
深入淺出——基于密度的聚類方法
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
“The observation of and the search forsimilarities and differences are the basis of all human knowledge.” —— ALFREDB. NOBEL
“人類所有知識的基礎(chǔ)就是觀察和尋找相似與相異” —— 阿爾弗雷德·伯恩哈德·諾貝爾
前言
我們生活在數(shù)據(jù)大爆炸時(shí)代,每時(shí)每刻都在產(chǎn)生海量的數(shù)據(jù)如視頻,文本,圖像和博客等。由于數(shù)據(jù)的類型和大小已經(jīng)超出了人們傳統(tǒng)手工處理的能力范圍,聚類,作為一種最常見的無監(jiān)督學(xué)習(xí)技術(shù),可以幫助人們給數(shù)據(jù)自動(dòng)打標(biāo)簽,已經(jīng)獲得了廣泛應(yīng)用。聚類的目的就是把不同的數(shù)據(jù)點(diǎn)按照它們的相似與相異度分割成不同的簇(注意:簇就是把數(shù)據(jù)劃分后的子集),確保每個(gè)簇中的數(shù)據(jù)都是盡可能相似,而不同的簇里的數(shù)據(jù)盡可能的相異。從模式識別的角度來講,聚類就是在發(fā)現(xiàn)數(shù)據(jù)中潛在的模式,幫助人們進(jìn)行分組歸類以達(dá)到更好理解數(shù)據(jù)的分布規(guī)律。
聚類的應(yīng)用非常廣泛,比如在商業(yè)應(yīng)用方面,聚類可以幫助市場營銷人員將客戶按照他們的屬性分層,發(fā)現(xiàn)不同的客戶群和他們的購買傾向(如下圖將客戶按照他們對顏色喜好歸類)。這樣公司就可以尋找潛在的市場,更高效地開發(fā)制定化的產(chǎn)品與服務(wù)。在文本分析處理上,聚類可以幫助新聞工作者把最新的微博按照的話題相似度進(jìn)行分類,而快速得出熱點(diǎn)新聞和關(guān)注對象。在生物醫(yī)學(xué)上,可以根據(jù)對相似表達(dá)譜的基因進(jìn)行聚類,從而知道未知基因的功能。

聚類可以將大規(guī)模的客戶數(shù)據(jù)按照客戶喜好進(jìn)行歸類,比如該圖展示了聚類后發(fā)現(xiàn)了3個(gè)簇
由于聚類是無監(jiān)督學(xué)習(xí)方法,不同的聚類方法基于不同的假設(shè)和數(shù)據(jù)類型,比如基于。由于數(shù)據(jù)通常可以以不同的角度進(jìn)行歸類,因此沒有萬能的通用聚類算法,并且每一種聚類算法都有其局限性和偏見性。也就是說某種聚類算法可能在市場數(shù)據(jù)上效果很棒,但是在基因數(shù)據(jù)上就無能為力了。
聚類算法很多,包括基于劃分的聚類算法(如:k-means),基于層次的聚類算法(如:BIRCH),基于密度的聚類算法(如:DBSCAN),基于網(wǎng)格的聚類算法( 如:STING )等等。本文將介紹聚類中一種最常用的方法——基于密度的聚類方法(density-based clustering)。
DBSCAN原理及其實(shí)現(xiàn)
