
基于 Flink 的 OLAP 分析及實(shí)時(shí)數(shù)倉(cāng)實(shí)踐
業(yè)務(wù)背景 落地實(shí)踐 & 特色改進(jìn) 應(yīng)用場(chǎng)景 未來(lái)規(guī)劃
一、業(yè)務(wù)背景
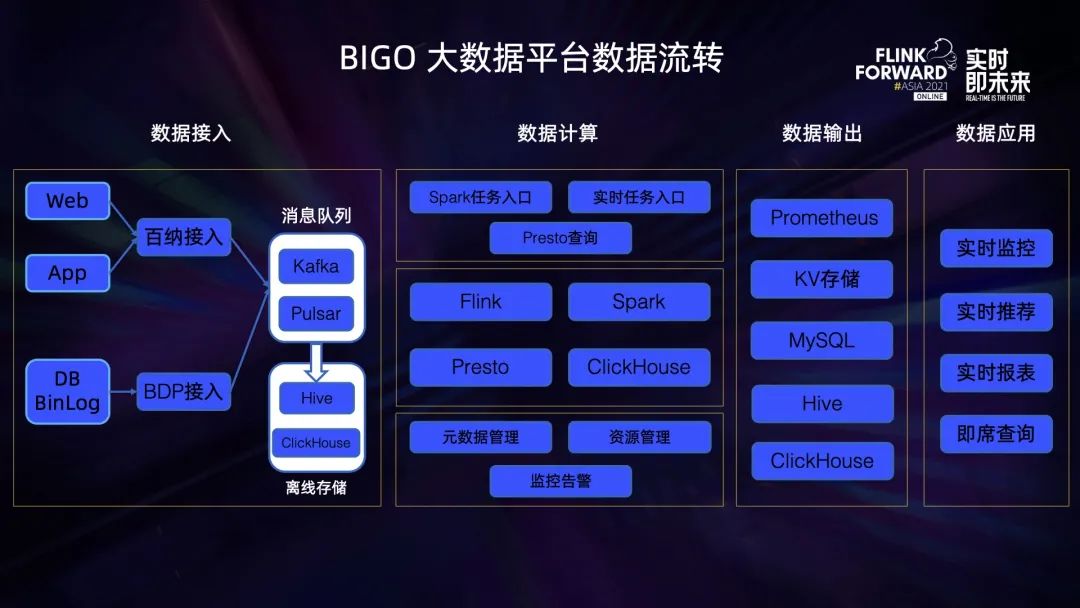
用戶在 APP,Web 頁(yè)面上的行為日志數(shù)據(jù),以及關(guān)系數(shù)據(jù)庫(kù)的 Binlog 數(shù)據(jù)會(huì)被同步到 BIGO 大數(shù)據(jù)平臺(tái)消息隊(duì)列,以及離線存儲(chǔ)系統(tǒng)中,然后通過(guò)實(shí)時(shí)的,離線的數(shù)據(jù)分析手段進(jìn)行計(jì)算,以應(yīng)用于實(shí)時(shí)推薦、監(jiān)控、即席查詢等使用場(chǎng)景。然而存在以下幾個(gè)問(wèn)題:
OLAP 分析平臺(tái)入口不統(tǒng)一:Presto/Spark 分析任務(wù)入口并存,用戶不清楚自己的 SQL 查詢適合哪個(gè)引擎執(zhí)行,盲目選擇,體驗(yàn)不好;另外,用戶會(huì)在兩個(gè)入口同時(shí)提交相同查詢,以更快的獲取查詢結(jié)果,導(dǎo)致資源浪費(fèi); 離線任務(wù)計(jì)算時(shí)延高,結(jié)果產(chǎn)出太慢:典型的如 ABTest 業(yè)務(wù),經(jīng)常計(jì)算到下午才計(jì)算出結(jié)果; 各個(gè)業(yè)務(wù)方基于自己的業(yè)務(wù)場(chǎng)景獨(dú)立開(kāi)發(fā)應(yīng)用,實(shí)時(shí)任務(wù)煙囪式的開(kāi)發(fā),缺少數(shù)據(jù)分層,數(shù)據(jù)血緣。
通過(guò) OneSQL OLAP 分析平臺(tái),統(tǒng)一 OLAP 查詢?nèi)肟冢瑴p少用戶盲目選擇,提升平臺(tái)的資源利用率; 通過(guò) Flink 構(gòu)建實(shí)時(shí)數(shù)倉(cāng)任務(wù),通過(guò) Kafka/Pulsar 進(jìn)行數(shù)據(jù)分層; 將部分離線計(jì)算慢的任務(wù)遷移到 Flink 流式計(jì)算任務(wù)上,加速計(jì)算結(jié)果的產(chǎn)出;
