
一文弄懂各種損失函數(shù)(loss function)
樸素貝葉斯: 最大化后驗(yàn)概率
遺傳編程: 最大化適應(yīng)度函數(shù)
強(qiáng)化學(xué)習(xí): 最大化總回報(bào)/價(jià)值函數(shù)
CART決策樹分類: 最大化信息增益/最小化子節(jié)點(diǎn)不純度
CART,決策樹回歸,線性回歸,自適應(yīng)線性神經(jīng)元…: 最小化均方誤差成本(或損失)函數(shù)
分類模型: 最大化對數(shù)似然或最小化交叉熵?fù)p失(或代價(jià))函數(shù)
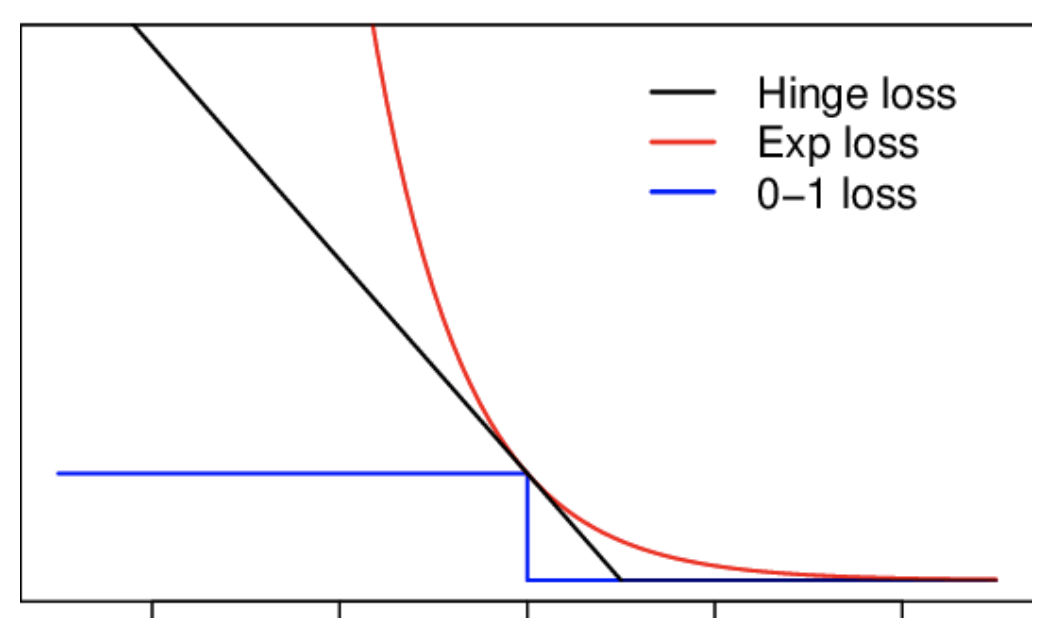
支持向量機(jī): 最小化hinge損失

Loss Function

損失函數(shù)是一種評估“你的算法/模型對你的數(shù)據(jù)集預(yù)估情況的好壞”的方法。如果你的預(yù)測是完全錯(cuò)誤的,你的損失函數(shù)將輸出一個(gè)更高的數(shù)字。如果預(yù)估的很好,它將輸出一個(gè)較低的數(shù)字。當(dāng)調(diào)整算法以嘗試改進(jìn)模型時(shí),損失函數(shù)將能反應(yīng)模型是否在改進(jìn)。“損失”有助于我們了解預(yù)測值與實(shí)際值之間的差異。損失函數(shù)可以總結(jié)為3大類,回歸,二分類和多分類。