相比其他的聚類方法,基于密度的聚類方法可以在有噪音的數(shù)據(jù)中發(fā)現(xiàn)各種形狀和各種大小的簇。DBSCAN(Ester, 1996)是該類方法中最典型的代表算法之一(DBSCAN獲得2014 SIGKDD Test of Time Award)。其核心思想就是先發(fā)現(xiàn)密度較高的點(diǎn),然后把相近的高密度點(diǎn)逐步都連成一片,進(jìn)而生成各種簇。算法實(shí)現(xiàn)上就是,對每個(gè)數(shù)據(jù)點(diǎn)為圓心,以eps為半徑畫個(gè)圈(稱為鄰域eps-neigbourhood),然后數(shù)有多少個(gè)點(diǎn)在這個(gè)圈內(nèi),這個(gè)數(shù)就是該點(diǎn)密度值。然后我們可以選取一個(gè)密度閾值MinPts,如圈內(nèi)點(diǎn)數(shù)小于MinPts的圓心點(diǎn)為低密度的點(diǎn),而大于或等于MinPts的圓心點(diǎn)高密度的點(diǎn)(稱為核心點(diǎn)Core point)。如果有一個(gè)高密度的點(diǎn)在另一個(gè)高密度的點(diǎn)的圈內(nèi),我們就把這兩個(gè)點(diǎn)連接起來,這樣我們可以把好多點(diǎn)不斷地串聯(lián)出來。之后,如果有低密度的點(diǎn)也在高密度的點(diǎn)的圈內(nèi),把它也連到最近的高密度點(diǎn)上,稱之為邊界點(diǎn)。這樣所有能連到一起的點(diǎn)就成一了個(gè)簇,而不在任何高密度點(diǎn)的圈內(nèi)的低密度點(diǎn)就是異常點(diǎn)。下圖展示了DBSCAN的工作原理。
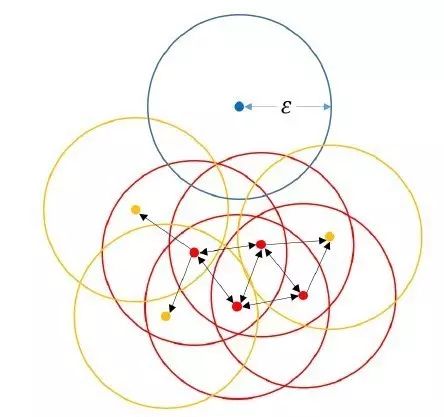
當(dāng)設(shè)置MinPts=4的時(shí)候,紅點(diǎn)為高密度點(diǎn),藍(lán)點(diǎn)為異常點(diǎn),黃點(diǎn)為邊界點(diǎn)。紅黃點(diǎn)串成一起成了一個(gè)簇。
由于DBSCAN是靠不斷連接鄰域內(nèi)高密度點(diǎn)來發(fā)現(xiàn)簇的,只需要定義鄰域大小和密度閾值,因此可以發(fā)現(xiàn)不同形狀,不同大小的簇。下圖展示了一個(gè)二維空間的DBSCAN聚類結(jié)果。
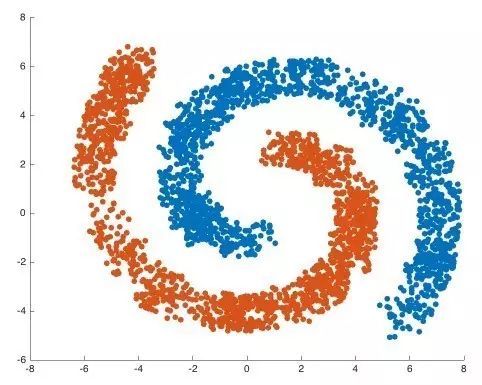
DBSCAN可以發(fā)現(xiàn)2個(gè)弧形的簇
DBSCAN算法偽碼表達(dá)如下:

DBSCAN實(shí)現(xiàn)偽碼(來源: Han 2011)
發(fā)現(xiàn)不同密度的簇
由于DBSCAN使用的是全局的密度閾值MinPts, 因此只能發(fā)現(xiàn)密度不少于MinPts的點(diǎn)組成的簇,即很難發(fā)現(xiàn)不同密度的簇。其成功與失敗的情況舉例如下:
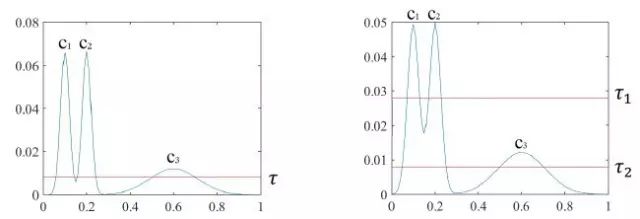 左圖有三個(gè)簇,一個(gè)全局密度閾值可以把三個(gè)簇分開。但是在右圖中,一個(gè)閾值無法把三個(gè)簇分開,過高的閾值會(huì)把C3全部變成異常點(diǎn),過低的閾值會(huì)把C1和C2合并起來。(來源:http://www.sciencedirect.com/science/article/pii/S0031320316301571)
左圖有三個(gè)簇,一個(gè)全局密度閾值可以把三個(gè)簇分開。但是在右圖中,一個(gè)閾值無法把三個(gè)簇分開,過高的閾值會(huì)把C3全部變成異常點(diǎn),過低的閾值會(huì)把C1和C2合并起來。(來源:http://www.sciencedirect.com/science/article/pii/S0031320316301571)
為了解決其發(fā)現(xiàn)不同密度的簇,目前已經(jīng)有很多新的方法被發(fā)明出來,比如OPTICS(Ordering points to identify the clustering structure)將鄰域點(diǎn)按照密度大小進(jìn)行排序,再用可視化的方法來發(fā)現(xiàn)不同密度的簇,如下圖所示。OPTICS必須由其他的算法在可視化的圖上查找“山谷”來發(fā)現(xiàn)簇,因此其性能直接受這些算法的約束。
