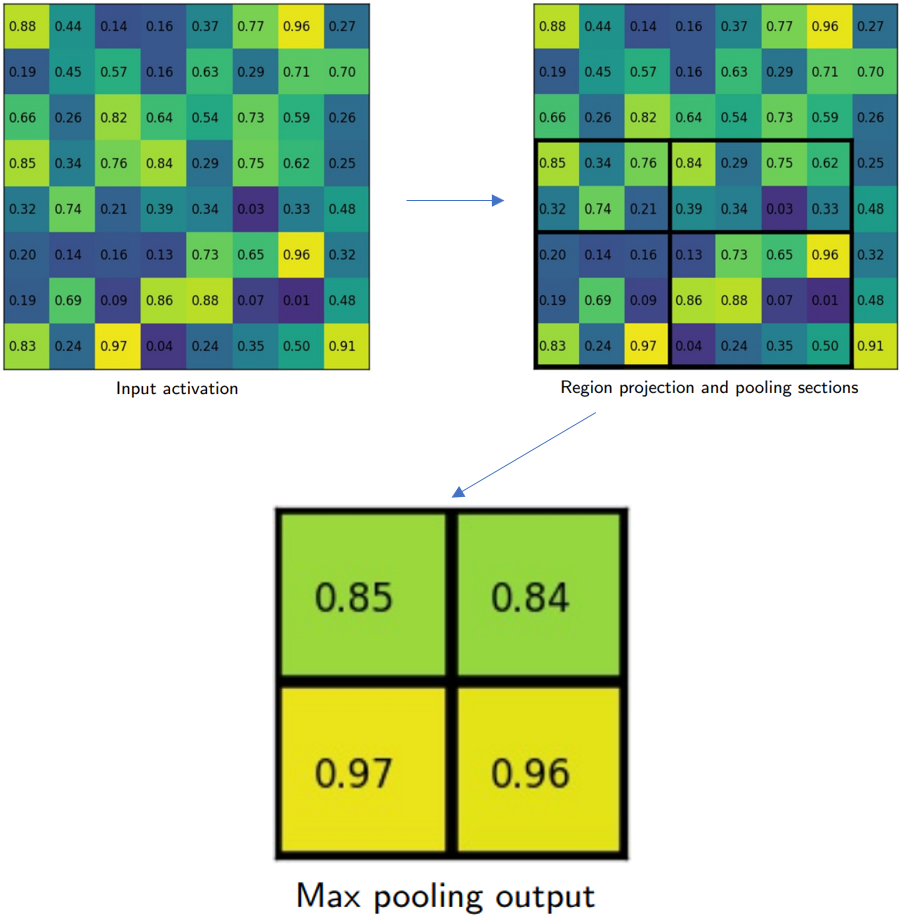
RoI pooling如圖所示。以RoI pooling后尺寸變成2x2為例,右上圖的黑色矩形框對應一個RoI(h,w=5,7),RoI需要分成4個bin,由于RoI pooling切分bin的時候需要對劃分尺寸進行量化(h//2=2,w//2=3),所有第一個bin包含2x3個像素,第二個bin包含2x4個像素,第三個bin包含3x3個像素,第四個bin包含3x4個像素。最后對每個bin中的像素進行max pooling得到最終的2x2 feature map。
Multi-task loss
Fast R-CNN有兩個輸出層。第一個輸出是每個RoI的離散概率分布,總共K+1個類別(其中一個是背景類),概率表示為
假設gt的類別為u,gt的邊界框為v。我們用多任務loss來聯(lián)合訓練分類和邊界框回歸:
其中
其中邊界框回歸loss為:
貢獻
Fast R-CNN極大的簡化了R-CNN的訓練流程,可以端到端的訓練檢測器,為后續(xù)Faster R-CNN的出現(xiàn)奠定了基礎。
Fast R-CNN同樣埋下了伏筆
伏筆
Fast R-CNN指出region proposal部分還是計算量太大了,導致速度不能進一步提高。
03
Faster R-CNN

雖然Fast R-CNN極大加快了檢測器的推理速度,但是region proposal部分仍然是檢測器進一步提升速度的瓶頸。于是,F(xiàn)aster R-CNN針對Fast R-CNN埋下的伏筆,設計了RPN和Anchor兩個新組件,來改善region proposal提取RoI的質量,同時提升檢測器的精度和速度。
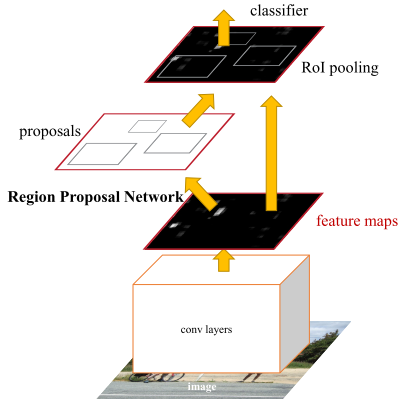
訓練流程:
1.通過ImageNet pre-trained model初始化CNN,然后端到端fine-tuning RPN部分。
2.固定住RPN,然后通過RPN產(chǎn)生的region proposal來訓練Fast R-CNN部分。
3.固定住CNN和Fast R-CNN來fine-tuning RPN網(wǎng)絡。
