
必須收藏!BatchNorm的避坑指南
 點藍色字關注“機器學習算法工程師”
點藍色字關注“機器學習算法工程師”
設為星標,干貨直達!
BatchNorm作為一種特征歸一化方法基本是CNN網(wǎng)絡的標配。BatchNorm可以加快模型收斂速度,防止過擬合,對學習速率更魯棒,但是BatchNorm由于在batch上進行操作,如果使用不當可能會帶來副作用。近期Facebook AI的論文Rethinking "Batch" in BatchNorm系統(tǒng)且全面地對BatchNorm可能會帶來的問題做了總結(jié),同時也給出了一些規(guī)避方案和建議,堪稱一份“避坑指南”。
BatchNorm
BatchNorm主要在CNN網(wǎng)絡中應用,對于NLP領域,常采用的transformer采用的是LayerNorm,所以這里只討論BatchNorm2D。在訓練階段,對于shape為的mini-batch ,BatchNorm首先計算各個channel的均值和方差:
然后BatchNorm對shape為特征進行歸一化:
可以看到計算均值和方差是依賴batch的,這也就是BatchNorm的名字由來。在測試階段,BatchNorm采用的均值和方差是從訓練過程估計的全局統(tǒng)計量(population statistics):和,這兩個參數(shù)也是從訓練數(shù)據(jù)學習到的參數(shù)(但不是可訓練參數(shù),沒有BP過程)。常規(guī)的做法在訓練階段采用EMA( exponential moving average,指數(shù)移動平均,在TensorFlow中EMA產(chǎn)生的均值和方差稱為moving_mean和moving_var,而PyTorch則稱為running_mean和running_var)來估計:
訓練階段采用的是mini-batch統(tǒng)計量,而測試階段是采用全局統(tǒng)計量,這就造成了BatchNorm的訓練和測試不一致問題,這個后面會詳細討論。
除了歸一化,BatchNorm還包含對各個channel的特征做affine transform(增加特征表征能力):
這里的和是可訓練的參數(shù),但是這個過程其實沒有batch的參與,從實現(xiàn)上等價于額外增加一個depthwise 1 × 1卷積層。BatchNorm的麻煩主要來自于mini-batch統(tǒng)計量的計算和歸一化中,這個affine transform不是影響因素,所以后面的討論主要集中在前面。
圍繞著batch所能帶來的問題,論文共討論了BatchNorm的四個方面:
Population Statistics:EMA是否能夠準確估計全局統(tǒng)計量以及PreciseBN; Batch in Training and Testing:訓練采用mini-batch統(tǒng)計量,而測試采用全局統(tǒng)計量,由此帶來的不一致問題; Batch from Different Domains:BatchNorm在multiple domains中遇到的問題; Information Leakage within a Batch:BatchNorm所導致的信息泄露問題;
第二個應該是大家都熟知的問題,但是其實BatchNorm可能影響的方面是很多的,如域適應(domain adaptation)和對比學習中信息泄露問題。另外,這里討論的4個方面也不是獨立的,它們往往交織在一起。
Population Statistics
訓練過程中的均值和方差是mini-batch計算出來的,但是在推理階段往往是每次只處理一個sample,沒有辦法再計算依賴batch的統(tǒng)計量。BatchNorm采用的方法是訓練過程中用EMA估計全局統(tǒng)計量,但是這個估計可能會夠好:當較大時,每個iteration中mini-batch的統(tǒng)計量對全局統(tǒng)計量貢獻很少,這會導致更新過慢;當較大時,每個iteration中mini-batch的統(tǒng)計量會起主導作用,導致估計值不能代表全局。一般情況取一個較大的值,如0.9或0.99,這是一個超參數(shù)。論文中在ResNet50的訓練過程(256 GPU,每個GPU batch_size=32)隨機選擇模型的某個BatchNorm層的某個channel,繪制了其EMA mean以及population mean,這里的population mean采用當前模型在100 mini-batches的batch mean的平均值來估計,這個可以代表當前模型的全局統(tǒng)計量,對比圖如下所示。在訓練前期,從圖a可以看到EMA mean和當前的batch mean是有距離的,而圖b說明EMA mean是落后于當前模型的近似全局統(tǒng)計量的,但是到訓練中后期EMA mean就比較準確了。
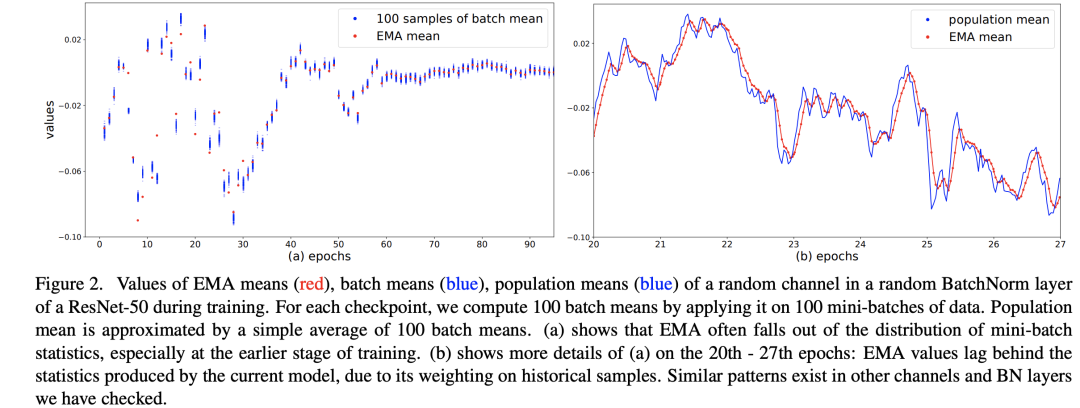
這說明EMA統(tǒng)計量在訓練早期是有偏差的。一個準確的全局統(tǒng)計量應該是:使用整個訓練集作為一個batch計算特征的均值和方差,但是這個計算成本太高了,論文中提出采用一種近似方法來計算:首先采用固定模型(訓練好的)計算很多mini-batch;然后聚合每個mini-batch的統(tǒng)計量來得到全局統(tǒng)計量。假定共需要計算個samples,batch_size為,那么共計算個mini-batch,記它們的統(tǒng)計量為,那么全局統(tǒng)計量可以近似這樣計算:
這其實只是一種聚合方式,論文附錄也討論了其它計算方式,結(jié)果是類似的。這種BatchNorm稱為PreciseBN,具體代碼實現(xiàn)可以參考fvcore.nn.precise_bn:
class _PopulationVarianceEstimator:
"""
Alternatively, one can estimate population variance by the sample variance
of all batches combined. This needs to use the batch size of each batch
in this function to undo the bessel-correction.
