
用 Jupyter Notebook 爬取微博圖片保存本地!

文 | 潮汐
來源:Python 技術(shù)「ID: pythonall」
感分割線")
今天咱們用 Jupyter-Notebook 并結(jié)合框架(Selenium)模擬瀏覽器抓取微博圖片并將圖片保存本地。
Selenium 是一個(gè)用電腦模擬人的操作瀏覽器網(wǎng)頁(yè),可以實(shí)現(xiàn)自動(dòng)化測(cè)試,模擬瀏覽器抓取數(shù)據(jù)等工作。
環(huán)境部署
安裝 Jupyter notebook
關(guān)于 Jupyter notebook 的詳細(xì)知識(shí)點(diǎn)在以往的文章中有做過詳細(xì)的介紹,詳情請(qǐng)參考文章一文吃透 Jupyter notebook
這里只需要在命令行中輸入:jupyter notebook 啟動(dòng)跳轉(zhuǎn)到瀏覽器編輯界面即可。
瀏覽器頁(yè)面:
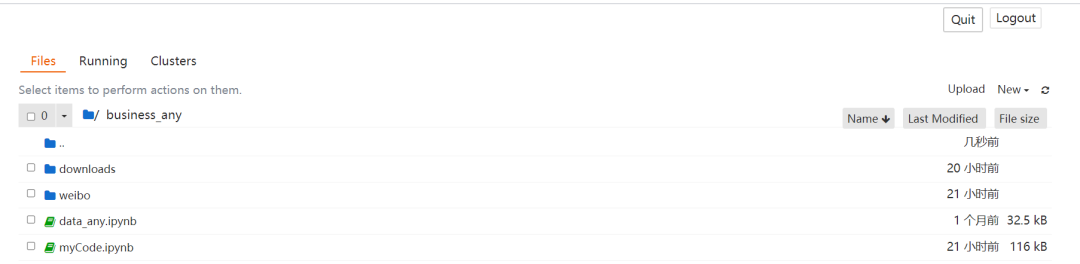
安裝 Selenium
安裝 Selenium 非常簡(jiǎn)單,只需要用命令 'pip install Selenium' 即可,安裝成功提示信息如下:

下載瀏覽器驅(qū)動(dòng)
下載驅(qū)動(dòng)地址如下:
Firefox瀏覽器驅(qū)動(dòng)
Chrome瀏覽器驅(qū)動(dòng):chromedriver
IE瀏覽器驅(qū)動(dòng):IEDriverServer
Edge瀏覽器驅(qū)動(dòng):MicrosoftWebDriver
需要把瀏覽器驅(qū)動(dòng)放入系統(tǒng)路徑中,或者直接告知 selenuim 的驅(qū)動(dòng)路徑。
環(huán)境都搭建好后就可以直接開始爬取數(shù)據(jù)了。
抓取微博數(shù)據(jù)