4.固定住CNN和RPN來fine-tuning Fast R-CNN網(wǎng)絡。
相當于是對RPN和Fast R-CNN兩個部分交替進行訓練,因為使用了RPN,導致訓練難度增加,比起Fast R-CNN訓練過程更加復雜了(后續(xù)開源代碼對Faster R-CNN訓練流程進行了簡化,可以同時訓練RPN和Fast R-CNN)。
推理流程:
1.先將圖片輸入CNN得到featmap。
2.然后通過RPN產(chǎn)生RoI。
3.然后將每個RoI送入RoI pooling轉化成相同維度的向量。
4.最后通過兩個獨立的FC,預測出類別和位置。
下面詳細講一下Faster R-CNN的三個部分:Region Proposal Networks、Anchors和Loss Function。
Region Proposal Networks
Faster RCNN則拋棄了傳統(tǒng)的滑動窗口和SS方法,直接使用RPN生成檢測框,這也是Faster R-CNN的巨大優(yōu)勢,能極大提升檢測框的生成速度。
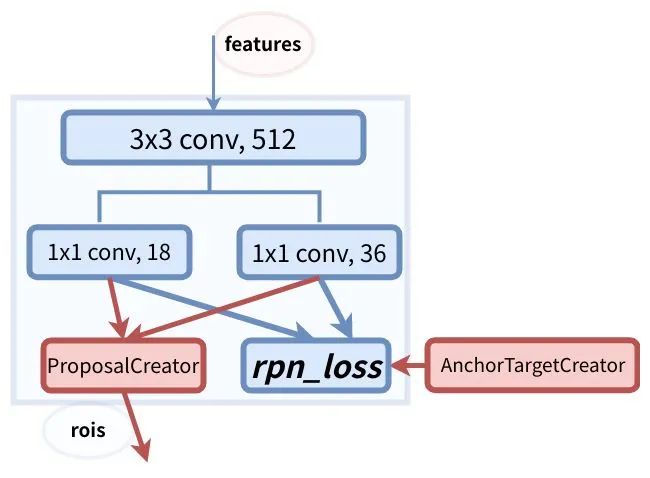
上圖是RPN網(wǎng)絡的具體結構。RPN網(wǎng)絡分成2個分支,一個分支通過softmax分類得到所有anchors的分類分數(shù),另一個分支用于計算所有anchors的邊界框回歸偏移量,以獲得精確的proposal。最后在ProposalCreator通過分類分數(shù)和偏移量來得到合適的proposals。
Anchors
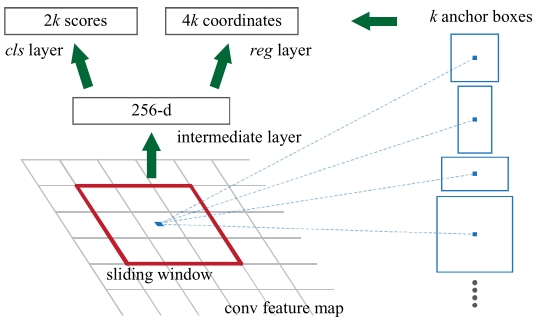
Faster R-CNN中在feature map的每個位置都設置了三種尺度三種長寬比的anchor,總共9種。
anchor數(shù)量對RPN輸出維度產(chǎn)生的變化如圖所示
原文中使用的CNN網(wǎng)絡是ZF,CNN最后的conv5層num_output=256,對應生成256張?zhí)卣鲌D,所以相當于feature map每個點都是256-dimensions。