二、落地實(shí)踐 & 特色改進(jìn)
2.1 OneSQL OLAP 分析平臺(tái)實(shí)踐和優(yōu)化
OneSQL OLAP 分析平臺(tái)是一個(gè)集 Flink、Spark、Presto 于一體的 OLAP 查詢分析引擎。用戶提交的 OLAP 查詢請(qǐng)求通過(guò) OneSQL 后端轉(zhuǎn)發(fā)到不同執(zhí)行引擎的客戶端,然后提交對(duì)應(yīng)的查詢請(qǐng)求到不同的集群上執(zhí)行。其整體架構(gòu)圖如下:
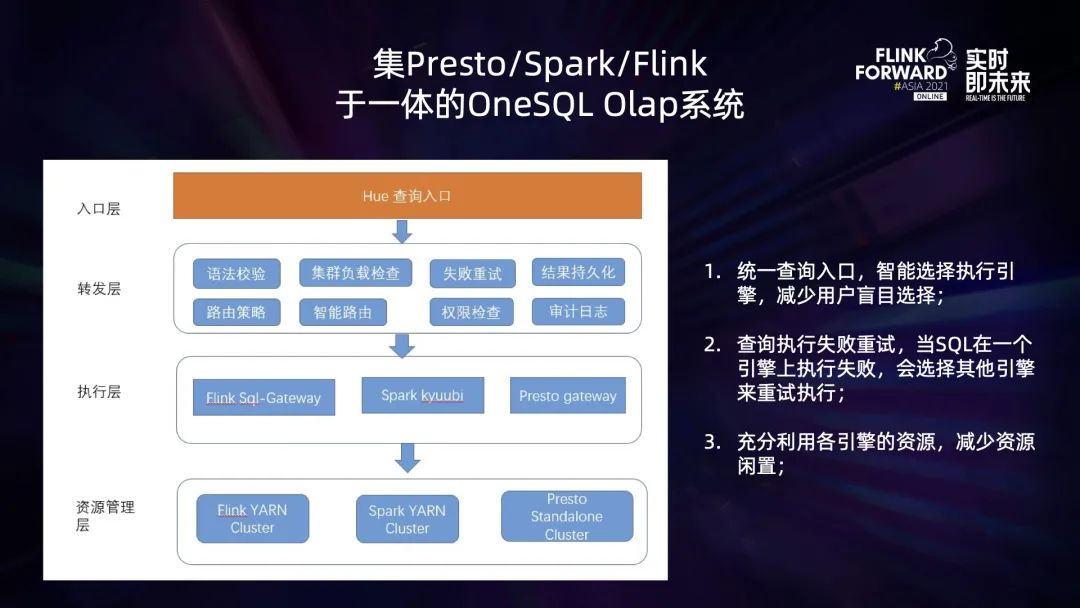
該分析平臺(tái)整體結(jié)構(gòu)從上到下分為入口層、轉(zhuǎn)發(fā)層、執(zhí)行層、資源管理層。為了優(yōu)化用戶體驗(yàn),減少執(zhí)行失敗的概率,提升各集群的資源利用率,OneSQL OLAP 分析平臺(tái)實(shí)現(xiàn)了以下功能:
統(tǒng)一查詢?nèi)肟?/strong>:入口層,用戶通過(guò)統(tǒng)一的 Hue 查詢頁(yè)面入口以 Hive SQL 語(yǔ)法為標(biāo)準(zhǔn)提交查詢; 統(tǒng)一查詢語(yǔ)法:集 Flink、Spark、Presto 等多種查詢引擎于一體,不同查詢引擎通過(guò)適配 Hive SQL 語(yǔ)法來(lái)執(zhí)行用戶的 SQL 查詢?nèi)蝿?wù); 智能路由:在選擇執(zhí)行引擎的過(guò)程中,會(huì)根據(jù)歷史 SQL 查詢執(zhí)行的情況 (在各引擎上是否執(zhí)行成功,以及執(zhí)行耗時(shí)),各集群的繁忙情況,以及各引擎對(duì)該 SQL 語(yǔ)法的是否兼容,來(lái)選擇合適的引擎提交查詢; 失敗重試:OneSQL 后臺(tái)會(huì)監(jiān)控 SQL 任務(wù)的執(zhí)行情況,如果 SQL 任務(wù)在執(zhí)行過(guò)程中失敗,將選擇其他的引擎執(zhí)行重試提交任務(wù);
■?2.1.1 Flink OLAP 分析系統(tǒng)建設(shè)
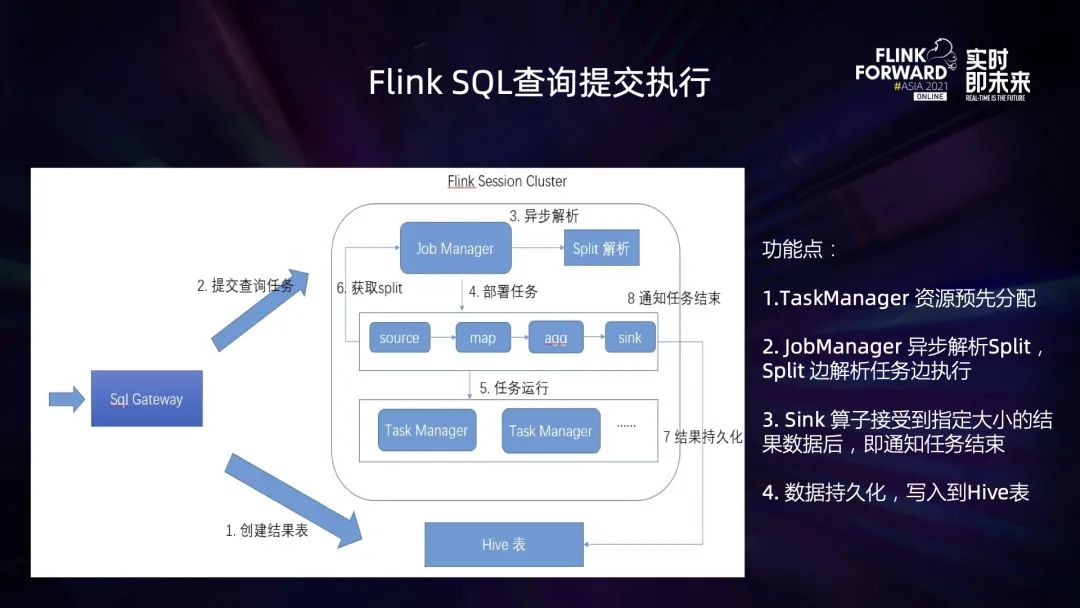