This produces better estimation when each batch is small.
See Appendix of the paper "Rethinking Batch in BatchNorm" for details.
In this implementation, we also take into account varying batch sizes.
A batch of N1 samples with a mean of M1 and a batch of N2 samples with a
mean of M2 will produce a population mean of (N1M1+N2M2)/(N1+N2) instead
of (M1+M2)/2.
"""
def __init__(self, mean_buffer: torch.Tensor, var_buffer: torch.Tensor) -> None:
self.pop_mean: torch.Tensor = torch.zeros_like(mean_buffer) # population mean
self.pop_square_mean: torch.Tensor = torch.zeros_like(var_buffer) # population variance
self.tot = 0 # total samples
# update per mini-batch, is called by `update_bn_stats`
def update(
self, batch_mean: torch.Tensor, batch_var: torch.Tensor, batch_size: int
) -> None:
self.tot += batch_size
batch_square_mean = batch_mean.square() + batch_var * (
(batch_size - 1) / batch_size
)
self.pop_mean += (batch_mean - self.pop_mean) * (batch_size / self.tot)
self.pop_square_mean += (batch_square_mean - self.pop_square_mean) * (
batch_size / self.tot
)
@property
def pop_var(self) -> torch.Tensor:
return self.pop_square_mean - self.pop_mean.square()
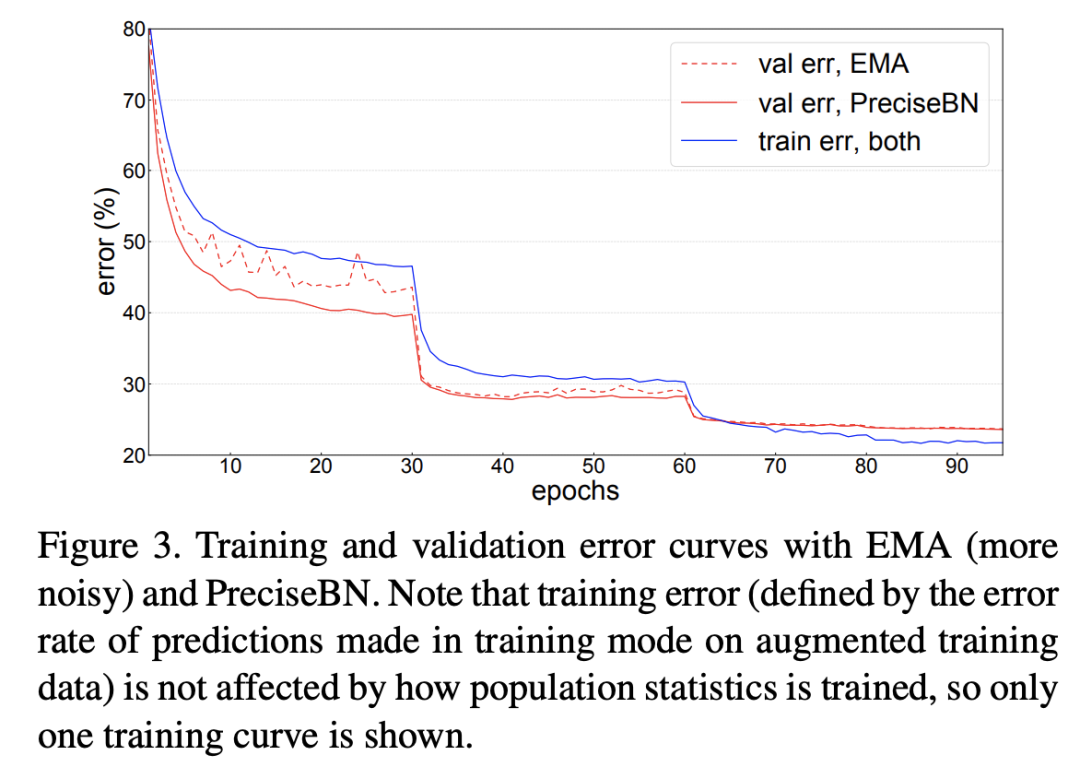
論文中以ResNet50的訓練為例對比了EMA和PreciseBN的效果,如下圖所示,可以看到PreciseBN比EMA效果更加穩(wěn)定,特別是訓練早期(此時模型未收斂),雖然最終兩者的效果接近。
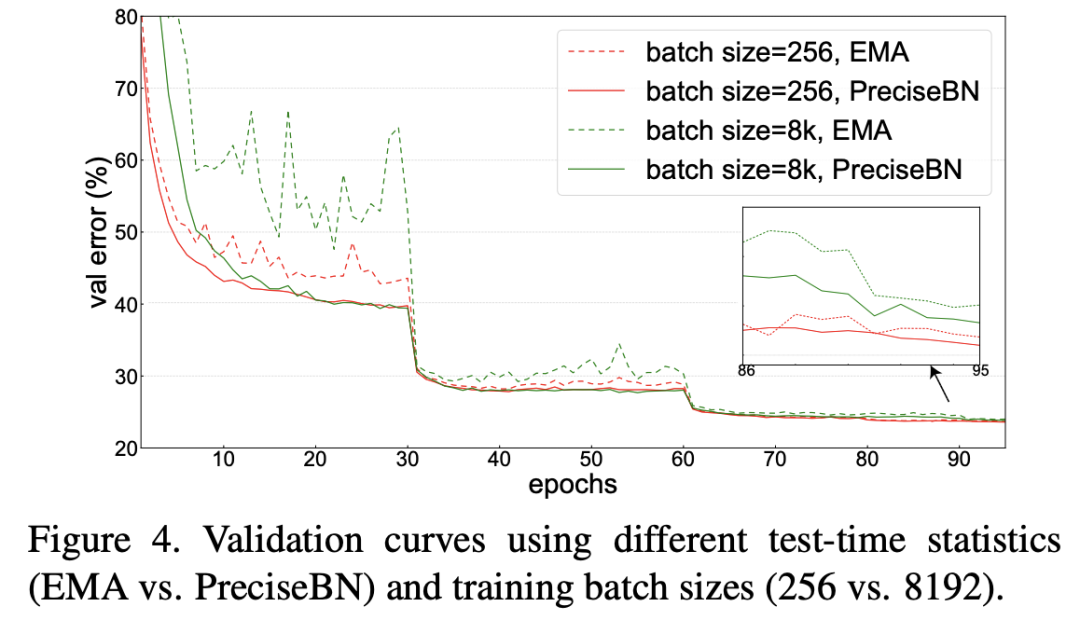
