
如何從0到1搭建大數(shù)據(jù)平臺
大數(shù)據(jù)時代這個詞被提出已有10年了吧,越來越多的企業(yè)已經(jīng)完成了大數(shù)據(jù)平臺的搭建。隨著移動互聯(lián)網(wǎng)和物聯(lián)網(wǎng)的爆發(fā),大數(shù)據(jù)價值在越來越多的場景中被挖掘,隨著大家都在使用歐冠大數(shù)據(jù),大數(shù)據(jù)平臺的搭建門檻也越來越低。借助開源的力量,任何有基礎(chǔ)研發(fā)能力的組織完全可以搭建自己的大數(shù)據(jù)平臺。但是對于沒有了解過大數(shù)據(jù)平臺、數(shù)據(jù)倉庫、數(shù)據(jù)挖掘概念的同學(xué)可能還是無法順利完成搭建,因?yàn)槟闳グ俣炔榈臅r候會發(fā)現(xiàn)太多的東西,不知道如何去選擇。今天給大家分享下大數(shù)據(jù)平臺是怎么玩的。
架構(gòu)總覽
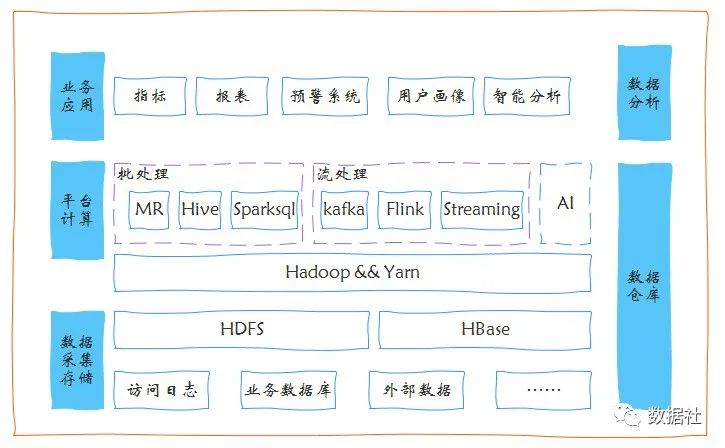
通常大數(shù)據(jù)平臺的架構(gòu)如上,從外部采集數(shù)據(jù)到數(shù)據(jù)處理,數(shù)據(jù)顯現(xiàn),應(yīng)用等模塊。
數(shù)據(jù)采集
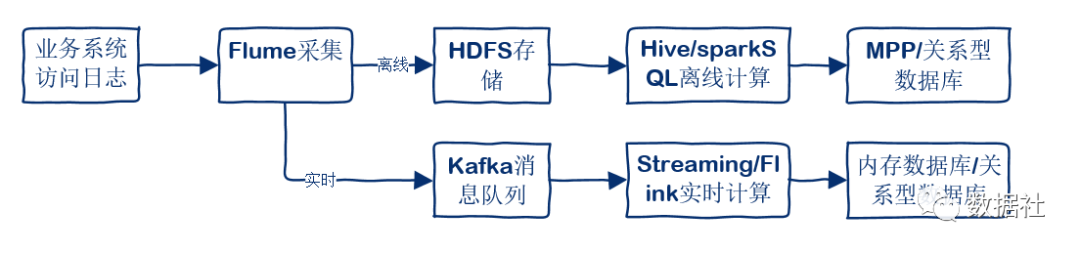
用戶訪問我們的產(chǎn)品會產(chǎn)生大量的行為日志,因此我們需要特定的日志采集系統(tǒng)來采集并輸送這些日志。Flume是目前常用的開源選擇,F(xiàn)lume是Cloudera提供的一個高可用的,高可靠的,分布式的海量日志采集、聚合和傳輸?shù)南到y(tǒng),F(xiàn)lume支持在日志系統(tǒng)中定制各類數(shù)據(jù)發(fā)送方,用于收集數(shù)據(jù);同時,F(xiàn)lume提供對數(shù)據(jù)進(jìn)行簡單處理,并寫到各種數(shù)據(jù)接受方的能力。

對于非實(shí)時使用的數(shù)據(jù),可以通過Flume直接落文件到集群的HDFS上。而對于要實(shí)時使用的數(shù)據(jù)來說,則可以采用Flume+Kafka,數(shù)據(jù)直接進(jìn)入消息隊列,經(jīng)過Kafka將數(shù)據(jù)傳遞給實(shí)時計算引擎進(jìn)行處理。
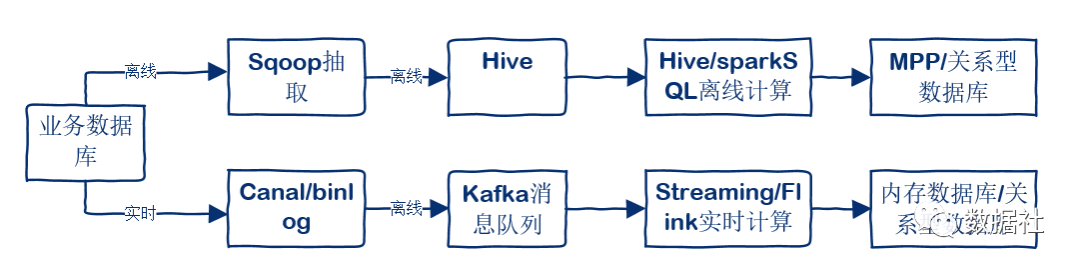