在conv5之后,做了3x3卷積保持num_output=256,相當于每個點又融合了周圍3x3的空間信息。
在conv5 feature map的每個位置上設置k個anchor(默認k=9),而每個anhcor要分positive和negative,所以每個點由256d feature轉化為cls=2k scores;而每個anchor都有(x, y, w, h)對應4個偏移量,所以reg=4k coordinates。
訓練時在合適的anchors中隨機選取128個postive anchors+128個negative anchors進行訓練。
Loss Function
Faster R-CNN訓練時有4個損失函數(shù),函數(shù)形式跟Fast R-CNN的損失函數(shù)相似:
1.RPN 分類損失:anchor是否為前景(二分類)
2.RPN位置回歸損失:anchor位置微調
3.RoI 分類損失:RoI所屬類別(21分類,多了一個類作為背景)
4.RoI位置回歸損失:繼續(xù)對RoI位置微調
四個損失相加作為最后的損失,反向傳播,更新參數(shù)。
貢獻
Faster R-CNN設計的RPN和anchor可以極大提升region proposal質量,同時極大提升了檢測器的精度和速度。Faster R-CNN是R-CNN系列的集大成者,能夠用近乎實時的速度檢測物體,讓目標檢測在更多場景應用成為可能。
04
Mask R-CNN

Faster R-CNN的RoI pooling是粗粒度的空間量化特征提取,不能做輸入和輸出pixel-to-pixel的特征對齊,并且不能直接應用于實例分割。于是Mask R-CNN提出用RoIAlign來替代RoI pooling,得到pixel-to-pixel的特征對齊,并且在Faster R-CNN框架的基礎上簡單的增加了一個mask分支就能實現(xiàn)實例分割。
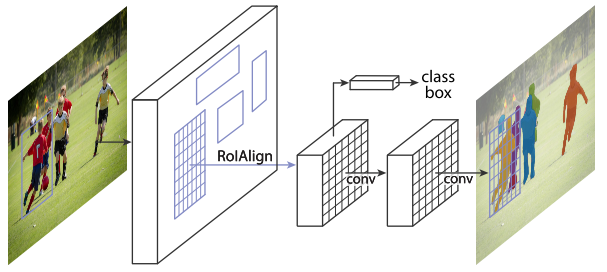
訓練流程:
1.先在ImageNet上進行pre-training。
2.然后在COCO數(shù)據(jù)集上進行分類、定位和分割三個任務fine-tuning。