進一步地,如果訓練采用更大的batch size,實驗發(fā)現(xiàn)EMA在訓練過程中的抖動更大,但此時PreciseBN效果比較穩(wěn)定。當采用larger batch訓練時,學習速率增大,而且EMA更新次數(shù)減少,這些都會對EMA產(chǎn)生較大影響。綜上,雖然EMA和PreciseBN最終效果接近(因此EMA的缺點往往被忽視),但是在模型未收斂的訓練早期,PreciseBN更加穩(wěn)定,像強化學習需要在訓練早期評估模型效果這種場景,PreciseBN能帶來更加穩(wěn)定可靠的結(jié)果。
此外,論文也通過實驗證明了PreciseBN只需要 samples就可以得到比較好的結(jié)果,以ImageNet訓練為例,采用PreciseBN評估只需要增加0.5%的訓練時間。

另外,論文里還對比了batch size對PreciseBN的影響。這里先理清楚兩個概念:(1)normalization batch size(NBS):實際計算統(tǒng)計量的mini-batch的size;(2)total batch size或者SGD batch size:每個iteration中mini-batch的size,或者說每執(zhí)行一次SGD算法的batch size;兩者在多卡訓練過程是不等同的(此時NBS是per-GPU batch size,而SyncBN可以實現(xiàn)兩者一致)。從結(jié)果來看,NBS較小時,模型效果會變差,但是PreciseBN的batch size是相對NBS獨立的,所以選擇batch size 時PreciseBN可以取得穩(wěn)定的效果,并且在NBS較小時相比EMA提升效果。

Batch in Training and Testing
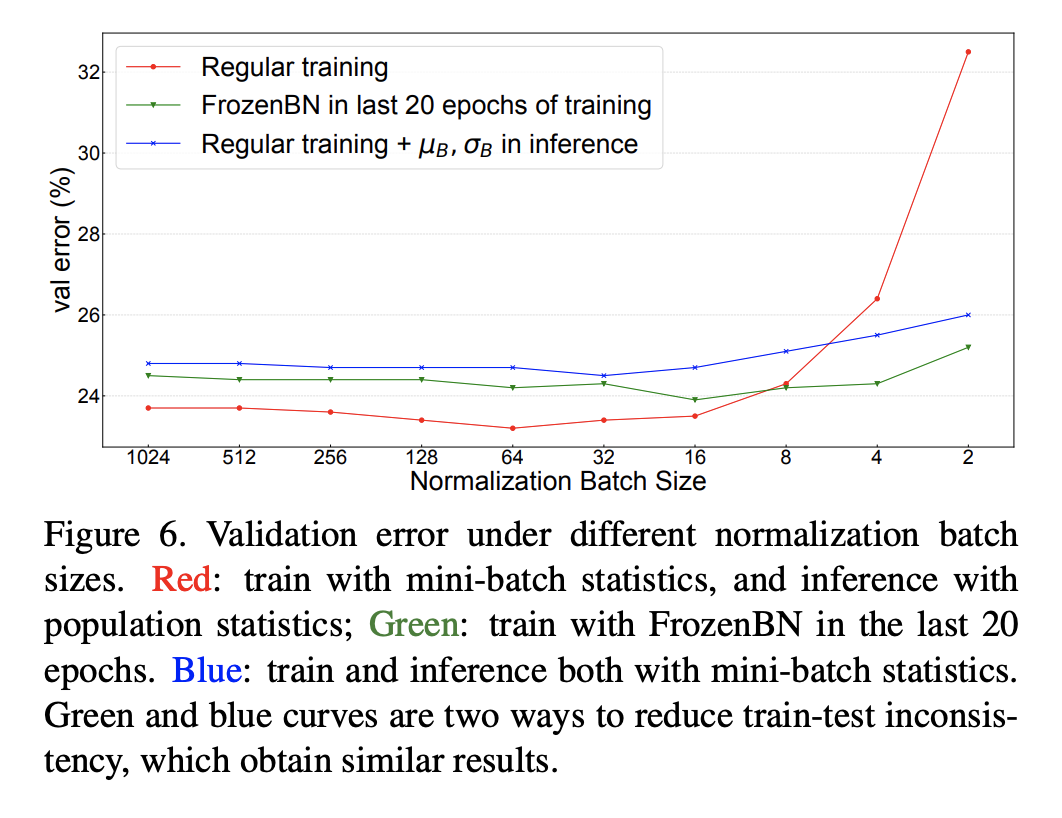
前面已經(jīng)說過BatchNorm在訓練時采用的是mini-batch統(tǒng)計量,而測試時采用的全局統(tǒng)計量,這就導致了訓練和測試的不一致性,從而帶來對模型性能的影響。為此,論文還是以ResNet50訓練為例分析這種不一致帶來的影響,這里還同時比較了不同NBS帶來的差異(SGD batch size固定在1024,此時NBS從2~1024變化),分別對比不同NBS下的三個指標:(1)采用mini-batch統(tǒng)計量在訓練集上的分類誤差;(2)采用mini-batch統(tǒng)計量在驗證集上的分類誤差;(3)采用全局統(tǒng)計量在驗證集上的分類誤差。這里(1)和(3)其實是常規(guī)評估方法,而(2)往往不會這樣做,但是(1)和(2)就保持一致了(訓練和測試均采用mini-batch統(tǒng)計量)。對比結(jié)果如下所示,從中可以得到三個方面的結(jié)論:
training noise:訓練集誤差隨著NBS增大而減少,這主要是由于SGD訓練噪音所導致的,當NBS較小時,mini-batch統(tǒng)計量波動大導致優(yōu)化困難,從而產(chǎn)生較大的訓練誤差; generalization gap:對比(1)和(2),兩者均采用mini-batch統(tǒng)計量,差異就來自數(shù)據(jù)集不同,這部分性能差異就是泛化gap; train-test inconsistency:對比(2)和(3),兩者數(shù)據(jù)集一樣,但是(2)采用mini-batch統(tǒng)計量,而(3)采用全局統(tǒng)計量,這部分性能差異就是訓練和測試不一致所導致的;