業(yè)務(wù)數(shù)據(jù)庫的數(shù)據(jù)量相比訪問日志來說小很多。對于非實(shí)時的數(shù)據(jù),一般定時導(dǎo)入到HDFS/Hive中。一個常用的工具是Sqoop,Sqoop是一個用來將Hadoop和關(guān)系型數(shù)據(jù)庫中的數(shù)據(jù)相互轉(zhuǎn)移的工具,可以將一個關(guān)系型數(shù)據(jù)庫(例如 :MySQL ,Oracle ,Postgres等)中的數(shù)據(jù)導(dǎo)進(jìn)到Hadoop的HDFS中,也可以將HDFS的數(shù)據(jù)導(dǎo)進(jìn)到關(guān)系型數(shù)據(jù)庫中。而對于實(shí)時的數(shù)據(jù)庫同步,可以采用Canal作為中間件,處理數(shù)據(jù)庫日志(如binlog),將其計算后實(shí)時同步到大數(shù)據(jù)平臺的數(shù)據(jù)存儲中。
數(shù)據(jù)存儲
無論上層采用何種的大規(guī)模數(shù)據(jù)計算引擎,底層的數(shù)據(jù)存儲系統(tǒng)基本還是以HDFS為主。HDFS(Hadoop Distributed File System)是Hadoop項(xiàng)目的核心子項(xiàng)目,是分布式計算中數(shù)據(jù)存儲管理的基礎(chǔ)。具備高容錯性、高可靠、高吞吐等特點(diǎn)。
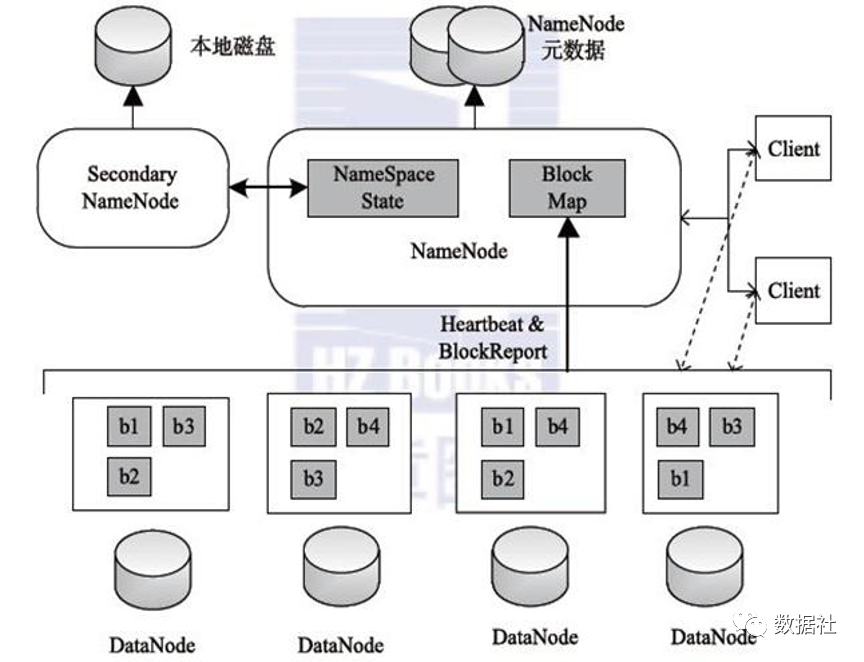
HDFS存儲的是一個個的文本,而我們在做分析統(tǒng)計時,結(jié)構(gòu)化會方便需要。因此,在HDFS的基礎(chǔ)上,會使用Hive來將數(shù)據(jù)文件映射為結(jié)構(gòu)化的表結(jié)構(gòu),以便后續(xù)對數(shù)據(jù)進(jìn)行類SQL的查詢和管理。
數(shù)據(jù)處理
數(shù)據(jù)處理就是我們常說的ETL。在這部分,我們需要三樣?xùn)|西:計算引擎、調(diào)度系統(tǒng)、元數(shù)據(jù)管理。
對于大規(guī)模的非實(shí)時數(shù)據(jù)計算來講,目前一樣采用Hive和spark引擎。Hive是基于MapReduce的架構(gòu),穩(wěn)定可靠,但是計算速度較慢;Spark則是基于內(nèi)存型的計算,一般認(rèn)為比MapReduce的速度快很多,但是其對內(nèi)存性能的要求較高,且存在內(nèi)存溢出的風(fēng)險。Spark同時兼容hive數(shù)據(jù)源。
從穩(wěn)定的角度考慮,一般建議以Hive作為日常ETL的主要計算引擎,特別是對于一些實(shí)時要求不高的數(shù)據(jù)。Spark等其他引擎根據(jù)場景搭配使用。