推理流程:
1.先將圖片輸入CNN得到featmap。
2.然后通過RPN產(chǎn)生RoI。
3.然后將每個RoI送入RoI pooling轉化成相同維度的向量。
4.最后通過兩個獨立的FC,預測出類別和位置,同時通過mask分支預測出分類分數(shù)前N個RoI的分割mask。
下面詳細講一下Mask R-CNN的三個部分:Region Proposal Networks、Anchors和Loss Function。
Network Architecture
Mask R-CNN把抽取特征的CNN部分定義為backbone,把分類、回歸和分割部分定義為head。Mask R-CNN把ResNet第4個stage出來的feature定義為ResNet C4,同時Mask R-CNN還探索了更加有效的FPN網(wǎng)絡。
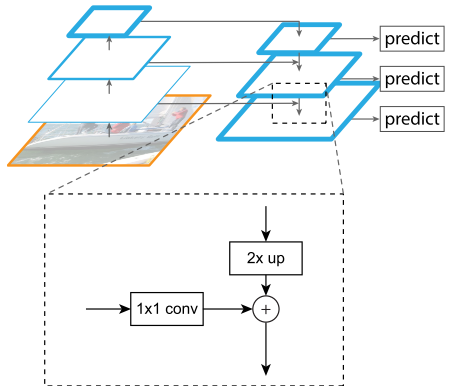
FPN結構如圖所示。FPN采用自頂向下結構,通過橫向連接構建網(wǎng)絡內部特征金字塔。FPN可以根據(jù)anchor的尺度大小分配特征層,從不同特征層提取RoI特征。
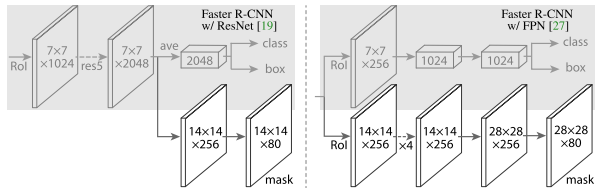
head結構如圖所示。ResNet C4的backbone后面增加了一個stage5,然后進行分類、回歸和分割。FPN的backbone將FPN結構收集到的RoI直接送入兩個分支,然后進行分類、回歸和分割。
其中分割分支,通過deconv來得到更大分辨率的feature map,從而得到更精確的mask預測結果,分割分支的最終feature map通道數(shù)等于類別數(shù),每個通道預測一種類別的mask。最終多任務的損失函數(shù)為
RoIAlign
分割需要pixel-to-pixel對齊的RoI特征,這促使Mask R-CNN設計了RoIAlign來替代RoI pooling。
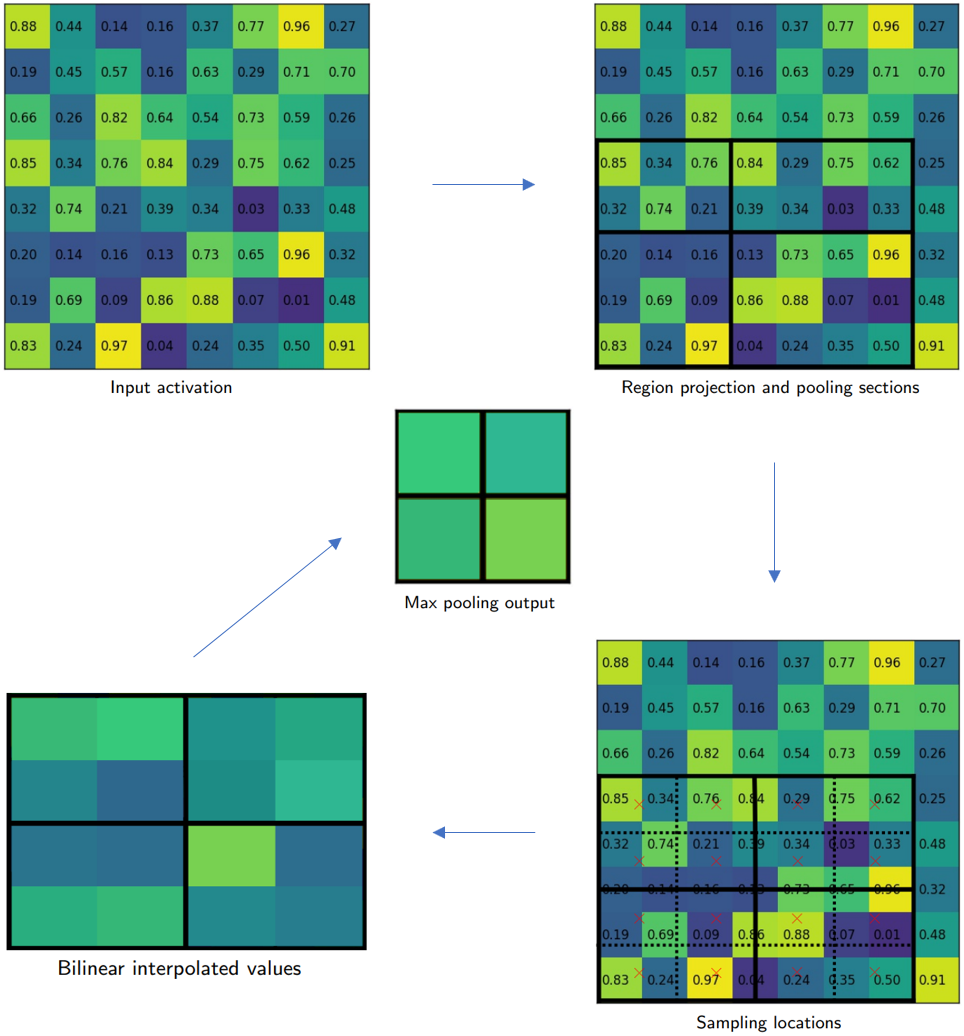