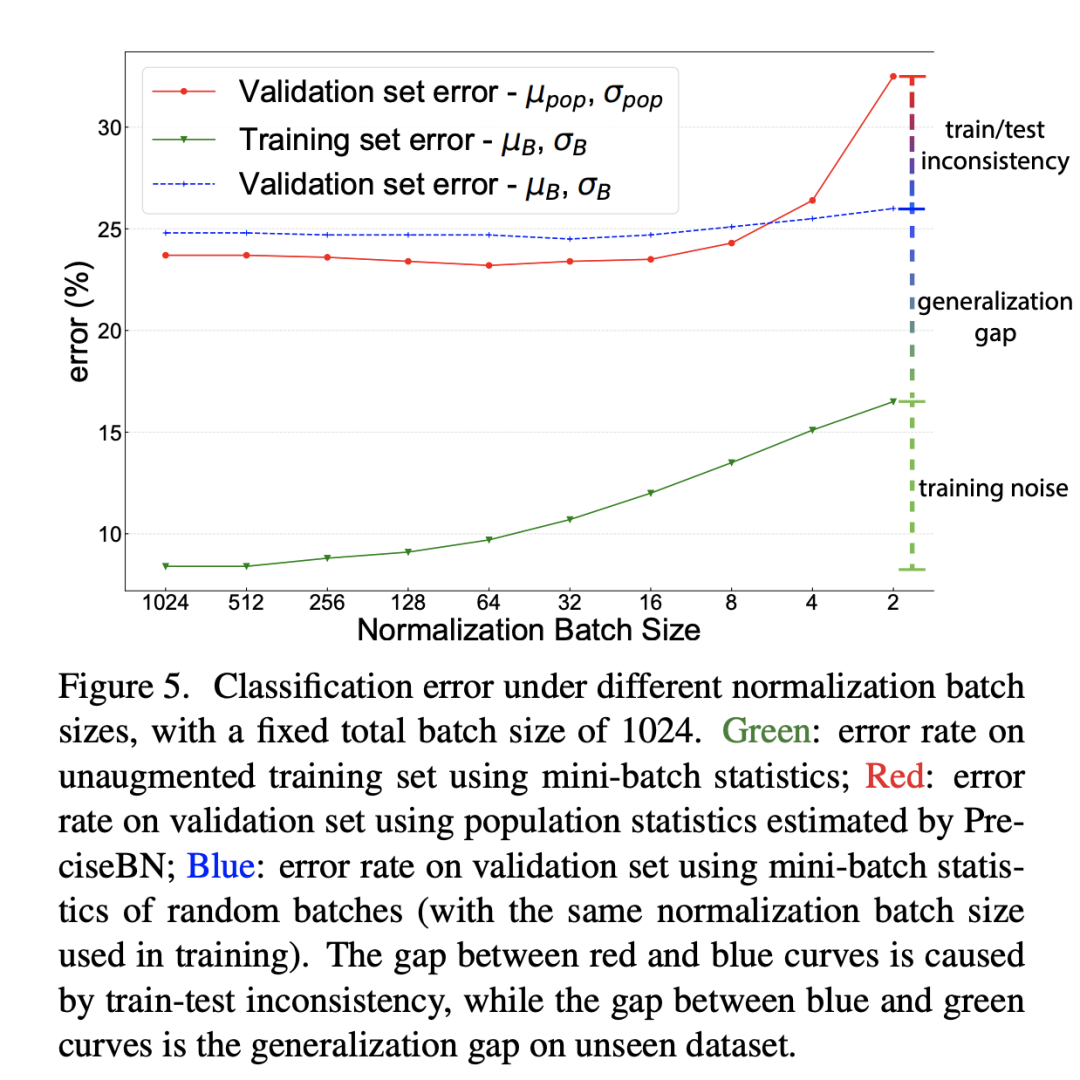
另外,我們可以看到當NBS較小時,(2)和(3)的性能差距是比較大的,這說明如果訓練的NBS比較小時在測試時采用mini-batch統(tǒng)計量效果會更好,此時保持一致是比較重要的(這點至關重要)。當NBS較大時,(2)和(3)的差異就比較小,此時mini-batch統(tǒng)計量越來越接近全局統(tǒng)計量。
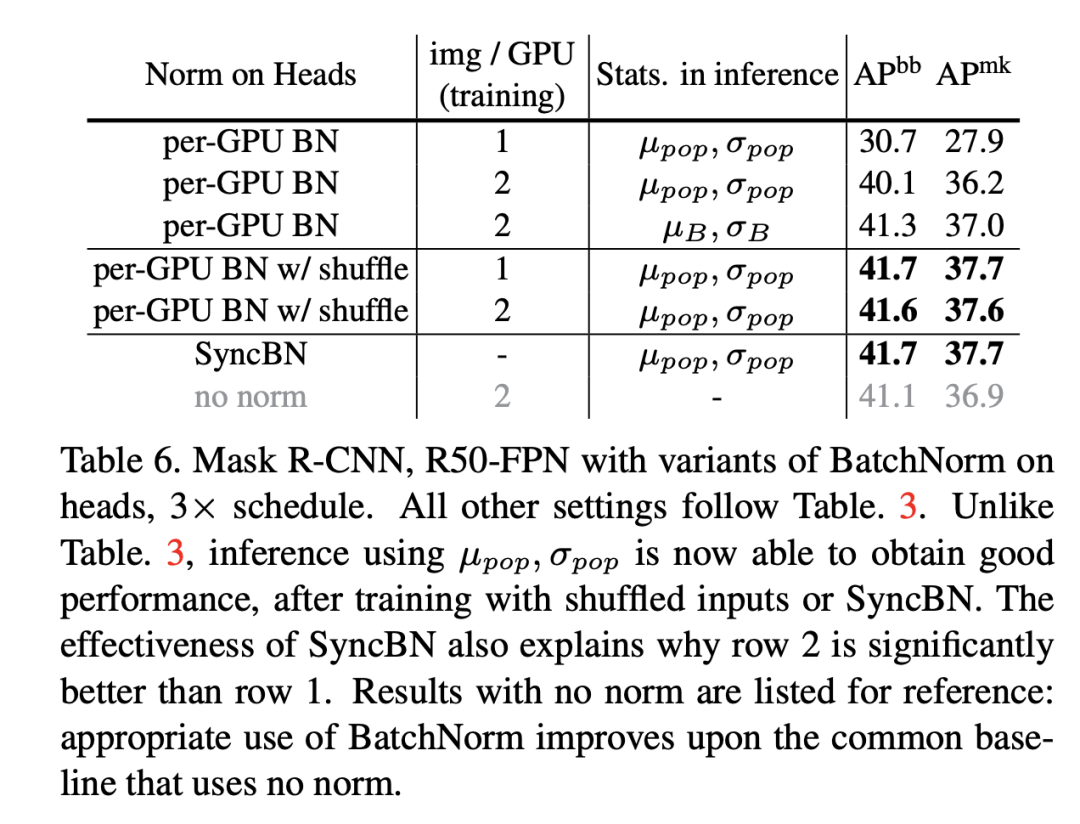
雖然NBS較小時,在測試時采用mini-batch統(tǒng)計量效果更好,但是在實際場景中幾乎不會這樣處理(一般情況下都是每次處理一個樣本)。不過還是有一些特例,比如兩階段檢測模型R-CNN中,R-CNN的head輸入是每個圖像的一系列region-of-interest (RoIs),一般情況下一個圖像會有個RoIs,實際情況這些RoIs是組成batch進行處理的,訓練過程是所有圖像的RoIs,而測試時是單個圖像的RoIs組成batch,在這種情況中測試時就可以選擇mini-batch統(tǒng)計量。這里以Mask R-CNN為實驗模型,將默認的2fc box head(2個全連接層)換成4conv1fc head(4個卷積層加一個,并且在box head和mask head的每個卷積層后面都加上BatchNorm層,實驗結(jié)果如下,可以看到采用mini-batch統(tǒng)計量是優(yōu)于采用全局統(tǒng)計量的,另外在訓練過程中每個GPU只用一張圖像時,此時測試時采用全局統(tǒng)計量效果會很差,這里有另外的過擬合問題存在,后面再述(BatchNorm導致的信息泄露)。另外R-CNN的head還存在另外的一種訓練和測試的inconsistency:訓練時mini-batch是正負樣本抽樣的,而測試時是按score選取的topK,mini-batch的分布就發(fā)生了變化。

另外一個避免訓練和測試的inconsistency可選方案是訓練也采用全局統(tǒng)計量,常用的方案是Frozen BatchNorm (FrozenBN)(訓練中直接采用EMA統(tǒng)計量模型無法訓練),F(xiàn)rozenBN指的是采用一個提前算好的固定全局統(tǒng)計量,此時BatchNorm的訓練優(yōu)化就只有一個linear transform了。FrozenBN采用的情景是將一個已經(jīng)訓練好的模型遷移到其它任務,如在ImageNet訓練的ResNet模型在遷移到下游檢測任務時一般采用FrozenBN。不過我們也可以在模型的訓練過程中采用FrozenBN,論文中還是以ResNet50為例,在前80個epoch采用正常的BN訓練,在后20個epoch采用FrozenBN,對比效果如下,可以看到FrozenBN在NBS較小時也是表現(xiàn)較好,優(yōu)于測試時采用mini-batch統(tǒng)計量,這不失為一種好的方案。這里值得注意的是當NBS較大時,F(xiàn)rozenBN還是測試時采用mini-batch統(tǒng)計量均差于常規(guī)方案(BN訓練,測試時采用全局統(tǒng)計量)。
Batch from Different Domains