 OPTICS將數(shù)據(jù)以密度的形式排序并展示,不同的山谷就是不同密度大小的簇。(來源:https://en.wikipedia.org/wiki/OPTICS_algorithm)
OPTICS將數(shù)據(jù)以密度的形式排序并展示,不同的山谷就是不同密度大小的簇。(來源:https://en.wikipedia.org/wiki/OPTICS_algorithm)
另外SNN采用一種基于KNN(最近鄰)來算相似度的方法來改進(jìn)DBSCAN。對于每個(gè)點(diǎn),我們在空間內(nèi)找出離其最近的k個(gè)點(diǎn)(稱為k近鄰點(diǎn))。兩個(gè)點(diǎn)之間相似度就是數(shù)這兩個(gè)點(diǎn)共享了多少個(gè)k近鄰點(diǎn)。如果這兩個(gè)點(diǎn)沒有共享k近鄰點(diǎn)或者這兩個(gè)點(diǎn)都不是對方的k近鄰點(diǎn),那么這兩個(gè)點(diǎn)相似度就是0。然后我們把DBSCAN里面的距離公式替換成SNN相似度,重新算每個(gè)點(diǎn)的鄰域和密度,就可以發(fā)現(xiàn)不同密度的簇了。SNN的核心就是,把原始的密度計(jì)算替換成基于每對點(diǎn)之間共享的鄰域的范圍,而忽略其真實(shí)的密度分布。SNN的缺點(diǎn)就是必須定義最近鄰個(gè)數(shù)k, 而且其性能對k的大小很敏感。下圖展示了SNN計(jì)算相似度的方法。
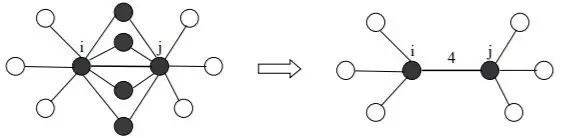
i點(diǎn)和j點(diǎn)共享4個(gè)近鄰點(diǎn),所以它們相似度為4
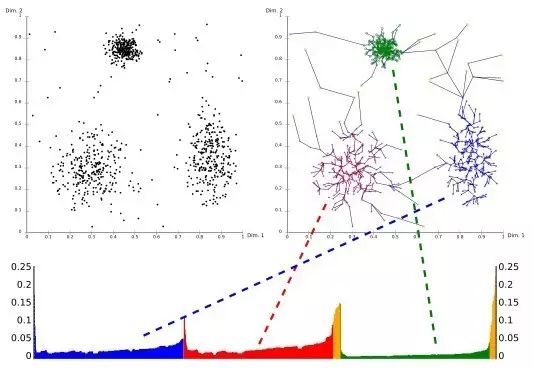
2014年Science雜志刊登了一種基于密度峰值的算法DP(Clustering by fast search and find of density peaks),也是采用可視化的方法來幫助查找不同密度的簇。其思想為每個(gè)簇都有個(gè)最大密度點(diǎn)為簇中心,每個(gè)簇中心都吸引并連接其周圍密度較低的點(diǎn),且不同的簇中心點(diǎn)都相對較遠(yuǎn)。為實(shí)現(xiàn)這個(gè)思想,它首先計(jì)算每個(gè)點(diǎn)的密度大小(也是數(shù)多少點(diǎn)在鄰域eps-neigbourhood內(nèi)),然后再計(jì)算每個(gè)點(diǎn)到其最近的且比它密度高的點(diǎn)的距離。這樣對每個(gè)點(diǎn)我們都有兩個(gè)屬性值,一個(gè)是其本身密度值,一個(gè)是其到比它密度高的最近點(diǎn)的距離值。對這兩個(gè)屬性我們可以生成一個(gè)2維圖表(決策圖),那么在右上角的幾個(gè)點(diǎn)就可以代表不同的簇的中心了,即密度高且離其他簇中心較遠(yuǎn)。然后我們可以把其他的點(diǎn)逐步連接到離其最近的且比它密度高的點(diǎn),直到最后連到某個(gè)簇中心點(diǎn)為止。這樣所有共享一個(gè)簇中心的點(diǎn)都屬于一個(gè)簇,而離其他點(diǎn)較遠(yuǎn)且密度很低的點(diǎn)就是異常點(diǎn)了。由于這個(gè)方法是基于相對距離和相對密度來連接點(diǎn)的,所以其可以發(fā)現(xiàn)不同密度的簇。DP的缺陷就在于每個(gè)簇必須有個(gè)最大密度點(diǎn)作為簇中心點(diǎn),如果一個(gè)簇的密度分布均與或者一個(gè)簇有多個(gè)密度高的點(diǎn),其就會(huì)把某些簇分開成幾個(gè)子簇。另外DP需要用戶指定有多少個(gè)簇,在實(shí)際操作的時(shí)候需要不斷嘗試調(diào)整。下圖展示了一個(gè)DP生成的決策圖。