RoIAlign如圖所示。切分bin的時候和RoI pooling有所不同,避免了量化帶來的誤差,保證pixel-to-pixel的對齊。如右下圖,RoIAlign切分bin的時候不進行量化,每個bin劃分成2x2(4個紅色x標記),每個紅色x通過最相鄰的4個像素值進行雙線性插值計算,得到每個bin的4個插值,最后通過max pooling得到最終的2x2 feature map。
貢獻
Mask R-CNN完美地展現(xiàn)了Faster R-CNN的易拓展性和強大的檢測能力。但是Mask R-CNN最重要的貢獻其實是提高了人們對實例分割任務思維上的認知。從現(xiàn)在看,先檢測后分割的思路似乎非常簡單,但是在Mask R-CNN出現(xiàn)之前,實例分割大多數(shù)都是bottom-up的思路,而Mask R-CNN是top-down的思路,在當時如何在檢測框架中簡潔優(yōu)雅的嵌入實例分割是很困難的。
詳細的討論可以看周博磊大佬當年的回答https://www.zhihu.com/question/51704852/answer/127120264
Mask R-CNN最終奪得ICCV 2017 Best Paper。Mask R-CNN即使放到現(xiàn)在也依然是王者,再次感受一下Mask R-CNN的強大

R-CNN/Fast R-CNN/Faster R-CNN/Mask R-CNN比較
這里祭出我的多年珍藏(slides放在公眾號了,回復R-CNN自取)
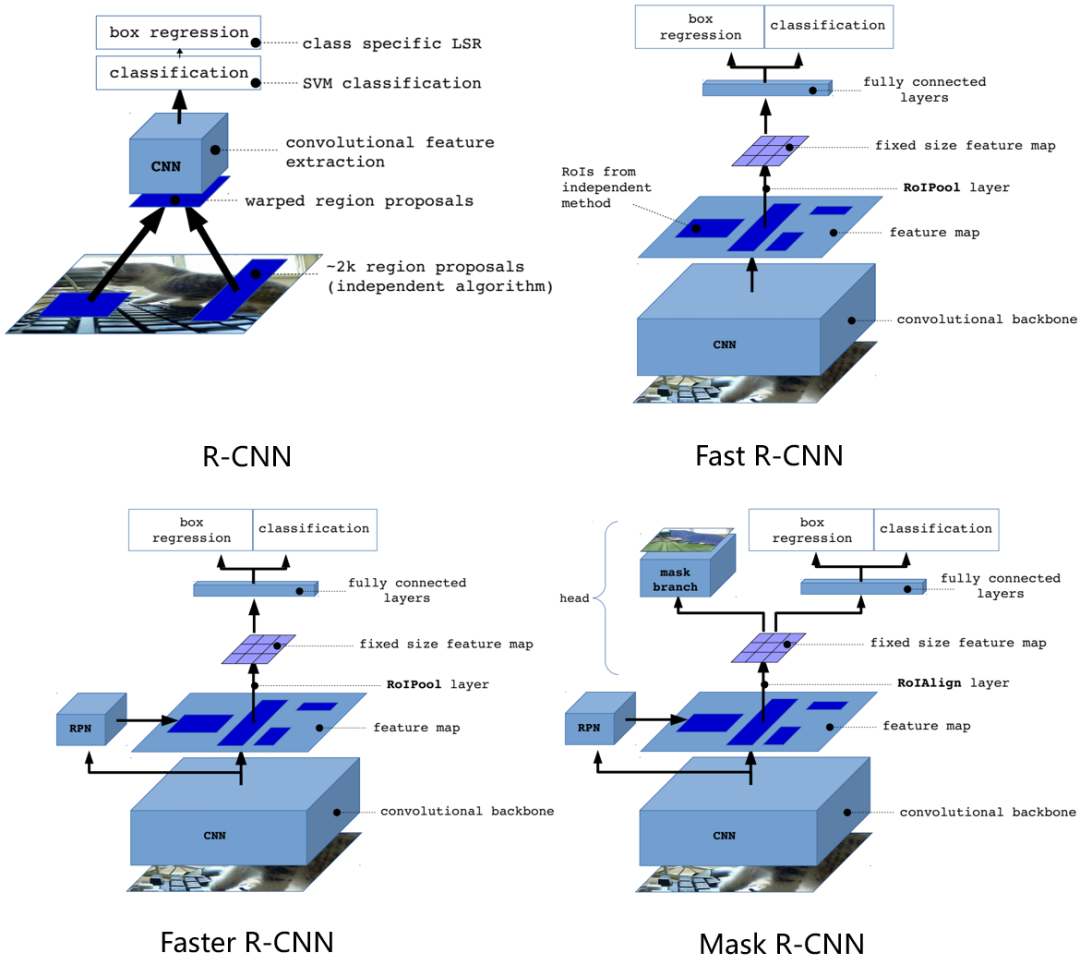
從上圖可以清清楚楚的看出從R-CNN到Mask R-CNN框架是如何演變的。
可以分成兩個支線看:訓練流程和推理框架。
訓練流程上
R-CNN -> Fast R-CNN極大精簡了目標檢測框架的訓練流程,從4個獨立訓練流程精簡成了2個獨立訓練流程。
Fast R-CNN -> Faster R-CNN因為RPN網(wǎng)絡的引入,導致訓練流程重新變成了RPN和Fast R-CNN交替訓練4次(后續(xù)開源代碼將RPN和Fast R-CNN聯(lián)合訓練了)。
Faster R-CNN -> Mask R-CNN又轉變成了2個獨立訓練流程。
推理框架上