為了保證整個(gè) Flink OLAP 系統(tǒng)的穩(wěn)定性,以及高效的執(zhí)行 SQL 查詢,在這個(gè)系統(tǒng)中,進(jìn)行了以下功能增強(qiáng):
穩(wěn)定性: 基于 zookeeper HA 來(lái)保證 Flink Session 集群的可靠性,SQL Gateway 監(jiān)聽(tīng) Zookeeper 節(jié)點(diǎn),感知 Session 集群; 控制查詢掃描 Hive 表的數(shù)據(jù)量,分區(qū)個(gè)數(shù),以及返回結(jié)果數(shù)據(jù)量,防止 Session 集群的 JobManager,TaskManager 因此出現(xiàn) OOM 情況; 性能: Flink Session 集群預(yù)分配資源,減少作業(yè)提交后申請(qǐng)資源所需的時(shí)間; Flink JobManager 異步解析 Split,Split 邊解析任務(wù)邊執(zhí)行,減少由于解析 Split 阻塞任務(wù)執(zhí)行的時(shí)間; 控制作業(yè)提交過(guò)程中掃描分區(qū),以及 Split 最大的個(gè)數(shù),減少設(shè)置任務(wù)并行所需要的時(shí)間; Hive SQL 兼容: 針對(duì) Flink 對(duì)于 Hive SQL 語(yǔ)法的兼容性進(jìn)行改進(jìn),目前針對(duì) Hive SQL 的兼容性大致為 80%; 監(jiān)控告警: 監(jiān)控 Flink Session 集群的 JobManager,TaskManager,以及 SQL Gateway 的內(nèi)存,CPU 使用情況,以及任務(wù)的提交情況,一旦出現(xiàn)問(wèn)題,及時(shí)告警和處理;
■?2.1.2 OneSQL OLAP 分析平臺(tái)取得的成果
基于以上實(shí)現(xiàn)的 OneSQL OLAP 分析平臺(tái),取得了以下幾個(gè)收益:
統(tǒng)一查詢?nèi)肟冢瑴p少用戶的盲目選擇,用戶執(zhí)行出錯(cuò)率下降 85.7%,SQL 執(zhí)行的成功率提升 3%; SQL 執(zhí)行時(shí)間縮短 10%,充分利用了各個(gè)集群的資源,減少任務(wù)排隊(duì)等待的時(shí)間; Flink 作為 OLAP 分析引擎的一部分,實(shí)時(shí)計(jì)算集群的資源利用率提升了 15%;??