首先導(dǎo)入包,模擬瀏覽器訪問微博主頁(yè),詳細(xì)代碼如下:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://weibo.com/')
此時(shí)瀏覽器會(huì)打開一個(gè)新頁(yè)面,如下圖所示:
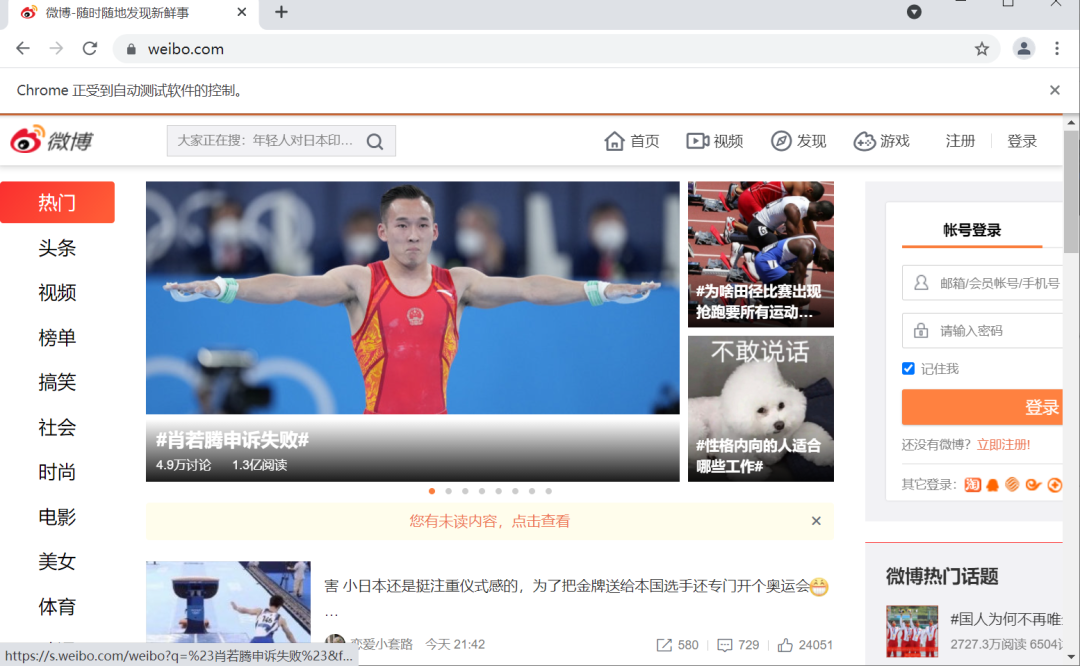
接下來開始分析頁(yè)面數(shù)據(jù):微博頁(yè)面搜索奧運(yùn)會(huì)關(guān)鍵字后出現(xiàn)新的頁(yè)面,然后復(fù)制網(wǎng)址,抓取和奧運(yùn)會(huì)相關(guān)的圖片保存于本地,搜索界面如下:
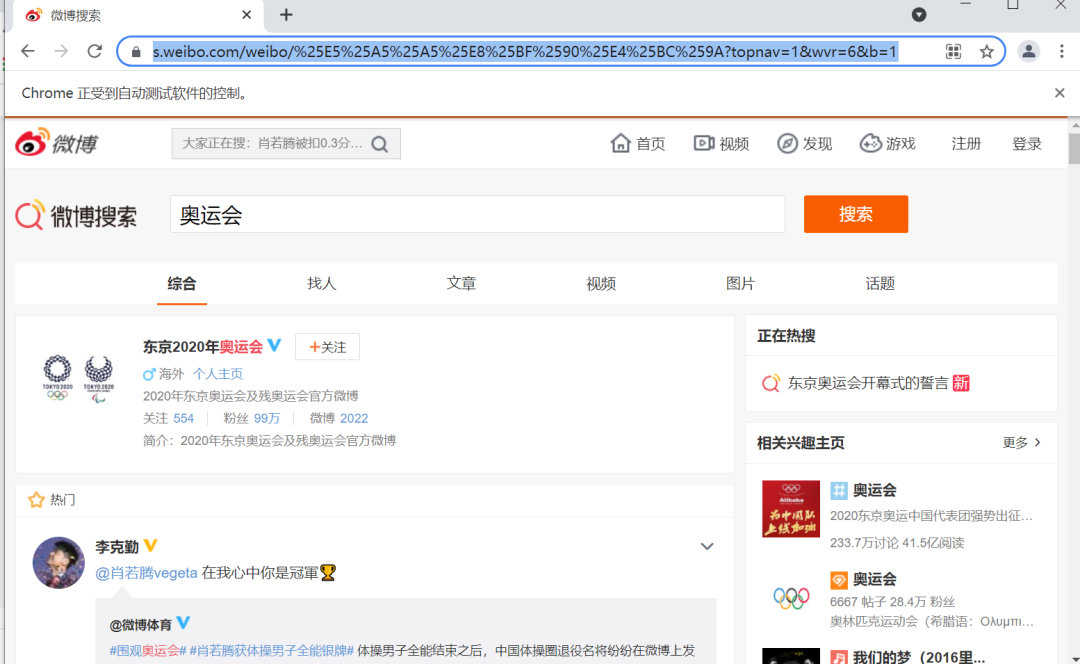
輸入網(wǎng)址獲取網(wǎng)頁(yè)內(nèi)容:
driver.get('https://s.weibo.com/weibo/%25E5%25A5%25A5%25E8%25BF%2590%25E4%25BC%259A?topnav=1&wvr=6&b=1')
contents = driver.find_elements_by_xpath(r'//p[@class="txt"]')
print(len(contents))
輸出內(nèi)容如下:

查看網(wǎng)頁(yè)詳細(xì)信息:
for i in range(0,3):
print("==============================")
print(contents[i].get_attribute('innerHTML'))
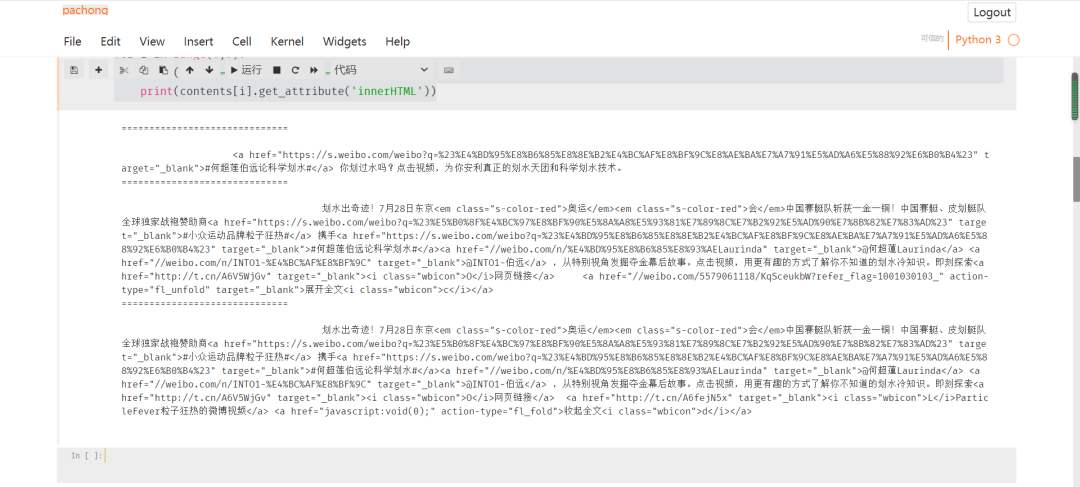
獲取圖片信息:
contents = driver.find_elements_by_xpath(r'//img[@action-type="fl_pics"]')