包含BatchNorm的模型訓練過程包含兩個學習過程:一是模型主體參數(shù)是通過SGD學習得到的(SGD training),二是全局統(tǒng)計量是通過EMA或者PreciseBN從訓練數(shù)據(jù)中學習得到(population statistics training)。當訓練數(shù)據(jù)和測試數(shù)據(jù)分布不同時,我們稱之為domain shift,這個時候?qū)W習得到的全局統(tǒng)計量就可能會在測試時失效,這個問題已經(jīng)有論文提出要采用Adaptive BatchNorm來解決,即在測試數(shù)據(jù)上重新計算全局統(tǒng)計量。這里還是以ResNet50為例(SGD batch size為1024,NBS為32),用ImageNet-C數(shù)據(jù)集(ImageNet的擾動版本,共三種類型:contrast,gaussian noise和jpeg compression)來評估domain shift問題,結(jié)果如下:
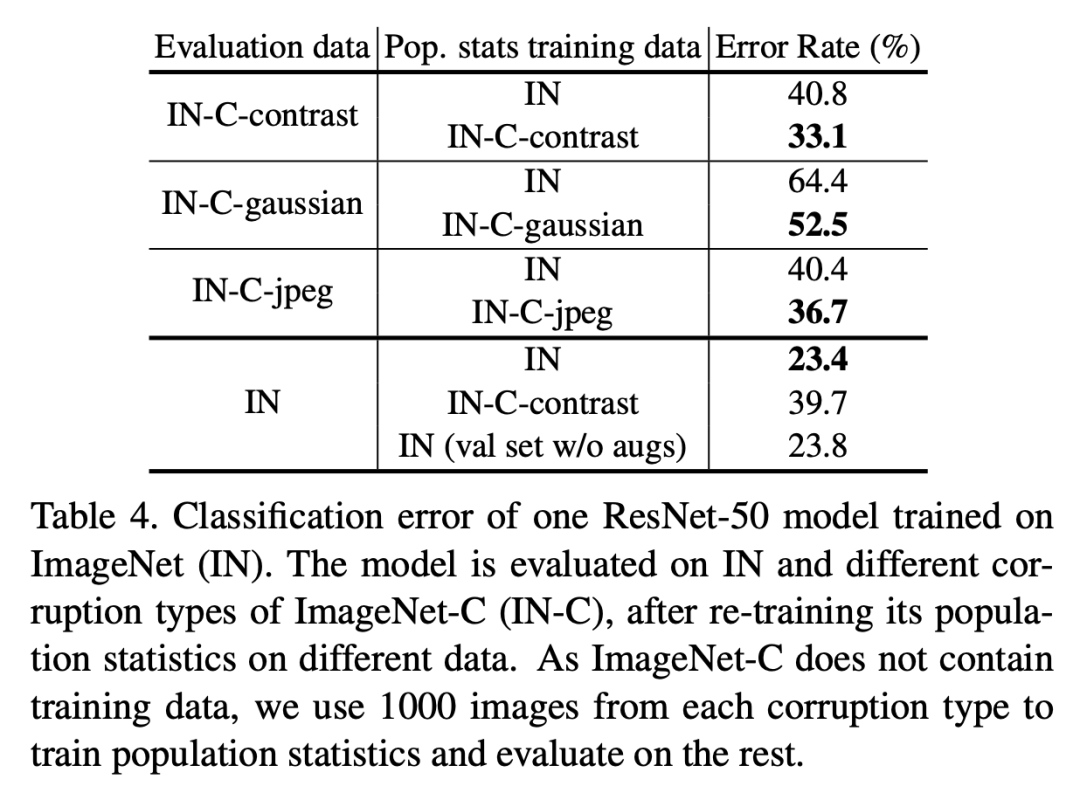
從表中可以明顯看出:當出現(xiàn)domain shift問題后,采用Adaptive BatchNorm在target domain數(shù)據(jù)集上重新計算全局統(tǒng)計量可以提升模型效果。不過從表最后一行可以看到,如果在ImageNet驗證集上重新計算統(tǒng)計量(直接采用inference-time預處理),最終效果要稍微差于原來結(jié)果(23.4 VS 23.8),這可能說明如果不存在明顯的domain shift,原始處理方式是最好的。
除了domain shift,訓練數(shù)據(jù)存在multi-domain也會對BatchNorm產(chǎn)生影響,這個問題更復雜了。這里以RetinaNet模型來說明multi-domain的出現(xiàn)可能出現(xiàn)的問題。RetinaNet的head包含4個卷積層以及最終的分類器和回歸器,其輸入是來自不同尺度的5個特征(),這可以kan'chehead在5個特征上是共享的,默認head是不包含BatchNorm,當我們在每個卷積后加上BatchNorm后,問題就變得復雜了。首先,首先就是訓練過程mini-batch統(tǒng)計量的計算,明顯有兩種不同處理方式,一是對不同domain的特征輸入單獨計算mini-batch統(tǒng)計量并單獨歸一化,二是將所有domain的特征concat在一起,計算一個mini-batch統(tǒng)計量來歸一化。這兩種處理方式如下所示:
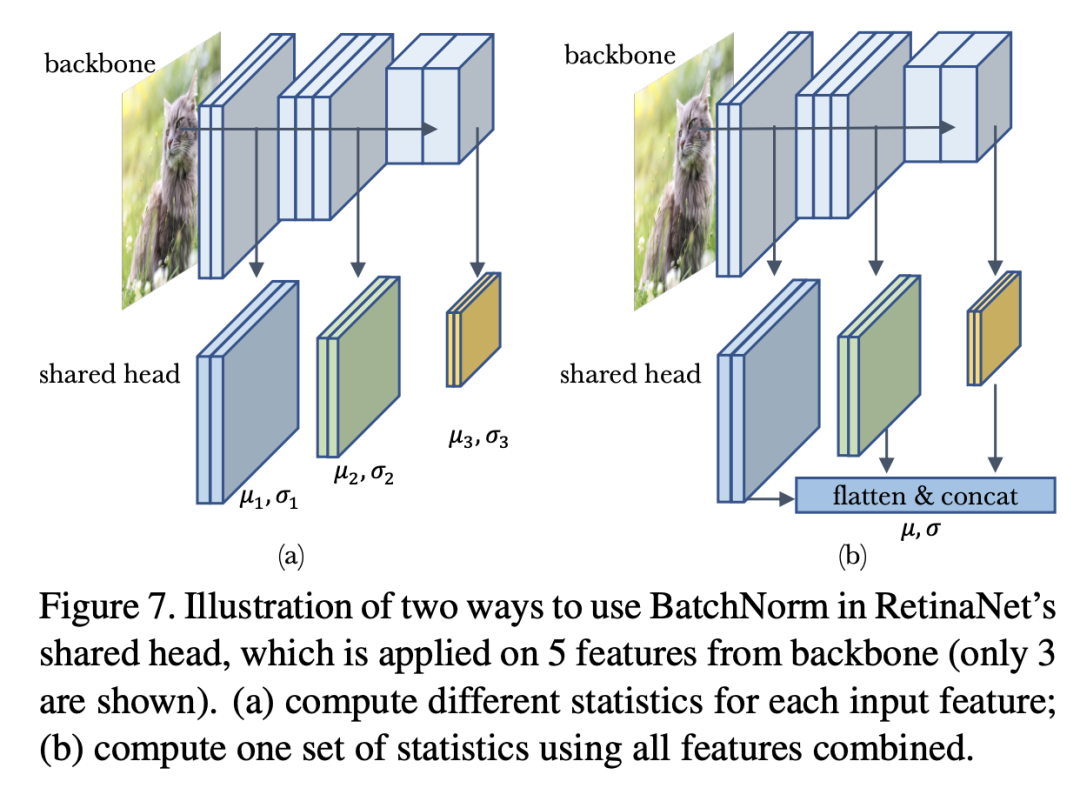
這里記SGD訓練過程中的兩種方式分別為domain-specific statistics和shared statistics。對于學習全局統(tǒng)計量,同樣存在對應的兩種方式,即每個domain的特征單獨學習一套全局統(tǒng)計量,還是共享一套全局統(tǒng)計量。對于BatchNorm的affine transform layer也存在兩種選擇:每個domain一套參數(shù)還是共享參數(shù)。不同組合的模型效果如下表所示:

從表中結(jié)果可以總結(jié)兩個結(jié)論:(1)SGD training和population statistics training保持一致非常重要,此時都可以取得較好的結(jié)果(行1,行4和行6);(2)affine transform layer無論單獨參數(shù)還是共享基本不影響結(jié)果。這里的一個小插曲是如果直接在head中加上BatchNorm,其實對應的是行3,其實這是因為不同尺度的特征是序列處理的,這就造成了SGD training其實是domain-specific的,此時效果就較差,所以大部分實現(xiàn)中要不然不用norm,要不然就用BatchNorm。不同組合的實現(xiàn)代碼如下:
# 簡單地加上BN,注意forward時,不同特征是串行處理的,那么SGD training其實是domain-specific的,
# 但是只維持一套全局統(tǒng)計量,所以測試時又是共享的
class RetinaNetHead_Row3:
def __init__(self, num_conv, channel):
head = []
for _ in range(num_conv):
head.append(nn.Conv2d(channel, channel, 3))
head.append(nn.BatchNorm2d(channel))
self.head = nn.Sequential(?head)
def forward(self, inputs: List[Tensor]):
return [self.head(i) for i in inputs]
# 如果要共享,那么在forward時對特征進行concat來統(tǒng)一計算并歸一化
class RetinaNetHead_Row1(RetinaNetHead_Row3):
def forward(self, inputs: List[Tensor]):
for mod in self.head:
if isinstance(mod, nn.BatchNorm2d):
# for BN layer, normalize all inputs together
shapes = [i.shape for i in inputs]
spatial_sizes = [s[2] ? s[3] for s in shapes]
x = [i.flatten(2) for i in inputs]
x = torch.cat(x, dim=2).unsqueeze(3)
x = mod(x).split(spatial_sizes, dim=2)
inputs = [i.view(s) for s, i in zip(shapes, x)]
else:
# for conv layer, apply it separately
inputs = [mod(i) for i in inputs]
return inputs
# 另外一種簡單的處理方式是每個特征采用各自的BN
class RetinaNetHead_Row6:
def __init__(self, num_conv, channel, num_features):
# num_features: number of features coming from
# different FPN levels, e.g. 5
heads = [[] for _ in range(num_levels)]