實(shí)時計算引擎方面,目前大體經(jīng)過了三代,依次是:storm、spark streaming、Flink。Flink已被阿里收購,大廠一直在推,社區(qū)活躍度很好,國內(nèi)也有很多資源。
調(diào)度系統(tǒng)上,建議采用輕量級的Azkaban,Azkaban是由Linkedin開源的一個批量工作流任務(wù)調(diào)度器。https://azkaban.github.io/
一般需要自己開發(fā)一套元數(shù)據(jù)管理系統(tǒng),用來規(guī)劃數(shù)據(jù)倉庫和ETL流程中的元數(shù)據(jù)。元數(shù)據(jù)分為業(yè)務(wù)元數(shù)據(jù)和技術(shù)元數(shù)據(jù)。
業(yè)務(wù)元數(shù)據(jù),主要用于支撐數(shù)據(jù)服務(wù)平臺Web UI上面的各種業(yè)務(wù)條件選項(xiàng),比如,常用的有如下一些:移動設(shè)備機(jī)型、品牌、運(yùn)營商、網(wǎng)絡(luò)、價格范圍、設(shè)備物理特性、應(yīng)用名稱等。這些元數(shù)據(jù),有些來自于基礎(chǔ)數(shù)據(jù)部門提供的標(biāo)準(zhǔn)庫,比如品牌、價格范圍等,可以從對應(yīng)的數(shù)據(jù)表中同步或直接讀取;而有些具有時間含義的元數(shù)據(jù),需要每天通過ETL處理生成,比如應(yīng)用信息。為支撐應(yīng)用計算使用,被存儲在MySQL數(shù)據(jù)庫中;而對于填充頁面上對應(yīng)的條件選擇的數(shù)據(jù),則使用Redis存儲,每天/月會根據(jù)MySQL中的數(shù)據(jù)進(jìn)行加工處理,生成易于快速查詢的鍵值對類數(shù)據(jù),存儲到Redis中。
技術(shù)元數(shù)據(jù),主要包括數(shù)據(jù)倉庫中的模型說明、血緣關(guān)系、變更記錄、需求來源、模型字段信息等。
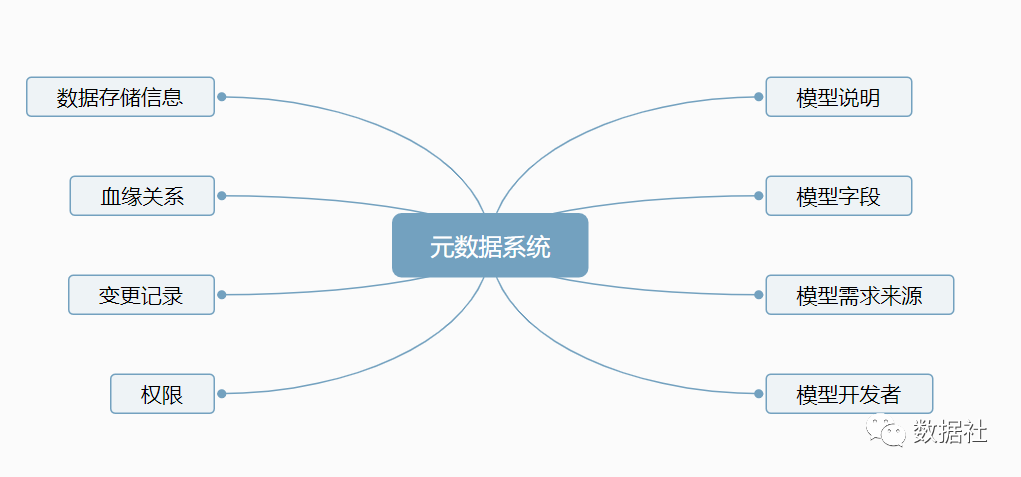
數(shù)據(jù)流轉(zhuǎn)
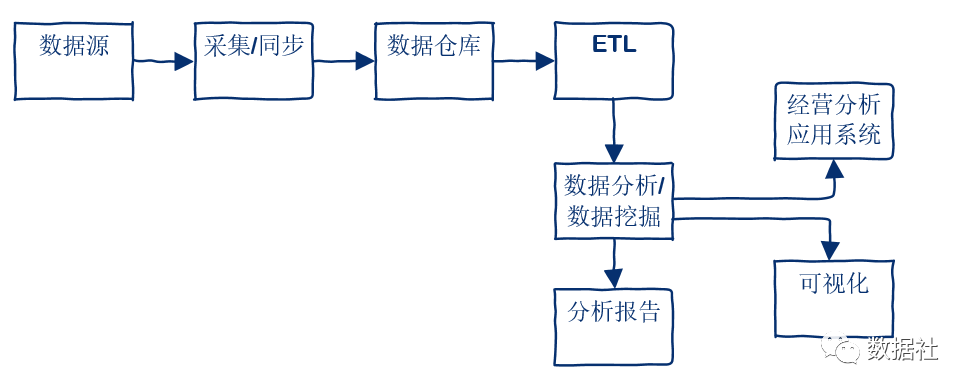
通過上面一張圖了解數(shù)據(jù)采集,數(shù)據(jù)處理,到數(shù)據(jù)展現(xiàn)的數(shù)據(jù)流轉(zhuǎn)。通常我們在實(shí)際工作中,從數(shù)據(jù)源到分析報告或系統(tǒng)應(yīng)用的過程中,主要包括數(shù)據(jù)采集同步、數(shù)據(jù)倉庫存儲、ETL、統(tǒng)計分析、寫入上層應(yīng)用數(shù)據(jù)庫進(jìn)行指標(biāo)展示。這是最基礎(chǔ)的一條線,現(xiàn)在還有基于數(shù)據(jù)倉庫進(jìn)行的數(shù)據(jù)分析挖掘工作,會基于機(jī)器學(xué)習(xí)和深度學(xué)習(xí)對已有模型數(shù)據(jù)進(jìn)一步挖掘分析,形成更深層的數(shù)據(jù)應(yīng)用產(chǎn)品。
