
一文看盡Pytorch之十九種損失函數(shù)
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達 
原文鏈接:https://blog.csdn.net/shanglianlm/article/details/85019768
01
criterion = LossCriterion() #構造函數(shù)有自己的參數(shù)loss = criterion(x, y) #調用標準時也有參數(shù)
02
2-1 L1范數(shù)損失 L1Loss
計算 output 和 target 之差的絕對值。
torch.nn.L1Loss(reduction='mean')參數(shù):
reduction-三個值,none: 不使用約簡;mean:返回loss和的平均值;sum:返回loss的和。默認:mean。
2-2 均方誤差損失 MSELoss
計算 output 和 target 之差的均方差。
torch.nn.MSELoss(reduction='mean')參數(shù):
reduction-三個值,none: 不使用約簡;mean:返回loss和的平均值;sum:返回loss的和。默認:mean。
2-3 交叉熵損失 CrossEntropyLoss
當訓練有 C 個類別的分類問題時很有效. 可選參數(shù) weight 必須是一個1維 Tensor, 權重將被分配給各個類別. 對于不平衡的訓練集非常有效。
在多分類任務中,經常采用 softmax 激活函數(shù)+交叉熵損失函數(shù),因為交叉熵描述了兩個概率分布的差異,然而神經網(wǎng)絡輸出的是向量,并不是概率分布的形式。所以需要 softmax激活函數(shù)將一個向量進行“歸一化”成概率分布的形式,再采用交叉熵損失函數(shù)計算 loss。

torch.nn.CrossEntropyLoss(weight=None, ignore_index=-100, reduction='mean')參數(shù):
weight (Tensor, optional) – 自定義的每個類別的權重. 必須是一個長度為 C 的 Tensor
ignore_index (int, optional) – 設置一個目標值, 該目標值會被忽略, 從而不會影響到 輸入的梯度。
reduction-三個值,none: 不使用約簡;mean:返回loss和的平均值;sum:返回loss的和。默認:mean。
2-4 KL 散度損失 KLDivLoss
計算 input 和 target 之間的 KL 散度。KL 散度可用于衡量不同的連續(xù)分布之間的距離, 在連續(xù)的輸出分布的空間上(離散采樣)上進行直接回歸時很有效.
torch.nn.KLDivLoss(reduction='mean')參數(shù):
reduction-三個值,none: 不使用約簡;mean:返回loss和的平均值;sum:返回loss的和。默認:mean。
2-5 二進制交叉熵損失 BCELoss
二分類任務時的交叉熵計算函數(shù)。用于測量重構的誤差, 例如自動編碼機. 注意目標的值 t[i] 的范圍為0到1之間.
torch.nn.BCELoss(weight=None, reduction='mean')參數(shù):
weight (Tensor, optional) – 自定義的每個 batch 元素的 loss 的權重. 必須是一個長度為 “nbatch” 的 的 Tensor
pos_weight(Tensor, optional) – 自定義的每個正樣本的 loss 的權重. 必須是一個長度 為 “classes” 的 Tensor
2-6 BCEWithLogitsLoss
BCEWithLogitsLoss損失函數(shù)把 Sigmoid 層集成到了 BCELoss 類中. 該版比用一個簡單的 Sigmoid 層和 BCELoss 在數(shù)值上更穩(wěn)定, 因為把這兩個操作合并為一個層之后, 可以利用 log-sum-exp 的 技巧來實現(xiàn)數(shù)值穩(wěn)定.
torch.nn.BCEWithLogitsLoss(weight=None, reduction='mean', pos_weight=None)參數(shù):
weight (Tensor, optional) – 自定義的每個 batch 元素的 loss 的權重. 必須是一個長度 為 “nbatch” 的 Tensor
pos_weight(Tensor, optional) – 自定義的每個正樣本的 loss 的權重. 必須是一個長度 為 “classes” 的 Tensor
2-7 MarginRankingLoss
torch.nn.MarginRankingLoss(margin=0.0, reduction='mean')對于 mini-batch(小批量) 中每個實例的損失函數(shù)如下:
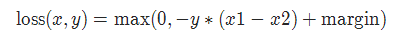
參數(shù):
margin:默認值0
2-8 HingeEmbeddingLoss
torch.nn.HingeEmbeddingLoss(margin=1.0, reduction='mean')對于 mini-batch(小批量) 中每個實例的損失函數(shù)如下:
參數(shù):

margin:默認值1
2-9 多標簽分類損失 MultiLabelMarginLoss
torch.nn.MultiLabelMarginLoss(reduction='mean')對于mini-batch(小批量) 中的每個樣本按如下公式計算損失:

2-10 平滑版L1損失 SmoothL1Loss
也被稱為 Huber 損失函數(shù)。
torch.nn.SmoothL1Loss(reduction='mean')
其中

2-11 2分類的logistic損失 SoftMarginLoss
torch.nn.SoftMarginLoss(reduction='mean')
2-12 多標簽 one-versus-all 損失 MultiLabelSoftMarginLoss
torch.nn.MultiLabelSoftMarginLoss(weight=None, reduction='mean')
2-13 cosine 損失 CosineEmbeddingLoss
torch.nn.CosineEmbeddingLoss(margin=0.0, reduction='mean')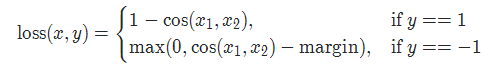
參數(shù):
margin:默認值0
2-14 多類別分類的hinge損失 MultiMarginLoss
torch.nn.MultiMarginLoss(p=1, margin=1.0, weight=None, reduction='mean')
參數(shù):
p=1或者2 默認值:1
margin:默認值1
2-15 三元組損失 TripletMarginLoss
torch.nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, swap=False, reduction='mean')
其中:

2-16 連接時序分類損失 CTCLoss
CTC連接時序分類損失,可以對沒有對齊的數(shù)據(jù)進行自動對齊,主要用在沒有事先對齊的序列化數(shù)據(jù)訓練上。比如語音識別、ocr識別等等。
torch.nn.CTCLoss(blank=0, reduction='mean')參數(shù):
reduction-三個值,none: 不使用約簡;mean:返回loss和的平均值;sum:返回loss的和。默認:mean。
2-17 負對數(shù)似然損失 NLLLoss
負對數(shù)似然損失. 用于訓練 C 個類別的分類問題.
torch.nn.NLLLoss(weight=None, ignore_index=-100, reduction='mean')參數(shù):
weight (Tensor, optional) – 自定義的每個類別的權重. 必須是一個長度為 C 的 Tensor
ignore_index (int, optional) – 設置一個目標值, 該目標值會被忽略, 從而不會影響到 輸入的梯度.
2-18 NLLLoss2d
對于圖片輸入的負對數(shù)似然損失. 它計算每個像素的負對數(shù)似然損失.
torch.nn.NLLLoss2d(weight=None, ignore_index=-100, reduction='mean')參數(shù):
weight (Tensor, optional) – 自定義的每個類別的權重. 必須是一個長度為 C 的 Tensor
reduction-三個值,none: 不使用約簡;mean:返回loss和的平均值;sum:返回loss的和。默認:mean。
2-19 PoissonNLLLoss
目標值為泊松分布的負對數(shù)似然損失
torch.nn.PoissonNLLLoss(log_input=True, full=False, eps=1e-08, reduction='mean')參數(shù):
log_input (bool, optional) – 如果設置為 True , loss 將會按照公 式 exp(input) - target * input 來計算, 如果設置為 False , loss 將會按照 input - target * log(input+eps) 計算.
full (bool, optional) – 是否計算全部的 loss, i. e. 加上 Stirling 近似項 target * log(target) - target + 0.5 * log(2 * pi * target).
eps (float, optional) – 默認值: 1e-8
參考資料
http://www.voidcn.com/article/p-rtzqgqkz-bpg.html
下載1:OpenCV-Contrib擴展模塊中文版教程
在「小白學視覺」公眾號后臺回復:擴展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標跟蹤、生物視覺、超分辨率處理等二十多章內容。
下載2:Python視覺實戰(zhàn)項目52講
在「小白學視覺」公眾號后臺回復:Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學校計算機視覺。
下載3:OpenCV實戰(zhàn)項目20講
在「小白學視覺」公眾號后臺回復:OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現(xiàn)20個實戰(zhàn)項目,實現(xiàn)OpenCV學習進階。
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關微信群。請勿在群內發(fā)送廣告,否則會請出群,謝謝理解~