
基于聚類(lèi)的圖像分割-Python

當(dāng)我們?cè)谧鲆粋€(gè)圖像分類(lèi)任務(wù)時(shí),首先我們會(huì)想從圖像中捕獲感興趣的區(qū)域,然后再將其輸入到模型中。讓我們嘗試一種稱(chēng)為基于聚類(lèi)的圖像分割技術(shù),它會(huì)幫助我們?cè)谝欢ǔ潭壬咸岣吣P托阅埽屛覀兛纯此鞘裁匆约耙恍┻M(jìn)行聚類(lèi)分割的示例代碼。
想象一下我們要過(guò)馬路,過(guò)馬路之前我們會(huì)做什么?
首先,我們會(huì)看道路兩旁,以確定接近的車(chē)輛等環(huán)境對(duì)象,然后我們會(huì)對(duì)接近的車(chē)輛的速度做出一些快速的估計(jì),并決定何時(shí)以及如何過(guò)馬路。所有這些都發(fā)生在很短的時(shí)間內(nèi),非常很的神奇。
我們的大腦捕捉道路兩側(cè)的圖像
它檢測(cè)道路上的車(chē)輛和其他物體==物體檢測(cè)
它還確定了它檢測(cè)到的每個(gè)對(duì)象的形狀 == 圖像分割
通過(guò)確定不同物體的形狀,我們的大腦能夠在同一張快照中檢測(cè)到多個(gè)物體,這是多么神奇啊。
讓我們進(jìn)一步了解,假設(shè)我們有我們的圖像分類(lèi)模型,它能夠以 95% 上的準(zhǔn)確率對(duì)蘋(píng)果和橙子進(jìn)行分類(lèi)。當(dāng)我們輸入一幅同時(shí)包含蘋(píng)果和橙子的圖像時(shí),預(yù)測(cè)精度會(huì)下降。隨著圖像中對(duì)象數(shù)量的增加,分類(lèi)模型的性能會(huì)下降,這就是目標(biāo)定位發(fā)揮作用的地方。
在我們檢測(cè)圖像中的對(duì)象并對(duì)其進(jìn)行分類(lèi)之前,模型需要了解圖像中的內(nèi)容,這就是圖像分割的幫助所在。它為圖像中的對(duì)象創(chuàng)建一個(gè)像素級(jí)的蒙版,這有助于模型更精細(xì)地理解對(duì)象的形狀及其在圖像中的位置。

目標(biāo)檢測(cè) VS 圖像分割?
圖像分割大致分為兩大類(lèi)。
語(yǔ)義分割
實(shí)例分割

檢測(cè)到的對(duì)象 — 語(yǔ)義段 — 實(shí)例段?
在第一張圖片中,我們可以看到檢測(cè)到的對(duì)象都是男性。在語(yǔ)義分割中,我們認(rèn)為所有這些像素都屬于一類(lèi),因此我們用一種顏色表示它們。另一方面,在實(shí)例分割中,這些像素屬于同一類(lèi),但我們用不同的顏色表示同一類(lèi)的不同實(shí)例。
根據(jù)我們使用的分割方法,分割可以分為許多類(lèi)別。
基于區(qū)域的分割
基于邊緣檢測(cè)的分割
基于聚類(lèi)的分割
基于CNN的分割等。
接下來(lái)讓我們看一個(gè)基于聚類(lèi)的分割示例。
聚類(lèi)算法用于將彼此更相似的數(shù)據(jù)點(diǎn)從其他組數(shù)據(jù)點(diǎn)更緊密地分組。
現(xiàn)在我們想象一幅包含蘋(píng)果和橙子的圖像。蘋(píng)果中的大部分像素點(diǎn)應(yīng)該是紅色/綠色,這與橙色的像素值不同。如果我們能把這些點(diǎn)聚在一起,我們就能正確地區(qū)分每個(gè)物體,這就是基于聚類(lèi)的分割的工作原理。現(xiàn)在讓我們看一些代碼示例。
from skimage.io import imreadfrom skimage.color import rgb2grayimport numpy as npimport matplotlib.pyplot as plt%matplotlib inlinefrom scipy import ndimage# Scaling the image pixels values within 0-1img = imread('./apple-orange.jpg') / 255plt.imshow(img)plt.title('Original')plt.show()
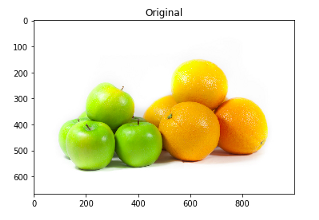
由于肉眼可見(jiàn),圖像中有五個(gè)色段
蘋(píng)果的綠色部分
橙子的橙色部分
蘋(píng)果和橙子底部的灰色陰影
蘋(píng)果頂部和右側(cè)部分的亮黃色部分
白色背景
讓我們看看我們是否可以使用來(lái)自 scikit-learn 的 K 均值算法對(duì)它們進(jìn)行聚類(lèi)
# For clustering the image using k-means, we first need to convert it into a 2-dimensional arrayimage_2D = img.reshape(img.shape[0]*img.shape[1], img.shape[2])# Use KMeans clustering algorithm from sklearn.cluster to cluster pixels in imagefrom sklearn.cluster import KMeans# tweak the cluster size and see what happens to the Outputkmeans = KMeans(n_clusters=5, random_state=0).fit(image_2D)clustered = kmeans.cluster_centers_[kmeans.labels_]# Reshape back the image from 2D to 3D imageclustered_3D = clustered.reshape(img.shape[0], img.shape[1], img.shape[2])plt.imshow(clustered_3D)plt.title('Clustered Image')plt.show()
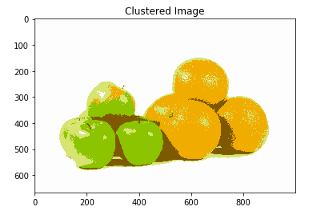
效果非常好,我們能夠?qū)⑽鍌€(gè)部分組合在一起,這就是聚類(lèi)分割的工作原理。目前有許多先進(jìn)的技術(shù),例如 Mask R-CNN,可以進(jìn)行更細(xì)粒度的分割。
Github代碼連接:
https://github.com/Mathanraj-Sharma/sample-for-medium-article/blob/master/cluster-based-segmentation-skimage/cluster-based-segmentation.ipynb

各位伙伴們好,詹帥本帥搭建了一個(gè)個(gè)人博客和小程序,匯集各種干貨和資源,也方便大家閱讀,感興趣的小伙伴請(qǐng)移步小程序體驗(yàn)一下哦!(歡迎提建議)
推薦閱讀
牛逼!Python常用數(shù)據(jù)類(lèi)型的基本操作(長(zhǎng)文系列第①篇)
牛逼!Python的判斷、循環(huán)和各種表達(dá)式(長(zhǎng)文系列第②篇)
推薦閱讀
牛逼!Python常用數(shù)據(jù)類(lèi)型的基本操作(長(zhǎng)文系列第①篇)
牛逼!Python的判斷、循環(huán)和各種表達(dá)式(長(zhǎng)文系列第②篇)