數(shù)據(jù)應(yīng)用
俗話說的好,“酒香也怕巷子深”。數(shù)據(jù)應(yīng)用前面我們做了那么多工作為了什么,對于企業(yè)來說,我們做的每一件事情都需要體現(xiàn)出價值,而此時的數(shù)據(jù)應(yīng)用就是大數(shù)據(jù)的價值體現(xiàn)。數(shù)據(jù)應(yīng)用包括輔助經(jīng)營分析的一些報表指標(biāo),商城上基于用戶畫像的個性化推送,還有各種數(shù)據(jù)分析報告等等。

好的數(shù)據(jù)應(yīng)用一定要借助可視化顯現(xiàn),比如很多傳統(tǒng)企業(yè)買的帆軟。開源界推薦一款可視化工具Superset,可視化種類很多,支持?jǐn)?shù)據(jù)源也不少,使用方便。最近數(shù)磚收購的redash,也為了自己能一統(tǒng)大數(shù)據(jù)處理平臺。可以看出可視化對于企業(yè)數(shù)據(jù)價值體現(xiàn)是很重要的。
結(jié)尾
通過本文,可以對大數(shù)據(jù)平臺處理做初步了解,知道包含哪些技術(shù)棧,數(shù)據(jù)怎么流轉(zhuǎn),想要真正從0到1搭建起自己的大數(shù)據(jù)平臺,還是不夠的。了解了流程,你還需要真正的上手搭建Hadoop集群,Spark集群,數(shù)據(jù)倉庫建設(shè),數(shù)據(jù)分析流程規(guī)范化等等都需要很多工作。
Python中文社區(qū)作為一個去中心化的全球技術(shù)社區(qū),以成為全球20萬Python中文開發(fā)者的精神部落為愿景,目前覆蓋各大主流媒體和協(xié)作平臺,與阿里、騰訊、百度、微軟、亞馬遜、開源中國、CSDN等業(yè)界知名公司和技術(shù)社區(qū)建立了廣泛的聯(lián)系,擁有來自十多個國家和地區(qū)數(shù)萬名登記會員,會員來自以工信部、清華大學(xué)、北京大學(xué)、北京郵電大學(xué)、中國人民銀行、中科院、中金、華為、BAT、谷歌、微軟等為代表的政府機(jī)關(guān)、科研單位、金融機(jī)構(gòu)以及海內(nèi)外知名公司,全平臺近20萬開發(fā)者關(guān)注。
長按掃碼添加“Python小助手”
▼點(diǎn)擊成為社區(qū)會員? ?喜歡就點(diǎn)個在看吧