
計算機視覺:圖像檢測和圖像分割有什么區(qū)別?

人工智能對于圖像處理有不同的任務。在本文中,我將介紹目標檢測和圖像分割之間的區(qū)別。
在這兩個任務中,我們都希望找到圖像中某些感興趣的項目的位置。例如,我們可以有一組安全攝像頭照片,在每張照片上,我們想要識別照片中所有人的位置。
通常有兩種方法可以用于此:目標檢測(Object Detection)和圖像分割(Image Segmentation)。
目標檢測-預測包圍盒
當我們說到物體檢測時,我們通常會說到邊界盒。這意味著我們的圖像處理將在我們的圖片中識別每個人周圍的矩形。
邊框通常由左上角的位置(2 個坐標)和寬度和高度(以像素為單位)定義。
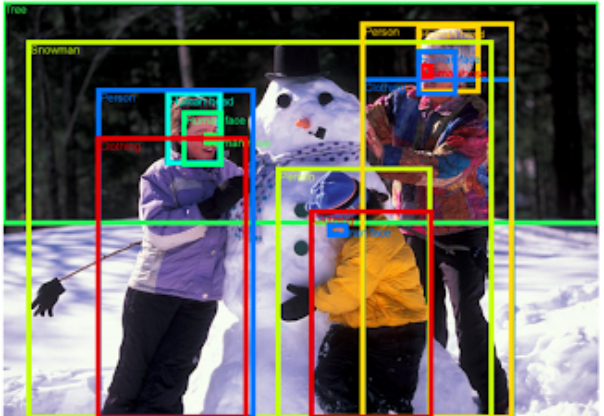
來自開放圖像數(shù)據(jù)集的注釋圖像。家庭堆雪人,來自 mwvchamber。在CC BY 2.0 許可下使用的圖像。
如何理解目標檢測 如果我們回到任務:識別圖片上的所有人,則可以理解通過邊界框進行對象檢測的邏輯。 我們首先想到的解決方案是將圖像切成小塊,然后在每個子圖像上應用圖像分類,以區(qū)別該圖像是否是人類。對單個圖像進行分類是一項較容易的任務,并且是對象檢測的一項,因此,他們采用了這種分步方法。 當前,YOLO模型(You Only Look Once)是解決此問題的偉大發(fā)明。YOLO模型的開發(fā)人員已經構建了一個神經網絡,該神經網絡能夠立即執(zhí)行整個邊界框方法! | |
當前用于目標檢測的最佳模型
|
目標分割-預測掩模
一步一步地掃描圖像的邏輯替代方法是遠離畫框,而是逐像素地注釋圖像。
如果你這樣做,你將會有一個更詳細的模型,它基本上是輸入圖像的一個轉換。
來自開放圖像數(shù)據(jù)集的注釋圖像。家庭堆雪人,來自 mwvchamber。在CC BY 2.0 許可下使用的圖像。
如何理解圖像分割 這個想法很基本:即使在掃描產品上的條形碼時,也可以應用一種算法來轉換輸入信息(通過應用各種過濾器),這樣,除了條形碼序列以外的所有信息在最終圖像中都不可見。  這是在圖像上定位條形碼的基本方法,但與在圖像分割中所發(fā)生的情況類似。 圖像分割的返回格式稱為掩碼:與原始圖像大小相同的圖像,但是對于每個像素,它只有一個布爾值來指示對象是否存在。 如果我們允許多個類別,它就會變得更加復雜:例如,它可以將一個海灘景觀分為三類:空氣、海洋和沙子。 | |
當下圖像分割的最佳模型
|
比較總結
對象檢測
| |
圖像分割
|
 End
End
聲明:部分內容來源于網絡,僅供讀者學術交流之目的。文章版權歸原作者所有。如有不妥,請聯(lián)系刪除。