2.2 實(shí)時(shí)數(shù)倉(cāng)建設(shè)和優(yōu)化
■?2.2.1 建設(shè)方案
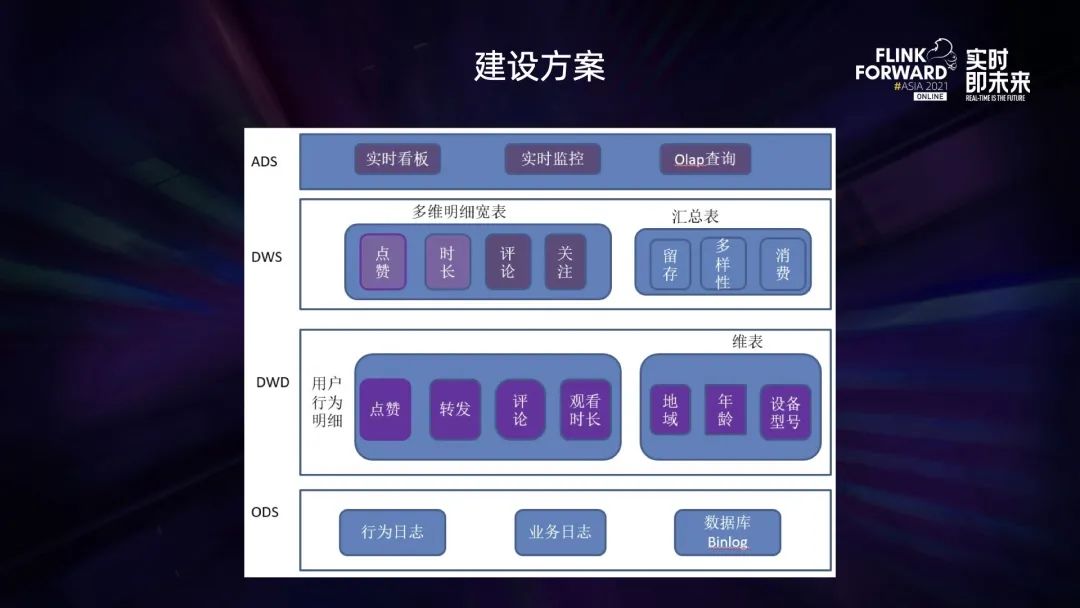
按照傳統(tǒng)數(shù)據(jù)倉(cāng)庫(kù)的數(shù)據(jù)分層方法,將數(shù)據(jù)劃分成 ODS、DWD、DWS、ADS 等四層數(shù)據(jù):
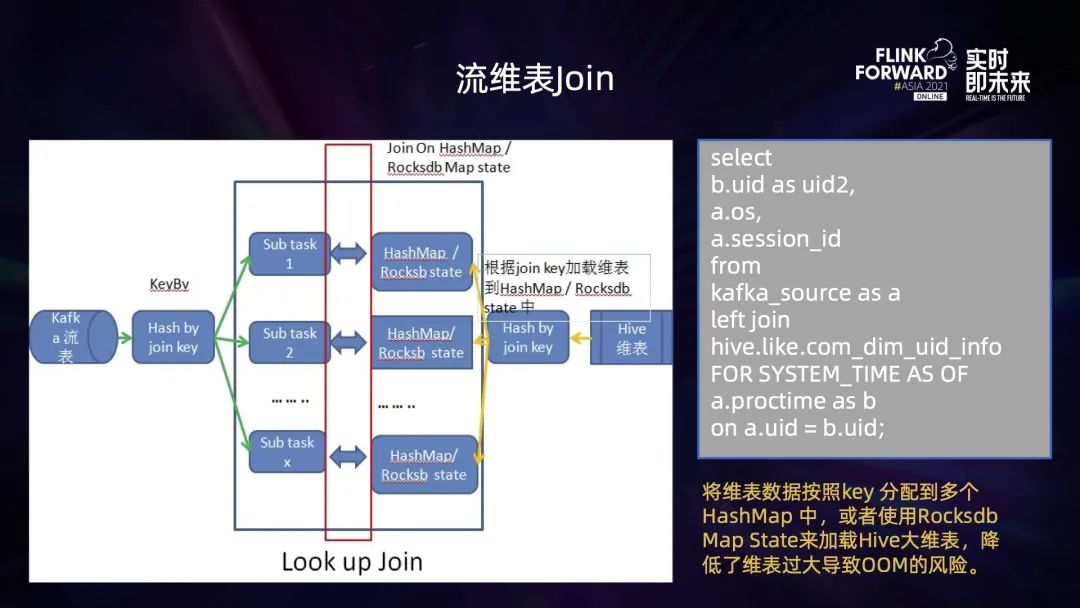
ODS 層:基于用戶的行為日志,業(yè)務(wù)日志等作為原始數(shù)據(jù),存放于 Kafka/Pulsar 等消息隊(duì)列中; DWD 層:這部分?jǐn)?shù)據(jù)根據(jù)用戶的 UserId 經(jīng)過(guò) Flink 任務(wù)進(jìn)行聚合后,形成不同用戶的行為明細(xì)數(shù)據(jù),保存到 Kafka/Pulsar 中; DWS 層:用戶行為明細(xì)的 Kafka 流表與用戶 Hive/MySQL 維表進(jìn)行流維表 JOIN,然后將 JOIN 之后產(chǎn)生的多維明細(xì)數(shù)據(jù)輸出到 ClickHouse 表中; ADS 層:針對(duì) ClickHouse 中多維明細(xì)數(shù)據(jù)按照不同維度進(jìn)行匯總,然后應(yīng)用于不同的業(yè)務(wù)中。
將離線任務(wù)轉(zhuǎn)為實(shí)時(shí)計(jì)算任務(wù)后,計(jì)算邏輯較為復(fù)雜 (多流 JOIN,去重),導(dǎo)致作業(yè)狀態(tài)太大,作業(yè)出現(xiàn) OOM (內(nèi)存溢出) 異常或者作業(yè)算子背壓太大; 維表 Join 過(guò)程中,明細(xì)流表與大維表 Join,維表數(shù)據(jù)過(guò)多,加載到內(nèi)存后 OOM,作業(yè)失敗無(wú)法運(yùn)行; Flink 將流維表 Join 產(chǎn)生的多維明細(xì)數(shù)據(jù)寫(xiě)入到 ClickHouse,無(wú)法保證 Exactly-once,一旦作業(yè)出現(xiàn) Failover,就會(huì)導(dǎo)致數(shù)據(jù)重復(fù)寫(xiě)入。
■?2.2.2 問(wèn)題解決 & 優(yōu)化
優(yōu)化作業(yè)執(zhí)行邏輯,減小狀態(tài)
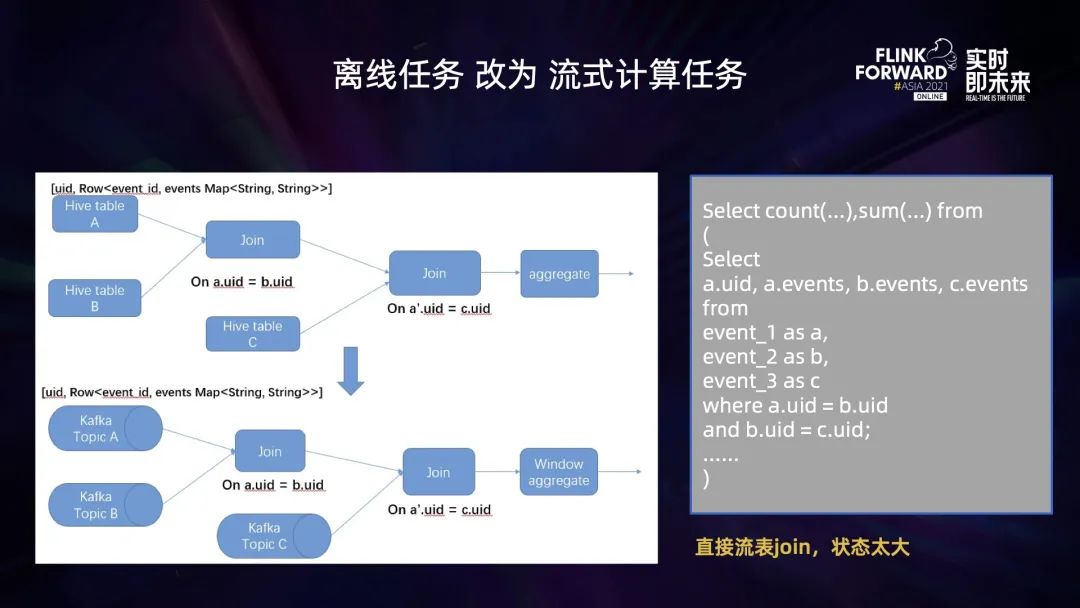
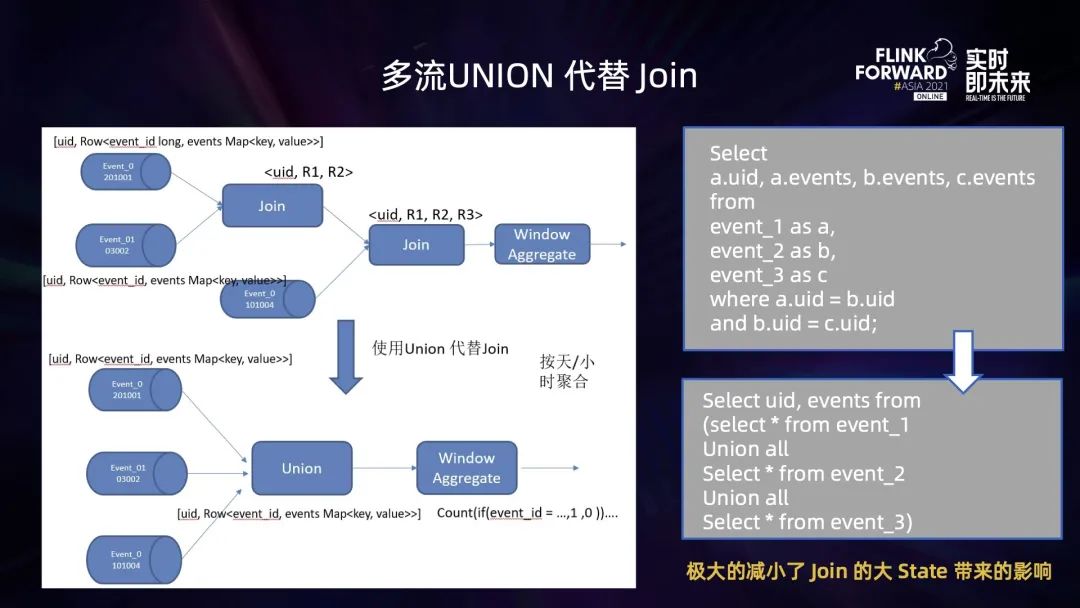
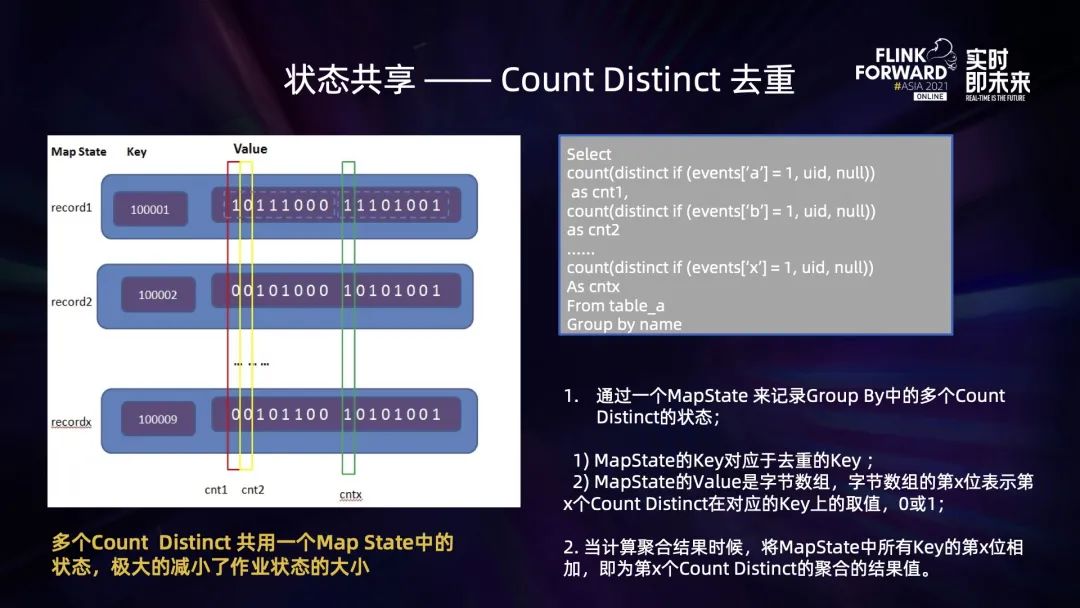
selectcount(distinct if(events['a'] = 1, postid, null))as cnt1,count(distinct if(events['b'] = 1, postid, null))as cnt2……count(distinct if(events['x'] = 1, postid, null))As cntxFrom table_aGroup by uid
流維表 JOIN 優(yōu)化
ClickHouse Sink 的 Exactly-Once 語(yǔ)義支持
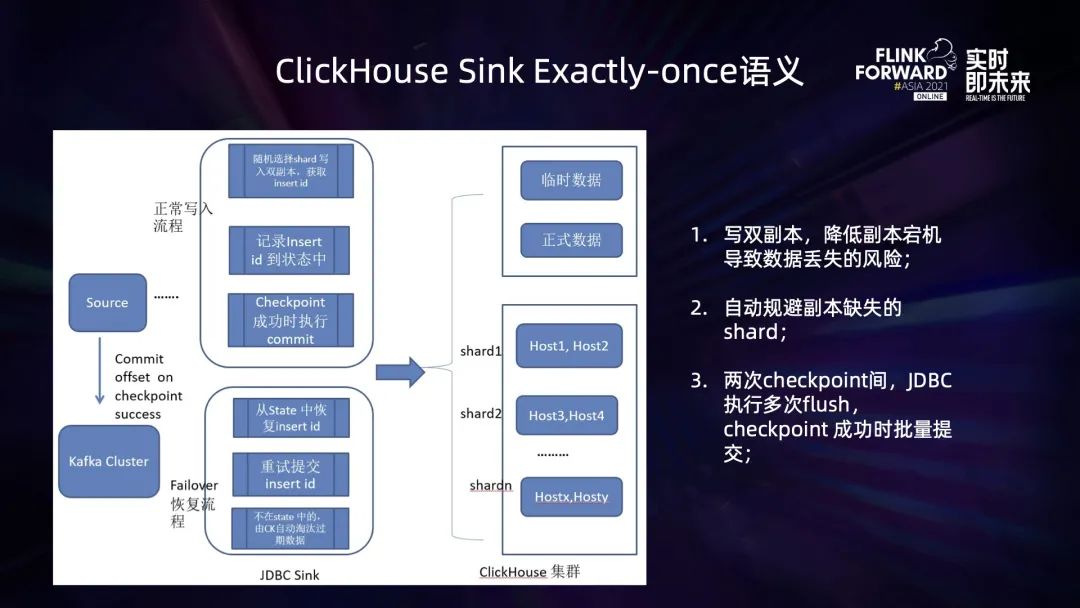
在正常寫(xiě)入的情況下,Connector 隨機(jī)選擇 ClickHouse 的某一個(gè) shard 寫(xiě)入,根據(jù)用戶配置寫(xiě)單副本,或者雙副本來(lái)執(zhí)行 insert 操作,并記錄寫(xiě)入后的 insert id;在兩次 checkpoint 之間就會(huì)有多次這種 insert 操作,從而產(chǎn)生多個(gè) insert id,當(dāng) checkpoint 完成時(shí),再將這些 insert id 批量提交,將臨時(shí)數(shù)據(jù)轉(zhuǎn)為正式數(shù)據(jù),即完成了兩次 checkpoint 間數(shù)據(jù)的寫(xiě)入; 一旦作業(yè)出現(xiàn) Failover,F(xiàn)link 作業(yè) Failover 重啟完成后,將從最近一次完成的 checkpoint 來(lái)恢復(fù)狀態(tài),此時(shí) ClickHouse Sink 中的 Operator State 可能會(huì)包含上一次還沒(méi)有來(lái)得及提交完成的 Insert id,針對(duì)這些 insert id 進(jìn)行重試提交;針對(duì)那些數(shù)據(jù)已經(jīng)寫(xiě)入 ClickHouse 中之后,但是 insert id 并沒(méi)有記錄到 Opeator State 中的數(shù)據(jù),由于是臨時(shí)數(shù)據(jù),在 ClickHouse 中并不會(huì)被查詢到,一段時(shí)間后,將會(huì)由 ClickHouse 的過(guò)期清理機(jī)制,被清理掉,從而保證了狀態(tài)回滾到上一次 checkpoint 之后,數(shù)據(jù)不會(huì)重復(fù)。
■?2.2.3 平臺(tái)建設(shè)
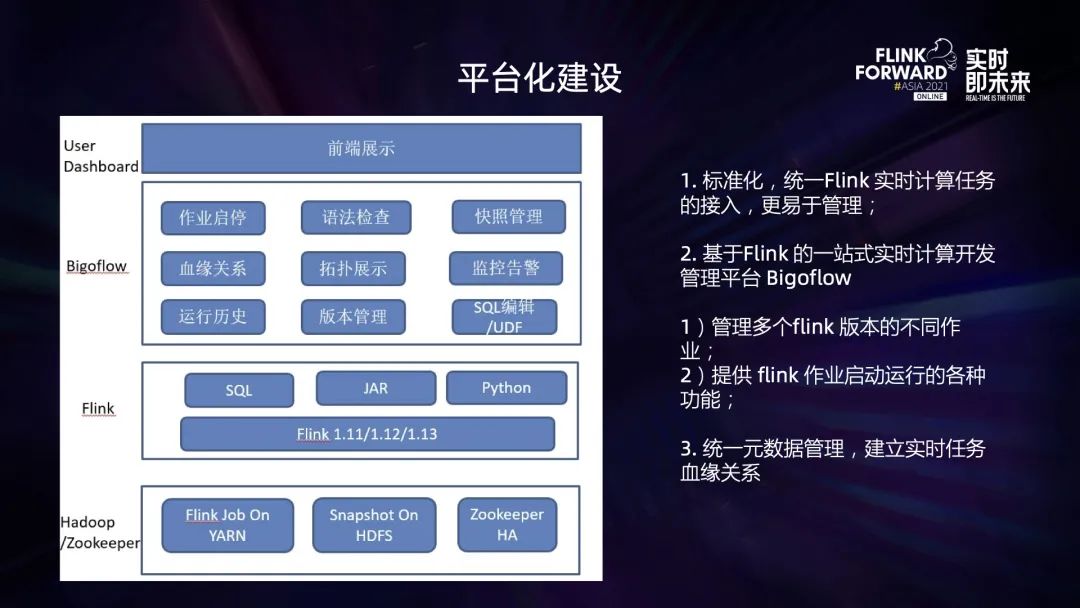
支持 Flink ?JAR、SQL、Python 等多種類型作業(yè);支持不同的 Flink 版本,覆蓋公司內(nèi)部大部分實(shí)時(shí)計(jì)算相關(guān)業(yè)務(wù); 一站式管理:集作業(yè)開(kāi)發(fā)、提交、運(yùn)行、歷史展示、監(jiān)控、告警于一體,便于隨時(shí)查看作業(yè)的運(yùn)行狀態(tài)和發(fā)現(xiàn)問(wèn)題; 血緣關(guān)系:方便查詢每個(gè)作業(yè)的數(shù)據(jù)源、數(shù)據(jù)目的、數(shù)據(jù)計(jì)算的來(lái)龍去脈。
三、應(yīng)用場(chǎng)景
3.1 Onesql OLAP 分析平臺(tái)應(yīng)用場(chǎng)景
3.2 實(shí)時(shí)數(shù)據(jù)倉(cāng)庫(kù)應(yīng)用場(chǎng)景

四、未來(lái)規(guī)劃
為了更好的建設(shè) OneSQL OLAP 分析平臺(tái)以及 BIGO 實(shí)時(shí)數(shù)據(jù)倉(cāng)庫(kù),實(shí)時(shí)計(jì)算平臺(tái)的規(guī)劃如下:
完善 Flink ?OLAP 分析平臺(tái),完善 Hive SQL 語(yǔ)法支持,以及解決計(jì)算過(guò)程中出現(xiàn)的 JOIN 數(shù)據(jù)傾斜問(wèn)題; 完善實(shí)時(shí)數(shù)倉(cāng)建設(shè),引入數(shù)據(jù)湖技術(shù),解決實(shí)時(shí)數(shù)倉(cāng)中任務(wù)數(shù)據(jù)的可重跑回溯范圍小的問(wèn)題; 基于 Flink 打造流批一體的數(shù)據(jù)計(jì)算平臺(tái)。