print(len(contents))
for i in range(0,20):
print("==============================")
print(contents[i].get_attribute('src'))
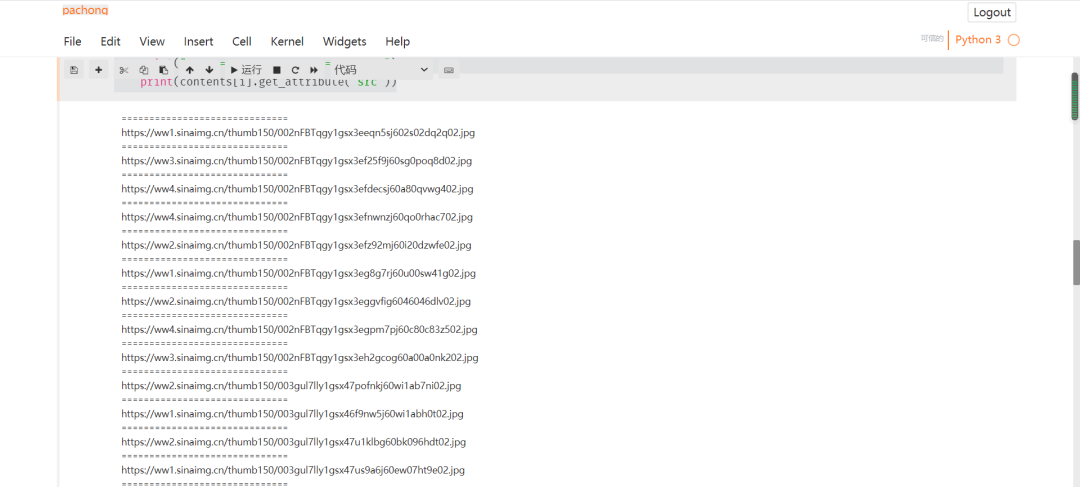
下載圖片在本地:
import os
import urllib.request
for i in range(0,20):
print("==============================")
image_url=contents[i].get_attribute('src')
file_name="downloads//p"+str(i)+".jpg"
print(image_url,file_name)
urllib.request.urlretrieve(image_url, filename=file_name)
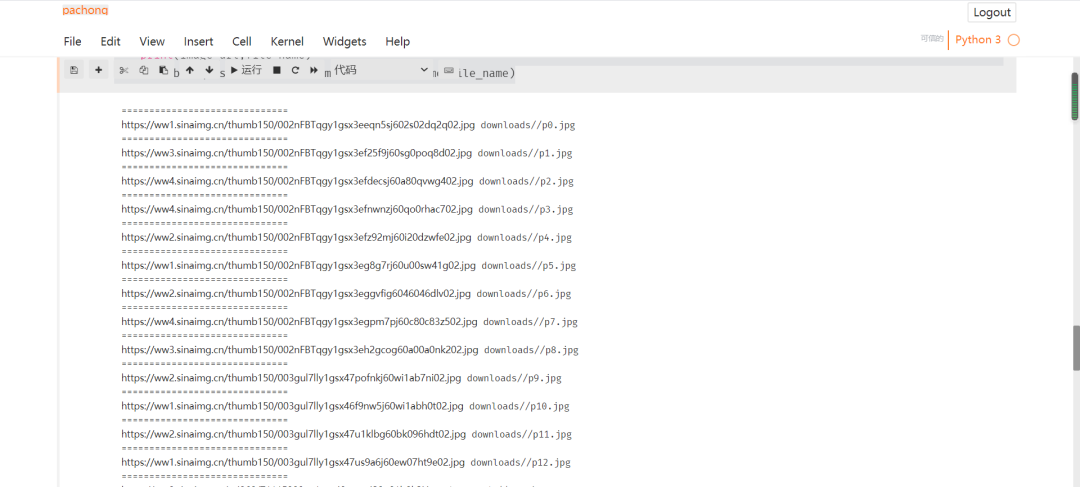
至此微博頁(yè)面關(guān)于奧運(yùn)會(huì)的相關(guān)圖片已保存于本地,圖片保存詳情如下:
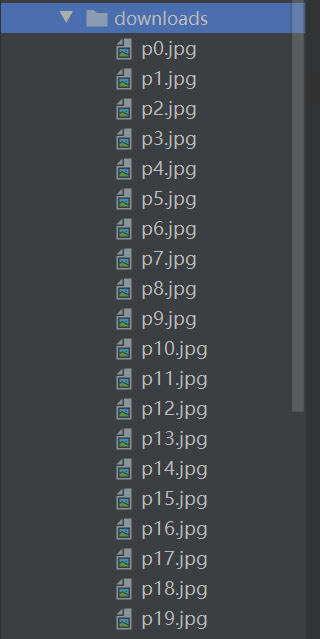
匯總代碼如下
from selenium import webdriver
import urllib.request
driver = webdriver.Chrome()
driver.get('https://weibo.com/')
driver.get('https://s.weibo.com/weibo/%25E5%25A5%25A5%25E8%25BF%2590%25E4%25BC%259A?topnav=1&wvr=6&b=1')
contents = driver.find_elements_by_xpath(r'//p[@class="txt"]')
for i in range(0,3):
print("==============================")
print(contents[i].get_attribute('innerHTML'))
contents = driver.find_elements_by_xpath(r'//img[@action-type="fl_pics"]')
print(len(contents))
for i in range(0,20):
print("==============================")
print(contents[i].get_attribute('src'))
for i in range(0,20):
print("==============================")
image_url=contents[i].get_attribute('src')
file_name="downloads//p"+str(i)+".jpg"
print(image_url,file_name)
urllib.request.urlretrieve(image_url, filename=file_name)
以上匯總代碼給沒有安裝 Jupyter Notebook 的朋友們使用,希望對(duì)大家有幫助。
總結(jié)
今天的文章主要講解用 Jupyter Notebook 工具和 Selenium 框架抓取微博數(shù)據(jù),希望對(duì)大家有所幫助。
PS:公號(hào)內(nèi)回復(fù)「Python」即可進(jìn)入Python 新手學(xué)習(xí)交流群,一起 100 天計(jì)劃!
老規(guī)矩,兄弟們還記得么,右下角的 “在看” 點(diǎn)一下,如果感覺文章內(nèi)容不錯(cuò)的話,記得分享朋友圈讓更多的人知道!


【代碼獲取方式】