for _ in range(num_conv):
conv = nn.Conv2d(channel, channel, 3)
for h in heads:
# add a shared conv and a domain?specific BN
h.extend([conv, nn.BatchNorm2d(channel)])
self.heads = [nn.Sequential(?h) for h in heads]
def forward(self, inputs: List[Tensor]):
# end up with one head for each input
return [head(i) for head, i in
zip(self.heads, inputs)]
對于行2和行4,可以通過訓練好的行1和行3模型重新在訓練數(shù)據(jù)上計算domain-specific全局統(tǒng)計量即可,在實現(xiàn)時,可以如下:
class CycleBatchNormList(nn.ModuleList):
"""
A hacky way to implement domain-specific BatchNorm
if it's guaranteed that a fixed number of domains will be
called with fixed order.
"""
def __init__(self, length, channels):
super().__init__([nn.BatchNorm2d(channels, affine=False) for k in range(length)])
# shared affine, domain-specific BN
self.weight = nn.Parameter(torch.ones(channels))
self.bias = nn.Parameter(torch.zeros(channels))
self._pos = 0
def forward(self, x):
ret = self[self._pos](x)
self._pos = (self._pos + 1) % len(self)
w = self.weight.reshape(1, -1, 1, 1)
b = self.bias.reshape(1, -1, 1, 1)
return ret * w + b
# 訓練好模型,我們可以重新將BN層換成以上實現(xiàn),就可以在訓練數(shù)據(jù)上重新計算domain-specific全局統(tǒng)計量
RetinaNet面臨的其實是特征層面的multi-domain問題,而且每個batch中的各個domain是均勻的。如果是數(shù)據(jù)層面的multi-domain,其面臨的問題將會復雜,此時domain的分布比例也是多變的,但是總的原則是盡量減少不一致性,因為consistency is crucial。
Information Leakage within a Batch
BatchNorm面臨的另外一個挑戰(zhàn),就是可能出現(xiàn)信息泄露,這里所說的信息泄露指的是模型學習到了利用mini-batch的信息來做預測,而這些其實并不是我們要學習的,因為這樣模型可能難以對mini-batch里的每個sample單獨做預測。