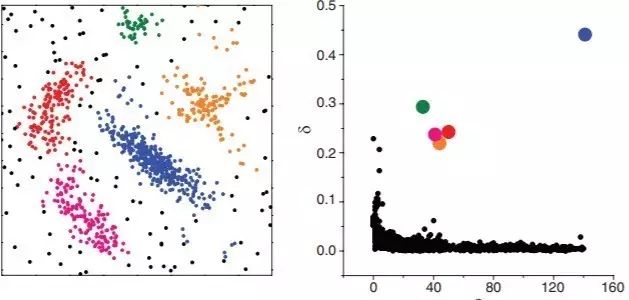
左圖為5個(gè)簇的分布,右圖為DP生成的決策圖,其右上角5個(gè)點(diǎn)就是左圖五個(gè)簇的中心點(diǎn)。(來源:http://science.sciencemag.org/content/344/6191/1492)
除此之外,還可以用密度比估計(jì)(Density-ratio estimation)來克服DBSCAN無法發(fā)現(xiàn)不同密度簇的缺陷。密度比的核心思想就是對每個(gè)點(diǎn),計(jì)算其密度與其鄰域密度的比率,然后用密度比計(jì)算替換DBSCAN的密度計(jì)算來發(fā)現(xiàn)核心點(diǎn)Core point,而其他過程和DBSCAN不變。這樣一來,每個(gè)局部高密度點(diǎn)就會(huì)被選出來作為核心點(diǎn),從而發(fā)現(xiàn)不同密度的簇。基于這個(gè)思想,我們還可以把原始數(shù)據(jù)按其密度分布進(jìn)行標(biāo)準(zhǔn)化(ReScale),即把密度高的區(qū)域進(jìn)行擴(kuò)張,密度低的區(qū)域繼續(xù)收縮。這樣以來,不同密度的簇就可以變成密度相近的簇了,我們再在標(biāo)準(zhǔn)化后的數(shù)據(jù)上直接跑DBSCAN就搞定了。這種方法需要用戶設(shè)置鄰域范圍來計(jì)算密度比,下圖展示了標(biāo)準(zhǔn)化前后的數(shù)據(jù)分布對比。
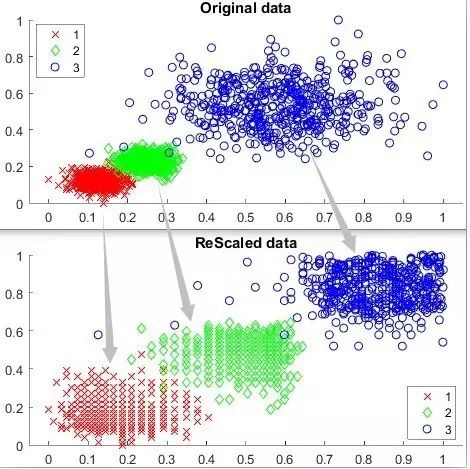
不同密度的簇在(ReScale)標(biāo)準(zhǔn)化后,變成密度相近的簇,進(jìn)而DBSCAN可以用全局閾值發(fā)現(xiàn)不同的簇
討論
基于密度的聚類是一種非常直觀的聚類方法,即把臨近的密度高的區(qū)域練成一片形成簇。該方法可以找到各種大小各種形狀的簇,并且具有一定的抗噪音特性。在日常應(yīng)用中,可以用不同的索引方法或用基于網(wǎng)格的方法來加速密度估計(jì),提高聚類的速度。基于密度的聚類也可以用在流數(shù)據(jù)和分布式數(shù)據(jù)中,關(guān)于其他方向的應(yīng)用,詳見(Aggarwal 2013)
源碼下載 (Matlab)
DP: https://au.mathworks.com/matlabcentral/fileexchange/53922-densityclust
DBSCAN, SNN, OPTICS 和 Density-ratio: https://sourceforge.net/projects/density-ratio/
參考文獻(xiàn)
Aggarwal, C. C., & Reddy, C. K.(Eds.). (2013). Data clustering: algorithms and applications. CRC press.
Ankerst, M., Breunig, M. M., Kriegel, H.P., & Sander, J. (1999, June). OPTICS: ordering points to identify theclustering structure. In ACM Sigmod record (Vol. 28, No. 2, pp. 49-60). ACM.
Ert?z, L., Steinbach, M., & Kumar,V. (2003, May). Finding clusters of different sizes, shapes, and densities innoisy, high dimensional data. In Proceedings of the 2003 SIAM InternationalConference on Data Mining(pp. 47-58). Society for Industrial and AppliedMathematics.
Ester, M., Kriegel, H. P., Sander, J.,& Xu, X. (1996, August). A density-based algorithm for discovering clustersin large spatial databases with noise. In SIGKDD (Vol. 96, No. 34, pp.226-231).
Han, J., Pei, J., & Kamber, M.(2011).Data mining: concepts and techniques. Elsevier.
Rodriguez, A., & Laio, A. (2014).Clustering by fast search and find of density peaks.Science,344(6191),1492-1496.
Zhu, Y., Ting, K. M., & Carman, M.J. (2016). Density-ratio based clustering for discovering clusters with varyingdensities. Pattern Recognition, Volume 60, 2016, Pages 983-997, ISSN 0031-3203.
好消息!
小白學(xué)視覺知識星球
開始面向外開放啦??????
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程 在「小白學(xué)視覺」公眾號后臺回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺、目標(biāo)跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺實(shí)戰(zhàn)項(xiàng)目52講 在「小白學(xué)視覺」公眾號后臺回復(fù):Python視覺實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計(jì)數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內(nèi)容提取、面部識別等31個(gè)視覺實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺。 下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講 在「小白學(xué)視覺」公眾號后臺回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個(gè)基于OpenCV實(shí)現(xiàn)20個(gè)實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。 交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會(huì)逐漸細(xì)分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會(huì)根據(jù)研究方向邀請進(jìn)入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會(huì)請出群,謝謝理解~