常用損失函數(shù):
Mean Error (ME)
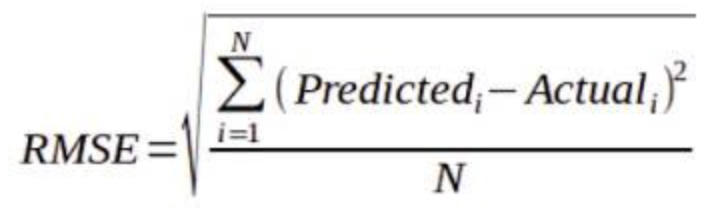
Mean Squared Error (MSE)
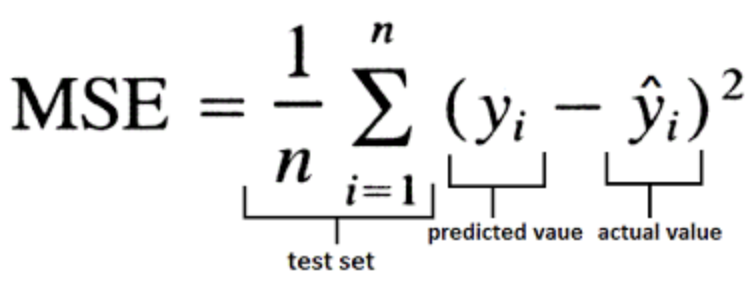
Mean Absolute Error (MAE)
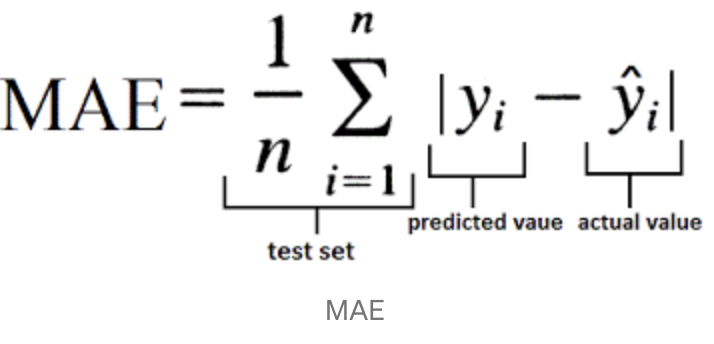
Root Mean Squared Error (RMSE)
Categorical Cross Entropy Cost Function(在只有一個(gè)結(jié)果是正確的分類問題中使用分類交叉熵)
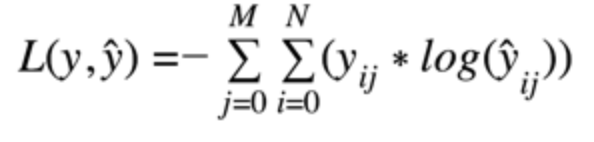
Binary Cross Entropy Cost Function.
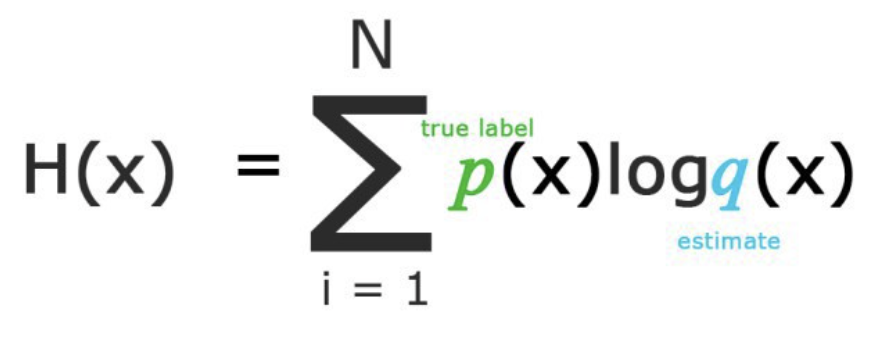
Hinge Loss(hinge損失不僅會(huì)懲罰錯(cuò)誤的預(yù)測,也會(huì)懲罰那些正確預(yù)測但是置信度低的樣本)
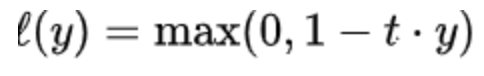
Multi-class Cross Entropy Loss
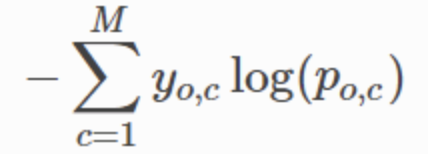
這里我們要區(qū)分Multi-class和Multi-label,如下圖:
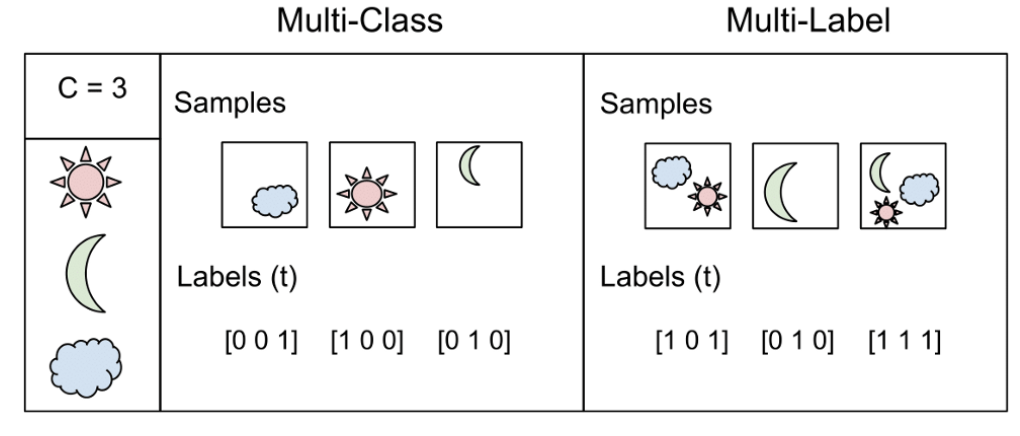
對于Multi-Label我們不能使用softmax,因?yàn)閟oftmax總是只強(qiáng)制一個(gè)類變?yōu)?,其他類變?yōu)?。因此,我們可以簡單地在所有輸出節(jié)點(diǎn)值上用sigmoid,預(yù)測每個(gè)類的概率。
Divergence LOSS (KL-Divergence)
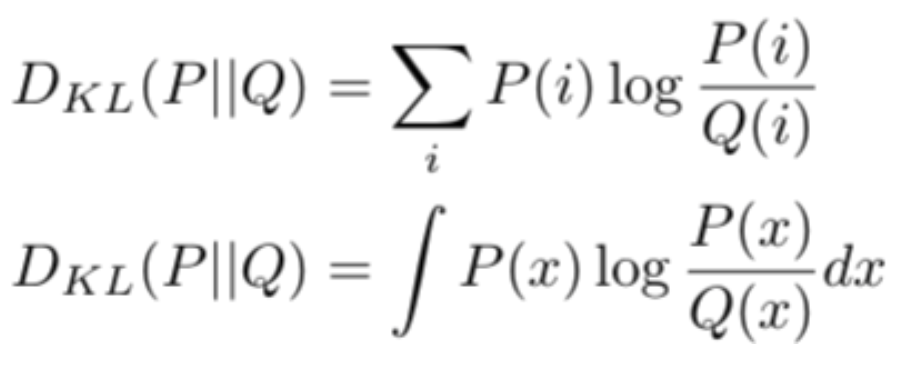
KL散度是一個(gè)分布與另一個(gè)分布的概率差異的度量,KL散度在功能上類似于多類交叉熵,KL散度不能用于距離函數(shù),因?yàn)樗皇菍ΨQ的。
Huber loss
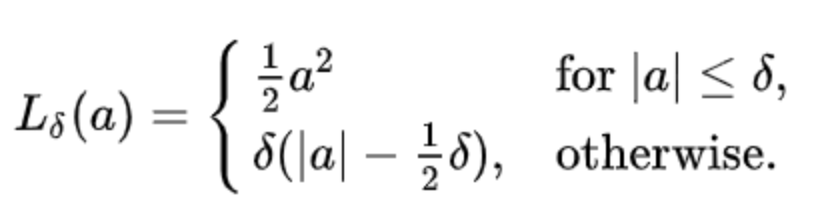
a為比較小的值,此函數(shù)是二次函數(shù);對于a為大值時(shí),此函數(shù)是線性函數(shù)。變量a通常是指殘差,即觀測值和預(yù)測值之間的差值。與平方誤差損失相比,Huber損失對數(shù)據(jù)中的異常值不那么敏感。使函數(shù)二次化的小誤差值是多少取決于“超參數(shù)”,??(delta),它可以調(diào)整。
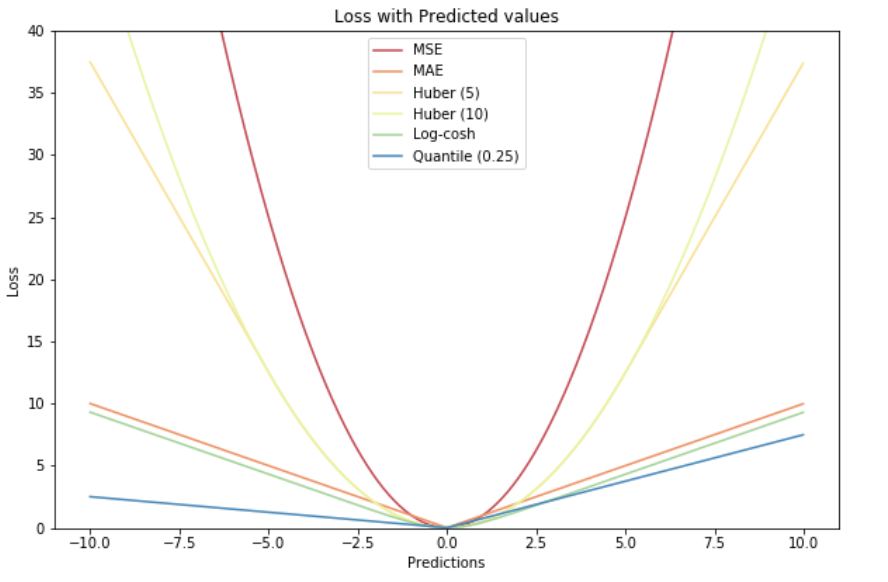
有的時(shí)候,我們的任務(wù)并不是回歸或分類,而是排序,下面介紹rank loss。
Rank Loss
排名損失用于不同的領(lǐng)域,任務(wù)和神經(jīng)網(wǎng)絡(luò)設(shè)置,如Siamese Nets或Triplet Nets。這就是為什么他們會(huì)有名稱,如Contrastive Loss, Margin Loss, Hinge Loss or Triplet Loss。
與其他損失函數(shù)(如交叉熵?fù)p失或均方誤差損失)不同,損失函數(shù)的目標(biāo)是學(xué)習(xí)直接預(yù)測給定輸入的一個(gè)標(biāo)簽、一個(gè)值或一組或多個(gè)值,rank loss的目標(biāo)是預(yù)測輸入之間的相對距離。這個(gè)任務(wù)通常被稱為度量學(xué)習(xí)。
rank loss在訓(xùn)練數(shù)據(jù)方面非常靈活:我們只需要得到數(shù)據(jù)點(diǎn)之間的相似性得分就可以使用它們。分?jǐn)?shù)可以是二元的(相似/不同)。例如,假設(shè)一個(gè)人臉驗(yàn)證數(shù)據(jù)集,我們知道哪些人臉圖像屬于同一個(gè)人(相似),哪些不屬于(不同)。利用rank loss,我們可以訓(xùn)練CNN來推斷兩張人臉圖像是否屬于同一個(gè)人。
為了使用rank loss,我們首先從兩個(gè)(或三個(gè))輸入數(shù)據(jù)點(diǎn)中提取特征,并得到每個(gè)特征點(diǎn)的嵌入表示。然后,我們定義一個(gè)度量函數(shù)來度量這些表示之間的相似性,例如歐幾里德距離。最后,我們訓(xùn)練特征提取器在輸入相似的情況下為兩個(gè)輸入產(chǎn)生相似的表示,或者在兩個(gè)輸入不同的情況下為兩個(gè)輸入產(chǎn)生距離表示。
Pairwise Ranking Loss
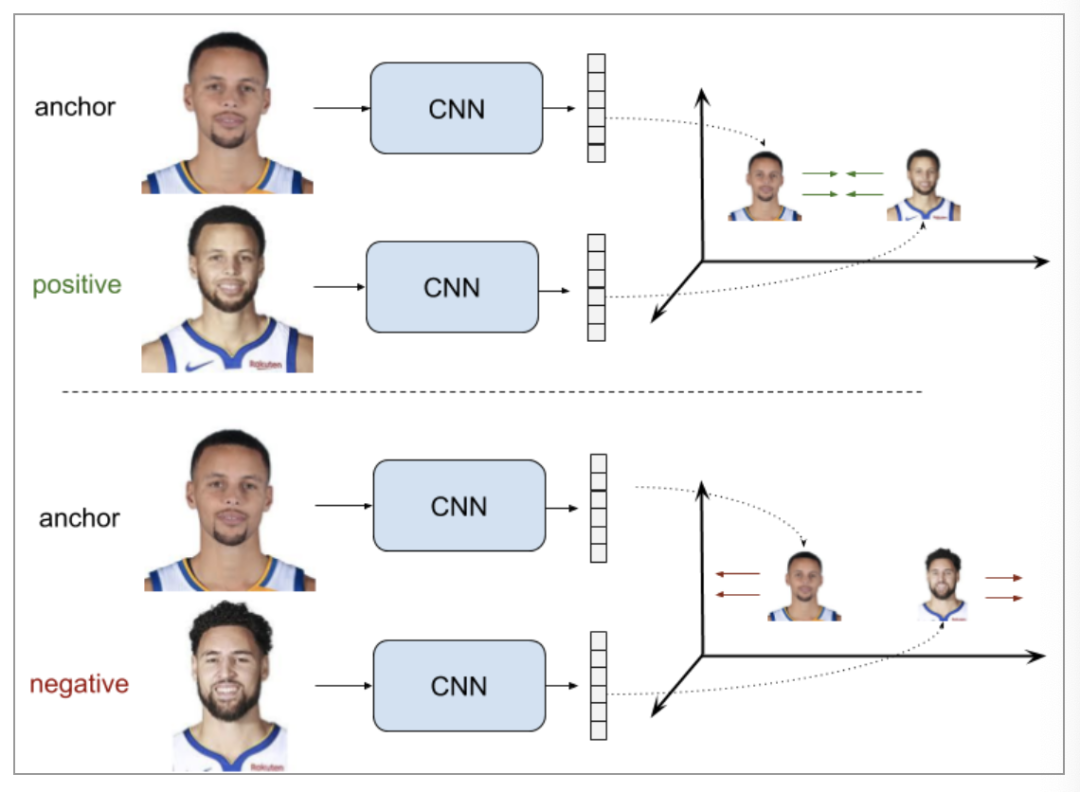
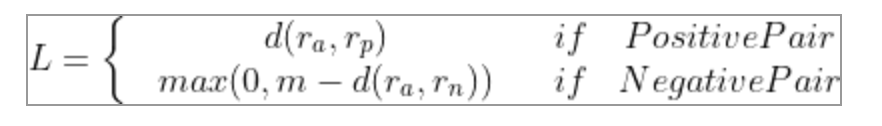
我們從上式可以看到,當(dāng)兩個(gè)人的描述的是一個(gè)人時(shí),他們嵌入表示距離大小就是loss,當(dāng)描述不是一個(gè)人時(shí),嵌入表示距離大于margin才不會(huì)產(chǎn)生loss。我們也可以把公式改寫為:
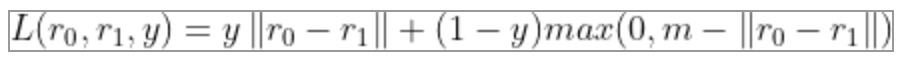
Triplet Ranking Loss
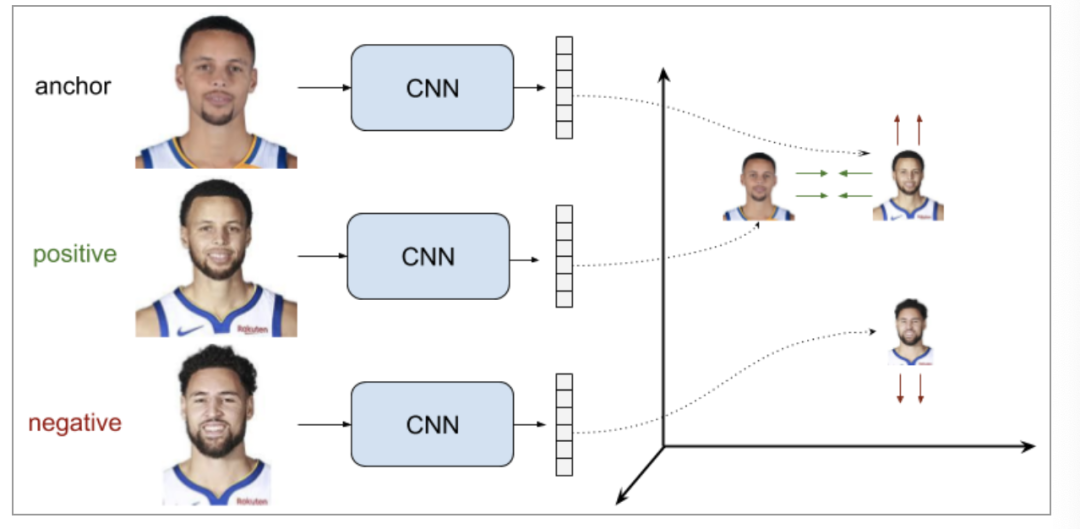
通過使用三組訓(xùn)練數(shù)據(jù)樣本(而不是成對樣本),這種設(shè)置優(yōu)于前者(同時(shí)優(yōu)化類內(nèi)距離和類間距),目標(biāo)就是使得錨點(diǎn)與負(fù)樣本距離顯著大于(由margin決定)與正樣本的距離,loss定義如下。
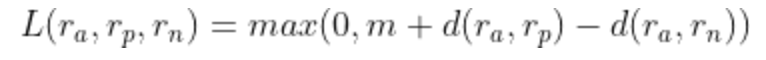
我們來分析一下這種損失的三種情況:
Easy Triplets: 相對于嵌入空間中的正樣本,負(fù)樣本已經(jīng)足夠遠(yuǎn)離錨定樣本。損失是0并且網(wǎng)絡(luò)參數(shù)不會(huì)更新。
Hard Triplets: 負(fù)樣本比正樣本更接近錨點(diǎn),損失是正的。
Semi-Hard Triplets:負(fù)樣本比正樣本離錨的距離遠(yuǎn),但距離不大于margin,所以損失仍然是正的。
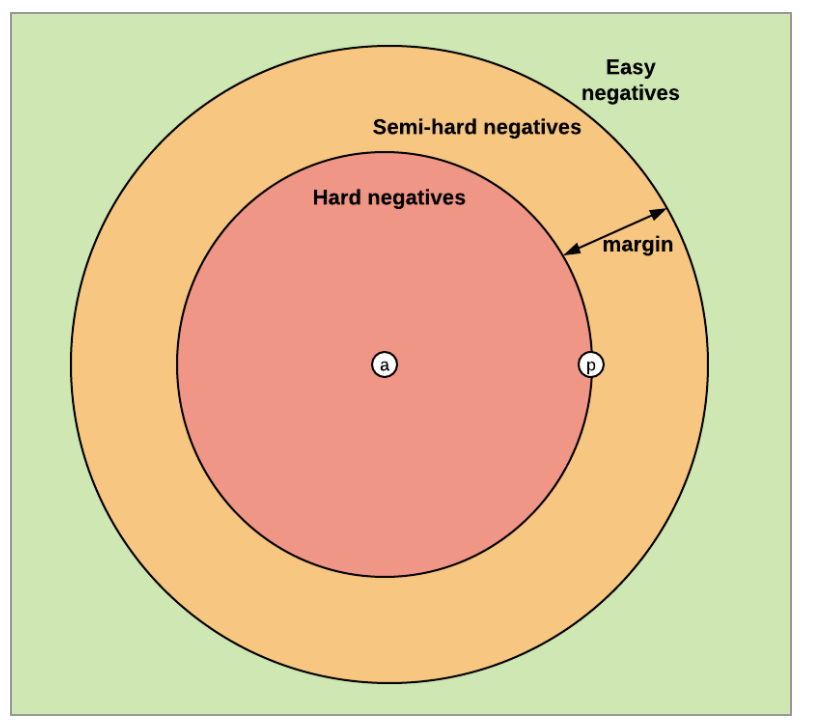
負(fù)樣本選擇:
在triplets loss訓(xùn)練過程中,負(fù)樣本選擇和三元祖樣本挖掘是非常重要的。選擇的策略對訓(xùn)練的效率和最終效果有很大的影響。一個(gè)很重要的點(diǎn)是,訓(xùn)練三元祖應(yīng)避免easy triplets,因?yàn)樗麄兯飚a(chǎn)生的loss是0,不能用于優(yōu)化模型。
樣本挖掘的第一種策略離線進(jìn)行三元組挖掘,這意味著三元組是在訓(xùn)練開始時(shí)定義的,或者是在每個(gè)epoch前。后來又提出了online triplet loss(在線三元組挖掘),即在訓(xùn)練過程中為每一個(gè)epoch定義三元組,從而提高了訓(xùn)練效率和性能。
需要注意的是,選擇負(fù)樣本的最佳方法是高度依賴于任務(wù)的。
Circle loss
在理解了triplet loss之后,我們終于可以開始研究circle loss:A Unified Perspective of Pair Similarity Optimization。Circle Loss 獲得了更靈活的優(yōu)化途徑及更明確的收斂目標(biāo),從而提高所學(xué)特征的鑒別能力。它使用同一個(gè)公式,在兩種基本學(xué)習(xí)范式,三項(xiàng)特征學(xué)習(xí)任務(wù)(人臉識別,行人再識別,細(xì)粒度圖像檢索),十個(gè)數(shù)據(jù)集上取得了極具競爭力的表現(xiàn)。
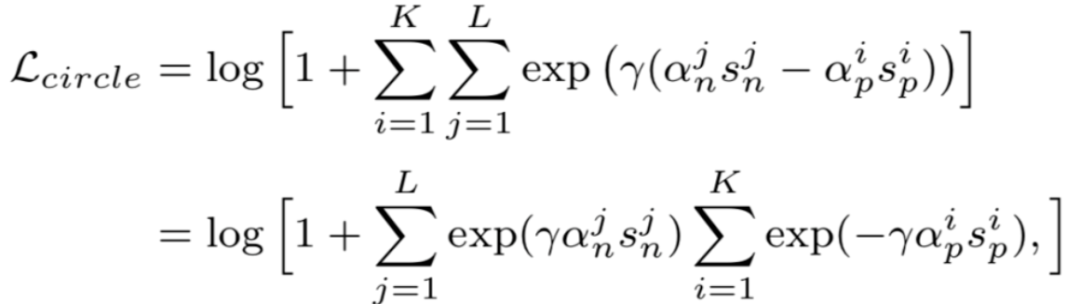
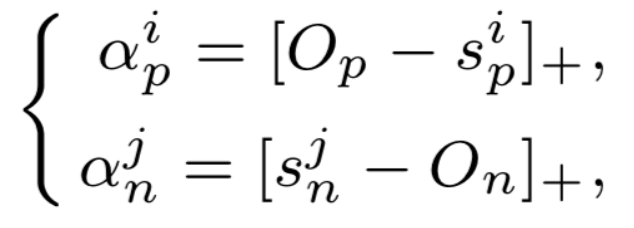
?------------------------------------------------
雙一流高校研究生團(tuán)隊(duì)創(chuàng)建,專注于計(jì)算機(jī)視覺原創(chuàng)并分享相關(guān)知識?
聞道有先后,術(shù)業(yè)有專攻,如是而已╮(╯_╰)╭