R-CNN -> Fast R-CNN提取RoI進行并行化處理,將分類和定位看成一個多任務,并設計RoI pooling來進行特征對齊。
Fast R-CNN -> Faster R-CNN提出RPN來對region proposal部分進行加速,并且提出anchor來適應不同形態(tài)的目標。
Faster R-CNN -> Mask R-CNN增加一個mask分支,展示了Faster R-CNN的易拓展性,并且設計了RoIAlign進行pixel-to-pixel的對齊。
05
總結
整個R-CNN系列非常經(jīng)典,陣容極其華麗(RBG、何愷明、任少卿等等)。從傳統(tǒng)視覺到深度學習,RGB簡單直接的應用CNN構造了R-CNN檢測器,開啟基于深度學習的目標檢測新時代;從R-CNN到Fast R-CNN、Faster R-CNN通過實驗觀察和思考,發(fā)現(xiàn)問題,解決問題;Mask R-CNN在已有領域,通過簡單設計改造,從目標檢測任務遷移到實例分割任務。無論是從設計思維,洞察力和科研敏銳性上,都無可挑剔。(ps:R-CNN的文章,看起來粗糙,實則干貨滿滿;現(xiàn)在的文章都一個模子刻出來的一樣,看起來精致,實則同質化嚴重)
最后,我想說的是計算機視覺中,從R-CNN到Mask R-CNN的思維躍遷是我最愛看的“小說”章節(jié)。
Reference
[1] Rich feature hierarchies for accurate object detection and semantic segmentation
[2] Fast R-CNN
[3] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
[4] Mask R-CNN
另外再推薦幾篇Faster R-CNN的blog,非常精彩
https://zhuanlan.zhihu.com/p/31426458
https://zhuanlan.zhihu.com/p/145842317
https://zhuanlan.zhihu.com/p/32404424
往期精彩回顧
本站qq群851320808,加入微信群請掃碼: