
數(shù)據(jù)湖 | Apache Hudi 設(shè)計(jì)與架構(gòu)最強(qiáng)解讀
點(diǎn)擊上方藍(lán)色字體,選擇“設(shè)為星標(biāo)”




本文將介紹Apache Hudi的基本概念、設(shè)計(jì)以及總體基礎(chǔ)架構(gòu)。
1. 簡(jiǎn)介
Apache Hudi(簡(jiǎn)稱:Hudi)允許您在現(xiàn)有的hadoop兼容存儲(chǔ)之上存儲(chǔ)大量數(shù)據(jù),同時(shí)提供兩種原語,使得除了經(jīng)典的批處理之外,還可以在數(shù)據(jù)湖上進(jìn)行流處理。
這兩種原語分別是:
1)Update/Delete記錄:Hudi使用細(xì)粒度的文件/記錄級(jí)別索引來支持Update/Delete記錄,同時(shí)還提供寫操作的事務(wù)保證。查詢會(huì)處理最后一個(gè)提交的快照,并基于此輸出結(jié)果。
2)變更流:Hudi對(duì)獲取數(shù)據(jù)變更提供了一流的支持:可以從給定的時(shí)間點(diǎn)獲取給定表中已updated/inserted/deleted的所有記錄的增量流,并解鎖新的查詢姿勢(shì)(類別)。
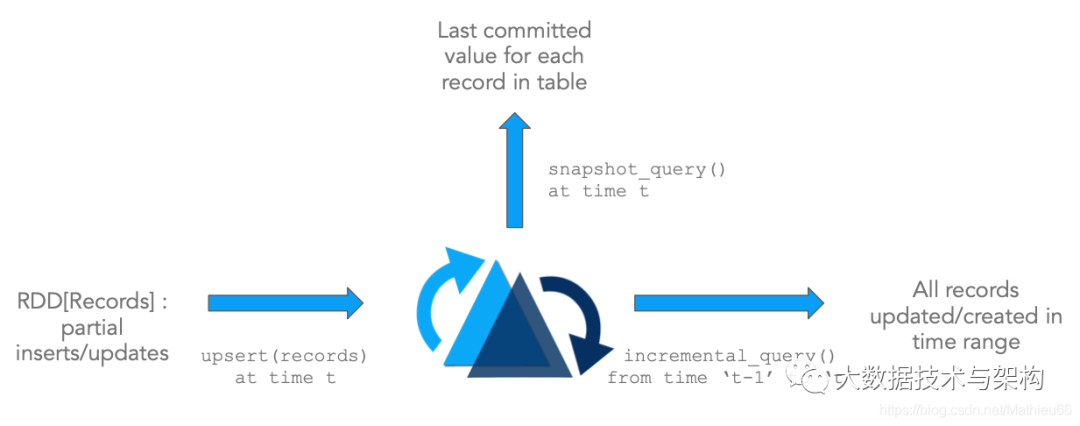
這些原語緊密結(jié)合,解鎖了基于DFS抽象的流/增量處理能力。如果您熟悉流處理,那么這和從kafka主題消費(fèi)事件,然后使用狀態(tài)存儲(chǔ)逐步累加中間結(jié)果類似。
在架構(gòu)上會(huì)有以下幾點(diǎn)優(yōu)勢(shì):
1)效率的提升:攝取數(shù)據(jù)通常需要處理更新、刪除以及強(qiáng)制唯一鍵約束。然而,由于缺乏像Hudi這樣能對(duì)這些功能提供標(biāo)準(zhǔn)支持的系統(tǒng),數(shù)據(jù)工程師們通常會(huì)采用大批量的作業(yè)來重新處理一整天的事件,或者每次運(yùn)行都重新加載整個(gè)上游數(shù)據(jù)庫(kù),從而導(dǎo)致大量的計(jì)算資源浪費(fèi)。由于Hudi支持記錄級(jí)更新,它通過只處理有變更的記錄并且只重寫表中已更新/刪除的部分,而不是重寫整個(gè)表分區(qū)甚至整個(gè)表,為這些操作帶來一個(gè)數(shù)量級(jí)的性能提升。
2)更快的ETL/派生Pipelines:從外部系統(tǒng)攝入數(shù)據(jù)后,下一步需要使用Apache Spark/Apache Hive或者任何其他數(shù)據(jù)處理框架來ETL這些數(shù)據(jù)用于諸如數(shù)據(jù)倉(cāng)庫(kù)、機(jī)器學(xué)習(xí)或者僅僅是數(shù)據(jù)分析等一些應(yīng)用場(chǎng)景。通常,這些處理再次依賴以代碼或SQL表示的批處理作業(yè),這些作業(yè)將批量處理所有輸入數(shù)據(jù)并重新計(jì)算所有輸出結(jié)果。通過使用增量查詢而不是快照查詢來查詢一個(gè)或多個(gè)輸入表,可以大大加速此類數(shù)據(jù)管道,從而再次導(dǎo)致像上面一樣僅處理來自上游表的增量更改,然后upsert或者delete目標(biāo)派生表。
3)獲取新鮮數(shù)據(jù):減少資源還能獲取性能上的提升并不是常見的事。畢竟我們通常會(huì)使用更多的資源(例如內(nèi)存)來提升性能(例如查詢延遲)。通過從根本上擺脫數(shù)據(jù)集的傳統(tǒng)管理方式,Hudi將批量處理增量化的一個(gè)很好的副作用是:與以前的數(shù)據(jù)湖相比,pipeline運(yùn)行的時(shí)間會(huì)更短,數(shù)據(jù)交付會(huì)更快。
4)統(tǒng)一存儲(chǔ):基于以上三個(gè)優(yōu)點(diǎn),在現(xiàn)有數(shù)據(jù)湖之上進(jìn)行更快速、更輕量的處理意味著僅出于訪問近實(shí)時(shí)數(shù)據(jù)的目的時(shí)不再需要專門的存儲(chǔ)或數(shù)據(jù)集市。
2. 設(shè)計(jì)原則
2.1 流式讀/寫
Hudi是從零設(shè)計(jì)的,用于從大型數(shù)據(jù)集輸入和輸出數(shù)據(jù),并借鑒了數(shù)據(jù)庫(kù)設(shè)計(jì)的原理。為此,Hudi提供了索引實(shí)現(xiàn),可以將記錄的鍵快速映射到其所在的文件位置。同樣,對(duì)于流式輸出數(shù)據(jù),Hudi通過其特殊列添加并跟蹤記錄級(jí)別的元數(shù)據(jù),從而可以提供所有發(fā)生變更的精確增量流。
2.2 自管理
Hudi注意到用戶可能對(duì)數(shù)據(jù)新鮮度(寫友好)與查詢性能(讀/查詢友好)有不同的期望,并支持了三種查詢類型,這些類型提供實(shí)時(shí)快照,增量流以及稍早的純列數(shù)據(jù)。在每一步,Hudi都努力做到自我管理(例如自動(dòng)優(yōu)化編寫程序的并行性,保持文件大小)和自我修復(fù)(例如:自動(dòng)回滾失敗的提交),即使這樣做會(huì)稍微增加運(yùn)行時(shí)成本(例如:在內(nèi)存中緩存輸入數(shù)據(jù)已分析工作負(fù)載)。如果沒有這些內(nèi)置的操作杠桿/自我管理功能,這些大型流水線的運(yùn)營(yíng)成本通常會(huì)翻倍。
2.3 萬物皆日志:
Hudi還具有 append only、云數(shù)據(jù)友好的設(shè)計(jì),該設(shè)計(jì)使Hudi無縫管理所有云提供商傷的數(shù)據(jù),并實(shí)現(xiàn)了日志結(jié)構(gòu)化存儲(chǔ)系統(tǒng)的原理。
2.4 鍵-值數(shù)據(jù)模型
在寫方面,Hudi表被建模為鍵值對(duì)數(shù)據(jù)集,其中每條記錄都有一個(gè)唯一的記錄鍵。此外,一個(gè)記錄鍵還可以包括分區(qū)路徑,在該路徑下,可以對(duì)記錄進(jìn)行分區(qū)和存儲(chǔ)。這通常有助于減少索引查詢的搜索空間。
3. 表設(shè)計(jì)
了解了Hudi項(xiàng)目的關(guān)鍵技術(shù)動(dòng)機(jī)后,現(xiàn)在讓我們更深入地研究Hudi系統(tǒng)本身的設(shè)計(jì)。在較高的層次上,用于寫Hudi表的組件使用了一種受支持的方式嵌入到Apache Spark作業(yè)中,它會(huì)在支持DFS的存儲(chǔ)上生成代表Hudi表的一組文件。然后,在具有一定保證的情況下,諸如Apache Spark、Presto、Apache Hive之類的查詢引擎可以查詢?cè)摫怼?/p>
Hudi表的三個(gè)主要組件:
1)有序的時(shí)間軸元數(shù)據(jù)。類似于數(shù)據(jù)庫(kù)事務(wù)日志。
2)分層布局的數(shù)據(jù)文件:實(shí)際寫入表中的數(shù)據(jù)。
3)索引(多種實(shí)現(xiàn)方式):映射包含指定記錄的數(shù)據(jù)集。
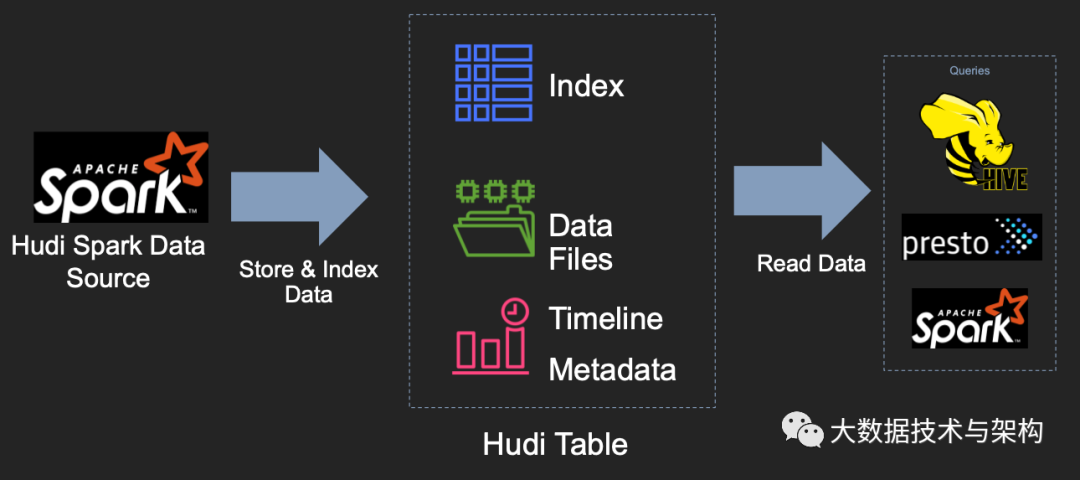
Hudi提供了以下功能來對(duì)基礎(chǔ)數(shù)據(jù)進(jìn)行寫入、查詢,這使其成為大型數(shù)據(jù)湖的重要模塊:
1)支持快速,可插拔索引的upsert();
2)高效、只掃描新數(shù)據(jù)的增量查詢;
3)原子性的數(shù)據(jù)發(fā)布和回滾,支持恢復(fù)的Savepoint;
4)使用mvcc風(fēng)格設(shè)計(jì)的讀和寫快照隔離;
5)使用統(tǒng)計(jì)信息管理文件大小;
6)已有記錄update/delta的自管理壓縮;
7)審核數(shù)據(jù)修改的時(shí)間軸元數(shù)據(jù);
8)滿足GDPR(通用數(shù)據(jù)保護(hù)條例)、數(shù)據(jù)刪除功能。
3.1 時(shí)間軸
在其核心,Hudi維護(hù)了一條包含在不同的即時(shí)時(shí)間(instant time)對(duì)數(shù)據(jù)集做的所有instant操作的timeline,從而提供表的即時(shí)視圖,同時(shí)還有效的支持按到達(dá)順序進(jìn)行數(shù)據(jù)檢索。時(shí)間軸類似于數(shù)據(jù)庫(kù)的redo/transaction日志,由一組時(shí)間軸實(shí)例組成。Hudi保證在時(shí)間軸上執(zhí)行的操作的原子性和基于即時(shí)時(shí)間的時(shí)間軸一致性。時(shí)間軸被實(shí)現(xiàn)為表基礎(chǔ)路徑下.hoodie元數(shù)據(jù)文件夾下的一組文件。具體來說,最新的instant被保存為單個(gè)文件,而較舊的instant被存檔到時(shí)間軸歸檔文件夾中,以限制writers和queries列出的文件數(shù)量。
一個(gè)Hudi 時(shí)間軸instant由下面幾個(gè)組件構(gòu)成:
1)操作類型:對(duì)數(shù)據(jù)集執(zhí)行的操作類型;
2)即時(shí)時(shí)間:即時(shí)時(shí)間通常是一個(gè)時(shí)間戳(例如:20190117010349),該時(shí)間戳按操作開始時(shí)間的順序單調(diào)增加;
3)即時(shí)狀態(tài):instant的當(dāng)前狀態(tài);
每個(gè)instant都有avro或者json格式的元數(shù)據(jù)信息,詳細(xì)的描述了該操作的狀態(tài)以及這個(gè)即時(shí)時(shí)刻instant的狀態(tài)。
關(guān)鍵的Instant操作類型有:
1)COMMIT:一次提交表示將一組記錄原子寫入到數(shù)據(jù)集中;
2)CLEAN: 刪除數(shù)據(jù)集中不再需要的舊文件版本的后臺(tái)活動(dòng);
3)DELTA_COMMIT:將一批記錄原子寫入到MergeOnRead存儲(chǔ)類型的數(shù)據(jù)集中,其中一些/所有數(shù)據(jù)都可以只寫到增量日志中;
4)COMPACTION: 協(xié)調(diào)Hudi中差異數(shù)據(jù)結(jié)構(gòu)的后臺(tái)活動(dòng),例如:將更新從基于行的日志文件變成列格式。在內(nèi)部,壓縮表現(xiàn)為時(shí)間軸上的特殊提交;
5)ROLLBACK: 表示提交/增量提交不成功且已回滾,刪除在寫入過程中產(chǎn)生的所有部分文件;
6)SAVEPOINT: 將某些文件組標(biāo)記為"已保存",以便清理程序不會(huì)將其刪除。在發(fā)生災(zāi)難/數(shù)據(jù)恢復(fù)的情況下,它有助于將數(shù)據(jù)集還原到時(shí)間軸上的某個(gè)點(diǎn);
任何給定的即時(shí)都會(huì)處于以下狀態(tài)之一:
1)REQUESTED:表示已調(diào)度但尚未初始化;
2)INFLIGHT: 表示當(dāng)前正在執(zhí)行該操作;
3)COMPLETED: 表示在時(shí)間軸上完成了該操作.
3.2 數(shù)據(jù)文件
Hudi將表組織成DFS上基本路徑下的文件夾結(jié)構(gòu)中。如果表是分區(qū)的,則在基本路徑下還會(huì)有其他的分區(qū),這些分區(qū)是包含該分區(qū)數(shù)據(jù)的文件夾,與Hive表非常類似。每個(gè)分區(qū)均由相對(duì)于基本路徑的分區(qū)路徑唯一標(biāo)識(shí)。在每個(gè)分區(qū)內(nèi),文件被組織成文件組,由文件ID唯一標(biāo)識(shí)。每個(gè)文件組包含一個(gè)或多個(gè)文件片,每個(gè)文件片都包含一個(gè)base file(某個(gè)提交/壓縮即時(shí)時(shí)間生成的列式存儲(chǔ)文件,例如:parquet文件)以及一組日志文件(包含自生成基本文件以來對(duì)基本文件的插入/更新)。Hudi采用了MVCC設(shè)計(jì),壓縮操作會(huì)將日志和基本文件合并以產(chǎn)生新的文件片,而清理操作則將未使用的/較舊的文件片刪除以回收DFS上的空間。
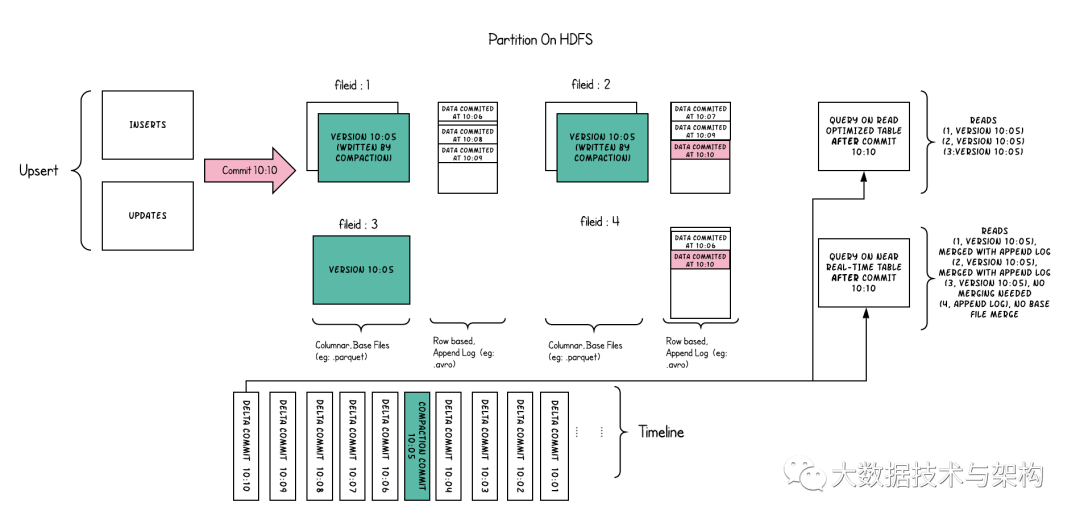
3.3 索引
Hudi通過索引機(jī)制提供高效的upsert操作,該機(jī)制會(huì)將一個(gè)記錄鍵+分區(qū)路徑組合一致性的映射到一個(gè)文件ID.這個(gè)記錄鍵和文件組/文件ID之間的映射自記錄被寫入文件組開始就不會(huì)再改變。簡(jiǎn)而言之,這個(gè)映射文件組包含了一組文件的所有版本。Hudi當(dāng)前提供了3種索引實(shí)現(xiàn)(HBaseIndex,、HoodieBloomIndex(HoodieGlobalBloomIndex)、InMemoryHashIndex)來映射一個(gè)記錄鍵到包含該記錄的文件ID。這將使我們無需掃描表中的每條記錄,就可顯著提高upsert速度。
Hudi索引可以根據(jù)其查詢分區(qū)記錄的能力進(jìn)行分類:
1)全局索引:不需要分區(qū)信息即可查詢記錄鍵映射的文件ID。比如,寫程序可以傳入null或者任何字符串作為分區(qū)路徑(partitionPath),但索引仍然會(huì)查找到該記錄的位置。全局索引在記錄鍵在整張表中保證唯一的情況下非常有用,但是查詢的消耗隨著表的大小函數(shù)式增加。
2)非全局索引:與全局索引不同,非全局索引依賴分區(qū)路徑(partitionPath),對(duì)于給定的記錄鍵,它只會(huì)在給定分區(qū)路徑下查找該記錄。這比較適合總是同時(shí)生成分區(qū)路徑和記錄鍵的場(chǎng)景,同時(shí)還能享受到更好的擴(kuò)展性,因?yàn)椴樵兯饕南闹慌c寫入到該分區(qū)下數(shù)據(jù)集有關(guān)系。
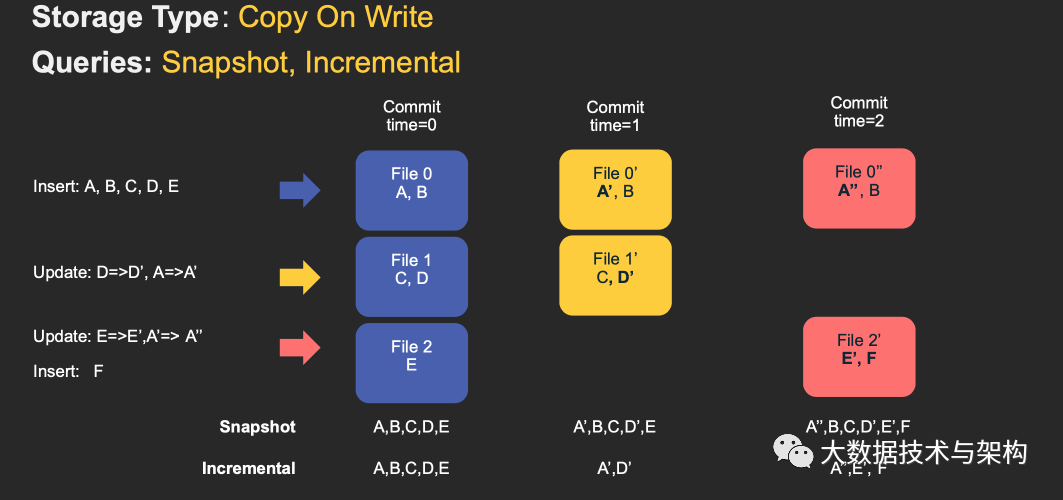
4.1 寫時(shí)復(fù)制(CopyOnWrite)表
COW表寫的時(shí)候數(shù)據(jù)直接寫入basefile,(parquet)不寫log文件。所以COW表的文件片只包含basefile(一個(gè)parquet文件構(gòu)成一個(gè)文件片)。
這種的存儲(chǔ)方式的Spark DAG相對(duì)簡(jiǎn)單。關(guān)鍵目標(biāo)是是使用partitioner將tagged Hudi記錄RDD(所謂的tagged是指已經(jīng)通過索引查詢,標(biāo)記每條輸入記錄在表中的位置)分成一些列的updates和inserts.為了維護(hù)文件大小,我們先對(duì)輸入進(jìn)行采樣,獲得一個(gè)工作負(fù)載profile,這個(gè)profile記錄了輸入記錄的insert和update、以及在分區(qū)中的分布等信息。把數(shù)據(jù)重新打包:
1)對(duì)于updates, 該文件ID的最新版本都將被重寫一次,并對(duì)所有已更改的記錄使用新值;
2)對(duì)于inserts.記錄首先打包到每個(gè)分區(qū)路徑中的最小文件中,直到達(dá)到配置的最大大小。之后的所有剩余記錄將再次打包到新的文件組,新的文件組也會(huì)滿足最大文件大小要求。
4.2 讀時(shí)合并(MergeOnRead)表
MOR表寫數(shù)據(jù)時(shí),記錄首先會(huì)被快速的寫進(jìn)日志文件,稍后會(huì)使用時(shí)間軸上的壓縮操作將其與基礎(chǔ)文件合并。根據(jù)查詢是讀取日志中的合并快照流還是變更流,還是僅讀取未合并的基礎(chǔ)文件,MOR表支持多種查詢類型。
在高層次上,MOR writer在讀取數(shù)據(jù)時(shí)會(huì)經(jīng)歷與COW writer 相同的階段。這些更新將追加到最新文件篇的最新日志文件中,而不會(huì)合并。對(duì)于insert,Hudi支持兩種模式:
1)插入到日志文件:有可索引日志文件的表會(huì)執(zhí)行此操作(HBase索引);
2)插入parquet文件:沒有索引文件的表(例如布隆索引)
與寫時(shí)復(fù)制(COW)一樣,對(duì)已標(biāo)記位置的輸入記錄進(jìn)行分區(qū),以便將所有發(fā)往相同文件id的upserts分到一組。這批upsert會(huì)作為一個(gè)或多個(gè)日志塊寫入日志文件。Hudi允許客戶端控制日志文件大小。對(duì)于寫時(shí)復(fù)制(COW)和讀時(shí)合并(MOR)writer來說,Hudi的WriteClient是相同的。幾輪數(shù)據(jù)的寫入將會(huì)累積一個(gè)或多個(gè)日志文件。這些日志文件與基本的parquet文件(如有)一起構(gòu)成一個(gè)文件片,而這個(gè)文件片代表該文件的一個(gè)完整版本。
這種表是用途最廣、最高級(jí)的表。為寫(可以指定不同的壓縮策略,吸收突發(fā)寫流量)和查詢(例如權(quán)衡數(shù)據(jù)的新鮮度和查詢性能)提供了很大的靈活性。同時(shí)它包含一個(gè)學(xué)習(xí)曲線,以便在操作上掌控他。

5. 寫設(shè)計(jì)
5.1 寫
了解Hudi數(shù)據(jù)源或者deltastreamer工具提供的3種不同寫操作以及如何最好的利用他們可能會(huì)有所幫助。這些操作可以在對(duì)數(shù)據(jù)集發(fā)出的每個(gè)commit/delta commit中進(jìn)行選擇/更改。
1)upsert操作:這是默認(rèn)操作,在該操作中,首先通過查詢索引將數(shù)據(jù)記錄標(biāo)記為插入或更新,然后再運(yùn)行試探法確定如何最好地將他們打包到存儲(chǔ),以對(duì)文件大小進(jìn)行優(yōu)化,最終將記錄寫入。對(duì)于諸如數(shù)據(jù)庫(kù)更改捕獲之類的用例,建議在輸入幾乎肯定包含更新的情況下使用此操作。
2)insert操作:與upsert相比,insert操作也會(huì)運(yùn)行試探法確定打包方式,優(yōu)化文件大小,但會(huì)完全跳過索引查詢。因此對(duì)于諸如日志重復(fù)數(shù)據(jù)刪除(結(jié)合下面提到的過濾重復(fù)項(xiàng)選項(xiàng))的用例而言,它比upsert的速度快得多。這也適用于數(shù)據(jù)集可以容忍重復(fù)項(xiàng),但只需要Hudi具有事務(wù)性寫/增量拉取/存儲(chǔ)管理功能的用例。
3)bulk insert操作:upsert 和insert操作都會(huì)將輸入記錄保留在內(nèi)存中,以賈逵愛存儲(chǔ)啟發(fā)式計(jì)算速度,因此對(duì)于最初加載/引導(dǎo)Hudi數(shù)據(jù)集的用例而言可能會(huì)很麻煩。Bulk insert提供了與insert相同的語義,同時(shí)實(shí)現(xiàn)了基于排序的數(shù)據(jù)寫入算法,該算法可以很好的擴(kuò)展數(shù)百TB的初始負(fù)載。但是這只是在調(diào)整文件大小方面進(jìn)行的最大努力,而不是像insert/update那樣保證文件大小。
5.2 壓縮
壓縮是一個(gè) instant操作,它將一組文件片作為輸入,將每個(gè)文件切片中的所有日志文件與其basefile文件(parquet文件)合并,以生成新的壓縮文件片,并寫為時(shí)間軸上的一個(gè)commit。壓縮僅適用于讀時(shí)合并(MOR)表類型,并且由壓縮策略(默認(rèn)選擇具有最大未壓縮日志的文件片)決定選擇要進(jìn)行壓縮的文件片。這個(gè)壓縮策略會(huì)在每個(gè)寫操作之后評(píng)估。
從高層次上講,壓縮有兩種方式:
1)同步壓縮:這里的壓縮由寫程序進(jìn)程本身在每次寫入之后同步執(zhí)行的,即直到壓縮完成后才能開始下一個(gè)寫操作。就操作而言,這個(gè)是最簡(jiǎn)單的,因?yàn)闊o需安排單獨(dú)的壓縮過程,但保證的數(shù)據(jù)新鮮度最低。不過,如果可以在每次寫操作中壓縮最新的表分區(qū),同時(shí)又能延遲遲到/較舊分區(qū)的壓縮,這種方式仍然非常有用。
2)異步壓縮:使用這種方式,壓縮過程可以與表的寫操作同時(shí)異步運(yùn)行。這樣具有明顯的好處,即壓縮不會(huì)阻塞下一批數(shù)據(jù)寫入,從而產(chǎn)生近實(shí)時(shí)的數(shù)據(jù)新鮮度。Hudi DeltaStreamer之類的工具支持邊界的連續(xù)模式,其中的壓縮和寫入操作就是以這種方式在單個(gè)Spark運(yùn)行時(shí)集群中進(jìn)行的。
5.3 清理
清理是一項(xiàng)基本的即時(shí)操作,其執(zhí)行的目的時(shí)刪除舊的文件片,并限制表占用的存儲(chǔ)空間。清理會(huì)在每次寫操作之后自動(dòng)執(zhí)行,并利用時(shí)間軸服務(wù)器上緩存的時(shí)間軸元數(shù)據(jù)來避免掃描整個(gè)表來評(píng)估清理時(shí)機(jī)。
Hudi支持兩種清理方式:
1)按commits / deltacommits清理:這是增量查詢中最常見且必須使用的模式。以這種方式,Cleaner會(huì)保留最近N次commit/delta commit提交中寫入的所有文件切片,從而有效提供在任何即時(shí)范圍內(nèi)進(jìn)行增量查詢的能力。盡管這對(duì)于增量查詢很有幫助,但由于保留了配置范圍內(nèi)所有版本的文件片,因此,在某些高寫入負(fù)載的場(chǎng)景下可能需要更大的存儲(chǔ)空間。
2)按保留的文件片清理:這是一種更為簡(jiǎn)單的清理方式,這里我們僅保存每個(gè)文件組中的最后N個(gè)文件片。諸如Apache Hive之類的某些查詢引擎會(huì)處理非常大的查詢,這些查詢可能需要幾個(gè)小時(shí)才能完成,在這種情況下,將N設(shè)置為足夠大以至于不會(huì)刪除查詢?nèi)匀豢梢栽L問的文件片是很有用的。
此外,清理操作會(huì)保證每個(gè)文件組下面會(huì)一直只有一個(gè)文件片(最新的一片)。
5.4 DFS訪問優(yōu)化
Hudi還對(duì)表中存儲(chǔ)的數(shù)據(jù)執(zhí)行了幾種秘鑰存儲(chǔ)管理功能。在DFS上存儲(chǔ)數(shù)據(jù)的關(guān)鍵是管理文件大小和技術(shù)以及回收存儲(chǔ)空間。例如,HDFS在處理小文件問題上臭名昭著--在NameNode上施加內(nèi)存/RPC壓力,可能破壞整個(gè)集群的穩(wěn)定性。通常,查詢引擎可在適當(dāng)大小的列文件上提供更好的性能,因?yàn)樗鼈兛梢杂行У財(cái)備N獲取列統(tǒng)計(jì)信息等的成本。即使在某些云數(shù)據(jù)存儲(chǔ)上,列出包含大量小文件的目錄也會(huì)產(chǎn)生成本。
下面是一些Hudi高效寫,管理數(shù)據(jù)存儲(chǔ)的方法:
1)小文件處理特性會(huì)剖析輸入的工作負(fù)載,并將內(nèi)容分配到現(xiàn)有的文件組,而不是創(chuàng)建新文件組(這會(huì)導(dǎo)致生成小文件)。
2)在writer中使用一個(gè)時(shí)間軸緩存,這樣只要Spark集群不每次都重啟,后續(xù)的寫操作就不需要列出DFS目錄來獲取指定分區(qū)路徑下的文件片列表。
3)用戶還可以調(diào)整基本文件和日志文件大小之間的比值系數(shù)以及期望的壓縮率,以便將足夠數(shù)量的insert分到統(tǒng)一文件組,從而生成大小合適的基本文件。
4)智能調(diào)整bulk insert并行度,可以再次調(diào)整大小合適的初始文件組。實(shí)際上,正確執(zhí)行此操作非常關(guān)鍵,因?yàn)槲募M一旦創(chuàng)建就不能被刪除,而智能如前面所述對(duì)其進(jìn)行擴(kuò)展。
6. 查詢
鑒于這種靈活而全面的數(shù)據(jù)布局和豐富的時(shí)間線,Hudi能夠支持三種不同的查詢表方式,具體取決于表的類型。

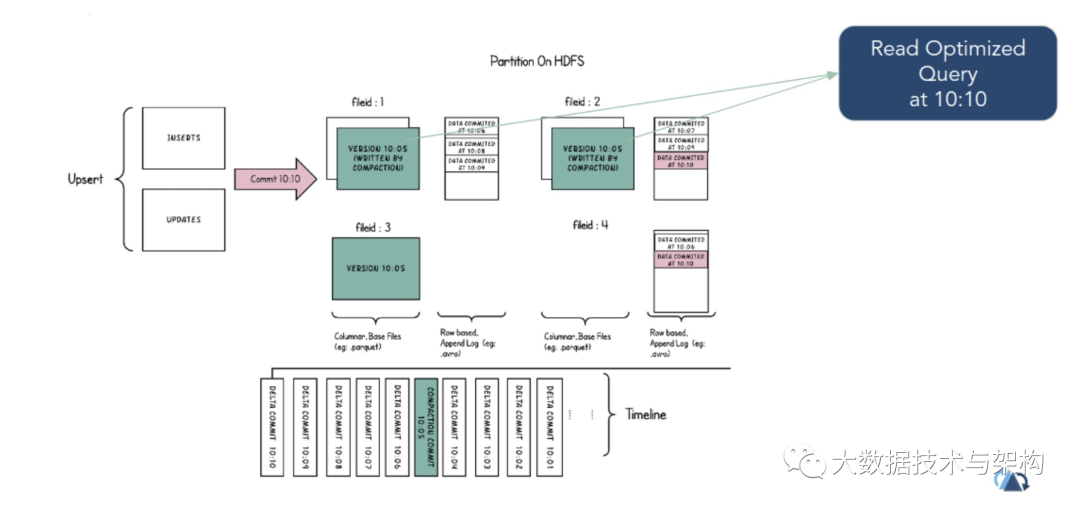
6.1 快照查詢
可查看給定delta commit或者commit即時(shí)操作后表的最新快照。在讀時(shí)合并(MOR)表的情況下,它通過即時(shí)合并最新文件片的基本文件和增量文件來提供近實(shí)時(shí)表(幾分鐘)。對(duì)于寫時(shí)復(fù)制(COW),它可以替代現(xiàn)有的parquet表(或相同基本文件類型的表),同時(shí)提供upsert/delete和其他寫入方面的功能。
6.2 增量查詢
可查看自給定commit/delta commit即時(shí)操作以來新寫入的數(shù)據(jù)。有效的提供變更流來啟用增量數(shù)據(jù)管道。
6.3 讀優(yōu)化查詢
可查看給定的commit/compact即時(shí)操作的表的最新快照。僅將最新文件片的基本/列文件暴露給查詢,并保證與非Hudi表相同的列查詢性能。



版權(quán)聲明:
文章不錯(cuò)?點(diǎn)個(gè)【在看】吧!??