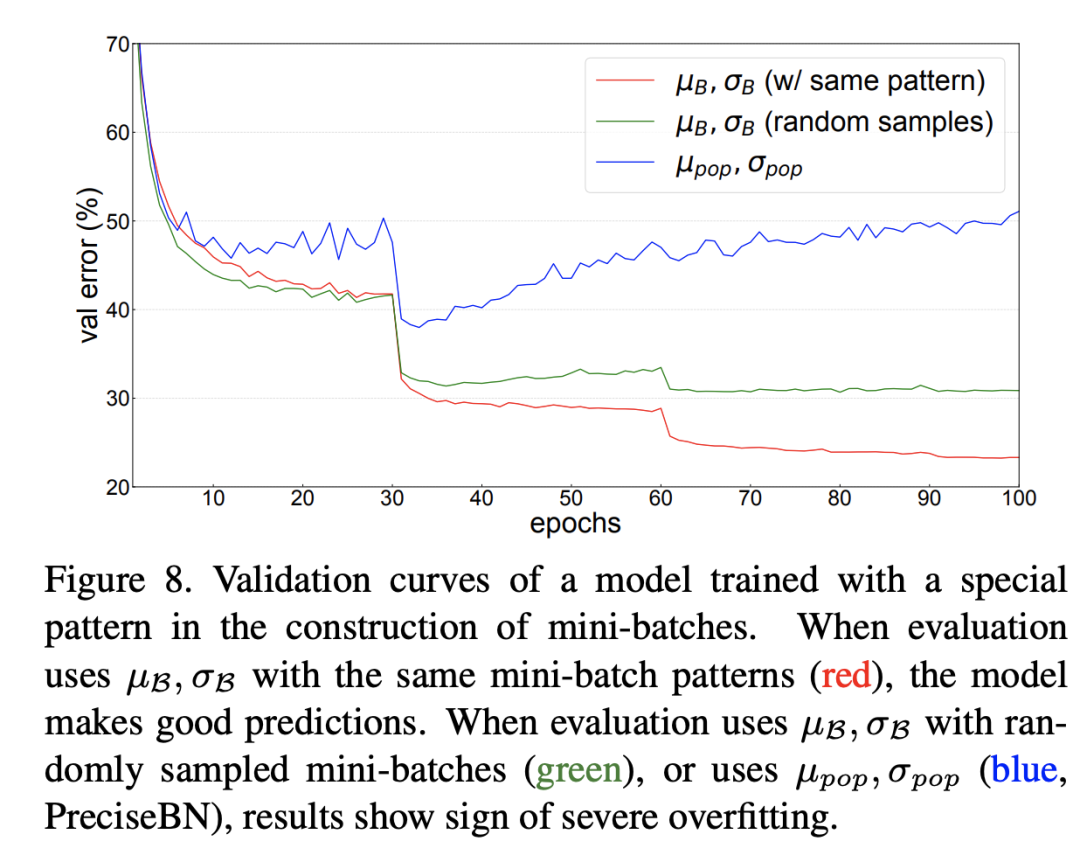
比如BatchNorm的作者曾做過這樣一個實驗,在ResNet50的訓練過程中,NBS=32,但是保證里面包含16個類別,每個類別有2個圖像,這樣一種特殊的設計要模型在訓練過程中強制記憶了這種模式(可能是每個mini-batch中必須有同類別存在),那么在測試時如果輸入不是這種設計,效果就會變差。這個在驗證集上不同處理結(jié)果如上所示,可以看到測試時無論是采用全局統(tǒng)計量還是random mini-batch統(tǒng)計量,效果均較差,但是如果采用和訓練過程同樣的模式,效果就比較好。這其實也從側(cè)面說明保持一致是多么的重要。
前面說過,如果在R-CNN的head加入BatchNorm,那么在測試時采用mini-batch統(tǒng)計量會比全局統(tǒng)計量會效果更好,這里面其實也存在信息泄露的問題。對于每個GPU只有一個image的情況,每個mini-batch里面的RoIs全部來自于一個圖像,這時候模型就可能依賴mini-batch來做預測,那么測試時采用全局統(tǒng)計量效果就會差了,對于每個GPU有多個圖像時,情況還稍好一些,所以原來的結(jié)果中單卡單圖像效果最差。一種解決方案是采用shuffle BN,就是head進行處理前,先隨機打亂所有卡上的RoIs特征,每個卡分配隨機的RoIs,這樣就避免前面那個可能出現(xiàn)的信息泄露,head處理完后再shuffle回來,具體處理流程如下所示:
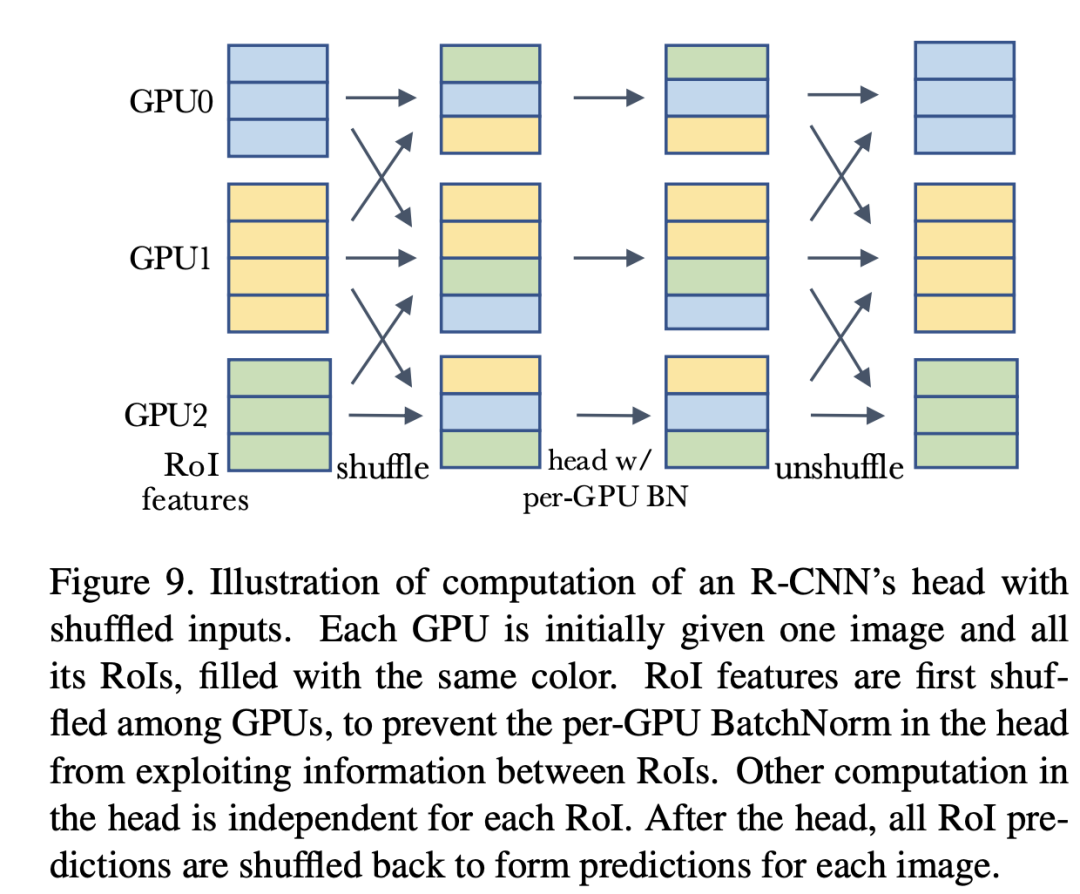
總結(jié)
一個簡單的BatchNorm,如果我們使用不當,往往會出現(xiàn)一些讓人意料的結(jié)果,所以要謹慎處理。總結(jié)來看,主要有如下結(jié)論和指南:
模型在未收斂時使用EMA統(tǒng)計量來評估模型是不穩(wěn)定的,一種替代方案是PreciseBN; BatchNorm本身存在訓練和測試的不一致性,特別是NBS較少時,這種不一致會更強,可用的方案是測試時也采用mini-batch統(tǒng)計量或者采用FrozenBN; 在domain shift場景中,最好基于target domain數(shù)據(jù)重新計算全局統(tǒng)計量,在multi-domain數(shù)據(jù)訓練時,要特別注意處理的一致性; BatchNorm會存在信息泄露的風險,這處理mini-batch時要防止特殊的出現(xiàn)。
參考
Rethinking "Batch" in BatchNorm
detectron2/projects/Rethinking-BatchNorm
推薦閱讀
谷歌AI用30億數(shù)據(jù)訓練了一個20億參數(shù)Vision Transformer模型,在ImageNet上達到新的SOTA!
"未來"的經(jīng)典之作ViT:transformer is all you need!
PVT:可用于密集任務backbone的金字塔視覺transformer!
漲點神器FixRes:兩次超越ImageNet數(shù)據(jù)集上的SOTA
不妨試試MoCo,來替換ImageNet上pretrain模型!
機器學習算法工程師
一個用心的公眾號
